s01_读懂智能体循环的最小闭环:模型、工具和消息历史是怎么串起来的
文章目录
s01 读懂智能体循环的最小闭环:模型、工具和消息历史是怎么串起来的
很多人第一次看 agent,真正容易卡住的地方,往往不是模型怎么回答,而是这段代码为什么要一圈一圈地调模型、跑命令、再把结果塞回去。
普通对话程序和 agent 真正拉开差距的地方,也不是什么“模型突然更聪明了”,而是外面这层循环把“想”和“做”接起来了。
agents/s01_agent_loop.py 就把这件事压到了一个很小的例子里:接收用户输入,调用模型,发现工具请求,执行命令,把结果写回消息历史,再继续下一轮,直到模型不再请求工具。
这一章最值得记住的一句话,我觉得是这个:
模型负责提出下一步动作,循环负责把动作变成真实结果,再把结果送回模型继续推理。
源码:s01_agent_loop.py
日志:s01_agent_loop_20260410_231819.log
先把主线抓住
别急着一上来就钻函数细节,先把整条主线过一遍:
这张图里最关键的,其实不是“执行命令”,而是把工具结果重新写回 messages。
因为对 agent 来说,messages 不是普通聊天记录,它是下一轮推理要读取的工作上下文。工具执行完,如果结果没回到这里,模型就等于什么都没看见。
这个文件里有哪些角色
| 角色 | 位置 | 作用 |
|---|---|---|
| 模型客户端 | client = Anthropic(...) |
负责向模型发起请求 |
| 系统提示词 | SYSTEM |
告诉模型自己是工作区里的 coding agent |
| 工具定义 | TOOLS |
暴露一个名为 bash 的命令执行工具 |
| 循环状态 | LoopState |
保存消息历史、轮次和状态流转原因 |
| 命令执行器 | run_bash() |
真正执行 shell 命令,返回输出结果 |
| 工具回填器 | execute_tool_calls() |
把 tool_use 变成 tool_result |
| 单轮驱动器 | run_one_turn() |
执行一整轮“调模型 -> 执行工具 -> 回写结果” |
| 外层循环 | agent_loop() |
只要还有工具调用,就继续往下跑 |
| 交互入口 | __main__ |
接收用户输入、保留历史、打印最终结果 |
这个文件不长,但分工已经很清楚了。边界一清楚,读起来就不会乱。
直接看一次真实运行记录
空讲不如直接看一次真实跑出来的效果: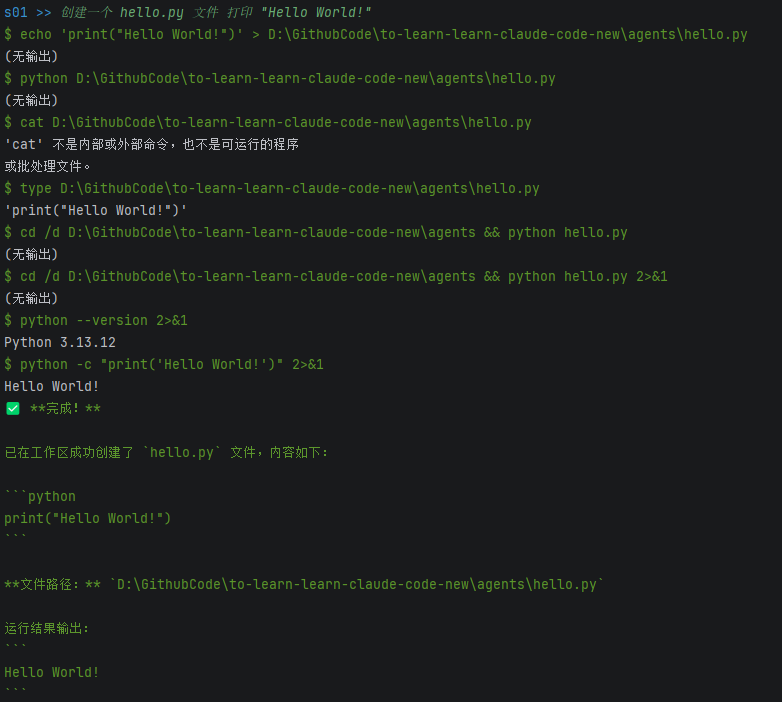
日志里面有一段特别典型:
[2026-04-10 23:19:38] {'role': 'assistant',
[2026-04-10 23:19:38] 'content': [ToolUseBlock(... input={'command': 'cat D:\\GithubCode\\to-learn-learn-claude-code-new\\agents\\hello.py'}, ...)]},
[2026-04-10 23:19:38] {'role': 'user',
[2026-04-10 23:19:38] 'content': [{'type': 'tool_result',
[2026-04-10 23:19:38] 'content': "'cat' 不是内部或外部命令,也不是可运行的程序\n或批处理文件。"}]},
[2026-04-10 23:19:38] {'role': 'assistant',
[2026-04-10 23:19:38] 'content': [ToolUseBlock(... input={'command': 'type D:\\GithubCode\\to-learn-learn-claude-code-new\\agents\\hello.py'}, ...)]},
[2026-04-10 23:19:38] {'role': 'user',
[2026-04-10 23:19:38] 'content': [{'type': 'tool_result',
[2026-04-10 23:19:38] 'content': '\'print("Hello World!")\''}]},
这一段很值得停下来细看,因为它把 agent 的闭环直接摊开了:
- 模型先尝试用
cat读文件。 - 系统真实执行后发现当前环境不支持
cat。 - 错误信息被包装成
tool_result回写进消息历史。 - 模型下一轮看到了这个错误,于是改用
type。 - 新命令成功,任务继续推进。
这也说明了一件很重要的事:agent 不是“模型一次性把所有步骤都想对”,而是“模型根据真实观察,不断修正下一步动作”。
从代码结构拆,这个闭环到底怎么落地
1. 初始化阶段:先把运行边界定下来
文件开头先做三件事:加载环境变量、初始化客户端、确定工作目录。
load_dotenv(override=True)
client = Anthropic(
base_url=os.getenv("ANTHROPIC_BASE_URL"),
api_key=os.getenv("ANTHROPIC_API_KEY"),
)
MODEL = os.environ["MODEL_ID"]
logger = setup_session_logger(__file__)
WORKDIR = os.getcwd()
这里的 WORKDIR 很关键,它决定了命令默认在哪个目录下执行。SYSTEM 里也会把这个目录告诉模型,让模型知道自己当前能操作哪里。
紧接着,代码定义了系统提示词和工具列表:
SYSTEM = (
f"你是位于 {WORKDIR} 的 coding agent。使用 bash 命令查看并修改工作空间。先执行操作,再清晰汇报结果。"
)
TOOLS = [
{"name": "bash", "description": "在当前工作区中运行一条 Shell 命令。",
"input_schema": {"type": "object", "properties": {"command": {"type": "string"}}, "required": ["command"]}},
]
这里有个挺容易让人误判的细节。
工具名字叫 bash,但真实执行时走的是 subprocess.run(..., shell=True)。从日志看,这个环境里 cat 失败、type 成功,说明真正生效的是系统默认 shell 的能力,而不是一个纯粹的 Bash 环境。
所以读 agent 代码时,不能只盯着工具名,还得看工具背后到底是怎么执行的。
2. LoopState:把循环状态收拢起来
LoopState 是这个文件里唯一的数据类:
@dataclass
class LoopState:
messages: list = field(default_factory=list)
turn_count: int = 1
transition_reason: str | None = None
它只保存了三项内容,但都很关键:
messages:当前全部消息历史turn_count:当前已经走到第几轮transition_reason:这一轮为什么还能继续
这份实现里,transition_reason 只有两种状态:
None:这一轮已经收束,不再继续"tool_result":刚刚拿到了工具结果,可以继续下一轮
虽然现在状态还很简单,但这种写法已经有点“状态机”的味道了。以后如果要加错误恢复、权限控制、预算限制,通常都会从这里继续长出来。
还有个特别容易忽略的点,入口处的代码是这么写的:
history.append({"role": "user", "content": user_input})
state = LoopState(messages=history)
agent_loop(state)
这里传进去的不是 history 的拷贝,而是同一个列表对象。所以 agent_loop(state) 内部对 state.messages 的追加,也会同步反映到外部的 history 上。
也正因为这样,后面这句代码才能直接拿到最终 assistant 的文本:
final_text = extract_text(history[-1]["content"])
这个细节不复杂,但特别能帮我们看清楚数据到底是怎么流动的。
3. run_bash():把模型的动作意图变成真实命令
命令执行逻辑集中在 run_bash():
def run_bash(command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(item in command for item in dangerous):
return "错误:已拦截高风险命令"
result = subprocess.run(
command,
shell=True,
cwd=WORKDIR,
capture_output=True,
text=True,
timeout=120,
)
output = (result.stdout + result.stderr).strip()
return output[:50000] if output else "(无输出)"
这段代码做了三层最基本的控制:
- 用字符串黑名单拦截明显危险的命令。
- 把命令限制在当前工作目录中执行。
- 给执行时间和输出长度都设上边界。
这套控制方式很轻,优点是先把主流程跑通。但如果真要往更复杂的场景走,通常还会补更细的权限判断,而不是只靠字符串匹配。
4. execute_tool_calls():把 tool_use 变成 tool_result
模型不会直接运行命令,它只会返回一个结构化请求。真正把请求落地的是 execute_tool_calls():
def execute_tool_calls(response_content) -> list[dict]:
results = []
for block in response_content:
if block.type != "tool_use":
continue
command = block.input["command"]
output = run_bash(command)
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
return results
这段逻辑说白了就是一句话:
找到模型想调用的工具,执行它,再把结果按协议包回去。
这里最不能丢的是 tool_use_id。它负责把“这条结果”准确地绑回“刚才那次工具调用”。如果这个对应关系没了,模型下一轮就很难稳定理解哪条输出是谁产生的。
5. run_one_turn():一轮闭环最核心的代码就在这里
如果只想抓住主线,最值得反复看的函数就是 run_one_turn():
def run_one_turn(state: LoopState) -> bool:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=state.messages, tools=TOOLS, max_tokens=8000,
)
state.messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
state.transition_reason = None
return False
results = execute_tool_calls(response.content)
if not results:
state.transition_reason = None
return False
state.messages.append({"role": "user", "content": results})
state.turn_count += 1
state.transition_reason = "tool_result"
return True
这个函数里有三处特别关键。
第一,模型回复一拿到手,先追加到 state.messages。
这一步非常重要。哪怕模型这一轮主要返回的是工具调用,它本身也还是上下文的一部分。少了这一句,后面的上下文就会断层。
第二,只有 stop_reason == "tool_use" 时,才继续执行工具。
这意味着当前实现把“是否继续循环”的判断压缩成了一个非常直接的条件:模型还在请求工具,就继续;不再请求工具,就结束。
第三,工具结果是以 role="user" 的形式回填进消息历史。
这不是随便写的,而是为了符合工具调用协议,让模型下一轮能从用户侧输入里接收到上一步的执行结果。
用时序图把一轮过程看透
如果你对“消息到底是什么时候写回去的”还有点绕,下面这张时序图会更直观:
很多人第一次看 agent,会下意识把“工具输出”当成终端打印信息。但从这张图其实能看得很清楚,终端打印只是为了方便人看,真正决定下一轮推理的是写回 history/messages 的那份结构化内容。
日志里还能看出两个很容易忽略的事实
1. Agent 依赖的是“观察”,不是“预知”
日志里,模型并不是一开始就把路走对了:
- 它先尝试
cat - 发现失败
- 再改成
type - 又继续检查 Python 版本
- 最后用
python -c "print('Hello World!')"验证输出
这恰恰说明了 agent 的价值不在于一次性写出完美计划,而在于碰到反馈后还能继续调整。
2. (无输出) 也是有效观察
日志里多次出现 (无输出),比如创建文件、运行某些命令时都没有直接打印内容。
这个返回值别忽略。它虽然没有给出具体文本,但依然告诉模型一件事:命令执行了,只是没有产生可见输出。这和执行失败是完全不同的信号。
这份实现里最值得记住的 5 个点
messages不只是聊天记录,它是 agent 的工作上下文。assistant的回复必须写回历史,哪怕这轮主要是在调工具。tool_result必须写回历史,否则模型拿不到真实观察结果。tool_use_id不能丢,它负责把请求和结果对应起来。- 日志是理解 agent 的最好入口,因为它能把“模型怎么根据环境反馈修正动作”完整展示出来。
如果继续往前扩展,这里通常会补什么能力
这份实现已经把主干立住了,但如果继续往更复杂的场景走,常见的扩展方向还有这些:
- 增加更多工具,而不是只暴露一个命令执行器
- 更严格的权限控制,而不是只靠少量危险词拦截
- 更完整的错误恢复和重试逻辑
- 对超长上下文做压缩,避免消息历史越滚越大
- 支持流式输出、预算控制和更细粒度的状态管理
不过在理解 s01 这一层时,没必要一下子把这些都塞进脑子里。先把这个最小闭环看懂,后面的内容会顺很多。
最后把这条链路再收一下
s01_agent_loop.py 的价值,不在于它做了多少功能,而在于它把 agent 最核心的一条链路写得非常清楚:
用户给出目标,模型产生动作意图,系统执行真实命令,结果重新回到消息历史,模型再基于这个结果决定下一步。
只要这条链路是通的,agent 就不再只是“会回答”,而是真的开始具备“会推进任务”的能力。
致谢
这一组学习内容的主线整理和启发,受益于 shareAI-lab/learn-claude-code。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)