多模态大模型学习笔记(十八)——基于 DeepSeek-7B 的 LoRA 微调训练实战教程
·
基于 DeepSeek-7B 的 LoRA 微调训练实战教程
1、什么是 LoRA 微调?
1.1 传统微调 vs LoRA 微调
在了解 LoRA 之前,我们先回顾一下传统的模型微调方法:
| 方法 | 特点 | 显存需求 | 训练时间 |
|---|---|---|---|
| 全参数微调 | 调整模型所有参数 | 极高(~28GB) | 很长 |
| LoRA 微调 | 只训练少量新增参数 | 较低(~6GB) | 较短 |
1.2 LoRA 原理详解
LoRA(Low-Rank Adaptation,低秩适配) 的核心思想是:在不改变原始模型参数的情况下,通过添加少量可训练的低秩矩阵来微调模型。
原始模型前向传播: h = W × x
LoRA 改进后: h = W × x + (ΔW) × x
h = W × x + BA × x
其中:
- W:原始模型的预训练权重(冻结,不更新)
- B、A:新增的可训练低秩矩阵(r × d 和 d × r)
- r:秩(Rank),通常设为 8、16、32
1.3 LoRA 的优势
✅ 参数效率高:只需训练约 0.1%-1% 的参数
✅ 显存需求低:4bit 量化 + LoRA 可在消费级 GPU 上训练
✅ 部署便捷:只需保存增量权重(几十MB),无需保存整个模型
✅ 效果出色:在多项任务上可达到接近全参数微调的效果
2、数据集准备
2.1 三元组数据格式
本项目使用指令微调(Instruction Tuning) 方式,数据格式为三元组:
{
"instruction": "基于《三国演义》文档回答问题,必须标注信息来源(格式:文件名+位置),答案需严格匹配文档内容,不添加外部知识",
"input": "桃园三结义的三位人物是谁?",
"output": "桃园三结义的三位人物分别是刘备、关羽和张飞。三人在桃园中祭告天地,结为异姓兄弟,约定同心协力共图大业。信息来源:《三国演义》.txt第8行、《三国演义》.docx第5段"
}
三个字段的含义:
| 字段 | 含义 | 作用 |
|---|---|---|
instruction |
任务指令 | 告诉模型要做什么 |
input |
用户输入 | 具体的问题或请求 |
output |
期望输出 | 模型应该生成的答案 |
2.2 数据集来源
本项目的训练数据基于中国古典名著:
- 《三国演义》
- 《水浒传》
- 《西游记》
2.3 数据加载代码
def load_triple_data(data_path):
"""加载三元组训练数据"""
if not os.path.exists(data_path):
raise FileNotFoundError(f"三元组数据文件不存在:{data_path}")
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 验证数据格式
required_keys = ["instruction", "input", "output"]
for i, item in enumerate(data):
if not all(key in item for key in required_keys):
raise ValueError(f"第{i}条数据格式错误,需包含{required_keys}")
print(f"成功加载三元组数据,共{len(data)}条样本")
return data
3、训练流程详解
3.1 整体流程图

3.2 格式化训练文本
将三元组数据转换为模型可训练的指令格式:
def format_train_text(example):
"""
将三元组转换为模型训练格式(指令微调常用格式)
格式:"### 指令:{instruction}\n### 输入:{input}\n### 输出:{output}"
"""
return f"""### 指令:{example['instruction']}
### 输入:{example['input']}
### 输出:{example['output']}"""
转换效果:
原始数据:
{
"instruction": "基于《三国演义》文档回答问题...",
"input": "桃园三结义的三位人物是谁?",
"output": "桃园三结义的三位人物分别是刘备、关羽和张飞..."
}
转换后:

4、核心代码讲解
4.1 基础模型加载
def load_base_model(model_path):
"""加载基础模型(DeepSeek-7B-base),启用4位量化节省内存"""
# 4位量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 开启 4bit 量化
bnb_4bit_use_double_quant=True, # 双重量化,进一步压缩
bnb_4bit_quant_type="nf4", # 使用 NF4 量化类型
bnb_4bit_compute_dtype=torch.bfloat16 # 计算时使用 bf16
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.pad_token = tokenizer.eos_token # 设置 pad_token
# 加载模型(4bit 量化)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config,
device_map="auto", # 自动分配设备
trust_remote_code=True
)
# 准备模型用于量化训练
model = prepare_model_for_kbit_training(model)
return model, tokenizer
关键参数说明:
| 参数 | 作用 | 说明 |
|---|---|---|
load_in_4bit=True |
4bit 量化 | 将模型压缩到 4bit,显存降低 75% |
double_quant=True |
双重量化 | 进一步压缩,节省约 0.4 bit/参数 |
device_map="auto" |
自动设备分配 | 自动将模型分配到 GPU/CPU |
prepare_model_for_kbit_training |
准备量化训练 | 冻结非量化参数,添加梯度支持 |
4.2 LoRA 配置
def setup_lora(model, r=8, lora_alpha=32, lora_dropout=0.05):
"""配置LoRA参数并应用到模型"""
# 找到模型中所有线性层
modules = find_all_linear_names(model)
# LoRA 配置
lora_config = LoraConfig(
r=r, # 秩(Rank),控制低秩矩阵维度
lora_alpha=lora_alpha, # LoRA 缩放参数
target_modules=modules, # 要应用 LoRA 的模块
lora_dropout=lora_dropout, # Dropout 比例,防止过拟合
bias="none", # 不训练 bias
task_type="CAUSAL_LM", # 任务类型:因果语言模型
)
# 应用 LoRA 到模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数比例
return model
LoRA 参数详解:
| 参数 | 默认值 | 说明 |
|---|---|---|
r(秩) |
8 | LoRA 矩阵的维度,越大表达能力越强,但参数量也增加 |
lora_alpha |
32 | LoRA 缩放参数,通常设为 r 的 2-4 倍 |
target_modules |
- | 要应用 LoRA 的层,通常是 QKV 注意力层 |
lora_dropout |
0.05 | LoRA 层的 Dropout 比例 |
典型配置对比:
| 配置 | r | lora_alpha | 可训练参数比例 |
|---|---|---|---|
| 轻量级 | 4 | 16 | ~0.1% |
| 平衡型 | 8 | 32 | ~0.27% |
| 强力型 | 16 | 64 | ~0.5% |
4.3 训练数据处理
def tokenize_function(example):
"""将训练文本转换为模型输入格式"""
# 格式化训练文本
text = format_train_text(example)
# Tokenize 编码
result = tokenizer(
text,
truncation=True, # 截断超长文本
max_length=1024, # 最大长度 1024 token
padding="max_length", # 填充到最大长度
return_tensors="pt" # 返回 PyTorch 张量
)
# 处理张量维度(去除批次维)
result["input_ids"] = result["input_ids"].squeeze()
result["attention_mask"] = result["attention_mask"].squeeze()
# 对于 Causal LM,labels 就是 input_ids
result["labels"] = result["input_ids"].clone()
return result
# 处理数据集
tokenized_dataset = dataset.map(
tokenize_function,
batched=False,
remove_columns=dataset.column_names # 移除原始列
)
数据处理流程:
原始数据 (JSON)
↓ format_train_text()
格式化文本 (带指令格式的字符串)
↓ tokenizer()
Token IDs + Attention Mask + Labels (PyTorch Tensor)
↓ dataset.map()
HuggingFace Dataset (可用于训练)
4.4 训练参数配置
training_args = TrainingArguments(
output_dir="./lora_results", # 输出目录
per_device_train_batch_size=2, # 每设备批次大小
gradient_accumulation_steps=4, # 梯度累积步数
learning_rate=2e-4, # 学习率(LoRA 常用值)
num_train_epochs=3, # 训练轮次
logging_steps=10, # 日志打印间隔
save_steps=50, # 模型保存间隔
warmup_ratio=0.1, # 学习率预热比例
optim="paged_adamw_8bit", # 8位优化器,节省显存
report_to="none", # 不使用外部日志
push_to_hub=False # 不推送到 Hub
)
关键参数说明:
| 参数 | 值 | 说明 |
|---|---|---|
per_device_train_batch_size |
2 | 每 GPU 批次大小,7B 模型建议 2-4 |
gradient_accumulation_steps |
4 | 梯度累积,实际批次 = 2 × 4 = 8 |
learning_rate |
2e-4 | LoRA 推荐学习率(比全参数微调大) |
num_train_epochs |
3 | 小数据集 3-5 轮即可 |
optim |
paged_adamw_8bit | 8 位 AdamW,优化器显存减半 |
5、运行与结果
5.1 运行命令
# encoding=utf-8
import os
import json
import torch
import transformers
from datasets import Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import bitsandbytes as bnb
# 加在三元组训练数据
def load_triple_data(data_path):
if not os.path.exists(data_path):
raise FileNotFoundError(f"三元组数据文件不存在:{data_path},请先准备数据")
with open(data_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 验证数据格式
required_keys = ["instruction", "input", "output"]
for i, item in enumerate(data):
if not all(key in item for key in required_keys):
raise ValueError(f"第{i}条数据格式错误,需包含{required_keys}")
print(f"成功加载三元组数据,共{len(data)}条样本")
return data
def format_train_text(example):
"""
将三元组转换为模型训练格式(指令微调常用格式)
格式:"### 指令:{instruction}\n### 输入:{input}\n### 输出:{output}"
"""
return f"""### 指令:{example['instruction']}
### 输入:{example['input']}
### 输出:{example['output']}"""
def find_all_linear_names(model):
"""找到模型中所有线性层(用于LoRA适配)"""
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # 排除lm_head,避免影响输出
lora_module_names.remove('lm_head')
return list(lora_module_names)
def load_base_model(model_path):
"""加载基础模型(DeepSeek-7B-base),启用4位量化节省内存"""
# 4位量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.pad_token = tokenizer.eos_token # 设置pad_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config,
device_map="auto", # 自动分配设备(优先GPU,无GPU则用CPU)
trust_remote_code=True
)
# 准备模型用于量化训练
model = prepare_model_for_kbit_training(model)
return model, tokenizer
def setup_lora(model, r=8, lora_alpha=32, lora_dropout=0.05):
"""配置LoRA参数并应用到模型"""
# 找到所有线性层
modules = find_all_linear_names(model)
# LoRA配置
lora_config = LoraConfig(
r=r, # 秩,控制LoRA矩阵维度(越小参数越少)
lora_alpha=lora_alpha,
target_modules=modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM",
)
# 应用LoRA到模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数比例(通常<1%)
return model
# 训练lora模型
def train_lora(model, tokenizer, dataset, output_dir="./lora_results"):
# 处理数据集:tokenize训练文本
def tokenize_function(example):
# 单个 example 格式:{"instruction": "...", "input": "...", "output": "..."}
text = format_train_text(example)
result = tokenizer(
text,
truncation=True,
max_length=1024,
padding="max_length",
return_tensors="pt"
)
# 确保返回正确的格式
result["input_ids"] = result["input_ids"].squeeze()
result["attention_mask"] = result["attention_mask"].squeeze()
# 对于 Causal LM,labels 就是 input_ids
result["labels"] = result["input_ids"].clone()
return result
tokenized_dataset = dataset.map(
tokenize_function,
batched=False,
remove_columns=dataset.column_names # 移除原始文本列,只保留tokenized数据
)
# 训练参数配置(轻量级微调,适合CPU/GPU)
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2, # 批次大小
gradient_accumulation_steps=4, # 梯度累积,模拟大批次
learning_rate=1e-4, # 降低学习率,更稳定
num_train_epochs=10, # 增加训练轮次
logging_steps=5, # 每5步打印一次日志
save_steps=20, # 每20步保存一次模型
warmup_steps=10, # 预热步数
optim="paged_adamw_8bit", # 8位优化器,节省内存
report_to="none", # 不使用wandb等日志工具
push_to_hub=False, # 不推送到hub
save_total_limit=3, # 最多保存3个检查点
)
# 开始训练
model.train()
trainer = transformers.Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()
# 保存LoRA权重(仅保存增量参数,约几十MB)
model.save_pretrained(os.path.join(output_dir, "lora_weights"))
print(f"LoRA微调完成,权重保存至:{os.path.join(output_dir, 'lora_weights')}")
return output_dir
# 主函数:LoRA微调全流程
if __name__ == "__main__":
# 配置路径
BASE_MODEL_PATH = "/root/models/deepseek-llm-7b-base/deepseek-ai/deepseek-llm-7b-base" # 基础模型路径
TRIPLE_DATA_PATH = "/root/autodl-fs/class-2/triple_data.json" # 三元组数据文件路径
OUTPUT_DIR = "/root/autodl-fs/class-2/lora_results" # 微调结果保存路径
# 加载三元组数据
triple_data = load_triple_data(TRIPLE_DATA_PATH)
dataset = Dataset.from_list(triple_data) # 转换为HuggingFace Dataset格式
# 加载基础模型
model, tokenizer = load_base_model(BASE_MODEL_PATH)
# 配置LoRA
model = setup_lora(model)
# 开始微调
train_lora(model, tokenizer, dataset, OUTPUT_DIR)
执行
python main.py
5.2 运行输出
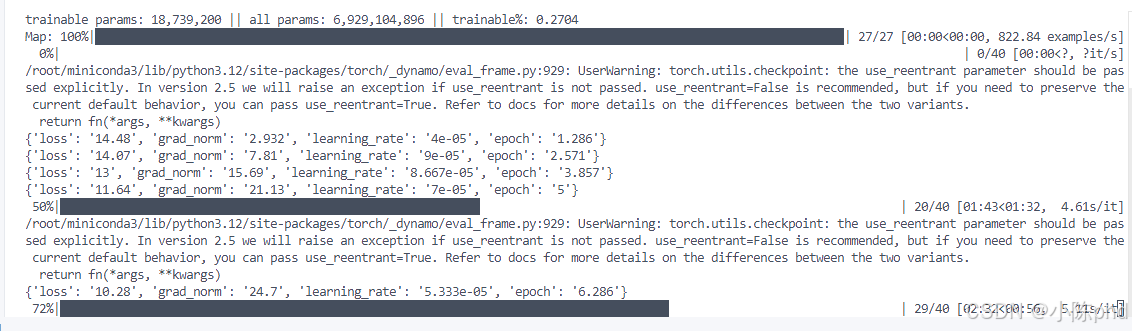

5.3 训练结果统计
| 指标 | 数值 |
|---|---|
| 训练样本数 | 27 条 |
| 基础模型 | DeepSeek-LLM-7B-base |
| 可训练参数 | 18,739,200 |
| 总参数 | 6,929,104,896 |
| 可训练参数比例 | 0.27% |
| 训练轮次 | 3 epochs |
| 训练时间 | 66.73 秒 |
| 最终 Loss | 13.17 |
| LoRA 权重大小 | ~20 MB |
##8、使用微调后的模型
6.1 加载 LoRA 权重
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
"/root/models/deepseek-llm-7b-base/deepseek-ai/deepseek-llm-7b-base",
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# 加载 LoRA 权重
lora_model = PeftModel.from_pretrained(
base_model,
"/root/autodl-fs/class-2/lora_results/lora_weights"
)
# 合并权重(可选,用于推理)
merged_model = lora_model.merge_and_unload()
6.2 测试微调效果
# 构建输入
prompt = "### 指令:基于《三国演义》文档回答问题,必须标注信息来源\n### 输入:刘备在长坂坡发生了什么?\n### 输出:"
# 生成
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)
7、常见问题与解决
问题 1:显存不足
错误:
RuntimeError: CUDA out of memory
解决方案:
- 减小
per_device_train_batch_size - 增大
gradient_accumulation_steps - 启用 4bit 量化
问题 2:Tokenizer 报错
错误:
ValueError: Couldn't instantiate the backend tokenizer
解决方案:
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
# 或安装 sentencepiece
pip install sentencepiece
问题 3:数据格式错误
错误:
json.decoder.JSONDecodeError
解决方案:
- 检查 JSON 文件是否完整(是否有缺失的
]) - 确保每条数据都有
instruction,input,output三个字段
8、总结
8.1 技术要点回顾
- LoRA 原理:通过低秩矩阵实现参数高效微调
- 4bit 量化:大幅降低显存需求,消费级 GPU 可训练
- 指令微调:使用三元组数据教会模型回答格式
- 数据处理:格式化 + Tokenize + Labels 准备
8.2 训练效果
- 仅用 27 条样本,训练 66 秒
- 可训练参数比例仅 0.27%
- 生成约 20MB 的 LoRA 权重文件
- 后续可加载权重进行问答测试
8.3 后续优化方向
- 增加训练数据量(建议 100+ 条)
- 调整 LoRA 参数(r=16 提升效果)
- 使用更大基础模型(DeepSeek-67B)
- 添加验证集评估模型效果
附录:完整代码
环境依赖
pip install torch transformers peft bitsandbytes datasets sentencepiece
核心函数清单
| 函数名 | 功能 |
|---|---|
load_triple_data() |
加载并验证三元组数据 |
format_train_text() |
格式化训练文本 |
find_all_linear_names() |
查找模型中的线性层 |
load_base_model() |
加载基础模型(4bit 量化) |
setup_lora() |
配置并应用 LoRA |
tokenize_function() |
Tokenize 训练数据 |
train_lora() |
执行训练流程 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)