深度学习模式与实践指南(三)
原文:Deep Learning Patterns and Practices
译者:飞龙
9 自编码器
本章涵盖了
-
理解深度神经网络(DNN)和卷积神经网络(CNN)自编码器的设计原则和模式
-
使用过程设计模式编码这些模型
-
训练自编码器时的正则化
-
使用自编码器进行压缩、去噪和超分辨率
-
使用自编码器进行预训练以提高模型泛化能力
到目前为止,我们只讨论了监督学习模型。自编码器模型属于无监督学习的范畴。提醒一下,在监督学习中,我们的数据由特征(例如,图像数据)和标签(例如,类别)组成,我们训练模型学习从特征预测标签。在无监督学习中,我们可能没有标签或者不使用它们,我们训练模型在数据中找到相关模式。你可能会问,没有标签我们能做什么?我们可以做很多事情,自编码器就是可以从未标记数据中学习的一种模型架构。
自编码器是无监督学习的根本深度学习模型。即使没有人工标记,自编码器也可以学习图像压缩、表示学习、图像去噪、超分辨率和预训练任务——我们将在本章中介绍每个这些内容。
那么,无监督学习是如何与自编码器一起工作的呢?尽管我们没有图像数据的标签,我们可以操作图像使其同时成为输入数据和输出标签,并训练模型来预测输出标签。例如,输出标签可以是简单的输入图像——在这里,模型将学习恒等函数。或者,我们可以复制图像并向其添加噪声,然后使用噪声版本作为输入,原始图像作为输出标签——这就是我们的模型学习去噪图像的方式。在本章中,我们将介绍这些以及其他几种将输入图像转换为输出标签的技术。
9.1 深度神经网络自编码器
我们将从这个章节开始介绍自编码器的经典深度神经网络版本。虽然你可以仅使用 DNN 学习到有趣的东西,但它不适用于图像数据,所以接下来的几节我们将转向使用 CNN 自编码器。
9.1.1 自编码器架构
DNN 自编码器如何有用的一个例子是在图像重建方面。我最喜欢的重建之一,通常用作预训练任务,是拼图。在这种情况下,输入图像被分成九个拼块,然后随机打乱。重建任务就是预测拼块被打乱的顺序。由于这个任务本质上是一个多值回归器输出,它非常适合传统的 CNN,其中多类分类器被多值回归器所取代。
自动编码器由两个基本组件组成:编码器和解码器。对于图像重建,编码器学习一个最优(或几乎最优)的方法来逐步将图像数据池化到潜在空间,而解码器学习一个最优(或几乎最优)的方法来逐步反池化潜在空间以进行图像重建。重建任务决定了表示学习和转换学习的类型。例如,在恒等函数中,重建任务是重建输入图像。但你也可以重建一个无噪声的图像(通过降噪)或更高分辨率的图像(超分辨率)。这些类型的重建与自动编码器工作得很好。
让我们看看编码器和解码器在自动编码器中如何协同工作来完成这些类型的重建。基本的自动编码器架构,如图 9.1 所示,实际上有三个关键组件,编码器和解码器之间有潜在空间。编码器对输入进行表示学习,学习一个函数 f(x) = x’。这个 x’ 被称为 潜在空间,它是从 x 学习到的低维表示。然后解码器从潜在空间进行转换学习,以执行原始图像的某种形式的重建。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F01_Ferlitsch.png
图 9.1 自动编码器宏架构中学习图像输入/输出的恒等函数
假设图 9.1 中的自动编码器学习恒等函数 f(x) = x。由于潜在空间 x’ 的维度更低,我们通常将这种形式的自动编码器描述为学习在数据集中压缩图像的最优方式(编码器)然后解压缩图像(解码器)。我们也可以将这描述为函数序列:编码器(x) = x’, 解码器(x’) = x。
换句话说,数据集代表了一种分布,对于这种分布,自动编码器学习最优的方法来压缩图像到更低的维度,并学习最优的解压缩方法来重建图像。让我们更详细地看看编码器和解码器,然后看看我们如何训练这种模型。
9.1.2 编码器
学习恒等函数的基本自动编码器形式使用密集层(隐藏单元)。池化是通过编码器中的每一层逐渐减少节点(隐藏单元)的数量来实现的,而反池化是通过每一层逐渐增加节点数量来学习的。最终反池化密集层中的节点数与输入像素数相同。
对于恒等函数,图像本身是标签。你不需要知道图像描绘的是什么,无论是猫、狗、马、飞机还是其他什么。当模型训练时,图像既是自变量(特征)也是因变量(标签)。
以下代码是自动编码器学习恒等函数的编码器的一个示例实现。它遵循图 9.1 中描述的过程,通过layers参数逐步池化节点(隐藏单元)的数量。编码器的输出是潜在空间。
我们首先将图像输入展平成一个一维向量。参数layers是一个列表;元素的数量是隐藏层的数量,元素值是该层的单元数。由于我们是逐步池化,每个后续元素的值逐渐减小。与用于分类的 CNN 相比,编码器在层上通常较浅,我们添加批量归一化以增强其正则化效果:
def encoder(x, layers):
''' Construct the Encoder
x : input to the encoder
layers: number of nodes per layer
'''
x = Flatten()(x) ❶
for layer in layers: ❷
n_nodes = layer['n_nodes']
x = Dense(n_nodes)(x)
x = BatchNormalization()(x)
x = ReLU()(x)
return x ❸
❶ 输入图像的展平
❷ 逐步单元池化(降维)
❸ 编码(潜在空间)
9.1.3 解码器
现在,让我们看看自动编码器解码器的一个示例实现。同样,遵循图 9.1 中描述的过程,我们通过layers参数逐步反池化节点(隐藏单元)的数量。解码器的输出是重构的图像。为了与编码器对称,我们以相反的方向遍历layers参数。最终Dense层的激活函数是sigmoid。为什么?每个节点代表一个重构的像素。由于我们已经将图像数据归一化到 0 到 1 之间,我们希望将输出挤压到相同的 0 到 1 范围内。
最后,为了重构图像,我们对来自最终Dense层的 1D 向量进行Reshape操作,将其重塑为图像格式(H × W × C):
def decoder(x, layers, input_shape):
''' Construct the Decoder
x : input to the decoder (encoding)
layers: nodes per layer
input_shape: input shape for reconstruction
'''
for _ in range(len(layers)-1, 0, -1): ❶
n_nodes = layers[_]['n_nodes']
x = Dense(n_nodes)(x)
x = BatchNormalization()(x)
x = ReLU()(x)
units = input_shape[0] * input_shape[1] * input_shape[2] ❷
x = Dense(units, activation='sigmoid')(x)
outputs = Reshape(input_shape)(x) ❸
return outputs ❹
❶ 逐步单元反池化(维度扩展)
❷ 最后一次反池化
❸ 重塑回图像输入形状
❹ 解码后的图像
9.1.4 训练
自动编码器想要学习一个低维度的表示(我们称之为潜在空间),然后学习一个根据预定义任务重构图像的变换;在这种情况下,恒等函数。
以下代码示例将训练前面的自动编码器,以学习 MNIST 数据集的恒等函数。该示例创建了一个具有隐藏单元 256、128、64(潜在空间)、128、256 和 784(用于像素重构)的自动编码器。
通常,一个深度神经网络自动编码器在编码器和解码器组件中都会包含三个或有时四个层。由于 DNNs 的有效性有限,增加更多的容量通常不会提高学习恒等函数的效果。
对于 DNN 自编码器,你在这里看到的另一个约定是,编码器中的每一层将节点数量减半,相反,解码器将节点数量加倍,除了最后一层。最后一层重建图像,因此节点数量与输入向量的像素数量相同;在这种情况下,784。在示例中选择从 256 个节点开始是有些任意的;除了从一个大尺寸开始会增加容量外,它对提高学习恒等函数的能力帮助很小,或者根本不起作用。
对于数据集,我们将图像形状从(28,28)扩展到(28,28,1),因为 TF.Keras 模型期望显式指定通道数——即使只有一个通道。最后,我们使用fit()方法训练自编码器,并将x_train作为训练数据和相应的标签(恒等函数)。同样,在评估时,我们将x_test作为测试数据和相应的标签。图 9.2 显示了自编码器学习恒等函数。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F02_Ferlitsch.png
图 9.2 自编码器学习两个函数:编码器学习将高维表示转换为低维表示,然后解码器学习将输入转换回高维表示,即输入的翻译。
以下代码演示了如图 9.2 所示的自动编码器的构建和训练,其中训练数据是 MNIST 数据集:
layers = [ {'n_nodes': 256 }, { 'n_nodes': 128 }, { 'n_nodes': 64 } ] ❶
inputs = Input((28, 28, 1)) ❷
encoding = encoder(inputs, layers)
outputs = decoder(encoding, layers, (28, 28, 1))
ae = Model(inputs, outputs)
from tensorflow.keras.datasets import mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = (x_train / 255.0).astype(np.float32)
x_test = (x_test / 255.0).astype(np.float32)
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)
ae.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
ae.fit(x_train, x_train, epochs=10, batch_size=32, validation_split=0.1,
verbose=1) ❸
ae.evaluate(x_test, x_test)
❶ 每层的过滤器数量元参数
❷ 构建自动编码器
❸ 无监督训练,其中输入和标签相同
让我们总结一下。自编码器想要学习一个低维度的表示(潜在空间),然后学习一个变换来根据预定义的任务(如恒等函数)重建图像。
使用 Idiomatic procedure reuse 设计模式为 DNN 自编码器提供的完整代码版本可在 GitHub 上找到(mng.bz/JvaK)。接下来,我们将描述如何使用卷积层代替密集层来设计和编写一个自编码器。
9.2 卷积自编码器
在 MNIST 或 CIFAR-10 数据集中的小图像中,DNN 自编码器运行良好。但是,当我们处理较大图像时,使用节点(即隐藏单元)进行(反)池化的自编码器在计算上很昂贵。对于较大图像,深度卷积(DC)自编码器更有效。它们不是学习(反)池化节点,而是学习(反)池化特征图。为此,它们在编码器中使用卷积,在解码器中使用反卷积,也称为转置卷积。
当步长卷积(进行特征池化)学习下采样分布的最佳方法时,步长反卷积(特征反池化)则做相反的操作,并学习上采样分布的可行方法。特征池化和反池化都在图 9.3 中展示。
让我们使用与 MNIST 的 DNN 自动编码器相同的上下文来描述这个过程。在那个例子中,编码器和解码器各有三层,编码器从 256 个特征图开始。对于 CNN 自动编码器,相应的等效结构是一个编码器,具有 256、128 和 64 个过滤器的三个卷积层,以及一个具有 128、256 和 C 个过滤器的解码器,其中 C 是输入的通道数。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F03_Ferlitsch.png
图 9.3 对比特征池化与特征反池化
9.2.1 架构
深度卷积自动编码器(DC 自动编码器)的宏观架构可以分解如下:
-
Stem—进行粗粒度特征提取
-
Learner—代表性和转换性学习
-
Task (重建)—进行投影和重建
图 9.4 显示了 DC 自动编码器的宏观架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F04_Ferlitsch.png
图 9.4 DC 自动编码器的宏观架构区分了表示学习和转换学习。
9.2.2 编码器
深度卷积自动编码器(如图 9.5 所示)中的编码器通过使用步长卷积逐步减少特征图的数量(通过特征减少)和特征图的大小(通过特征池化)。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F05_Ferlitsch.png
图 9.5 CNN 编码器中输出特征图的数量和尺寸的逐步减少
如你所见,编码器逐步减少过滤器的数量,也称为通道,以及相应的尺寸。编码器的输出是潜在空间。
现在让我们看看一个编码器的示例代码实现。参数layers是一个列表,其中元素的数量是卷积层的数量,元素值是每个卷积的过滤器数量。由于我们是逐步池化,每个后续元素的值都是逐步变小的。此外,每个卷积层通过使用步长为 2 来减少特征图的大小,进一步对特征图进行池化。
在这个实现中,对于卷积,我们使用 Conv-BN-RE 约定。你可能想尝试使用 BN-RE-Conv 来查看是否能得到更好的结果。
def encoder(inputs, layers):
""" Construct the Encoder
inputs : the input vector
layers : number of filters per layer
"""
outputs = inputs
for n_filters in layers: ❶
outputs = Conv2D(n_filters, (3, 3), strides=(2, 2), padding='same')
(outputs)
outputs = BatchNormalization()(outputs)
outputs = ReLU()(outputs)
return outputs ❷
❶ 逐步特征池化(降维)
❷ 编码(潜在空间)
9.2.3 解码器
对于解码器,如图 9.6 所示。解码器通过使用步长反卷积(转置卷积)逐步增加特征图的数量(通过特征扩展)和特征图的大小(通过特征反池化)。最后一个反池化层根据重建任务将特征图投影。对于恒等函数示例,该层将特征图投影到编码器输入图像的形状。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F06_Ferlitsch.png
图 9.6 CNN 解码器中输出特征图数量和尺寸的渐进扩展
这里是一个实现恒等函数解码器的示例。在这个例子中,输出是一个 RGB 图像;因此,在最后一个转置卷积层上有三个过滤器,每个过滤器对应一个 RGB 通道:
def decoder(inputs, layers):
""" Construct the Decoder
inputs : input to decoder
layers : the number of filters per layer (in encoder)
"""
outputs = inputs
for _ in range(len(layers)-1, 0, -1): ❶
n_filters = layers[_]
outputs = Conv2DTranspose(n_filters, (3, 3), strides=(2, 2),
padding='same')(outputs)
outputs = BatchNormalization()(outputs)
outputs = ReLU()(outputs)
outputs = Conv2DTranspose(3, (3, 3), strides=(2, 2), padding='same')
(outputs) ❷
outputs = BatchNormalization()(outputs)
outputs = Activation('sigmoid')(outputs)
return outputs ❸
❶ 渐进特征反池化(维度扩展)
❷ 最后的反池化和恢复到图像输入形状
❸ 解码后的图像
现在让我们将编码器与解码器组装起来。
在这个例子中,卷积层将逐步从 64 个、32 个到 16 个过滤器进行特征池化,而反卷积层将逐步从 32 个、64 个到 3 个过滤器进行特征反池化,以重建图像。对于 CIFAR,图像大小非常小(32 × 32 × 3),因此如果我们添加更多层,潜在空间将太小,无法进行重建;如果我们通过更多过滤器加宽层,我们可能会因为额外的参数容量而面临过拟合(欠拟合)的风险。
layers = [64, 32, 16] ❶
inputs = Input(shape=(32, 32, 3))
encoding = encoder(inputs, layers) ❷
❷
outputs = decoder(encoding, layers) ❷
❷
model = Model(inputs, outputs) ❷
❶ 编码器每层的过滤器数量元参数
❷ 构建自编码器
使用 Idiomatic 程序重用设计模式为 CNN 自编码器编写的一个完整代码示例在 GitHub 上(mng.bz/JvaK)。
9.3 稀疏自编码器
潜在空间的大小是一个权衡。如果我们做得太大,模型可能会过度拟合训练数据的表示空间,而无法泛化。如果我们做得太小,它可能会欠拟合,以至于我们无法执行指定的任务(例如,恒等函数)的转换和重建。
我们希望在这两者之间找到一个“甜蜜点”。为了增加自编码器不过度拟合或欠拟合的可能性,一种方法是添加一个稀疏性约束。稀疏性约束的概念是限制瓶颈层输出潜在空间的神经元激活。这既是一个压缩函数,也是一个正则化器,有助于自编码器泛化潜在空间表示。
稀疏性约束通常描述为仅激活具有大激活值的单元,并使其余单元输出为零。换句话说,接近零的激活被设置为零(稀疏性)。
从数学上讲,我们可以这样表述:我们希望任何单元(σ[i])的激活被限制在平均激活值(σ[µ])的附近:
σ[i] ≈ σ[µ]
为了实现这一点,我们添加了一个惩罚项,该惩罚项惩罚当激活 σ[i] 显著偏离 σ[µ] 时。
在 TF.Keras 中,我们通过在编码器的最后一层添加 activity_regularizer 参数来添加稀疏性约束。该值指定了激活值在 +/– 零附近的阈值,将其更改为零。一个典型的值是 1e-4。
下面是使用稀疏性约束实现的 DC-自编码器的实现。参数 layers 是一个列表,表示逐步池化特征图的数量。我们首先从列表的末尾弹出,这是编码器的最后一层。然后我们继续构建剩余的层。然后我们使用弹出(最后一层)的特征图数量来构建最后一层,其中我们添加稀疏性约束。这个最后的卷积层是潜在空间:
from tensorflow.keras.regulaziers import l1
def encoder(inputs, layers):
""" Construct the Encoder
inputs : the input vector
layers : number of filters per layer
"""
outputs = inputs
last_filters = layers.pop() ❶
for n_filters in layers: ❷
outputs = Conv2D(n_filters, (3, 3), strides=(2, 2), padding='same')
(outputs)
outputs = BatchNormalization()(outputs)
outputs = ReLU()(outputs)
outputs = Conv2D(last_filters, (3, 3), strides=(2, 2), padding='same', ❸
activity_regularizer=l1(1e-4))(outputs)
outputs = BatchNormalization()(outputs)
outputs = ReLU()(outputs)
return outputs
❶ 保留最后一层
❷ 特征池化
❸ 在编码器的最后一层添加稀疏性约束
9.4 去噪自编码器
使用自编码器的另一种方式是将其训练为图像去噪器。我们输入一个噪声图像,然后输出图像的去噪版本。将这个过程视为学习带有一些噪声的恒等函数。如果我们用方程表示这个过程,假设 x 是图像,e 是噪声。该函数学习返回 x:
f(x + e) = x
我们不需要为此目的更改自编码器架构;相反,我们更改我们的训练数据。更改训练数据需要三个基本步骤:
-
构建一个随机生成器,它将输出一个具有你想要添加到训练(和测试)图像中的噪声值范围的随机分布。
-
在训练时,向训练数据中添加噪声。
-
对于标签,使用原始图像。
下面是训练用于去噪的自编码器的代码。我们将噪声设置为在以 0.5 为中心的正态分布内,标准差为 0.5。然后我们将随机噪声分布添加到训练数据的副本(x_train_noisy)中。我们使用 fit() 方法来训练去噪器,其中噪声训练数据是训练数据,原始(去噪)训练数据是对应的标签:
noise = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape) ❶
x_train_noisy = x_train + noise ❷
model.fit(x_train_noisy, x_train, epochs=epochs, batch_size=batch_size,
verbose=1) ❸
❶ 生成噪声为以 0.5 为中心,标准差为 0.5 的正态分布
❷ 将噪声添加到图像训练数据的副本中
❸ 通过将噪声图像作为训练数据,原始图像作为标签来训练编码器
9.5 超分辨率
自编码器也被用来开发用于 超分辨率 (SR) 的模型。这个过程将低分辨率(LR)图像上采样以提高细节,以获得高分辨率(HR)图像。与压缩中学习恒等函数或去噪中学习噪声恒等函数不同,我们想要学习低分辨率图像和高分辨率图像之间的表示映射。让我们用一个函数来表示我们想要学习的这个映射:
f(x[lr]) = x[hr]
在这个方程中,f()代表模型正在学习的变换函数。术语x[lr]代表函数输入的低分辨率图像,而术语x[hr]是函数从高分辨率预测输出的变换。
尽管现在非常先进的模型可以进行超分辨率处理,但早期版本(约 2015 年)使用自动编码器的变体来学习从低分辨率表示到高分辨率表示的映射。一个例子是 Chao Dong 等人提出的超分辨率卷积神经网络(SRCNN)模型,该模型在“使用深度卷积网络进行图像超分辨率”一文中被介绍(arxiv.org/pdf/1501.00092.pdf)。在这种方法中,模型学习在多维空间中对低分辨率图像的表示(潜在空间)。然后它学习从低分辨率图像的高维空间到高分辨率图像的映射,以重建高分辨率图像。注意,这与典型的自动编码器相反,自动编码器在低维空间中学习表示。
9.5.1 预上采样 SR
SRCNN 模型的创造者引入了全卷积神经网络在图像超分辨率中的应用。这种方法被称为预上采样 SR 方法,如图 9.7 所示。我们可以将模型分解为四个组件:低分辨率特征提取、高维表示、编码到低维表示,以及用于重建的卷积层。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F07_Ferlitsch.png
图 9.7 预上采样超分辨率模型学习从低分辨率图像重建高分辨率图像。
让我们深入了解。与自动编码器不同,在低分辨率特征提取组件中没有特征池化(或下采样)。相反,特征图的大小与低输入图像中的通道大小相同。例如,如果输入形状是(16,16,3),则特征图的H × W将保持 16 × 16。
在主干卷积中,特征图的数量从输入的通道数(3)显著增加到,这为我们提供了低分辨率图像的高维表示。然后编码器将高维表示降低到低维表示。最后的卷积将图像重建为高分辨率图像。
通常,您会通过使用现有的图像数据集来训练这种方法,该数据集成为 HR 图像。然后您复制训练数据,其中每个图像都已被调整大小为更小,然后调整回原始大小。为了进行这两次调整大小,您使用静态算法,如双三次插值。LR 图像将与 HR 图像具有相同的大小,但由于调整大小操作期间所做的近似,LR 图像的质量将低于原始图像。
究竟什么是插值,更具体地说,双三次插值?可以这样想:如果我们有 4 个像素,用 2 个像素替换它们,或者反过来,你需要一种数学方法来对替换表示进行良好的估计——这就是插值。三次插值是用于向量的特定方法(1D),而 双三次 是用于矩阵(2D)的变体。对于图像缩小,双三次插值通常比其他插值算法给出更好的估计。
这里有一个代码示例,用于展示使用 CIFAR-10 数据集进行此训练数据准备的过程。在这个例子中,NumPy 数组 x_train 包含了训练数据图像。然后我们通过依次将 x_train 中的每个图像调整大小到一半的 H × W(16, 16),然后将图像调整回原始的 H × W(32, 32),并在 x_train_lr 中放置相同的索引位置,来创建一个低分辨率配对列表 x_train_lr。最后,我们对两组图像中的像素数据进行归一化:
from tensorflow.keras.datasets import cifar10
import numpy as np
import cv2
(x_train, y_train), (x_test, y_test) = cifar10.load_data() ❶
x_train_lr = [] ❷
for image in x_train: ❷
image = cv2.resize(image, (16, 16), interpolation=cv2.INTER_CUBIC) ❷
x_train_lr.append(cv2.resize(image, (32, 32), ❷
interpolation=cv2.INTER_CUBIC)) ❷
x_train_lr = np.asarray(x_train_lr) ❷
x_train = (x_train / 255.0).astype(np.float32) ❸
x_train_lr = (x_train_lr / 255.0).astype(np.float32) ❸
❶ 将 CIFAR-10 数据集下载到内存中作为高分辨率图像
❷ 创建训练图像的低分辨率配对
❸ 对训练中的像素数据进行归一化
现在,让我们看看用于在小型图像(如 CIFAR-10)上实现高分辨率重建质量的预上采样 SR 模型的代码。为了训练它,我们将原始 CIFAR-10 32 × 32 图像(x_train)视为高分辨率图像,将镜像配对图像(x_train_lr)视为低分辨率图像。对于训练,低分辨率图像是输入,配对的 HR 图像是相应的标签。
这个例子在 CIFAR-10 上仅用 20 个周期就得到了相当好的重建结果,重建准确率为 88%。如代码所示,stem() 组件使用粗略的 9 × 9 滤波器进行低分辨率特征提取,并为高维表示输出 64 个特征图。encoder() 由一个卷积组成,使用 1 × 1 瓶颈卷积将低分辨率表示从高维度降低到低维度,并将特征图的数量减少到 32。最后,使用粗略的 5 × 5 滤波器学习从低分辨率表示到高分辨率的映射以进行重建:
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Conv2D, BatchNormalization
from tensorflow.ketas.layers import ReLU, Conv2DTranspose, Activation
from tensorflow.keras.optimizers import Adam
def stem(inputs): ❶
x = Conv2D(64, (9, 9), padding='same')(inputs) ❷
x = BatchNormalization()(x) ❷
x = ReLU()(x) ❷
return x
def encoder(x):
x = Conv2D(32, (1, 1), padding='same')(x) ❸
x = BatchNormalization()(x) ❸
x = ReLU()(x) ❸
x = Conv2D(3, (5, 5), padding='same')(x) ❹
x = BatchNormalization()(x) ❹
outputs = Activation('sigmoid')(x) ❹
return outputs
inputs = Input((32, 32, 3))
x = stem(inputs)
outputs = encoder(x)
model = Model(inputs, outputs)
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.001),
metrics=['accuracy'])
model.fit(x_train_lr, x_train, epochs=25, batch_size=32, verbose=1,
validation_split=0.1)
❶ 低分辨率特征提取
❷ 高维表示
❸ 作为编码器的 1 × 1 瓶颈卷积
❹ 用于将重建为高分辨率图像的 5 × 5 卷积
现在让我们看看一些实际的图像。图 9.8 展示了 CIFAR-10 训练数据集中同一只孔雀的一组图像。前两个图像是用于训练的低分辨率和高分辨率图像对,第三个是模型训练后对同一孔雀图像的超分辨率重建。请注意,低分辨率图像比高分辨率图像有更多的伪影——即边缘周围的区域是方形的,颜色过渡不平滑。重建的超分辨率图像在边缘周围的色彩过渡更平滑,类似于高分辨率图像。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F08_Ferlitsch.png
图 9.8 预上采样超分辨率中 LR、HR 配对和重建 SR 图像的比较
9.5.2 后上采样超分辨率
另一个 SRCNN 风格模型的例子是后上采样超分辨率模型,如图 9.9 所示。我们可以将这个模型分解为三个部分:低分辨率特征提取、高维表示和重建的解码器。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F09_Ferlitsch.png
图 9.9 后上采样超分辨率模型
让我们更深入地探讨。与自动编码器不同,在低分辨率特征提取组件中没有特征池化(或下采样)。相反,特征图的大小与低输入图像中的通道大小相同。例如,如果输入形状是 (16, 16, 3),特征图的 H × W 将保持 16 × 16。
在卷积过程中,我们逐步增加特征图的数量——这就是我们得到高维空间的原因。例如,我们可能从三通道输入到 16,然后到 32,再到 64 个特征图。所以你可能想知道为什么维度更高?我们希望丰富的不同低分辨率特征提取表示有助于我们学习从它们到高分辨率的映射,这样我们就可以使用反卷积进行重建。但是,如果我们有太多的特征图,我们可能会使模型暴露在训练数据中的映射记忆中。
通常,我们使用现有的图像数据集来训练超分辨率模型,这些数据集将成为高分辨率图像,然后复制训练数据,其中每个图像都被调整大小以生成低分辨率图像对。
以下代码示例展示了使用 CIFAR-10 数据集进行此训练数据准备的过程。在这个例子中,NumPy 数组 x_train 包含训练数据图像。然后我们通过逐个调整 x_train 中每个图像的大小,并将其放置在 x_train_lr 中的相同索引位置,创建了一个低分辨率图像对列表 x_train_lr。最后,我们对两组图像中的像素数据进行归一化。
在后上采样的情况下,低分辨率图像保持为 16 × 16,而不是像预上采样那样调整回 32 × 32,这是因为在调整回 32 × 32 时,通过静态插值丢失了像素信息。
from tensorflow.keras.datasets import cifar10
import numpy as np
import cv2
(x_train, y_train), (x_test, y_test) = cifar10.load_data() ❶
x_train_lr = [] ❷
for image in x_train: ❷
x_train_lr.append(cv2.resize(image, (16, 16), ❷
interpolation=cv2.INTER_CUBIC)) ❷
x_train_lr = np.asarray(x_train_lr) ❷
x_train = (x_train / 255.0).astype(np.float32) ❸
x_train_lr = (x_train_lr / 255.0).astype(np.float32) ❸
❶ 将 CIFAR-10 数据集作为高分辨率图像下载到内存中
❷ 对训练图像进行低分辨率配对
❸ 对训练的像素数据进行归一化
下面的代码实现了一个后上采样 SR 模型,它在 CIFAR-10 等小图像上获得了良好的 HR 重建质量。我们专门为 CIFAR-10 编写了这个实现。为了训练它,我们将原始 CIFAR-10 32 × 32 图像 (x_train) 作为 HR 图像,将镜像配对图像 (x_train_lr) 作为 LR 图像。对于训练,LR 图像是输入,配对的 HR 图像是相应的标签。
这个示例在 CIFAR-10 上仅用 20 个 epoch 就获得了相当好的重建结果,重建准确率达到 90%。在这个示例中,stem() 和 learner() 组件执行低分辨率特征提取,并逐步扩展特征图维度从 16、32 到 64 个特征图。64 个特征图的最后一个卷积的输出是高维表示。decoder() 由一个反卷积组成,用于学习从低分辨率表示到高分辨率的映射以进行重建:
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Conv2D, BatchNormalization
from tensorflow.keras.layers import ReLU, Conv2DTranspose, Activation
from tensorflow.keras.optimizers import Adam
def stem(inputs): ❶
x = Conv2D(16, (3, 3), padding='same')(inputs)
x = BatchNormalization()(x)
x = ReLU()(x)
return x
def learner(x): ❶
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = ReLU()(x)
x = Conv2D(64, (3, 3), padding='same')(x) ❷
x = BatchNormalization()(x) ❷
x = ReLU()(x) ❷
return x
def decoder(x): ❸
x = Conv2DTranspose(3, (3, 3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('sigmoid')(x)
return x
inputs = Input((16, 16, 3))
x = stem(inputs)
x = learner(x)
outputs = decoder(x)
model = Model(inputs, outputs)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001),
metrics=['accuracy'])
model.fit(x_train_lr, x_train, epochs=25, batch_size=32, verbose=1,
validation_split=0.1)
❶ 低分辨率特征提取
❷ 高维表示
❸ 低到高分辨率重建
让我们回到之前看过的那些孔雀图像。在图 9.10 中,前两个图像是用于训练的低分辨率和高分辨率配对,第三个是模型训练后对同一孔雀图像的超分辨率重建。与之前的预上采样 SR 模型一样,后上采样 SR 模型产生的重建 SR 图像比低分辨率图像的伪影更少。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F10_Ferlitsch.png
图 9.10 LR、HR 配对和后上采样 SR 重建图像的比较
在 GitHub 上提供了使用 Idiomatic 程序重用设计模式对 SRCNN 进行完整代码实现的示例 (mng.bz/w0a2).
9.6 预训练任务
正如我们讨论的,自动编码器可以在没有标签的情况下进行训练,以学习关键特征的特征提取,这些特征我们可以重新用于迄今为止给出的示例之外:压缩和去噪。
我们所说的“关键特征”是什么意思?对于成像,我们希望我们的模型学习数据的本质特征,而不是数据本身。这使得模型不仅能够泛化到同一分布中的未见数据,而且还能在模型部署后,当输入分布发生偏移时,更好地预测其正确性。
例如,假设我们有一个训练好的模型用于识别飞机,训练时使用的图像包括各种场景,如停机坪、滑向航站楼和在空中,但没有一个是停机库中的。如果在部署模型后,它现在看到了停机库中的飞机,那么输入分布发生了变化;这被称为数据漂移。而当飞机图像出现在停机库中时,我们得到的准确度会降低。
在这个示例案例中,我们可能会尝试通过重新训练模型并添加包含背景中飞机的额外图像来改进模型。很好,现在部署时它工作了。但假设新模型看到了它没有训练过的其他背景中的飞机,比如在水面上的飞机(水上飞机)、在飞机坟场上的沙地上的飞机、在工厂中部分组装的飞机。好吧,在现实世界中,总有你预料不到的事情!
正因如此,学习数据集中的基本特征而不是数据本身非常重要。对于自动编码器来说,它们必须学习像素之间的相关性——即表示学习。相关性越强,关系越有可能在潜在空间表示中显现出来,相关性越弱,则不太可能显现。
我们不会在这里详细讨论使用前缀任务进行预训练,但我们将简要地在此处提及它,特别是在自动编码器的上下文中。就我们的目的而言,我们希望使用自动编码器方法来训练主干卷积组,以便在数据集上训练模型之前学习提取基本粗略级特征。以下是步骤:
-
在目标模型上进行预热(监督学习)训练,以实现数值稳定(将在第十四章中进一步讨论)。
-
构建一个自动编码器,其中模型的主干组作为编码器,反转的主干组作为解码器。
-
将目标模型中的数值稳定权重转移到自动编码器的编码器中。
-
在前缀任务(例如,压缩、去噪)上训练(无监督学习)自动编码器。
-
将前缀任务训练的权重从自动编码器的编码器转移到目标模型。
-
训练(监督学习)目标模型。
图 9.11 描述了这些步骤。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F11_Ferlitsch.png
图 9.11 使用自动编码器预训练主干组,以改善在模型完全使用标记数据训练后对未见数据的泛化。
让我们再讨论一下这种前缀任务的一部分。你可能已经想到,来自主干卷积组的输出将大于输入。当我们对通道进行静态或特征池化时,我们增加了总通道数。例如,我们可能使用池化将通道大小减少到 25%甚至仅为 6%,但我们将通道数从三个(RGB)增加到 64 个左右。
因此,潜在空间现在比输入更大,更容易过拟合。为此特定目的,我们构建了一个稀疏自动编码器来抵消过拟合的潜在可能性。
以下是一个示例实现。虽然我们尚未讨论UpSampling2D层,但它是对步长MaxPooling2D的逆操作。它不是使用静态算法将高度和宽度减半,而是使用静态算法将高度和宽度增加 2:
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Conv2D, Conv2DTranspose
from tensorflow.keras.layers import MaxPooling2D, UpSampling2D
from tensorflow.keras.regularizers import l1
def stem(inputs):
x = Conv2D(64, (5, 5), strides=(2, 2), padding='same',
activity_regularizer=l1(1e-4))(inputs) ❶
x = MaxPooling2D((2, 2), strides=(2, 2))(x) ❷
return x
def inverted_stem(inputs):
x = UpSampling2D((2, 2))(inputs) ❸
x = Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same')(x) ❹
return x
inputs = Input((128, 128, 3))
_encoder = stem(inputs)
_decoder = inverted_stem(_encoder)
model = Model(inputs, _decoder)
❶ 使用 5 × 5 滤波器进行粗略特征提取并使用特征池化
❷ 使用最大池化将特征图减少到图像大小的 6%
❸ 反转最大池化
❹ 反转特征池化并重建图像
以下是从该自动编码器的summary()方法输出的内容。请注意,输入大小等于输出大小:
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 128, 128, 3)] 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 64) 4864
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 64) 0
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 64, 64, 64) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 128, 128, 3) 4803
=================================================================
Total params: 9,667
Trainable params: 9,667
Non-trainable params: 0
9.7 超越计算机视觉:序列到序列
让我们简要地看看一种基本的自然语言处理模型架构,称为序列到序列(Seq2Seq)。此类模型结合了自然语言理解(NLU)——理解文本,和自然语言生成(NLG)——生成新文本。对于 NLG,Seq2Seq 模型可以执行诸如语言翻译、摘要和问答等操作。例如,聊天机器人是执行问答的 Seq2Seq 模型。
在第五章的结尾,我们介绍了 NLU 模型架构,并看到了组件设计如何与计算机视觉相媲美。我们还研究了注意力机制,它与残差网络中的身份链接相当。我们没有涵盖的是在 2017 年引入的 Transformer 模型架构,它引入了注意力机制。这一创新将 NLU 从基于时间序列的解决方案,使用 RNN,转变为空间问题。在 RNN 中,模型一次只能查看文本输入的片段并保持顺序。此外,对于每个片段,模型必须保留重要特征的记忆。这增加了模型设计的复杂性,因为您需要在图中实现循环以保留先前看到的特征。有了 Transformer 和注意力机制,模型可以一次性查看文本。
图 9.12 展示了 Transformer 模型架构,该架构实现了一个 Seq2Seq 模型。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH09_F12_Ferlitsch.png
图 9.12 Transformer 架构包括用于 NLU 的编码器和用于 NLG 的解码器
如您所见,学习组件包括用于 NLU 的编码器和用于 NLG 的解码器。您通过使用文本对、句子、段落等来训练模型。例如,如果您正在训练一个问答聊天机器人,输入将是问题,标签是答案。对于摘要,输入将是文本,标签是摘要。
在转换器模型中,编码器按顺序学习输入上下文的降维,这与计算机视觉自动编码器中编码器的表征学习相当。编码器的输出被称为中间表示,与计算机视觉自动编码器中的潜在空间相当。
解码器按顺序学习将中间表示扩展到变换上下文的维度扩展,这与计算机视觉自动编码器中解码器的变换学习相当。
解码器的输出传递给任务组件,该组件学习文本生成。文本生成任务与计算机视觉自动编码器中的重建任务相当。
摘要
-
自动编码器学习输入到低维表示的最佳映射,然后学习映射回高维表示,以便可以进行图像的变换重建。
-
自动编码器可以学习的变换函数示例包括恒等函数(压缩)、去噪图像和构建图像的高分辨率版本。
-
在卷积神经网络自动编码器中,池化操作通过步长卷积完成,而反池化操作通过步长反卷积完成。
-
在无监督学习中使用自动编码器可以训练模型学习数据集分布的基本特征,而无需标签。
-
使用编码器作为无监督学习预训练任务的前缀可以辅助后续的监督学习,以学习更好的泛化所需的基本特征。
-
NLU 的 Seq2Seq 模型模式使用一个编码器和解码器,与自动编码器相当。
第三部分. 使用管道
在本第三部分,你将学习如何设计和构建用于模型训练、部署和服务的生产级管道。我们首先向你介绍超参数调优在底层是如何工作的,然后展示使用 KerasTuner 的 DIY 方法和自动超参数调优。在两种情况下,有效的超参数调优都需要在选择搜索空间时做出良好的判断,因此我们讨论了这些最佳实践。
接下来,我们将转向迁移学习。在迁移学习中,你将重用另一个训练模型的权重,并使用更少的数据和更少的训练时间微调新的模型。我们涵盖了迁移学习的几种变体,一种是在新数据集的领域与训练模型非常相似时(例如,蔬菜与水果),另一种是在领域非常不同时。最后,我们介绍了在完整训练时初始化模型的领域迁移技术。
在剩余的章节中,我们将深入探讨整个生产级管道。我们首先探讨数据分布背后的概念以及它们如何影响部署的模型对训练期间未见过的真实世界输入的泛化能力。你将学习提高模型泛化训练的技术。接下来,我们将深入研究数据管道的组件、设计和配置,包括数据仓库、ETL 过程和模型喂养。你将学习以多种方式编码这些管道,使用 TF.Keras、tf.data、TFRecords 和 TensorFlow Extended (TFX)。
最后,我们将所有内容整合在一起,展示管道如何扩展到训练、部署,然后是服务。你将看到部署的硬件资源细节,如沙箱、负载均衡和自动扩展。在服务方面,你将学习如何通过使用预构建和自定义容器从云端提供服务,以及从边缘提供服务,并熟悉生产部署和 A/B 测试的细节。
10 超参数调整
本章涵盖
-
在预热训练之前初始化模型中的权重
-
手动和自动进行超参数搜索
-
为训练模型构建学习率调度器
-
在训练过程中正则化模型
超参数调整是寻找训练超参数最优设置的过程,以便我们最小化训练时间和最大化测试准确率。通常,这两个目标无法完全优化。如果我们最小化训练时间,我们可能无法达到最佳准确率。同样,如果我们最大化测试准确率,我们可能需要更长时间进行训练。
调整是找到满足你目标的最优超参数设置组合。例如,如果你的目标是尽可能高的准确率,你可能不会关心最小化训练时间。在另一种情况下,如果你只需要良好的(但不是最好的)准确率,并且你持续进行重新训练,你可能希望找到在最小化训练时间的同时获得这种良好准确率的设置。
通常,一个目标没有特定的设置。更有可能的是,在搜索空间内,各种设置组合都能实现你的目标。你需要找到其中之一——这就是调整的目的。
现在,我们调整的超参数有哪些?我们将在本章中详细探讨这些内容,但基本上它们是指导模型训练以最大化实现目标的参数。本章我们将调整的参数,例如,包括批量大小、学习率和学习率调度器。
在本章中,我们将探讨几种常用的超参数搜索(调整)技术。图 10.1 展示了传统生产环境中整体超参数过程的概览。目前不必担心细节,我们将一步步进行讲解。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F01_Ferlitsch.png
图 10.1 传统生产训练环境中的超参数过程
我将简要地浏览这个图表,以便你了解本章余下部分我们将遵循的过程。第一步是选择模型权重最佳初始化,我们将花些时间了解为什么这个选择可以显著影响训练结果。我们将从基于研究和进展的预定分布开始,进而探讨选择分布中抽取的一种替代方法:彩票原则。
接下来,在权重初始化后,我们转向预热预训练。这个过程从数值上稳定了权重,这将增加在训练时间和模型准确率方面获得更优结果的可能性。
一旦权重数值稳定,我们将探讨搜索和调整超参数的技术。
在我们初始化良好且数值稳定的权重和超参数调整完毕后,我们进入实际训练阶段,首先采用一些技术来进一步提高获得更优结果的可能性。其中一种我们将在此使用的技术是在训练的后期部分调整学习率。这可以显著提高收敛到全局或近似最优解的机会。换句话说,这些技术增加了在较低总体经济成本下产生更精确模型的概率。
我们将通过介绍在训练过程中权重更新时实施的常见正则化技术来结束本章。正则化有助于减少记忆(过拟合),同时增加模型在生产部署时对示例的泛化能力。我们将讨论生产中最常用的两种技术:权重衰减(也称为核正则化或层正则化)和标签平滑。
10.1 权重初始化
当我们从零开始训练一个模型时,我们需要给权重一个初始值。这个过程称为初始化。为了简单起见,我们可以先设置所有权重为相同的值——比如说,0 或 1。然而,这样做是不行的,因为反向传播中梯度下降的工作方式意味着每个权重都会进行相同的更新。
那个神经网络将是对称的,相当于一个单独的节点。一个单独的节点只能做出单一的二元决策,并且只能解决具有线性分离的问题,如逻辑与或或。逻辑异或问题不能通过单个节点解决,因为它需要一个非线性分离。早期感知器模型无法解决异或问题,这归因于从 1984 年到 2012 年人工智能研究减少和资金减少,这被称为人工智能冬天。
因此,我们需要将模型中的权重设置为随机值分布。理想情况下,分布范围应较小(在-1 和 1 之间),且以 0 为中心。在过去几年中,为了初始化权重,已经使用了几个随机分布的范围。为什么权重应该在一个小的分布范围内?好吧,如果我们的范围很大,较大的初始化权重将主导模型更新中的较小权重,导致稀疏性、准确性降低,并可能无法收敛。
10.1.1 权重分布
让我们先澄清权重初始化和权重分布之间的区别。权重初始化是在训练模型之前为权重设置的初始值,是起点。权重分布是我们选择那些初始权重的来源。
三种权重分布已被证明是最受研究人员欢迎的。均匀分布在整个范围内均匀分布。这不再使用。Xavier,或Glorot分布,是对均匀分布的改进,是一种以零为中心的随机正态分布。其标准差设置为以下公式,其中fan_in是层的输入数量:
sqrt(1 / fan_in)
这是在早期 SOTA 模型中流行的一种方法,最适合激活函数为 tanh(双曲正切)时使用。现在很少使用。
最后,我们有He-normal 分布,它是对 Xavier 分布的改进。如今,几乎所有权重初始化都是使用 He-normal 分布进行的;它是当前的主流分布,最适合 ReLU 激活函数。这种随机分布是以零为中心的正态分布,其标准差设置为以下公式,其中fan_in是层的输入数量:
sqrt(2 / fan_in)
现在我们来看看如何实现这一点。在 TF.Keras 中,默认情况下,权重初始化为 Xavier 分布(称为glorot_uniform)。要将权重初始化为 He-normal 分布,必须显式设置关键字参数kernel_initializer为he_normal。以下是实现方式:
x = Conv2D(16, (3, 3), strides=1, padding='same', activation='relu',
kernel_initializer='he_normal')(inputs) ❶
outputs = Dense(10, activation='softmax',
kernel_initializer='he_normal')(x) ❶
❶ 将权重初始化为 He-normal 分布
10.1.2 彩票假设
一旦研究人员就用于初始化神经网络的权重分布达成共识,下一个问题是,从分布中抽取的最佳方法是什么?我们将从讨论彩票假设开始,它引发了一系列从分布中抽取的快速进展,这进而导致了数值稳定性概念(在第 10.1.3 节中介绍)。
2019 年提出了用于权重初始化的彩票假设。该假设包含两个假设:
-
从随机分布中抽取的两个值不会相等。对于权重初始化的随机分布抽取中,有些抽取结果比其他抽取结果更好。
-
大型模型具有高精度,因为它们实际上是一系列小型模型的集合。每个模型从随机分布中抽取不同的值,其中一个抽取值是“中奖彩票”。
随后尝试从训练的大型模型中识别和提取具有“中奖彩票”的子模型到一个紧凑模型,但从未成功。因此,由 Jonathan Frankle 和 Michael Carbin 在“彩票假设”(arxiv.org/abs/1803.03635)中提出的方法现在不再使用,但后续研究导致了其他变体。在本节中,我们将探讨其中一种常用的变体。
然而,关于“中奖彩票”的问题尚未解决。另一群机器学习实践者使用预训练多个模型实例的方法,每个实例都有单独的抽取。通常,当使用这种方法时,我们使用非常小的学习率(例如,0.0001)运行少量 epoch。对于每个 epoch,步数远少于训练数据的大小。通过这样做,我们可以在短时间内预训练大量实例。一旦完成,选择具有最佳目标指标(如训练损失)的模型实例。假设这种抽取的中奖彩票比其他抽取更好。
图 10.2 通过使用彩票假设方法展示了预训练模型实例。创建了多个参考模型架构的副本以进行训练,每个副本从随机分布中抽取不同的样本。然后,每个实例使用相同的小学习率进行少量 epoch/减少的步数进行预训练。如果计算资源可用,预训练是分布式的。一旦完成,检查每个预训练模型的训练损失。具有最低训练损失的实例是具有最佳抽取的实例——即中奖彩票。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F02_Ferlitsch.png
图 10.2 使用彩票假设方法进行预训练
我们可以使用以下代码实现此过程。样本中显示的主要步骤如下:
-
创建 10 个模型实例,每个实例都有单独的抽取进行权重初始化。我们这样做是为了模拟这样一个原则:没有两个抽取是相同的。在这个例子中,选择 10 只是一个任意数。实例数量越多,每个实例都有单独的抽取,那么其中某个抽取是中奖彩票的可能性就越大。
-
对每个实例进行少量 epoch 和步数的训练。
-
选择具有最低训练损失的模型实例(
best)。
这里是代码:
def make_model():
''' make an instance of the model '''
bottom = ResNet50(include_top=False, weights=None,
input_shape=(32, 32, 3))
model = Sequential()
model.add(bottom)
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer=Adam(0.0001),
metrics=['acc'])
return model
lottery = [] ❶
for _ in range(10):
lottery.append(make_model())
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = (x_train / 255.0).astype(np.float32)
best = (None, 99999) ❷
datagen = ImageDataGenerator()
for model in lottery:
result = model.fit(datagen.flow(x_train, y_train, batch_size=32),
epochs=3,
steps_per_epoch=100)
print(result.history['loss'][2])
loss = result.history['loss'][2]
if loss < best[1]:
best = (model, loss)
❶ 创建 10 个模型实例,每个实例都有单独的抽取进行初始化
❷ 预训练并选择具有最低训练损失的实例
接下来,我们看看另一种权重初始化的方法,即使用预热来对权重进行数值稳定性。
10.1.3 预热(数值稳定性)
与彩票假设方法在权重初始化方面采取不同方法的数值稳定性方法,是目前在完整训练之前初始化权重的流行技术。在彩票假设中,大模型被视为子模型的集合,其中一个子模型拥有中奖彩票。在数值稳定性方法中,大模型被分为上层(底部)和下层(顶部)。
虽然我们之前讨论了底部与顶部的区别,但这种术语可能对一些读者来说仍然显得有些倒退——对我来说确实如此。在神经网络中,输入层是底部,输出层是顶部。输入从模型的底部馈入,预测从顶部输出。
假设较低(顶部)层在训练期间为较高(底部)层提供数值稳定性。或者更具体地说,较低层为较高层提供数值稳定性,以便它们可以学习获胜的彩票(初始化抽签)。图 10.3 描述了此过程。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F03_Ferlitsch.png
图 10.3 预训练以实现底层数值稳定性,以便高层学习获胜的彩票初始化
此方法通常在模型完整训练之前作为一个预热训练周期来实现。对于预热训练,我们从一个非常小的学习率开始,以避免引起权重的大幅波动,并使权重向获胜彩票移动。预热学习率的典型初始值在 1e-5 到 1e-4 的范围内。
我们对模型进行少量周期(通常是四到五个)的训练,并在每个周期后逐步提高学习率到为训练所选的初始学习率。
图 10.4 说明了预热训练方法,如图 10.1 中的步骤 1、2 和 3 所示。与彩票假设不同,我们从一个参考模型的单个实例开始训练。从非常低的学习率开始,其中权重通过微小的调整,模型以完整周期进行训练。每次学习率逐渐与完整训练的初始学习率成比例。达到最终周期后,模型实例中的权重被认为是数值稳定的。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F04_Ferlitsch.png
图 10.4 预热预训练以实现数值稳定性
在下面的代码示例中,你可以看到实现了以下五个关键步骤:
-
实例化一个模型的单个权重初始化实例。
-
定义学习率调度器
warmup_scheduler(),在每个周期后提高学习率。第 10.3 节详细介绍了学习率调度器。 -
将预热调度器作为
fit()方法的回调。 -
训练少量周期(例如,四个)。
def make_model(w_lr):
''' make an instance of the model '''
bottom = ResNet50(include_top=False, weights=None,
input_shape=(32, 32, 3))
model = Sequential()
model.add(bottom)
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer=Adam(w_lr),
metrics=['acc'])
return model
w_lr = 0.0001 ❶
i_lr = 0.001
w_epochs = 4
w_step = (i_lr - w_lr) / w_epochs
model = make_model(w_lr) ❷
def warmup_scheduler(epoch, lr):
""" learning rate scheduler for warmup training
epoch : current epoch iteration
lr : current learning rate
"""
if epoch == 0:
return lr
return lr + w_step ❸
from tensorflow.keras.callbacks import LearningRateScheduler ❹
lrate = LearningRateScheduler(warmup_scheduler, verbose=1)
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = (x_train / 255.0).astype(np.float32)
result = model.fit(x_train, y_train, batch_size=32, epochs=4,
validation_split=0.1,
verbose=1, callbacks=[lrate])
❶ 设置预热学习率和学习率步长
❷ 创建模型并设置初始学习率为预热率
❸ 从预热率逐步增加到完整训练的初始学习率
❹ 创建回调到学习率调度器
现在我们已经介绍了预训练,让我们来看看超参数搜索背后的基础。然后我们将把在这里学到的所有内容付诸实践,并对模型进行完整训练。
10.2 超参数搜索基础
一旦你的模型权重初始化具有数值稳定性(无论是由抽签还是预热),我们进行超参数搜索,也称为超参数调整或超参数优化。
记住,超参数搜索的目的是找到(近似)最佳超参数设置,以最大化您模型针对目标(例如,训练速度或评估准确性)的训练。而且,正如我们之前讨论的,我们区分模型配置的参数,称为元参数,以及训练的参数,称为超参数。在本节中,我们只关注调整超参数。
通常,在训练预配置模型时,我们尝试调整的超参数如下:
-
学习率
-
批量大小
-
学习率调度器
-
正则化
注意:不要在权重未进行数值稳定的模型上进行超参数搜索。如果没有权重的数值稳定,实践者可能会无意中丢弃性能较差的组合,而这些组合可能原本是好的组合。
让我们从视觉开始。图 10.5 展示了搜索空间。黑色区域代表产生最佳结果的超参数组合。搜索空间中可能存在多个最佳组合区域;在这种情况下,我们有三个黑色点。通常,在每个最佳区域附近都有一个较大的近似最佳结果区域,用灰色表示。搜索空间的大部分,用白色空间表示,产生非最佳(和非近似)的结果。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F05_Ferlitsch.png
图 10.5 超参数搜索空间
如您所见,白色区域相对于黑色区域的数量,如果您随机挑选一些超参数组合,您不太可能找到一个最佳或近似最佳结果。因此,您需要一个策略。一个好的策略是具有高概率落在近似最佳区域(s)的策略;处于近似最佳区域内可以缩小搜索空间,以找到附近的最佳区域。
10.2.1 超参数搜索的手动方法
在我们进入自动化搜索之前,让我们先通过一个手动方法来了解一下。我在训练计算机视觉模型方面有很多经验,并且在选择超参数方面有很强的直觉。我能够利用这种学到的直觉来进行手动引导的搜索。我通常遵循以下这四个初始步骤:
-
粗调初始学习率。
-
调整批量率。
-
精调初始学习率。
-
调整学习率调度器。
粗调初始学习率
我首先使用固定的批量大小和固定的学习率。如果是一个小数据集,通常少于 50,000 个示例,我使用 32 个批量大小;否则,我使用 256 个。我选择一个学习率的中心点——通常为 0.001。然后我在中心点(例如,0.001)及其一个数量级更大(例如,0.01)和更小(0.0001)的位置进行实验。我查看三个运行之间的验证损失和准确性,并决定哪个方向会导致更好的收敛。
如果我有一个具有最低验证损失和最高验证准确率的运行,我将选择那个。有时一个运行上的较低验证损失不会导致更高的准确率。在这些情况下,我更多地依赖直觉,但倾向于倾向于基于最低验证损失做出决定。
然后,我在现有和更好的收敛点之间选择一个新的中心点。例如,如果中心和收敛点是 0.001 和 0.01,我选择 0.005 作为中心,并使用一个数量级更大(0.05)和更小(0.0005),然后重复实验。我重复这种分而治之的策略,直到中心点给我最佳的收敛,这成为粗调的初始学习率。我很有可能接近最优区域(灰色)。
调整批量大小
接下来,我调整批量大小。一般来说,对于小型数据集使用 32,对于大型数据集使用 256 代表最低水平。所以我将尝试更高的值。我使用 2 倍因子。例如,如果我的批量大小是 32,我将尝试使用粗略学习率的 64。如果收敛性有所改善,我将尝试 128,依此类推。当它没有改善时,我选择之前的好值。
微调初始学习率
在这一点上,我很有可能已经接近了最优区域(黑色)。批量大小越大,每批损失的变化就越小。因此,如果我们增加了批量大小,我们通常可以提高学习率。
考虑到较大的批量大小,我重复进行了学习率的调整实验,以粗略学习率作为初始中心点。
学习率调度
在这一点上,我开始一个完整的训练运行,当验证准确率停止提高时进行早期停止。我通常首先尝试在学习率上使用余弦退火(随后讨论)。如果那有显著的改进,我通常就停在那里。否则,我会回顾最初的完整运行,并找到验证准确率平顶或发散的时期。然后我设置一个学习率调度器,在该点之前的一个时期将学习率降低一个数量级。
这通常给我一个非常好的起点,我现在可以专注于其他预训练步骤,如增强和标签平滑(在第 10.4 节中讨论)。
10.2.2 网格搜索
网格 搜索 是超参数搜索的最古老形式。这意味着你在狭窄的搜索空间中搜索每一个可能的组合;这是对于新问题获得洞察力的固有的人类方法。这种方法只有少数参数和值时才是实用的。例如,如果我们有三个学习率值和两个批量大小,组合的数量将是 3 × 2 或 6,这是实用的。让我们稍微增加一下,增加到五个学习率值和三个批量大小。现在就是 5 × 3 或 15。哇,看看组合是如何快速增长的!
由于与整个搜索空间相比,(近)最优区域要小得多,我们不太可能早期就找到一个好的组合。
这种方法不再使用,因为它计算开销大。以下是一个网格搜索的示例实现。我在这里提出它,以便你可以在下一小节中将它与随机搜索进行比较。
在这个例子中,我们在两个超参数上进行网格搜索:学习率(lr)和批量大小(bs)。对于两者,我们指定要尝试的值集,例如学习率指定为[0.1, 0.01]。然后我们使用两个嵌套循环迭代器生成学习率和批量大小值集的所有组合。对于每个组合,我们获取模型预训练实例的副本(get_model())并对其进行几个 epoch 的训练。保持最佳验证分数及其对应的超参数组合的运行总计(best)。完成后,best元组包含导致最低验证损失的超参数设置。
best = (None, 0, 0, 0)
epochs = 5
for lr in [0.1, 0.01]: ❶
for bs in [32, 64]:
model = get_model(lr) ❷
result = model.fit(x_train, y_train, batch_size=bs, epochs=epochs,
validation_split=0.1) ❸
val_acc = result.history['val_acc'][epochs-1] ❹
if val_acc > best[1]:
best = (model, val_acc, lr, bs)
❶ 对三个学习率和两个批量大小进行网格搜索
❷ 在编译模型时设置学习率
❸ 训练几个 epoch
❹ 使用验证准确率来选择最佳的学习率和批量大小组合
10.2.3 随机搜索
让我们转向随机搜索方法,这种方法在寻找好的超参数方面比网格搜索计算成本更低。你可能会问,随机搜索怎么可能比网格搜索计算成本更低(它只是随机的)?
为了回答这个问题,让我们回顾一下我们之前对超参数搜索空间的描述。我们知道其中只有一小部分有最优组合,所以我们随机找到它的概率非常低。但我们还知道,大量更大的区域是近最优的,所以我们使用随机搜索落在这些区域之一的概率大大提高。
一旦搜索找到一个近最优组合,我们就知道在附近很可能存在一个最优组合。在这个时候,我们将随机搜索缩小到围绕近最优组合的区域。如果新的组合提高了结果,我们可能会进一步缩小围绕新组合附近的随机搜索。
总结这些步骤:
-
设置搜索空间的边界。
-
在整个搜索空间内进行随机搜索。
-
一旦找到一个近最优组合,将搜索空间缩小到新组合的附近。
-
持续重复,直到找到一个满足你的目标标准的组合。
-
如果新的组合提高了结果,进一步缩小围绕新组合的搜索空间。
-
如果在预定义的试验次数后结果没有改善,则返回到搜索整个搜索空间(步骤 2)。
-
图 10.6 说明了前三个步骤。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F06_Ferlitsch.png
图 10.6 超参数随机搜索
这里是前三个步骤的一个示例实现。在这段代码中,我们做了以下操作:
-
在整个搜索空间上运行五个
试验。因为这个例子只有少数几种组合,通常五个试验就足够了。 -
选择一个随机组合的学习率(
lr)和批量大小(bs)。 -
在模型的一个预训练实例上进行短时间训练。
-
维护最佳验证准确率和超参数组合(
best)的累计记录。 -
从五个试验中选择最佳验证准确率作为接近最优的。
-
在接近最优的超参数(2X 和 1/2X )周围设置一个狭窄的搜索空间。
-
在狭窄的搜索空间内再运行五个试验。
from random import randint
learning_rates = [0.1, 0.01, 0.001, 0.0001] ❶
batch_sizes = [ 32, 128, 512] ❶
trials = 5
epochs = 3
best = (None, 0, 0, 0)
for _ in range(trials): ❷
lr = learning_rates[randint(0, 3)] ❸
bs = batch_sizes[randint(0, 2)] ❸
model = get_model(lr)
result = model.fit(x_train, y_train, epochs=epochs, batch_size=bs,
validation_split=0.1, verbose=0) ❹
val_acc = result.history['val_acc'][epochs-1] ❺
if val_acc > best[1]: ❺
best = (model, val_acc, lr, bs) ❺
learning_rates = [ best[2] / 2, best[2] * 2] ❻
batch_sizes = [best[3] // 2, int(best[3] * 2)]
for _ in range(trials): ❼
lr = learning_rates[randint(0, 1)]
bs = batch_sizes[randint(0, 1)]
model = get_model(lr)
result = model.fit(x_train, y_train, epochs=epochs, batch_size=bs,
validation_split=0.1, verbose=0)
val_acc = result.history['val_acc'][epochs-1]
if val_acc > best[1]:
best = (model, val_acc, lr, bs)
❶ 如果我们进行网格搜索,我们将有 4 × 3 = 12 种组合。
❷ 步骤 1:第一轮试验,找到最佳接近最优组合
❸ 步骤 2:选择随机组合
❹ 步骤 3:为试验进行短时间训练
❺ 步骤 4 和 5:记录当前最佳结果
❻ 步骤 6:将搜索空间缩小到最佳接近最优的附近
❼ 步骤 7:在缩小后的搜索空间周围运行另一组试验
我在没有数值稳定化的情况下运行了这段代码,使用了 CIFAR-10 数据集。在完整搜索空间的前五个试验之后,最佳验证准确率为 0.352。在缩小搜索空间后,最佳验证准确率跃升至 0.487,学习率为 0.0002,批量大小为 64。
我然后重复了这个过程,但这次我在进行超参数搜索之前首先对模型进行了数值稳定化。在完整搜索空间的前五个试验之后,最佳验证准确率为 0.569。在缩小搜索空间后,最佳验证准确率跃升至 0.576,学习率为 0.1,批量大小为 512。哇,这真是太好了。而且我们还没有对学习率调度、正则化、增强和标签平滑进行调整!
接下来,我们将讨论如何使用自动超参数搜索工具 KerasTuner,它是一个 TF.Keras 的附加模块。你可能会问,为什么我们要学习手动方法,而不是直接使用自动方法?即使使用自动方法,你也需要引导搜索空间。使用手动方法可以帮助你获得引导搜索空间的专长。对我来说,以及研究人员来说,开发手动方法让我们对未来自动搜索的改进有了洞察。最后,你可能会发现,现成的自动方法并不适合你的专有数据集和模型,你可以通过你独特的学习方法来改进它。
10.2.4 KerasTuner
KerasTuner 是 TF.Keras 的一个附加模块,用于进行自动化超参数调整。它有两种方法:随机搜索和超参数搜索。为了简洁,本节将介绍随机搜索方法。了解这种方法将使您对在搜索空间稀疏且好的组合较少的情况下搜索超参数的整体方法有所了解。
注意,我建议您参考在线文档(keras-team.github.io/keras-tuner/)了解超参数调整,这是一种用于改进随机搜索时间的 bandit 算法方法。您可以在李莎·李等人的“Hyberband”中找到更多信息(arxiv.org/abs/1603.06560)。
像所有自动化工具一样,KerasTuner 既有优点也有缺点。自动化且使用起来相对简单显然是优点。对我来说,无法调整批量大小是一个很大的缺点,因为你最终不得不手动调整批量大小。
这是安装 KerasTuner 的pip命令:
pip install -U keras-tuner
要使用 KerasTuner,我们首先创建一个 tuner 实例。在以下示例中,我们创建了一个RandomSearch类的实例。这个实例化需要三个必需的参数:
-
可调整超参数(
hp)模型 -
目标测量(例如,验证准确率)
-
训练试验的最大数量(实验)
from kerastuner.tuners import RandomSearch
tuner = RandomSearch(hp_model, ❶
objective='val_acc', ❷
max_trials=3) ❸
❶ 获取可调整超参数的模型
❷ 用于比较(改进)的训练指标
❸ 训练试验次数
在这个例子中,为了演示目的,我将试验次数设置得较低(3 次)。最多尝试三种随机组合。根据你的搜索空间大小,你通常会使用更大的数字。这是一个权衡。试验次数越多,探索的搜索空间就越大,但所需的计算成本(时间)也越高。
接下来,我们创建一个函数来实例化一个可调整超参数的模型。该函数接受一个参数,表示为hp。这是一个由 KerasTuner 传入的超参数控制变量。
在我们的例子中,我们将仅调整学习率。我们首先获取我们模型的一个数值稳定的版本实例,正如我之前推荐的那样。然后,我们使用compile()方法中的optimizer参数设置实例的学习率。在我们的例子中,我们将使用超参数调整器(hp)控制方法hp.Choice()指定四个学习率的选择。这告诉调整器要搜索的参数值集合。在这种情况下,我们将选择设置为[1e-1, 1e-2, 1e-3, 1e-4]:
def hp_model(hp):
''' hp is passed in by the tuner '''
model = tf.keras.models.load_model('numeric') ❶
model.compile(loss='sparse_categorical_crossentropy', metrics=['acc'], ❷
optimizer=Adam(hp.Choice('learning_rate',
values=[1e-1, 1e-2, 1e-3, 1e-4]))) ❸
return model
❶ 加载已保存(在磁盘上)的模型
❷ 重新编译模型以重置学习率
❸ 将学习率设置为可调整的参数
接下来,我们准备进行超参数调整。我们使用tuner的search()方法开始搜索。该方法接受与 Keras 模型fit()方法相同的参数。注意,在search()中明确指定了批大小,因此它不是自动可调的。在我们的例子中,我们的训练数据是 CIFAR-10 训练数据:
tuner.search(x_train, y_train, batch_size=32, validation_data=(x_test, y_test))
现在是结果!首先,使用results_summary()方法查看试验的摘要:
tuner.results_summary()
这里是输出,它显示 0.1 是最佳学习率:
Results summary
|-Results in ./untitled_project
|-Showing 10 best trials
|-Objective(name='val_acc', direction='max')
Trial summary
|-Trial ID: 0963640822565bfc03280657d5350d26
|-Score: 0.4927000105381012
|-Best step: 0
Hyperparameters:
|-learning_rate: 0.0001
Trial summary
|-Trial ID: 9c6ed7a1276c55a921eaf1d3f528d64d
|-Score: 0.28610000014305115
|-Best step: 0
Hyperparameters:
|-learning_rate: 0.01
Trial summary
|-Trial ID: d269858c936c2b6a2941e66f880304c7
|-Score: 0.10599999874830246
|-Best step: 0
Hyperparameters:
|-learning_rate: 0.1 ❶
❶ 选定的最佳学习率
然后,你使用get_best_models()方法来获取相应的模型。此方法根据参数num_models按降序返回最佳模型列表。在这种情况下,我们只想得到最佳的一个,所以我们将它设置为 1。
models = tuner.get_best_models(num_models=1)
model = models[0]
最后,你的结果和模型存储在一个文件夹中,可以在实例化tuner时通过参数project_name指定。如果没有指定,文件夹名称默认为untitled_project。为了清理试验后的文件夹,你会删除这个文件夹。
10.3 学习率调度器
到目前为止,在我们的示例中,我们一直在整个训练过程中保持学习率不变。你可以用恒定的学习率得到好的结果,但它不如在训练过程中调整学习率有效。
通常,在训练过程中,你会从较大的学习率逐渐降低到较小的学习率。最初,你希望尽可能开始使用较大的学习率,而不引起数值不稳定性。较大的学习率允许优化器探索不同的路径(局部最优解),并在最小化损失方面取得一些初始的大幅收益,从而加快训练速度。
但一旦我们朝着良好的局部最优解取得良好进展,如果我们继续使用高学习率,我们可能会开始来回震荡,无法收敛,或者无意中跳出良好的局部最优解,开始向较差的局部最优解收敛。
因此,随着我们接近收敛,我们开始降低学习率,以采取越来越小的步骤,这样就不会震荡,并找到局部最优解中的最佳路径以收敛。
那么,“学习率调度器”这个术语是什么意思呢?这意味着我们将有一个方法来监控训练过程,并根据一定的条件对学习率进行调整,以找到并收敛到最佳或近似的局部最优解。在本节中,我们将介绍几种常见的方法:包括时间衰减、斜坡、常数步长和余弦退火。我们将从描述时间衰减方法开始,这是 TF.Keras 优化器集内置的方法,用于在训练过程中逐步降低学习率。
10.3.1 Keras 衰减参数
TF.Keras 优化器支持使用decay参数逐步降低学习率。优化器使用时间衰减方法。时间衰减的数学公式如下,其中lr是学习率,k是衰减系数,t是迭代次数(例如,epochs):
lr = lr 0 / (1 + kt)
在 TF.Keras 中,时间衰减的实现方式如下:
lr = lr × (1.0 / (1.0 + decay × iterations))
以下是在compile()方法中指定优化器时设置学习率时间衰减的示例:
model.compile(optimizer=SGD(lr=0.1, decay=1e-3))
表 10.1 显示了使用先前设置的前 10 个 epochs 的学习率进度;典型的衰减值在 1e-3 和 1e-6 之间。
表 10.1 学习率随 epoch 的衰减进度
| 迭代(epoch) | 学习率 |
|---|---|
| 1 | 0.0999 |
| 2 | 0.0997 |
| 3 | 0.0994 |
| 4 | 0.0990 |
| 5 | 0.0985 |
| 6 | 0.0979 |
| 7 | 0.0972 |
| 8 | 0.0964 |
| 9 | 0.0955 |
| 10 | 0.0945 |
10.3.2 Keras 学习率调度器
如果使用时间衰减没有产生最佳结果,你可以使用LearningRateScheduler回调函数实现自己的自定义方法来逐步降低学习率。在生产环境中,ML 团队随着时间的推移进行实验并找到自定义调整,使训练更加高效,并在目标上产生更好的结果,例如在生产部署时的分类准确率。
以下代码是一个示例实现,其步骤在此概述:
-
定义我们的学习率调度器回调函数。
-
在训练过程中(通过
fit()方法),传递给回调函数的参数是当前 epoch 计数(epoch)和学习率(lr)。 -
对于第一个 epoch,返回当前的(初始)学习值。
-
否则,实现一个逐步降低学习率的方法。
-
实例化一个用于学习率调度器的回调函数。
-
将回调函数传递给
fit()方法。
from tensorflow.keras.callbacks import LearningRateScheduler
def lr_scheduler(epoch, lr):
''' Set the learning rate at the beginning of epoch
epoch: The epoch count (first epoch is zero)
lr: The current learning rate
'''
if epoch == 0: ❶
return lr
return n_lr ❷
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.01)) ❸
lr_callback = LearningRateScheduler(lr_scheduler) ❹
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
callbacks=[lr_callback]) ❺
❶ 步骤 3:对于第一个(0)epoch,从初始学习率开始
❷ 步骤 4:添加你的逐步降低学习率的实现
❸ 步骤 1:设置初始学习率
❹ 步骤 5:创建学习率调度器的回调函数
❺ 步骤 2 和 6:为训练启用学习率调度器
10.3.3 渐增
因此,你已经完成了数值稳定性的预训练步骤和批量大小以及初始学习率的超参数调整。现在你准备好实现你的学习率调度器算法了。通常,你可以使用一个渐增算法来实现这一点,该算法在指定数量的 epochs 后重置学习率。通常,在这个阶段,我会进行一次扩展的训练运行。我通常从 50 个 epochs 开始,并在评估损失上设置一个提前停止条件(patience为 2)。无论数据集如何,我通常会看到两种情况之一:
-
在最后(50)个 epochs 中,评估损失保持稳定和一致地减少。
-
在最后一个时期之前,验证损失出现平台期,并且提前停止已经启动。
如果我看到验证损失持续减少,我将继续重复额外的 50 个时期,直到出现提前停止。
一旦我设置了提前停止,我会查看它发生在哪个时期。比如说,它发生在第 40 个时期。然后我会减去几个时期,通常是 5 个(在这种情况下,结果是 35)。然后我将我的学习率调度器硬编码为在该时期降低一个数量级的学习率。几乎 100%的情况下,我的训练会改善到更低的验证损失和更高的验证准确率。图 10.7 显示了降低的学习率。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F07_Ferlitsch.png
图 10.7 降低的学习率
以下是一个斜坡学习率调度器的示例实现:
epoch_ramp = 35 ❶
def lr_scheduler(epoch, lr):
if epoch == epoch_ramp: ❷
return lr / 10.0 ❷
return lr
❶ 设置降低一个数量级的时期
❷ 在斜坡时期降低学习率一个数量级
这通常不是我的最后一步,而是我用它来了解这个数据集的损失地形可能是什么样子。从那以后,我计划我的完整训练学习率调度器。在这个层面上,解释损失地形会太具有挑战性。相反,我将介绍你可以尝试的各种学习率调度器策略。
10.3.4 恒定步长
在恒定步长方法中,我们希望在最后一个时期内以等量递增的方式从初始学习率到零。这个方法很简单。你将初始学习率除以时期数。图 10.8 展示了这个方法。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F08_Ferlitsch.png
图 10.8 恒定步长学习率
这是一个学习率调度器的步长方法的示例实现:
epochs = 200 ❶
lr = 0.001 ❷
step = lr / epochs ❸
def lr_scheduler(epochs, lr):
''' step learning rate '''
return lr - step
❶ 训练的时期数
❷ 由超参数调整确定的初始学习率
❸ 每个时期后步长衰减的大小
10.3.5 余弦退火
余弦退火方法在研究人员中很受欢迎,在关于消融研究的学术论文中经常出现。它也被称为循环学习率。这里的理念是,不是在训练过程中逐渐降低学习率,而是在周期中这样做。
更简单地来说,我们从初始学习率开始,逐渐降低到一个较低的学习率,然后我们再次逐渐提高它。我们持续重复这个循环,但每次循环开始时的速率(高)和结束时的速率(低)都更低——因此我们在循环中仍然在向更低的方向进步。
那么,它的优势是什么?它提供了定期探索其他局部最优解(跳出)和逃离鞍点的机会。对于局部最优解,它就像进行一次梁搜索。训练过程可能会跳出当前的局部最优解,并开始深入另一个。虽然一开始没有任何迹象表明新的局部最优解更好,但最终会是这样。原因如下。随着训练的进行,我们将深入到比较差的局部最优解更好的局部最优解。随着学习率的下降,我们跳出好的局部最优解的可能性越来越小。另一种思考这种周期性行为的方式是探索与利用:在周期的较高端,训练正在探索新的路径,而在较低端,它正在利用好的路径。随着训练的进展,我们逐渐减少探索,增加利用。
另一个优势是,在我们使用学习率周期的低端深入挖掘后,我们可能会卡在鞍点上。让我们使用以下图表来帮助理解鞍点是什么。
如果我们的特征(自变量)与标签(因变量)之间存在线性关系,一旦我们发现了变化率,我们就会深入到全局最优解,无论学习率如何(如图中第一条曲线所示)。
另一方面,如果关系是多项式的,我们将看到更像是凸曲线的东西,全局最优解作为曲线的最低点。原则上,只要我们持续降低学习率,我们就会下降到最低点,避免在曲线两侧来回弹跳(如图中第二条曲线所示)。
但深度学习的力量在于特征与标签之间存在非线性(和非多项式)关系(如图中第三条曲线所示)。在这种情况下,考虑损失空间由山谷、山峰和鞍点组成,一个山谷是全局最优解。我们的目标当然是找到这个山谷,这就是探索多个局部最优解(山谷)的优势。
鞍点是在山谷中具有平台的部分;它在继续下降之前变得平坦。如果我们的学习率非常低,我们将在平台上无休止地弹跳。因此,虽然我们希望在训练接近结束时拥有那个很小的学习率,但我们希望它偶尔上升,以推动我们在下降到最低点时离开鞍点。
图 10.9 对比了线性/多项式与非线性关系之间的损失表面,显示了峰值、谷值和平台——这些可以成为鞍点。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F09_Ferlitsch.png
图 10.9 梯度下降和学习率变化率斜率
当使用余弦衰减与早停结合时,我们必须重新思考停止的目标(验证准确率)。如果我们使用非周期性衰减进行训练,我们可能会在停止前使用非常小的阈值差异。但是,由于周期性行为,我们在探索(周期的末端)时可能会看到差异的突然激增(验证损失增加)。因此,我们需要为早停使用更大的差距。另一种选择是使用自定义早停,随着周期末端的降低,逐渐减小差异。
以下是一个使用余弦衰减的学习率调度器的示例实现。该函数有点复杂。我们使用余弦函数np.cos()从 0 到 1 生成正弦波。例如,余弦(π)是-1,余弦(2π)是 1,所以传递给np.cos()的值的计算是π的倍数。这样,值就是正的,计算中加 1,结果现在将在 0 到 2 的范围内。然后,该值减半(0.5 倍),所以结果现在将在 0 到 1 的范围内。然后,衰减通过 alpha 调整,它设置最小学习率的下限。
def cosine_decay(epoch, lr, alpha=0.0):
""" Cosine Decay
"""
cosine_decay = 0.5 * (1 + np.cos(np.pi * (e_steps * epoch) / t_steps)) ❶
decayed = (1 - alpha) * cosine_decay + alpha ❷
return lr * decayed ❸
def lr_scheduler(epochs, lr):
''' cosine annealing learning rate '''
return cosine_decay(epochs, lr) ❹
❶ 计算介于 0 和 2 之间的余弦值并减半
❷ 通过 alpha 调整值
❸ 返回衰减后的学习率
❹ 将学习率调度器回调连接到余弦衰减函数
在 TF 2.x 中,余弦衰减被添加为内置的学习率调度器:
from tf.keras.experimental import CosineDecay ❶
lrate = CosineDecay(initial_learning_rate, decay_steps, alpha) ❷
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
callbacks=[lrate]) ❸
❶ 导入 CosineDecay 内置学习率调度器
❷ 实例化 CosineDecay 学习率调度器
❸ 在训练期间将学习率调度器作为回调添加
10.4 正则化
下一个重要的超参数是正则化。这指的是向训练中添加噪声的方法,使得模型不会记住训练数据。我们可以延迟记忆的时间越长,在预测未训练数据(如测试(保留)数据)时获得更高模型准确率的机会就越好。
让我们更简单地重申这一点。我们希望模型学习基本特征(泛化),而不是数据(记忆)。
关于正则化中的 dropout 的说明:现在没有人那样做了;这是古老的。
10.4.1 权重正则化
目前最广泛使用的正则化形式是权重正则化,也称为权重衰减。权重正则化是按层应用。其目的是在反向传播中向权重更新添加与权重大小相关的噪声。这种噪声通常被称为惩罚,权重较大的层比权重较小的层有更大的惩罚。
不深入探讨梯度下降和反向传播,可以说损失计算是更新每一层权重计算的一部分。例如,在回归器模型中,我们通常使用均方误差来表示预测值 (ŷ) 和实际(真实 – y)值之间的损失,可以表示如下:
损失函数 = MSE(ŷ, y)
为了为每一层添加噪声,我们希望按权重大小比例添加一小部分作为惩罚:
损失函数 = MSE(ŷ, y) + penalty
惩罚 = decay × R(w)
在这里,decay 是权重衰减,其值 << 1。而 R(w) 是应用于该层权重 w 的正则化函数。TF.Keras 支持以下正则化函数:
-
L1—绝对权重的总和,也称为 Lasso 正则化
-
L2—平方权重的总和,也称为 Ridge 正则化
-
L1L2—绝对和平方权重的总和,也称为 Elastic Net 正则化
现代 SOTA 研究论文中引用的消融研究使用 L2 权重正则化,其值范围在 0.0005 到 0.001 之间。根据我的经验,我发现 0.001 以上的值在权重正则化上过于激进,并且训练无法收敛。
在 TF.Keras 中,使用关键字参数 kernel_regularizer 来设置每层的权重正则化。如果您使用它,您应该在所有具有学习参数的层上指定它(例如,Conv2D,Dense)。以下是一个为卷积层(Conv2D)指定L2权重衰减正则化的示例实现:
from tensorflow.keras.regularizers import L2
inputs = Input((128, 128, 3))
x = Conv2D(16, (3, 3), strides=(1, 1), kernel_regularizer=L2(0.001))(inputs)
10.4.2 标签平滑
标签 平滑方法从不同的角度进行正则化。到目前为止,我们讨论了添加噪声以防止记忆化的技术,从而使模型能够泛化到模型在训练期间未见过的同一分布内的示例。
然而,我们发现,即使我们惩罚这些权重更新以防止记忆化,这些模型在预测上往往过于自信(高概率值)。
当模型过于自信时,真实标签和非真实标签之间的距离可以有很大差异。当绘制时,它更倾向于看起来像散点图而不是簇;如果真实标签聚集在一起,即使置信度较低,这也是更理想的情况。图 10.10 展示了使用硬目标标签的过于自信的模型。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F10_Ferlitsch.png
图 10.10 训练时作为独热编码标签(0 或 1)的标签
标签平滑通过使预测不那么自信来帮助模型泛化,这导致真实标签和非真实标签之间的距离聚集在一起。
在标签平滑中,我们将 one-hot 编码的标签(真实值)从绝对确定性(1 和 0)调整为小于绝对确定性,用α(阿尔法)表示。例如,对于真实标签,我们不是将其值设置为 1(100%),而是将其设置为略低一些的值,比如 0.9(90%),然后将所有非真实值从 0(0%)调整到降低真实标签的相同数量(例如,10%)。
图 10.11 说明了标签平滑。在这个描述中,将输出密集层的预测与标签平滑后的真实标签进行比较,称为软目标。损失是从软目标而不是硬目标计算出来的,这在实践中已被证明可以使真实值和非真实值之间的距离更加一致。这些距离更有可能形成簇,这有助于模型更加泛化。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH10_F11_Ferlitsch.png
图 10.11 标签平滑作为当标签小于绝对确定性时的软目标
在 TF 2.x 中,标签平滑内置在损失函数中。要使用它,显式实例化相应的损失函数并设置关键字参数label_smoothing。在实践中,α因子保持较小,0.1 是最常用的值。
from tensorflow.keras.losses import CategoricalCrossentropy
model.compile(loss=CategoricalCrossentropy(label_smoothing=0.1), ❶
optimizer='adam', metrics=['acc']) ❶
❶ 在编译模型时设置标签平滑
接下来,我们将总结我们在超参数方面所涵盖的内容,以及它们如何影响在训练时间和目标(例如,准确率)方面实现最佳结果。
10.5 超越计算机视觉
所有深度学习模型架构,无论数据类型或领域,都有可调整的超参数。调整它们的策略是相同的。无论你是在处理计算机视觉、自然语言理解还是结构化数据,深度学习领域的四大超参数都存在:学习率、学习率衰减、批量大小和正则化。
正则化的超参数在模型架构和不同领域之间可能类型不同。很多时候它们并不不同。例如,权重衰减可以应用于任何具有可学习权重的层,无论它是计算机视觉、NLU 还是结构化数据模型。
一些模型架构,如深度神经网络和提升树,有一些历史上独特的超参数。例如,对于 DNN,你可能看到调整层数和每层的单元数。对于提升树,你可能看到调整树的数量和叶子数。但是,由于超参数(用于训练模型)和元参数(用于配置模型架构)的划分,这些可调整的参数现在被称为元参数。因此,如果你在深度神经网络中同时调整层数和单元数以及学习率,实际上你正在进行宏观架构搜索和超参数调整的并行操作。
摘要
-
不同的权重分布和抽取会影响训练过程中的收敛性。
-
在搜索最佳权重初始化(抽签原则)与学习最佳权重初始化(预热)之间的区别在于,模型学习最佳初始化而不是通过经验找到它。
-
当数据集较小时,使用手动方法进行超参数搜索是最佳选择,但其缺点是您可能会忽略在训练过程中实现更好结果的超参数值。
-
网格搜索用于小搜索空间,而在大搜索空间中进行超参数调整时,随机搜索效率更高。
-
使用 KerasTuner 进行超参数搜索可以自动化搜索过程,但其缺点是您无法手动引导搜索。
-
用于学习率衰减的各种算法包括时间衰减、恒定步长、斜坡步长和余弦退火。
-
设置学习率调度器涉及定义回调函数,在回调函数中实现自定义学习率算法,并将回调函数添加到
fit()方法中。 -
常规的正则化方法包括权重衰减和标签平滑。
11 迁移学习
本章涵盖
-
使用 TF.Keras 和 TensorFlow Hub 中的预构建和预训练模型
-
在类似和不同领域之间执行任务迁移学习
-
使用特定领域权重初始化迁移学习模型
-
确定何时重用高维或低维潜在空间
TensorFlow 和 TF.Keras 支持广泛的预构建和预训练模型。预训练模型可以直接使用,而预构建模型则可以从零开始训练。通过替换任务组,预训练模型也可以重新配置以执行任何数量的任务。用重新训练替换或重新配置任务组的过程称为迁移学习。
从本质上讲,迁移学习意味着将解决一个任务的知识迁移到解决另一个任务。与从头开始训练模型相比,迁移学习的优势是新的任务可以更快地训练,并且需要的数据更少。把它看作是一种重用:我们正在重用带有其学习权重的模型。
你可能会问,我能否将一个模型架构学习到的权重重用于另一个模型?不,两个模型必须是相同的架构,例如 ResNet50 到 ResNet50。另一个常见的问题是:我能否将学习到的权重重用于任何不同的任务?你可以,但结果将取决于预训练模型的领域和新数据集之间的相似程度。所以我们真正所说的学习权重是指学习到的基本特征、相应的特征提取和潜在空间表示——表示学习。
让我们看看几个例子,看看迁移学习是否会产生期望的结果。假设我们有一个针对水果种类和品种的预训练模型,我们还有一个针对蔬菜种类和品种的新数据集。高度可能的是,水果的学习表示可以用于蔬菜,我们只需要训练任务组。但如果我们的新数据集包括卡车和面包车的型号和制造商。在这种情况下,数据集领域之间的差异非常大,水果学习到的表示不太可能用于卡车和面包车。在类似领域的情况下,我们希望新模型执行的任务在领域上与原始模型训练的数据相似。
另一种学习表示的方法是使用在大量不同图像类别上训练的模型。许多 AI 公司提供这种类型的迁移学习服务。通常,他们的预训练模型是在数万个图像类别上训练的。这里的假设是,由于这种广泛的多样性,学习到的表示中的一部分可以在任何任意新的数据集上重用。缺点是,为了覆盖如此广泛的多样性,潜在空间必须非常大——因此你最终得到的是一个在任务组中非常大的模型(过参数化)。
第三种方法是在参数高效、窄域训练模型和大规模训练模型之间找到一个合适的平衡点。例如,ResNet50 和更近期的 EffcientNet-B7 都是使用包含 1000 个不同类别图像的 ImageNet 数据集进行预训练的。DIY 迁移学习项目通常使用这些模型。例如,ResNet50 具有合理高效的潜在空间,但足够大,可以在任务组件之前用于迁移学习到各种图像分类数据集;潜在空间由 2048 个 4×4 特征图组成。
让我们总结这三种方法:
-
相似领域迁移:
-
参数高效、窄域预训练模型
-
重新训练新的任务组件
-
-
不同领域迁移:
-
参数过剩、窄域预训练模型
-
使用其他组件的微调重新训练新的任务组件
-
-
通用迁移
-
参数过剩、通用领域预训练模型
-
重新训练新的任务组件
-
预训练模型也可以在迁移学习中重复使用,以从预训练模型学习不同类型的任务。例如,假设我们有一个预训练模型,它可以从房屋前外部的图片中分类建筑风格。现在假设我们想要学习预测房屋的售价。很可能,基本特征、特征提取和潜在空间会转移到不同类型的任务上,例如回归器——一个输出单个实数的模型(例如,房屋的售价)。如果其他任务类型也可以使用原始数据集进行训练,那么这种将迁移学习应用于其他任务类型通常是可能的。
本章介绍了从公共资源中获取预构建和预训练的 SOTA 模型:TF.Keras 和 TensorFlow Hub。然后我将向您展示如何直接使用这些模型。最后,您将学习各种使用预训练模型进行迁移学习的方法。
11.1 TF.Keras 预构建模型
TF.Keras 框架附带预构建模型,您可以使用它们直接训练新模型,或者修改和/或微调以进行迁移学习。这些模型基于图像分类的最佳模型,在 ImageNet 等竞赛中获奖的模型,这些模型在深度学习研究论文中被频繁引用。
预构建 Keras 模型的文档可以在 Keras 网站上找到(keras.io/api/applications/)。表 11.1 列出了 Keras 预构建模型架构。
表 11.1 Keras 预构建模型
| 模型类型 | SOTA 模型架构 |
|---|---|
| 顺序 CNN | VGG16, VGG19 |
| 残差 CNN | ResNet, ResNet v2 |
| 宽残差 CNN | ResNeXt, Inception v3, InceptionResNet v2 |
| 交替连接的 CNN | DenseNet, Xception, NASNet |
| 移动 CNN | MobileNet, MobileNet v2 |
预构建的 Keras 模型是从keras.applications模块导入的。以下是可以导入的预构建 SOTA 模型的示例。例如,如果您想使用 VGG16,只需将 VGG19 替换为 VGG16 即可。一些模型架构可以选择不同数量的层,例如 VGG、ResNet、ResNeXt 和 DenseNet。
from tensorflow.keras.applications import VGG19
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications import InceptionV3
from tensorflow.keras.applications import InceptionResNetV2
from tensorflow.keras.applications import DenseNet121
from tensorflow.keras.applications import DenseNet169
from tensorflow.keras.applications import DenseNet201
from tensorflow.keras.applications import Xception
from tensorflow.keras.applications import NASNetLarge
from tensorflow.keras.applications import NASNetMobile
from tensorflow.keras.applications import MobileNet
11.1.1 基础模型
默认情况下,TF.Keras 预构建模型是完整的但未训练的,这意味着权重和偏差是随机初始化的。每个未训练的预构建 CNN 模型都针对特定的输入形状(见文档)和输出类数量进行配置。在大多数情况下,输入形状是(224, 224, 3)或(299, 299, 3)。模型还将以通道优先的格式接收输入,例如(3, 224, 224)和(3, 299, 299)。输出类数量通常是 1000,这意味着模型可以识别 1000 个常见的图像标签。这些预构建但未训练的模型本身可能对您不太有用,因为您必须在一个具有相同数量标签(1000)的数据集上完全训练它们。了解这些预构建模型的内容很重要,这样您就可以使用预训练的权重、新的任务组件或两者结合来重新配置。我们将在本章中涵盖所有三种后续的重新配置。
图 11.1 展示了预构建 CNN 模型的架构。该架构包括为输入形状预设的茎卷积组、一个用于更多卷积组(学习者)的预设、瓶颈层以及预设为 1000 个类别的分类器层。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F01_Ferlitsch.png
列表 11.1 以深灰色显示任务组层的预构建 CNN 模型架构
预构建模型没有分配损失函数和优化器。在使用它们之前,我们必须发出compile()方法来分配损失、优化器和性能度量。在下面的代码示例中,我们首先导入并实例化一个 ResNet50 预构建模型,然后编译模型:
from tensorflow.keras.applications import ResNet50
model = ResNet50() ❶
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) ❷
❶ 获取一个完整且未训练的预构建 ResNet50 模型
❷ 将模型编译为用于数据集的分类器
以这种方式使用预构建模型相当有限,不仅因为输入大小固定,而且分类器的类别数量也是固定的,即 1000。您需要完成的任何任务很可能不会使用默认配置。接下来,我们将探讨配置预构建模型以执行各种任务的方法。
11.1.2 用于预测的预训练 ImageNet 模型
所有预构建的模型都附带从ImageNet 2012数据集预训练的权重和偏差,该数据集包含 1000 个类别中的 120 万张图像。如果你的需求仅仅是预测图像是否在 ImageNet 数据集的 1000 个类别中,你可以直接使用预训练的预构建模型。标签标识符到类名的映射可以在 GitHub 上找到(gist.github.com/yrevar/942d3a0ac09ec9e5eb3a)。类别的例子包括秃鹰、卫生纸、草莓和气球等。
让我们使用预训练的 ResNet 模型,该模型使用 ImageNet 权重进行预训练,来对大象的图像进行分类(或预测)。以下是步骤,一步一步来:
-
preprocess_input()方法将根据预构建的 ResNet 模型使用的方法对图像进行预处理。 -
decode_predictions()方法将标签标识符映射回类名。 -
使用 ImageNet 权重实例化预构建的 ResNet 模型。
-
使用 OpenCV 读取大象的图像,并将其调整大小为(224, 224)以适应模型的输入形状。
-
然后使用模型的
preprocessed_input()方法对图像进行预处理。 -
然后将图像重塑为一批。
-
然后使用
predict()方法通过模型对图像进行分类。 -
然后使用
decode_predictions()将前三个预测标签映射到其类名,并打印出来。在这个例子中,我们可能会看到非洲象作为最高预测。
图 11.2 展示了 TF.Keras 预训练模型及其伴随的预处理输入和后处理输出函数。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F02_Ferlitsch.png
列表 11.2 TF.Keras 预训练模型及其伴随的预处理输入和后处理输出特定函数
现在我们来看看如何编写这个过程:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet import preprocess_input,
decode_predictions
model = ResNet50(weights='imagenet') ❶
image = cv2.imread('elephant.jpg', cv2.IMREAD_COLOR) ❷
image = cv2.resize(image, (224, 224), cv2.INTER_LINEAR) ❸
image = preprocess_input(image) ❹
image = image.reshape((-1, 224, 224, 3)) ❺
predictions = model.predict(image) ❻
print(decode_predictions(predictions, top=3)) ❼
❶ 获取在 ImageNet 上预训练的 ResNet50 模型
❷ 读取图像并将其作为 NumPy 数组预测到内存中
❸ 将图像调整大小以适应预训练模型的输入形状
❹ 使用与预训练模型相同的图像处理方法对图像进行预处理
❺ 将单个图像形状(224, 224, 3)重塑为单个图像的一批(1, 224, 224, 3)以供 predict()方法使用
❻ 调用 predict()方法对图像进行分类
❽ 使用预训练模型的解码函数根据预测标签显示类名
11.1.3 新的分类器
在所有预构建模型中,可以移除最终的分类器层并替换为新的分类器——以及另一个任务,如回归器。然后,可以使用新的分类器来训练预构建模型以适应新的数据集和类别集。例如,如果你有一个包含 20 种面条菜肴的数据集,你只需移除现有的分类器层,用新的 20 节点分类器层替换它,编译模型,并用面条菜肴数据集进行训练。
在所有预构建的模型中,分类器层被称为顶层。对于 TF.Keras 预构建模型,输入形状默认为(224, 224, 3),输出层的类别数为 1000。当你实例化一个 TF.Keras 预构建模型时,你会设置参数include_top为False以获取一个不带分类器层的模型实例。另外,当include_top=False时,我们可以使用参数input_shape指定模型的不同输入形状。
现在我们来描述这个流程及其在我们 20 种面条菜品分类器中的应用。假设你拥有一家面条餐厅,厨师们不断地将各种新鲜烹制的面条菜品放在点餐柜台上。顾客可以挑选任何菜品,为了简化起见,让我们假设所有面条菜品的价格相同。收银员只需要计算面条菜品的数量。但你仍然有一些问题需要解决。有时你的厨师准备过多的一种或多种菜品,这些菜品变凉后不得不丢弃,因此你损失了收入。其他时候,你的厨师准备得太少的一种或多种菜品,顾客因为他们的菜品不可用而去了另一家餐厅——这是一个机会损失的情况。
为了解决这两个问题,你计划在结账处放置一个摄像头,并在丢弃冷面条菜品的烹饪区域放置另一个摄像头。你希望摄像头能够实时分类购买的面条菜品和丢弃的菜品,并将这些信息显示给厨师,以便他们更好地估计需要准备哪些菜品。
让我们开始实施你的计划。首先,因为你是一家现有的面条餐厅,你雇佣了一个人来拍摄放在点餐柜台上的菜品照片。当拍照时,厨师会喊出菜品的名字,这个名字会与照片一起记录。假设在一天的业务结束时,你的面条菜品数量为 500 种。假设菜品的分布相当均匀,这将给你平均每种面条菜品 25 张照片。这可能看起来每个类别的数量很少,但既然它们是你的菜品,背景总是相同的,这可能是足够的。现在你只需要从音频录音中标记照片。
现在你已经准备好进行训练了。你从 TF.Keras 获取一个预构建的模型,并指定include_top=False以删除 1000 类分类器的密集层——你将随后用 20 节点的密集层替换它。因为你移动很多面条菜品,所以你希望模型预测速度快,因此你想要减少参数数量,同时不影响模型的准确性。你不再从(224, 224, 3)大小的 ImageNet 进行预测,而是指定input_shape=(100, 100, 3)以改变模型的输入向量大小为(100, 100, 3)。
我们也可以在预构建模型中删除最终的展平/池化层(瓶颈层),通过设置参数 pooling=None 来替换成你自己的。
图 11.3 描述了一个可重构的预构建 CNN 模型架构。它由一个可配置输入大小的茎卷积组、一个或多个卷积组(学习器)以及可选的可配置瓶颈层组成。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F03_Ferlitsch.png
列表 11.3 在这个没有分类器层的可重构预构建模型架构中,保留池化层是可选的。
至于输入形状,预构建模型的文档对最小输入形状大小有限制。对于大多数模型,这是 (32, 32, 3)。我通常不建议以这种方式使用预构建模型,因为对于这些架构中的大多数,全局平均池化层(瓶颈层)之前的最终特征图将是 1 × 1(单像素)特征图——本质上丢失了所有空间关系。然而,研究人员发现,当与 CIFAR-10 和 CIFAR-100(32, 32, 3)图像一起使用时,他们能够在进入竞赛级(如 ImageNet)图像数据集(224, 224, 3)之前找到良好的超参数设置。
在下面的代码中,我们实例化了一个预构建的 ResNet50 模型,并用一个新的分类器替换了它,用于我们的 20 种面条菜肴示例:
-
我们使用参数
include_top=False移除了现有的 1000 个节点的分类器。 -
我们使用参数
input_shape将输入形状设置为 (100, 100, 3),以适应较小的输入尺寸。 -
我们决定保留最终的池化/展平层(瓶颈层),将其作为全局平均池化层,参数为
pooling。 -
我们添加了一个替换的密集层,包含 20 个节点,对应于面条菜肴的数量,以及一个 softmax 激活函数作为顶层。
-
预构建 ResNet50 模型的最后一个(输出)层是
model.output。这对应于瓶颈层,因为我们删除了默认的分类器。 -
我们将预构建 ResNet50 的
model.output绑定为替换密集层的输入。
-
-
我们构建了模型。输入是 ResNet 模型的输入,即
models.input。 -
最后,我们编译模型以进行训练,并将损失函数设置为
categorical_crossentropy,优化器设置为adam,这是图像分类模型的最佳实践。
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense
model = ResNet50(include_top=False, input_shape=(100, 100, 3), pooling='avg') ❶
outputs = Dense(20, activation='softmax')(model.output) ❷
model = Model(model.input, outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) ❸
❶ 获取输入形状为 (100,100,3) 且没有最终分类器的预构建模型
❷ 添加了 20 个类别的分类器
❸ 编译模型以进行训练
对于大多数 TF.Keras 预构建模型,瓶颈层是一个全局平均池化层。这个层既作为特征图的最终池化层,又作为一个展平操作,将特征图转换为 1D 向量。在某些情况下,我们可能想用我们自己的自定义最终池化/展平层替换这个层。在这种情况下,我们要么指定参数 pooling=None,要么不指定它,这是默认设置。那么我们为什么要这样做呢?
为了回答这个问题,让我们回到我们的面条菜肴。假设当您训练模型时,您得到了 92%的准确率,并希望做得更好。首先,您决定添加图像增强。嗯,我们可能不会考虑水平翻转,因为面条菜肴永远不会被倒着看到!同样,垂直翻转可能也不会有帮助,因为面条碗相当均匀(没有镜像)。我们可以跳过旋转,因为面条碗相当均匀,我们跳过缩放,因为相机到菜肴的位置是固定的。嗯,所以您问,还有什么?
关于移动碗的位置怎么样,因为碗在结账和扔掉柜台时都会移动?您这样做并得到了 94%的准确率。但您希望更高的准确率。凭直觉,我们推测可能特征信息保留得不够,当每个最终特征图通过默认的 GlobalAveragePooling2D 池化减少到一个像素,然后展平成一个 1D 向量时。您查看您的模型摘要,看到最终特征图的大小是 4 × 4。因此,您决定取消默认池化,并用步长为 2 的 MaxPooling2D 替换它,这样每个特征图将减少到 2 × 2,4 个像素而不是一个像素,然后进行展平成一个 1D 向量。
在这个代码示例中,我们用最大池化 (outputs = MaxPooling2D(model.outputs)) 和展平 (outputs = Flatten(outputs)) 替换了瓶颈层,用于我们的 20 种面条菜肴分类器:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
model = ResNet50(include_top=False, input_shape=(100, 100, 3), pooling=None) ❶
outputs = MaxPooling2D(model.output) ❷
outputs = Flatten()(ouputs) ❷
outputs = Dense(20, activation='softmax')(outputs) ❸
model = Model(model.input, outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
❶ 获取输入形状为 (100,100,3) 且不带分类器组的预建模型
❷ 将特征图池化并展平成一个 1D 向量
❸ 添加了一个 20 类别的分类器
在本节中,我们介绍了 TF.Keras 的预建模型和预训练模型。总结一下,预建模型是一个现有的模型,通常基于 SOTA 架构,其输入形状和任务组是可重新配置的,且权重未经过训练。预建模型通常用于从头开始训练模型,具有可重用性和可重新配置以适应您的数据集和任务的优势。缺点是架构可能没有针对您的数据集/任务进行调整,因此最终得到的模型在尺寸和准确性方面可能都不够高效。
预训练模型本质上与预建模型相同,只是权重已经使用另一个数据集(如 ImageNet 数据集)进行了预训练。预训练模型用于即插即用预测或迁移学习,具有通过代表性学习重用快速训练新数据集/任务并减少数据量的优势。缺点是预训练的代表性学习可能不适合您的数据集/任务领域。
在下一节中,我们将使用来自 TensorFlow Hub 存储库的预建模型介绍相同的概念。
11.2 TF Hub 预建模型
TensorFlow Hub,或TF Hub,是一个开源公共仓库,包含预构建和预训练模型,比 TF.Keras 更为广泛。TF.Keras 的预构建/预训练模型适合学习和练习迁移学习,但在生产目的上提供的选项过于有限。TF Hub 包含大量预构建的 SOTA 架构、广泛的任务类别、特定领域的预训练权重以及超出 TensorFlow 组织直接提供的模型之外的公共提交。
本节涵盖了图像分类的预构建模型。TF Hub 为每个模型提供两个版本,具体描述如下:
-
用于特定类别的图像分类的模块。这个过程与预训练模型相同。
-
用于提取图像特征向量(瓶颈值)的模块,用于在自定义图像分类器中使用。这些分类器与 TF.Keras 中描述的新分类器相同。
我们将使用两个预构建模型,一个用于开箱即用的分类,另一个用于迁移学习。我们将从 TensorFlow Hub 的预构建模型开源仓库中下载这些模型,该仓库位于www.tensorflow.org/hub。
要使用 TF Hub,您首先需要安装tensorflow_hub Python 模块:
pip install tensorflow_hub
在您的 Python 脚本中,通过导入tensorflow_hub模块来访问 TF Hub:
import tensorflow_hub as hub
您现在已设置好下载我们两个模型。
11.2.1 使用 TF Hub 预训练模型
与 TF.Keras 相比,TF Hub 在可加载的模型格式类型方面非常灵活:
-
TF2.x SavedModel—在本地、REST 或云上的微服务、桌面/笔记本电脑或工作站中使用。
-
TF Lite—在移动或内存受限的 IoT 设备上的应用程序服务中使用。
-
TF.js—在客户端浏览器应用程序中使用。
-
Coral—优化用于在 Coral Edge/IoT 设备上作为应用程序服务使用。
本节将仅涵盖 TF 2.x 的 SavedFormat 模型。要加载一个模型,您需要执行以下操作:
-
获取 TF Hub 仓库中图像分类器模型的 URL。
-
使用
hub.KerasLayer()从指定的 URL 指定的仓库中检索模型数据。 -
通过使用 TF.Keras sequential API 从模型数据构建一个 TF.Keras SavedModel。
-
将输入形状指定为(224, 224, 3),这与预训练模型在 ImageNet 数据库上训练的输入形状相匹配。
model_url = "https://tfhub.dev/google/imagenet/resnet_v2_50/classification/4" ❶
model = tf.keras.Sequential([hub.KerasLayer(model_url,
input_shape=(224,224,3))]) ❷
❶ TF Hub 仓库中 ResNet50 v2 模型数据的存储位置
❷ 从模型数据检索并构建 SavedModel 格式的模型
当您执行model.summary()时,输出将如下所示:
Layer (type) Output Shape Param #
=================================================================
keras_layer_7 (KerasLayer) (None, 1001) 25615849
=================================================================
Total params: 25,615,849
Trainable params: 0
Non-trainable params: 25,615,849
现在,您可以使用该模型进行预测,这被称为推理。图 11.4 描述了使用 TF Hub ImageNet 预训练模型进行预测的以下步骤:
-
获取 ImageNet 的标签(类别名称)信息,以便我们将预测的标签(数字索引)转换为类别名称。
-
预处理图像以预测以下内容:
-
将图像输入调整大小以匹配模型的输入:(224, 224, 3)。
-
标准化图像数据:除以 255。
-
-
对图像调用
predict()。 -
使用
np.argmax()返回最高概率的标签索引。 -
将预测的标签索引转换为相应的类名。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F04_Ferlitsch.png
列表 11.4 使用 TF Hub 的 ImageNet 预训练模型预测标签,然后使用 ImageNet 映射显示预测的类名
这里是这些五个步骤的一个示例实现。
path = tf.keras.utils.get_file('ImageNetLabels.txt',
'https://storage.googleapis.com/download.tensorflow.org/data/
ImageNetLabels.txt')
imagenet_labels = np.array(open(path).read().splitlines()) ❶
import cv2
import numpy as np
data = cv2.imread('apple.png') ❷
data = cv2.resize(data, (224, 224)) ❷
data = (data / 255.0).astype(np.float32) ❷
p = model.predict(np.asarray([data])) ❸
y = np.argmax(p) ❸
print(imagenet_labels[y]) ❹
❶ 获取从 ImageNet 标签索引到类名的转换
❷ 预处理图像以进行预测
❸ 使用模型进行预测
❹ 将预测的标签索引转换为类名
11.2.2 新的分类器
对于为预训练模型构建新的分类器,我们加载相应的模型 URL,表示为模型的特征向量版本。这个版本加载了预训练模型,但没有模型顶部或分类器。这允许你添加自己的顶部或任务组。模型的输出是输出层。我们还可以指定一个与 TF Hub 模型默认输入形状不同的新输入形状。
以下是一个加载预训练 ResNet50 v2 模型特征向量版本的示例实现,我们将添加自己的任务组件以训练 CIFAR-10 模型。由于我们的 CIFAR-10 输入大小与 TF Hub 的 ResNet50 v2 版本不同,其大小为(224, 224, 3),因此我们还可以选择指定输入形状:
-
获取 TF Hub 存储库中图像分类器模型的 URL。
-
使用
hub.KerasLayer()从由 URL 指定的存储库中检索模型数据。 -
为 CIFAR-10 数据集指定新的输入形状为(32, 32, 3)。
f_url = "https://tfhub.dev/google/imagenet/resnet_v2_50/feature_vector/4" ❶
f_layer = hub.KerasLayer(f_url, input_shape=(32,32,3)) ❷
❶ TF Hub 存储库中 ResNet50 v2 特征向量版本模型数据的存储位置
❷ 将模型数据作为 TF.Keras 层检索并设置输入形状
这里是构建 CIFAR-10 新分类器的一个示例实现,格式为 SavedModel:
-
使用顺序 API 创建 SavedModel。
-
将预训练的 ResNet v2 的特征向量版本指定为模型底部。
-
指定一个有 10 个节点(每个 CIFAR-10 类别一个)的密集层作为模型顶部。
-
-
编译模型。
model = tf.keras.Sequential([
f_layer,
Dense(10, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam',
metrics=['acc'])
当你执行 model.summary() 时,输出将如下所示:
Layer (type) Output Shape Param #
=================================================================
keras_layer_4 (KerasLayer) (None, 2048) 23561152
_________________________________________________________________
dense_2 (Dense) (None, 10) 20490
=================================================================
Total params: 23,581,642
Trainable params: 20,490
Non-trainable params: 23,561,152
到目前为止,我们已经涵盖了使用预训练模型进行即插即用预测和使用可重新配置的预构建模型进行更方便的新模型训练。接下来,我们将介绍如何使用和重新配置预训练模型以实现更高效的训练并减少新任务所需的数据。
11.3 领域间的迁移学习
在迁移学习中,我们使用预训练模型完成一个任务,并重新训练分类器和/或微调层以完成新任务。这个过程与我们刚刚在预构建模型上构建新分类器类似,但除此之外,模型是从头开始完全训练的。
迁移学习有两种一般方法:
-
相似任务——预训练数据集和新数据集来自相似的域(例如水果到蔬菜)。
-
不同任务——预训练数据集和新数据集来自不同的域(例如水果和卡车/面包车)。
11.3.1 相似任务
如本章前面所讨论的,在决定方法时,我们查看源(预训练)图像域和目标(新)域的相似性。越相似,我们可以重用更多现有底层而无需重新训练。例如,如果我们有一个在水果上训练的模型,那么预训练模型的底层所有层很可能可以重用而无需重新训练来构建一个用于识别蔬菜的新模型。
我们假设在底层学习到的粗略和详细特征对于新分类器将是相同的,并且可以在进入最顶层(的)分类之前直接重用。让我们考虑一些我们可以推测水果和蔬菜来自非常相似域的原因。两者都是天然食品。虽然水果通常在地面上生长,而蔬菜在地下生长,但它们在形状和质地上有相似的物理特性,以及如茎和叶等装饰。
当源域和目标域具有这种高水平相似性时,我们通常可以用新的分类器层替换现有的最顶层分类器层,冻结底层层,并仅训练分类器层。由于我们不需要学习其他层的权重/偏差,因此我们可以用大量更少的数据和更少的周期来训练新域的模型。
虽然拥有更多数据总是更好的,但相似源域和目标域之间的迁移学习提供了使用大量更小数据集进行训练的能力。关于数据集最小尺寸的两个最佳实践如下:
-
每个类别(标签)的大小是源数据集的 10%。
-
每个类别(标签)至少有 100 张图片。
与新分类器所示的方法相反,我们在训练之前修改代码以冻结所有位于最顶层分类器层之前的层。冻结可以防止这些层(的)权重/偏差在分类器(最顶层)层的训练期间被更新(重新训练)。在 TF.Keras 中,每个层都有trainable属性,默认为True。
图 11.5 描述了预训练模型分类器层的重新训练;以下是步骤:
-
使用具有预训练权重/偏差的预构建模型(ImageNet 2012),
-
从预构建模型中删除现有的分类器(最顶层)。
-
冻结剩余的层。
-
添加一个新的分类器层。
-
通过迁移学习训练模型。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F05_Ferlitsch.png
列表 11.5 当源域和目标域相似时,只有分类器权重被重新训练,而剩余模型底层的权重被冻结。
这里是一个示例实现:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
model = ResNet50(include_top=False, pooling='avg', weights='imagenet') ❶
for layer in model.layers: ❷
layer.trainable = False ❷
output = Dense(20, activation='softmax')(model.output) ❸
model = Model(model.input, output) ❹
model.compile(loss='categorical_crossentropy', optimizer='adam', ❹
metrics=['accuracy']) ❹
❶ 获取不带分类器的预训练模型并保留全局平均池化层
❷ 冻结剩余层的权重
❸ 添加一个 20 个类别的分类器
❹ 编译模型以进行训练
注意,在这个代码示例中,我们保留了原始输入形状(224, 224, 3)。在实际操作中,如果我们更改输入形状,现有的训练权重/偏差将不会匹配它们训练的特征提取分辨率。在这种情况下,最好将其作为一个独立任务案例处理。
11.3.2 独立任务
当图像数据集的源域和目标域不同,例如我们例子中的水果和卡车/面包车时,我们开始与之前相似任务方法中的相同步骤,然后继续微调底部层。步骤,如图 11.6 所示,通常如下:
-
添加一个新的分类器层并冻结剩余的底部层。
-
训练新的分类器层以达到目标周期数。
-
重复进行微调:
-
解冻下一个最底部的卷积组(从顶部到底部的方向)。
-
训练几个周期以进行微调。
-
-
在卷积组微调后:
-
解冻卷积主干组。
-
训练几个周期以进行微调。
-
在图 11.6 中,你可以看到步骤 2 到 4 的训练周期:在周期 1 中重新训练分类器,在周期 2 到 4 中按顺序微调卷积组,在周期 5 中微调主干。请注意,这与源域和目标域相似且我们只微调分类器的情况不同。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F06_Ferlitsch.png
列表 11.6 在这种独特的源到目标迁移学习中,卷积组逐步微调。
以下是一个示例实现,演示了对新分类器级别(周期 1)的粗粒度训练,然后是每个卷积组(周期 2 到 4)的微调,最后是主干卷积组(周期 5)。步骤如下:
-
模型底部的层被冻结(
layer.trainable = False)。 -
在模型顶部添加一个 20 个类别的分类器层。
-
分类器层使用 50 个周期进行训练:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
model = ResNet50(include_top=False, pooling='avg', weights='imagenet')
for layer in model.layers: ❶
layer.trainable = False ❶
output = Dense(20, activation='softmax')(model.output) ❷
model = Model(model.input, output)
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) ❸
model.fit(x_data, y_data, batch_size=32, epochs=50, validation_split=0.2) ❹
❶ 冻结所有预训练层的权重
❷ 添加一个未训练的分类器
❸ 编译模型以进行训练
❹ 粗粒度训练新的分类器
在分类器训练后,模型进行微调(周期 2 到 4):
-
从底部到顶部遍历层,识别主干卷积和每个 ResNet 组的结束,这通过一个
Add()层检测到。 -
对于每个卷积组,构建该组中每个卷积层的列表。
-
以相反的顺序构建组列表(
groups.insert(0, conv2d)): 从顶部到底部。 -
从顶部到底部遍历卷积组,并逐步训练每个组和其前驱,共五个周期。
以下是对这四个步骤的示例实现。
stem = None
groups = []
conv2d = []
first_conv2d = True
for layer in model.layers:
if type(layer) == layers.convolutional.Conv2D:
if first_conv2d == True: ❶
stem = layer
first_conv2d = False
else: ❷
conv2d.append(layer)
elif type(layer) == layers.merge.Add: ❸
groups.insert(0, conv2d) ❹
conv2d = []
for i in range(1, len(groups)): ❺
for layer in groups[i]: ❺
layer.trainable = True ❺
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) ❻
❻
model.fit(x_data, y_data, batch_size=32, epochs=5) ❻
❶ 在 ResNet50 中,第一个 Conv2D 是主干卷积层。
❷ 为每个卷积组保持卷积层的列表
❸ 残差网络中的每个卷积组都以一个 Add()层结束。
❹ 以相反的顺序维护列表(最上面的卷积组是列表的顶部)
❺ 一次解冻一个卷积组(从上到下)
❻ 微调(训练)该层
最后,主干卷积以及整个模型额外训练了五个周期(周期 5)。以下是最后一步的示例实现:
stem.trainable = True ❶
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
model.fit(x_data, y_data, batch_size=32, epochs=5, validation_split=0.2) ❷
❶ 解冻主干卷积
❷ 进行最终微调
在此示例中,当解冻层进行微调时,必须在发出下一个训练会话之前重新编译模型。
11.3.3 特定领域权重
在之前的迁移学习示例中,我们使用从 ImageNet 2012 数据集学习到的权重初始化了模型的冻结层。但让我们假设你想要使用除 ImageNet 2012 之外特定领域的预训练权重,就像我们关于水果的例子一样。
例如,如果你正在构建一个植物领域的域迁移模型,你可能需要树木、灌木、花朵、杂草、叶子、树枝、水果、蔬菜和种子的图像。但我们不需要每种可能的植物类型——只需要足够的来学习基本特征和特征提取,这些可以推广到更具体和更全面的植物领域。你也可能考虑你想要推广的背景。例如,目标领域可能是室内植物,因此你有家庭室内背景,或者它可能是产品,因此你想要一个货架背景。你应该在源域中有一定数量的这些背景,这样源模型就学会了从潜在空间中过滤掉它们。
在下一个代码示例中,我们首先为特定领域(在这种情况下,是水果产品)训练一个预构建的 ResNet50 架构;然后,我们使用预训练的、特定领域的权重和初始化来训练另一个在类似领域(例如,蔬菜)中的 ResNet50 模型。
图 11.7 描述了将特定领域的权重从水果迁移到类似领域(蔬菜)并进行微调的过程如下:
-
实例化一个未初始化的 ResNet50 模型,不带分类器和池化层,我们将其指定为基础模型。
-
保存基础模型架构以供以后在迁移学习中重复使用(
produce-model)。 -
添加一个分类器(
Flatten和Dense层)并针对特定的(源)领域(例如,产品)进行训练。 -
保存训练模型的权重(
produce-weights)。 -
加载基础模型架构(
model-produce),它不包含分类器层。 -
使用源域的预训练权重初始化基础模型架构(
model-produce)。 -
为新类似领域添加一个分类器。
-
训练新类似领域的模型/分类器。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F07_Ferlitsch.png
列表 11.7:与源域类似领域的预训练模型之间的迁移学习
这里是一个将特定领域权重从水果迁移到类似领域蔬菜的迁移学习的示例实现:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras import Model
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import load_model
model = ResNet50(include_top=False, pooling=None, input_shape=(100, 100, 3))
model.save('produce-model') ❶
output = Flatten(name='bottleneck')(model.output) ❷
output = Dense(20, activation='softmax')(output) ❷
model.save_weights('produce-weights') ❸
model = load_model('produce-model') ❹
model.load_weights('produce-weights') ❹
output = Flatten(name='bottleneck')(model.output) ❺
output = Dense(20, activation='softmax')(output) ❺
model = Model(model.input, output) ❻
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) ❼
❶ 保存基础模型
❷ 添加分类器
❸ 保存训练好的模型权重
❹ 训练模型
❺ 重新使用基础模型和训练好的权重
❻ 添加分类器
❼ 编译并训练新数据集的新模型
11.3.4 领域迁移权重初始化
另一种迁移学习的形式是将特定领域权重迁移到作为我们将重新训练的模型的权重初始化。在这种情况下,我们试图改进基于随机权重分布算法(例如,对于 ReLU 激活函数的 He-normal)的初始化器,而不是使用彩票假设或数值稳定性。让我们再次看看我们的产品示例,并假设我们已经为数据集实例(如水果)完全训练了一个模型。我们不是从完全训练的模型实例中迁移权重,而是使用一个更早的检查点,其中我们已经建立了数值稳定性。我们将重用这个更早的检查点作为重新训练领域相似数据集(如蔬菜)的初始化器。
转移特定领域权重是一种一次性权重初始化方法。假设是生成一组足够泛化的权重初始化,以便模型训练将导致最佳局部(或全局)最优解。理想情况下,在初始训练期间,模型的权重将执行以下操作:
-
指向收敛的一般正确方向
-
防止过度泛化以避免陷入任意局部最优解
-
作为单次(一次性)训练会话的初始化权重,该会话将收敛到最佳局部最优解
图 11.8 描述了权重初始化的领域迁移。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH11_F08_Ferlitsch.png
列表 11.8 使用类似领域的早期检查点作为新模型完全重新训练的权重初始化
这种权重初始化的预训练步骤如下:
-
实例化一个 ResNet50 模型,具有随机权重分布(例如,Xavier 或 He-normal)。
-
使用高水平的正则化(l2(0.001))以防止拟合数据和小学习率。
-
运行几个时代(未展示)。
-
使用模型方法
save_weights()保存权重。
from tensorflow.keras.regularizers import l2
model = ResNet50(include_top=False, pooling='avg', input_shape=(100, 100, 3)) ❶
model.save('base_model') ❷
output = layers.Dropout(0.75)(model.output) ❸
output = layers.Dense(20, activation='softmax', ❸
kernel_regularizer=l2(0.001))(output) ❸
model = Model(model.input, output) ❸
model.save_weights('weights-init') ❹
❶ 使用默认权重初始化(He-normal)实例化基础模型
❷ 保存模型
❸ 在基础 ResNet 模型中添加 dropout 层和分类器,并使用激进的正则化级别
❹ 预训练后保存模型和权重
在下一个代码示例中,我们使用保存的预训练权重开始一个完整的训练会话。首先我们加载未初始化的基础模型(base_model),它不包括最顶层。然后我们将保存的预训练权重(weights-init)加载到模型中。接下来,我们添加一个新的最顶层,它是一个有 20 个节点的密集层,用于 20 个类别。我们构建新的模型,编译,然后开始完整的训练。
model = load_model('base_model') ❶
model.load_weights('weights-init') ❷
output = Dense(20, activation='softmax')(model.output) ❸
model = Model(model.input, output) ❹
model.compile(loss='categorical_crossentropy', optimizer='adam', ❹
metrics=['accuracy']) ❹
❶ 重新加载基础模型
❷ 使用域迁移权重初始化来初始化权重
❸ 添加不带 dropout 的分类器
❹ 编译并训练新模型
11.3.5 负迁移
在某些情况下,我们会发现迁移学习的结果比从头开始训练的准确度低:当使用预训练模型来训练新模型时,训练过程中的整体准确度低于如果没有预训练模型时的准确度。这被称为负迁移。
在这种情况下,源域和目标域非常不同,以至于源域的学习权重不能在目标域上重用。此外,当权重被重用时,模型将不会收敛,甚至可能会发散。一般来说,我们通常可以在五到十个 epoch 内发现负迁移。
11.4 超越计算机视觉
本章讨论的用于计算机视觉的迁移学习方法也适用于 NLU 模型。除了某些术语外,过程是相同的。在 NLU 模型中,移除顶层有时被称为移除头部。
在这两种情况下,你都是在移除所有或部分的任务组件,并用新的任务替换它。你所依赖的是类似于计算机视觉中的潜在空间;中间表示具有学习新任务所必需的上下文(特征)。对于相似任务和不同任务的方 法,在计算机视觉和 NLU 中是相同的。
然而,对于结构化数据来说,情况并非如此。实际上,跨域(数据集)的预训练模型之间不可能进行迁移学习。你可以在同一个数据集上学习不同类型的工作(例如,回归与分类),但你不能在不同特征的数据集之间重用学习到的权重。至少目前还没有一个概念——即具有可跨不同领域(列)的数据集重用基本特征的潜在空间。
摘要
-
来自 TF.Keras 和 TF Hub 模型存储库的预构建和预训练模型可以用于直接用于预测的重用,或者用于迁移学习新的分类器。
-
预训练模型的分类器组可以被替换,无论是通用的还是与类似域的,并且可以在更少的训练时间和更小的数据集上重新训练以适应新域。
-
在迁移学习中,如果新域与之前训练的域相似,则冻结所有层除了新的任务层,并进行微调训练。
-
在迁移学习中,如果新领域与之前训练的领域不同,你需要在重新训练时按顺序冻结和解冻层,从模型底部开始,逐步向上移动。
-
在领域迁移权重中,你使用训练模型的权重作为初始权重,并完全训练一个新的模型。
12 数据分布
本章涵盖了
-
在机器学习中应用分布的统计原理
-
理解精选数据集和非精选数据集之间的差异
-
使用总体、抽样和子总体分布
-
在训练模型时应用分布概念
作为数据科学家和教育工作者,我经常收到软件工程师关于如何提高模型准确性的问题。我给出的五个基本答案,以提高模型的准确性如下:
-
增加训练时间。
-
增加模型的深度(或宽度)。
-
添加正则化。
-
通过数据增强扩展数据集。
-
增加超参数调整。
这些是最有可能需要解决的问题,并且通常解决其中之一或多个将提高模型准确性。但重要的是要理解,准确性的限制最终在于用于训练模型的数据库集。这正是我们要探讨的:数据集的细微差别,以及它们如何以及为什么会影响准确性。而“细微差别”指的是数据的分布模式。
在本章中,我们将深入探讨三种类型的数据分布:总体、抽样和子总体。特别是,我们将研究这些分布如何影响模型在现实世界中对数据的准确泛化能力。你会发现,模型的准确性通常与训练或评估数据集生成的预测不同,这种差异被称为服务偏差和数据漂移。
在本章的后半部分,我们将通过一个实际案例来展示如何在训练过程中将不同的数据分布应用于同一模型,并观察在推理阶段,对真实世界服务偏差和数据漂移的不同影响结果。
要理解分布及其对结果和准确性的影响,我们需要回到基础统计学,这可能是你在高中或大学学过的。术语模型不是由人工智能、机器学习或任何其他计算机技术的新发展创造的。这个术语起源于统计学。作为一个软件工程师,你习惯于编写一个算法,该算法通常具有输入和输出之间的多对一关系。我们通常将这种关系称为输入与输出之间的线性关系——换句话说,输出是确定的。
在统计学中,输出不是确定的,而是一个概率分布。让我们考虑一下抛硬币的情况。你无法编写一个算法来输出任何单次抛硬币的正确结果(正面或反面),因为它不是确定的。但你可以建模单次、十次或上千次抛硬币的概率分布。
12.1 分布类型
统计学领域处理的是非确定性算法,但其结果是概率分布。就像我们的抛硬币例子一样,如果我抛两次硬币,结果不是确定的。相反,一次抛出正面和一次抛出反面的概率是 50%,两次都是正面的概率是 25%,两次都是反面的概率也是 25%。这些算法被称为模型,它们模拟一个行为,使得预测在概率分布上的输出(或结果)。
在本节中,我们考察了在机器学习建模中最常用的三种分布:总体分布、抽样分布和子总体分布。我们的目标是了解每种分布如何影响深度学习模型的训练,特别是它的准确性。
使用神经网络开发模型的深度学习出现于人工智能领域。近年来,统计建模和深度学习这两个独立的领域已经融合在一起,我们现在将它们都归类为机器学习。但无论你是在做我所说的经典机器学习(统计学)还是基于神经网络的深度学习,你能够建模或学习到的限制都归结于数据集。
为了查看这三个分布,我们将使用 MNIST 数据集(keras.io/datasets/)。这个数据集足够小,我们可以用它来演示这些概念,同时给你留下代码示例,你可以复制并使用这些代码,亲眼看到为什么(以及如何)数据是限制。
12.1.1 总体分布
当你构建一个模型,结果发现它没有像你预期的那样在“野外”(在生产环境中)泛化,通常原因之一是你没有理解你所建模的总体分布。
假设你正在构建一个模型,根据身体特征(身高、发色等)预测美国成年男性的鞋码。这个模型的总体分布将是所有美国成年男性。让我强调所有。当我们说一个总体分布时,它包含人口中的每一个例子——整个人口。有了总体分布,我们就知道鞋码的完整分布以及相应的特征(身高、发色等)。
当然,问题是,你不会拥有美国所有成年男性的数据。相反,你将拥有数据的一个子集:我们随机抽取数据的一批(我们称之为随机样本)来确定批次内的分布,你希望这个分布尽可能接近整体人口的分布。
图 12.1 展示了在总体分布内的随机抽样。外圈,标记为总体,代表总体中的所有例子,例如在我们关于美国所有成年男性鞋码的例子中。内圈,标记为随机样本,代表随机选择的一组例子,例如在美国随机选择的一定数量的成年男性。对于总体分布,我们知道诸如确切的大小(成年男性的数量)、平均值(平均鞋码)和标准差(不同尺寸的百分比)等信息。这些在统计学上被称为总体的参数,这是一个确定性分布。假设我们没有总体分布,我们希望使用随机样本来估计参数——这被称为统计量。样本越大、越随机,我们的估计就越有可能接近参数。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F01_Ferlitsch.png
图 12.1 展示了总体分布及其内部的随机抽样
12.1.2 抽样分布
使用抽样分布的目标是拥有足够多的来自总体的随机样本,这样,这些样本内部的分布可以共同用来预测整个总体的分布,从而我们可以将模型推广到总体。这里的关键词是预测,意味着我们从样本中确定一个概率分布,而不是从总体中确定一个确定性分布。
让我们以我们的鞋码例子为例。如果我们只有一个例子,我们可能无法充分地模拟分布的参数。但如果我们有一千个例子,我们可能能够显著提高模拟参数的能力。但是等等,如果那一千个例子并不是真正随机的——比如说它们是从专业运动鞋店的购买中收集的。这些例子可能会倾向于某些非随机例子的特征(特性)。因此,抽样分布中的例子需要是随机选择的。
图 12.2 描述了一个总体抽样分布。一个抽样分布由随机选择的一组例子组成,通常大小相同。例如,我们可能雇佣了不同的调查公司来收集我们的鞋码数据,每个公司使用自己的选择标准。每个公司根据其选择标准收集了一百个随机样本的数据。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F02_Ferlitsch.png
图 12.2:预测总体分布参数的抽样分布
我们可以假设这些单独的随机样本是总体参数的弱预测器。相反,我们将它们视为一个整体。例如,如果我们取每个随机样本均值的平均值,给定足够数量和足够大小的随机样本,我们可以更准确地预测总体的均值。
通常,您用于训练模型的数据库是一个抽样分布,样本量越大,例子越随机,您的模型就越有可能推广到群体的参数。
12.1.3 子群体分布
您需要理解,无论您的数据集有多大、多么全面,它很可能是一个子群体的抽样分布,而不是整个群体。子群体是群体的一部分,由一组特征定义,并且与群体的概率分布不同。例如,在我们的早期成年男性鞋类例子中,假设我们的样本都来自一家专门为职业运动员销售运动鞋的连锁店。有了足够的样本,我们可以开发出一个具有代表性的抽样分布,因此可以预测职业运动员的子群体,但它不太可能代表整个群体。
这与偏差不同,只要我们的意图是模拟该子群体而不是整个群体。当从随机样本批次中抽取时,会出现偏差,无论我们抽取多少,相应的抽样分布都不会代表我们正在模拟的群体——因为我们是从子群体中抽取的随机样本。图 12.3 展示了子群体分布。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F03_Ferlitsch.png
图 12.3 子群体分布
12.2 分布外
假设您已经训练了一个模型并将其部署在数据集上,但它并没有像您的评估数据那样在生产中推广。这个模型可能看到了与训练时不同的例子分布。我们称这种情况为“分布外”,也称为“服务偏差”。换句话说,您的模型是在一个与部署模型看到的不同的子群体分布上训练的。
在本节中,我们将使用 MNIST 数据集来演示在模型部署时如何检测分布外的群体。然后我们将探讨改进模型以推广到分布外群体的方法。我们已在第二章中首次讨论了 MNIST 数据集。我们将从对该数据集的简要回顾开始。
12.2.1 MNIST 精选数据集
MNIST 是一个包含 70,000 个手写数字图像的数据集,每个数字的比例平衡。训练一个模型以在数据集上达到接近 100%的准确率非常容易(因此它是机器学习的“hello, world”示例)。但几乎所有的“实际应用”中的训练模型都会失败——因为 MNIST 中的图像分布是一个子群体。
MNIST 是一个精选的数据集。数据管理员选择了符合一定定义的特征的样本进行包含。换句话说,精选数据集足以代表一个亚群体,可以对该亚群体的参数进行建模,但否则可能不代表整个群体(例如,所有数字)。
在 MNIST 的情况下,每个样本是一个 28-×-28 像素的图像,数字的绘制位于中间。数字是白色的,背景是灰色的,数字周围至少有 4 像素的填充。图 12.4 显示了 MNIST 图像的布局。这个数字 7 的实例只是从数据集中随机选择的任意随机选择,仅用于示例目的。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F04_Ferlitsch.png
图 12.4 MNIST 图像的布局
12.2.2 设置环境
首先,让我们做一下我所说的家务管理。以下是我们将在所有示例中使用的代码片段。它包括导入 TF.Keras API 以设计和训练模型,我们将使用的各种 Python 库,以及最后,加载预建在 TF.Keras API 中的 MNIST 数据集:
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Activation, ReLU,
from tensorflow.keras.layers import MaxPooling2D, Conv2D, Dropout
import numpy as np
import random
import cv2
from tensorflow.keras.datasets import mnist ❶
(x_train, y_train), (x_test, y_test) = mnist.load_data() ❶
❶ 获取 MNIST 的内置数据集
Keras 的数据集是通用格式,因此我们需要进行一些初始数据准备,以便用于训练 DNN 或 CNN。这些准备包括以下内容:
-
像素数据(
x_train和x_test)包含原始 INT8 值(0 到 255)。我们将像素数据归一化到 0 到 1 的 FLOAT32。 -
图像数据矩阵的形状为高度 × 宽度 (H × W)。Keras 期望张量的形状为高度 × 宽度 × 通道。这些是灰度图像,因此我们将训练和测试数据调整为(H × W × 1)。
在准备(我们将在 12.2.3 节中讨论)之前,我们将留出一份数据集的测试和训练数据的副本。
x_test_copy = x_test ❶
x_train_copy = x_train ❶
x_train = (x_train / 255.0).astype(np.float32) ❷
x_test = (x_test / 255.0).astype(np.float32) ❷
x_train = x_train.reshape(-1, 28, 28, 1) ❸
x_test = x_test.reshape(-1, 28, 28, 1) ❸
print("x_train", x_train.shape, "x_test", x_test.shape)
print("y_train", y_train.shape, "y_test", y_test.shape)
❶ 留出原始训练和测试数据的副本
❷ 将像素数据归一化并转换为 32 位浮点数
❸ 调整形状以符合 TF.Keras 模型 API
12.2.3 挑战(在野外)
除了从这个精选数据集中随机选择测试数据(称为保留集)之外,我们还将创建另外两个测试数据集,作为展示训练模型在野外可能看到的示例。这两个额外的数据集,称为反转集和筛选集,将包含训练数据未表示的示例。换句话说,原始 MNIST 数据集是数字群体中的一个亚群体,而我们这两个新的数据集是数字的不同亚群体。反转集和筛选集的分布与 MNIST 数据集不同,因此我们称它们相对于 MNIST 数据集为分布外。
我们将使用这两个额外的测试数据集来展示模型将如何失败,并找到我们可能修改训练和数据集以克服这些局限性的方法。每个集合由什么构成?
-
倒置集——像素数据被倒置,使得图像现在是在白色背景上的灰色数字。
-
平移集——图像向右平移了 4 个像素,因此不再居中。由于至少有 4 个像素的填充,没有任何数字会被裁剪。
图 12.5 是从原始测试数据、倒置测试数据和平移测试数据中选取的单个测试图像的示例。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F05_Ferlitsch.png
图 12.5 原始和野外分布外的示例
在此代码中,我们从原始测试数据集的副本中创建了两个额外的测试数据集:
x_test_invert = np.invert(x_test_copy) ❶
x_test_invert = (x_test_invert / 255.0).astype(np.float32) ❶
x_test_shift = np.roll(x_test_copy, 4) ❷
x_test_shift = (x_test_shift / 255.0).astype(np.float32) ❷
x_test_invert = x_test_invert.reshape(-1, 28, 28, 1)
x_test_shift = x_test_shift.reshape(-1, 28, 28, 1)
❶ “野外”倒置数据
❷ “野外”平移数据
12.2.4 作为 DNN 进行训练
我们将首先基于现有的 MNIST 子集训练一个模型,将准确率与来自同一子集的保留集进行比较,最后测试并比较它们与野外分布数据。
MNIST 非常简单,我们可以用 DNN 构建一个 97%+准确率的分类器。下一个代码示例是一个构建简单 DNN 的函数,包括以下内容:
-
参数
nodes是一个列表,指定每层的节点数。 -
DNN 的输入是形状为 28 × 28 × 1 的图像
-
输入被展平成一个长度为 784 的 1D 向量。
-
每个层后都有一个可选的 dropout(用于正则化)。
-
最后一个有 10 个节点的密集层,带有 softmax 激活函数,是分类器。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F06_Ferlitsch.png
图 12.6 MNIST 模型的可配置 DNN 架构
图 12.6 展示了本例中可配置的 DNN 架构。
def DNN(nodes, dropout=False): ❶
model = Sequential()
model.add(Flatten(input_shape=(28, 28, 1)))
for n_nodes in nodes:
model.add(Dense(n_nodes))
model.add(ReLU())
if dropout:
model.add(Dropout(0.5))
dropout /= 2.0
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']) ❷
model.summary()
return model
❶ 构建简单 DNN 的函数
❷ 编译多类分类器的 DNN
在我们的第一次测试中,我们将数据集在一个包含 512 个节点的单层(不包括输出层)上进行训练。图 12.7 展示了相应的架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F07_Ferlitsch.png
图 12.7 我们第一个 MNIST 模型的单层、512 节点 DNN
下面是构建、训练和评估我们第一次测试模型的代码:
model = DNN([512])
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2) ❶
score = model.evaluate(x_test, y_test, verbose=1) ❷
print("test", score)
❶ 在 MNIST 上训练模型
❷ 评估训练好的模型
summary()方法的输出将如下所示:
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
re_lu_1 (ReLU) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 5130
_________________________________________________________________
activation_1 (Activation) (None, 10) 0
=================================================================
Total params: 407,050
可训练参数的数量是我们模型复杂度的衡量标准,共有 408,000 个参数。我们总共训练了 10 个 epoch(我们将整个训练数据通过模型输入 10 次)。以下是从训练中得到的输出。训练准确率迅速达到 99%+,我们在测试(保留)数据上的准确率接近 98%。
Epoch 1/10
2019-02-08 12:14:59.065963: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA
- 5s - loss: 0.2007 - acc: 0.9409
Epoch 2/10
- 5s - loss: 0.0897 - acc: 0.9743
Epoch 3/10
- 5s - loss: 0.0651 - acc: 0.9817
Epoch 4/10
- 5s - loss: 0.0517 - acc: 0.9853
Epoch 5/10
- 5s - loss: 0.0419 - acc: 0.9887
Epoch 6/10
- 5s - loss: 0.0341 - acc: 0.9913
Epoch 7/10
- 5s - loss: 0.0273 - acc: 0.9928
Epoch 8/10
- 5s - loss: 0.0236 - acc: 0.9939
Epoch 9/10
- 5s - loss: 0.0188 - acc: 0.9953
Epoch 10/10
- 5s - loss: 0.0163 - acc: 0.9961
10000/10000 [==============================] - 0s 21us/step
test [0.11250439590732676, 0.9791]
到目前为止,看起来不错。现在让我们尝试在倒置和平移的测试数据集上使用模型:
score = model.evaluate(x_test_invert, y_test, verbose=1) ❶
print("inverted", score)
score = model.evaluate(x_test_shift, y_test, verbose=1) ❷
print("shifted", score)
❶ 在野外分布的倒置数据集上评估模型
❷ 在野外分布的平移数据集上评估模型
以下是从测试中得到的输出。我们在倒置数据集上的准确率仅为 2%,在平移数据集上表现较好,但只有 41%:
inverted [15.660332287597656, 0.0206]
shifted [7.46930496673584, 0.4107]
发生了什么?对于反转数据集,看起来我们的模型将灰色背景和数字的纯度作为数字识别的一部分来学习。因此,当我们反转数据时,模型完全无法对其进行分类。
对于移动数据集,密集层没有保留像素之间的空间关系。每个像素都是独特的特征。因此,即使像素的微小移动也足以大幅降低准确率。
因此,为了提高准确率,我们可能尝试增加输入层的节点数量——节点越多,学习效果越好。让我们用 1024 个节点重复相同的测试。图 12.8 展示了相应的架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F08_Ferlitsch.png
图 12.8 为我们的第二个 MNIST 模型训练的更宽的单层 1024 节点深度神经网络
下面是构建、训练和评估第二个测试模型的代码:
model = DNN([1024]) ❶
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2)
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 节点数量加倍(变宽)。
model.summary()的输出如下:
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) (None, 784) 0
_________________________________________________________________
dense_3 (Dense) (None, 1024) 803840
_________________________________________________________________
re_lu_2 (ReLU) (None, 1024) 0
_________________________________________________________________
dense_4 (Dense) (None, 10) 10250
_________________________________________________________________
activation_2 (Activation) (None, 10) 0
=================================================================
Total params: 814,090
Trainable params: 814,090
你可以看到,通过将输入层的节点数量加倍,我们也将计算复杂度(可训练参数的数量)加倍。让我们看看这能否提高我们替代测试数据的准确率。
没有,我们在反转数据集上看到了微小的提升,大约 5%,但这太低了,可能只是噪声,而在移动数据集上的准确率大约相同,为 40%。所以增加输入层的节点数量(变宽)并没有帮助过滤掉(未学习)数字的背景和纯度,也没有学习空间关系:
inverted [15.157325344848633, 0.0489]
shifted [7.736222146606445, 0.4038]
另一种我们可能尝试的方法是增加层数(变深)。这次,让我们使用两个 512 节点的层。图 12.9 展示了我们的模型架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F09_Ferlitsch.png
图 12.9 为我们的第三个 MNIST 模型训练的更深的两层深度神经网络(512 + 512 个节点)
下面是构建、训练和评估第三个测试模型的代码:
model = DNN([512, 512]) ❶
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2)
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 增加层数(变深)
model.summary()的输出结果:
Total params: 669,706
Trainable params: 669,706
让我们看看这能否提高我们替代测试数据的准确率:
inverted [14.464950880432129, 0.1025]
shifted [8.786513813018798, 0.3887]
我们在移动数据集上看到了另一个轻微的提升,达到 10%。但这真的有所改善吗?我们有 10 个类别(数字)。如果我们随机猜测,我们会有 10%的时间猜对。这仍然是一个纯粹随机的结果——这里没有学习到任何东西。看起来增加层并没有帮助学习空间关系。
另一种方法可能是添加一些正则化,以防止模型过度拟合训练数据并使其更具泛化能力。我们将使用每层 512 节点的相同两层深度神经网络,并在第一层后添加 50%的 dropout,在第二层后添加 25%的 dropout。过去,在第一层使用更高的 dropout(学习粗糙特征)和在后续层使用较小的 dropout(学习更精细的特征)是一种常见的做法。图 12.10 显示了模型架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F10_Ferlitsch.png
图 12.10 添加 dropout 以改善泛化的 DNN
下面是构建、训练和评估我们第四次测试模型的代码:
model = DNN([512, 512], True) ❶
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2)
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 添加 dropout 进行正则化
让我们看看这能否提高我们备用测试数据上的准确率:
inverted [15.862942279052735, 0.0144]
shifted [8.341207506561279, 0.3965]
没有改进。因此,加宽层、加深层和正则化并没有帮助模型在分布外的测试数据集中识别数字。也许问题在于 DNN 根本不是泛化到分布外模型的正确模型架构。接下来,我们将尝试 CNN 并看看会发生什么。
12.2.5 作为 CNN 的训练
好的,现在让我们在一个卷积神经网络中测试三个数据集的准确率。有了卷积层,我们至少应该学会空间关系。也许卷积层会过滤掉背景以及数字的白色。
以下代码按照以下方式构建我们的 CNN:
-
参数
filters是一个列表,指定每个卷积的过滤器数量。 -
CNN 的输入是形状为 28 × 28 × 1 的图像。
-
每次卷积后,最大池化将特征图大小减少 75%。
-
每个卷积/最大池化层之后发生 25%的 dropout(正则化)。
-
最后一个具有 10 个节点和 softmax 激活函数的密集层是分类器。
def CNN(filters): ❶
model = Sequential()
first = True
for n_filters in filters:
if first:
model.add(Conv2D(n_filters, (3, 3), strides=1, input_shape=(28, 28, 1)))
else:
model.add(Conv2D(n_filters, (3, 3), strides=1))
model.add(ReLU())
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy']) ❷
model.summary()
return model
❶ 构建简单 CNN 的函数
❷ 编译 CNN 以进行多类分类器
让我们从具有单个 16 个过滤器的卷积层的 CNN 开始。图 12.11 说明了模型架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F11_Ferlitsch.png
图 12.11 用于 MNIST 训练的单层 CNN
下面是我们使用 CNN 进行第一次测试的构建、训练和评估模型的代码:
model = CNN([16]) ❶
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2)
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 构建具有 16 个过滤器的 CNN
model.summary()的输出如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
re_lu_1 (ReLU) (None, 26, 26, 16) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 16) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 13, 13, 16) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2704) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 27050
_________________________________________________________________
activation_1 (Activation) (None, 10) 0
=================================================================
Total params: 27,210
Trainable params: 27,210
下面是我们 CNN 训练的结果:
test [0.05741905354047194, 0.9809]
您可以看到,我们可以使用具有许多更少的可训练参数的 CNN(27,000 个参数与超过 400,000 个参数相比)在测试数据上获得相当准确的准确率(98%)。
让我们看看这能否提高我们备用测试数据上的准确率:
inverted [2.1893138484954835, 0.5302]
shifted [2.231996842956543, 0.5682]
是的,这确实产生了可测量的差异。我们从之前倒置数据集上的 10%准确率提高到 50%准确率。因此,卷积层似乎有助于过滤(而不是学习)数字的背景或白色。
但准确率仍然太低。对于偏移数据集,我们将其提高到 57%。这仍然低于我们的目标,但我们也可以看到,现在卷积层正在学习空间关系。那么,我们在这里学到了什么呢?嗯,如果你有一个错误的模型架构,无论你如何加深或加宽模型,或者添加多少正则化,模型都不会泛化到分布外的测试数据。我们还了解到,CNN 不仅泛化得更好,而且在参数方面也更为高效,在我们的第一次测试中,我们只使用了茎而没有学习组件。
如果一个卷积层能改善事情,那么让我们看看使用两个卷积层我们能做得更好。我们将使用两层:第一层有 16 个过滤器,第二层有 32 个过滤器。随着 CNN 逐渐加深,加倍过滤器数量是一种常见的做法。图 12.12 展示了我们的模型架构。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F12_Ferlitsch.png
图 12.12 深度两层 CNN 用于 MNIST 训练
这里是构建、训练和评估我们第二次测试中 CNN 模型的代码:
model = CNN([16, 32]) ❶
model.fit(x_train, y_train, epochs=10, batch_size=32, shuffle=True,
verbose=2)
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 构建一个两层 CNN
这是我们的 CNN 训练结果:
test [0.03628469691830687, 0.9882]
再次,我们在测试数据上获得了相当准确的精度,略有提升,达到约 99%。让我们看看添加卷积层是否能够提高我们在替代测试数据上的精度:
inverted [1.2761547603607177, 0.6332]
shifted [0.6951200264453888, 0.7679]
我们确实看到了一些渐进的改进。我们的反转数据集上升到 63%。因此,它正在学习更好地过滤掉数字的背景和白色,但仍然没有达到目标。我们的平移数据集测试跃升至 76%。所以你可以看到卷积层是如何学习数字的空间关系与图像中的位置(与 DNN 相比)。
12.2.6 图像增强
最后,让我们使用图像增强来尝试改进对分布外替代测试数据的泛化。回想一下,图像增强是一个通过在现有样本上进行小修改来生成新样本的过程。这些修改不会改变图像的分类,而且图像仍然会被人类眼睛识别为那个类别。
图 12.13 展示了图像增强的一个示例,其中一张猫的图片被随机旋转,然后裁剪并调整大小回到原始形状。这张图片仍然可以被人类眼睛识别为猫。
https://github.com/OpenDocCN/ibooker-dl-zh/raw/master/docs/dl-ptn-prac/img/CH12_F13_Ferlitsch.png
图 12.13 使用随机选择的平移生成的图像增强示例管道
除了向训练集中添加更多样本外,某些类型的增强可以帮助模型泛化,以便准确分类测试(保留)数据集之外的图像,否则模型可能会在这些图像上失败。
正如我们在 CNN 中看到的,我们在平移图像上仍然缺乏足够的精度;因此,我们的模型还没有完全学会将数字的空间关系从图像中的位置和背景中分离出来。我们可以添加更多过滤器并增加卷积层,以尝试提高平移图像上的精度。这将使模型更复杂,训练时间更长,并且在部署进行预测(推理)时会有更大的内存占用和更长的延迟。
或者,我们将通过使用图像增强来随机左右移动图像最多 20%来改进模型。由于我们的图像宽度为 28 像素,20%意味着图像在任一方向上最多移动 6 像素。我们有一个最小 4 像素的边界,因此数字的裁剪将很少或没有。
我们将使用 TF.Keras 中的ImageDataGenerator类来进行图像增强。在下面的代码示例中,我们执行以下操作:
-
创建与之前相同的 CNN 模型。
-
实例化一个
ImageDataGenerator生成器对象,其参数width_shift_range=0.2将在训练期间通过随机左右移动图像+/- 20%来增强数据集。 -
调用
fit_generator()方法,使用我们的图像增强生成器和现有的训练数据来训练模型。 -
在生成器中指定
steps_per_epoch的数值为训练样本数除以批大小;否则,生成器将在第一个 epoch 上无限循环:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
model = CNN([16, 32])
datagen = ImageDataGenerator(width_shift_range=0.2) ❶
model.fit_generator(datagen.flow(x_train, y_train, batch_size=32),
steps_per_epoch= 60000 // 32 , epochs=10) ❷
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 实例化随机左右移动图像 +/- 20%的生成器
❷ 使用图像增强训练模型
下面是我们对 CNN 训练的结果:
test [0.046405045648082156, 0.986]
让我们看看这能否提高分布外测试数据的准确率:
inverted [4.463096208190918, 0.2338]
shifted [0.06386796866590157, 0.9796]
哇,现在我们在移动数据上的准确率接近 98%。所以我们能够训练模型学习数字在图像中移动时的空间关系,而不会增加模型的复杂性。但在倒置数据上我们还没有看到任何改进。
现在我们来训练模型,以过滤掉数字的背景和白色,以提高模型泛化到分布外倒置测试数据的能力。在下面的代码中,我们像测试数据那样取了 10%的训练数据(x_train_copy[0:6000])并对其进行倒置。为什么是 10%而不是全部训练数据?当我们想要训练一个模型来过滤掉某些东西时,我们通常可以用整个训练数据分布的 10%来完成。
接下来,我们将原始训练数据与额外的倒置训练数据合并,将两个训练集连接在一起——包括x_train(数据)和y_train(标签——在我们的训练集中总共 66,000 张图像(与 60,000 张相比):
x_train_invert = np.invert(x_train_copy[0:6000]) ❶
x_train_invert = (x_train_invert / 255.0).astype(np.float32) ❶
x_train_invert = x_train_invert.reshape(-1, 28, 28, 1) ❶
y_train_invert = x_train[0:6000] ❷
x_combine = np.append(x_train, x_train_invert, axis=0) ❸
y_combine = np.append(y_train, y_train_invert, axis=0) ❸
model = CNN([16, 32])
datagen = ImageDataGenerator(width_shift_range=0.2)
datagen.fit(x_train_combine)
model.fit_generator( datagen.flow(x_combine, y_combine, batch_size=32),
steps_per_epoch= 66000 // 32 , epochs=10) ❹
score = model.evaluate(x_test, y_test, verbose=1)
print("test", score)
❶ 从(副本)训练数据中选择 10%并对其进行倒置
❷ 选择相同的 10%的对应标签
❸ 将两个训练数据集合并成一个训练集
❹ 使用合并的训练数据集训练模型
下面是我们对 CNN 训练的结果:
test [0.04763028650498018, 0.9847]
让我们看看这能否提高我们备用测试数据的准确率:
inverted [0.13941174189522862, 0.9589]
shifted [0.06449916120804847, 0.979]
哇,我们在倒置图像上的测试准确率接近 96%。
12.2.7 最终测试
作为最后的测试,我从谷歌图片搜索中随机选择了一些手写单个数字的“野外”图像。这些图像包括用彩色绘制的、用圆珠笔绘制的、用画笔绘制的以及由小孩子用蜡笔绘制的图像。在我完成测试后,我使用本章训练的 CNN 只得到了 40%的准确率。
为什么只有 40%,我们该如何诊断原因?问题应该是模型学习了哪个子群体分布?模型是否学会了独立于背景对比的数字轮廓的泛化,还是它只是学会了数字要么是白色要么是黑色?如果我们用黑色数字在灰色背景上(而不是白色)进行测试会发生什么?
MNIST 的训练和测试数据是用笔或铅笔绘制的数字,所以线条很细。我的一些“野外”图像线条较粗,是用圆珠笔、画笔或蜡笔绘制的。模型是否学会了泛化线条的粗细?关于纹理呢?用蜡笔和颜料绘制的数字有粗糙的纹理;这些纹理差异是否作为边缘在卷积层中被学习?
作为最后的例子,假设你开发了一个用于在工厂中检测零件缺陷的模型。相机位于一个固定的位置,其视角覆盖着一个有凹槽的灰色输送带。一切正常,直到有一天,所有者用一条光滑的黄色输送带来替换它,以给工厂增添一些色彩,现在缺陷检测模型失败了。发生了什么?好吧,因为灰色输送带在所有训练图像中,它就会成为潜在空间中学习特征的一部分,在进入任务学习器(分类器)之前。这类似于经典的狗与狼的案例,其中所有的狼照片都是在冬天拍摄的。在这个经典案例中,当训练模型被给了一张背景有雪的狗的照片(分布外)时,模型预测的是狼。在这种情况下,模型只是学会了雪意味着狼。
摘要
-
样本分布模型了一个群体分布的参数。
-
子群体分布模型了一个偏差,这是群体分布的一个子部分。
-
如果你在一个子群体分布上进行训练,并且你的模型在生产中对它看到的例子没有泛化,那么生产数据很可能超出了你训练的子群体分布。这也被称为服务偏差。
-
添加更深或更宽的层以及/或更多的正则化通常不会帮助泛化到分布外的群体。
-
从图像增强中生成训练样本有时可以帮助泛化到分布外的群体。
-
当图像增强不足以泛化时,你需要添加来自分布外子群体的训练示例。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
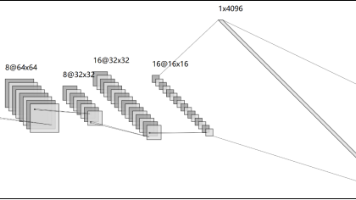
 0
0 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)