反绎学习(Abductive Learning)详解:融合机器学习与逻辑推理的AI新范式及ABLkit实践
前言
参考论文和项目:
Abductive Learning 论文链接
ABLkit: A Toolkit for Abductive Learning
反绎学习由周志华教授于 2019 年提出,是一种将演绎反向嵌入到归纳过程中、以 “均衡互促” 方式融合机器学习与逻辑推理的人工智能新范式。
机器学习是数据驱动,擅长经验数据;逻辑推理是知识驱动,有内生可信性,但不擅长用数据。
什么是逻辑推理?
逻辑推理 = 从已知规则 / 知识出发,推导出正确结论的过程。它是知识驱动的,不需要大量数据,过程可解释,可追溯,可信。下面是三种最常见的逻辑推理:分别是演绎推理,归纳推理和反绎推理。

如何理解将演绎反向嵌入到归纳过程这句话呢?
归纳(induction)是机器学习干的事情,它从大量数据中总结规律和模型。而演绎(deduction)是逻辑推理干的事情,它从已知规律/知识推出具体结论。
定义:演绎(deduction)是从一般到特殊的“特化”(specialization)过程,即从基础原理推导出具体状况,例如基于数学公理和推理规则进行定理证明;归纳(induction)是从特殊到一般的“泛化”(generalization)过程,即从具体的事实归结出一般性规律,例如对数据样例进行机器学习。
正常的 AI 流程是 先学习(从数据到模型 ---- 归纳过程)再推理(模型 + 输入 得到输出 ---- 演绎过程),这是单向的。而反绎学习是说让演绎反过来去修改指导和纠正归纳的过程,而不只是再最后做推理。
定义:反绎”(abduction)是从一组不完备的观察事实(通常以数据的形态呈现)出发、基于背景知识来获得对观察事实最有可能的解释。在逻辑推理领域,abduction一般被译为“诱导”或“溯因”;从机器学习的角度看,“诱导”的含义不够明确,“溯因”容易跟“因果发现”混淆,因此周志华采用了“反绎学习”这个名称,可以理解为将演绎反向嵌入到归纳过程中,既有“正向”基于数据事实的学习,亦有“反向”基于知识规则的演绎。
为什么研究反绎学习?
二十年前,如何让机器学习与逻辑推理在统一框架中有效协同,就已被视为人工智能领域的“圣杯问题”。
对比当前人工智能技术能力和人类决策过程涉及的能力可以看出,机器学习比较善于利用经验数据事实、逻辑推理比较善于利用领域知识规则,而人类决策过程往往并不依赖于单方面,而是同时利用经验数据事实和领域知识规则。因此,若能在统一框架中同时发挥机器学习和逻辑推理的优势,那么人工智能技术能力应能得到更大提升。
一旦二者能够无缝融合,即像人类可以综合运用“感知(Perception)”和“推理(reasoning)”能力解决问题一样,那么高级人工智能将会出现。
反绎学习的难点
将机器学习和逻辑推理相融合的主要阻碍在于二者不同的表示方式(different representations)。
原文内容如下:
- 主流逻辑推理技术基于一阶逻辑表示(first-order logic representation),而主流机器学习技术则基于属性 - 值表示(attribute-value representation)。尽管属性 - 值对可转化为真值表,看似与命题逻辑表示等价,但这种转化无法直接搭建起机器学习与逻辑推理的沟通桥梁,二者之间仍存在显著鸿沟。
- 以一阶逻辑子句向属性 - 值表示的转化为例:一阶逻辑中的全称量词(∀)会导致单个子句衍生出无限实例;每个谓词实际表达的是实例间的关系,而非单个实例的确定属性值。因此,这种转化最终得到的往往是 “实例子集的属性值约束”,而非 “单个实例的明确属性值”。
对上面这部分内容的解释:
- 逻辑推理(一阶逻辑):擅长描述关系、规则、量词,比如 “所有 X 都是 Y”“如果 A 则 B”。
量词:所有 ∀、存在 ∃ ---------- 谓词:关系 ---------- 规则:如果… 那么…
比如 ∀x (Student(x) → Person(x))所有学生都是人。其中:∀x 是全称量词(对所有 x),Student(x)、Person(x) 是谓词(描述 x 是什么),→ 是逻辑蕴含
- 机器学习(属性 - 值表示):只认每个样本有哪些特征、取什么值,不认关系、不认量词。
机器学习里,一个样本长这样:特征 1 = 值,特征 2 = 值,特征 3 = 值…
比如:年龄 = 20,职业 = 学生,身高 = 175
机器学习只关心:每个对象有哪些属性,属性取什么值。它不理解关系,也不理解量词。
为什么机器学习的属性 - 值,对应不了一阶逻辑 ?
一阶逻辑中的全称量词(∀)会导致单个子句衍生出无限实例;每个谓词实际表达的是实例间的关系,而非单个实例的确定属性值。
比如所有学生都有作业:∀x (Student(x) → HasHomework(x)),那么∀x 表示对所有 x,x可以是无限多学生。但是机器学习正能处理有限,固定的属性 - 值 样本。它处理不了 “ 对所有x ” 这种无限规则。
Student(x) 不是属性,而是谓词 。机器学习想要的是:is_student = True 这是属性 - 值。∀x (Student(x) → HasHomework(x))硬转成机器学习能懂的东西,只能得到:如果一个对象是学生,那么它必须有作业。这是约束(Constraint),不是某个具体样本的属性值。
现有研究
尽管存在上述障碍,过去数十年间,研究人员仍围绕这一 “圣杯级” 难题开展了大量探索。总体而言,机器学习与逻辑推理的融合主要形成两种经典范式:

| 融合范式 | 核心流向 | 典型代表 |
|---|---|---|
| 重推理 - 轻学习 | 机器学习 → 逻辑推理 | PLP(概率逻辑程序) |
| 重学习 - 轻推理 | 逻辑推理 → 机器学习 | SRL(统计关系学习) |
| 双向平衡循环 | 机器学习 ↔ 逻辑推理 | ABL(归纳学习) |
反绎学习(Abductive Learning, ABL),通过双向平衡循环实现机器学习与逻辑推理的深度协同,使二者形成互利共赢的协作关系。
具体动机案例请参考原文。
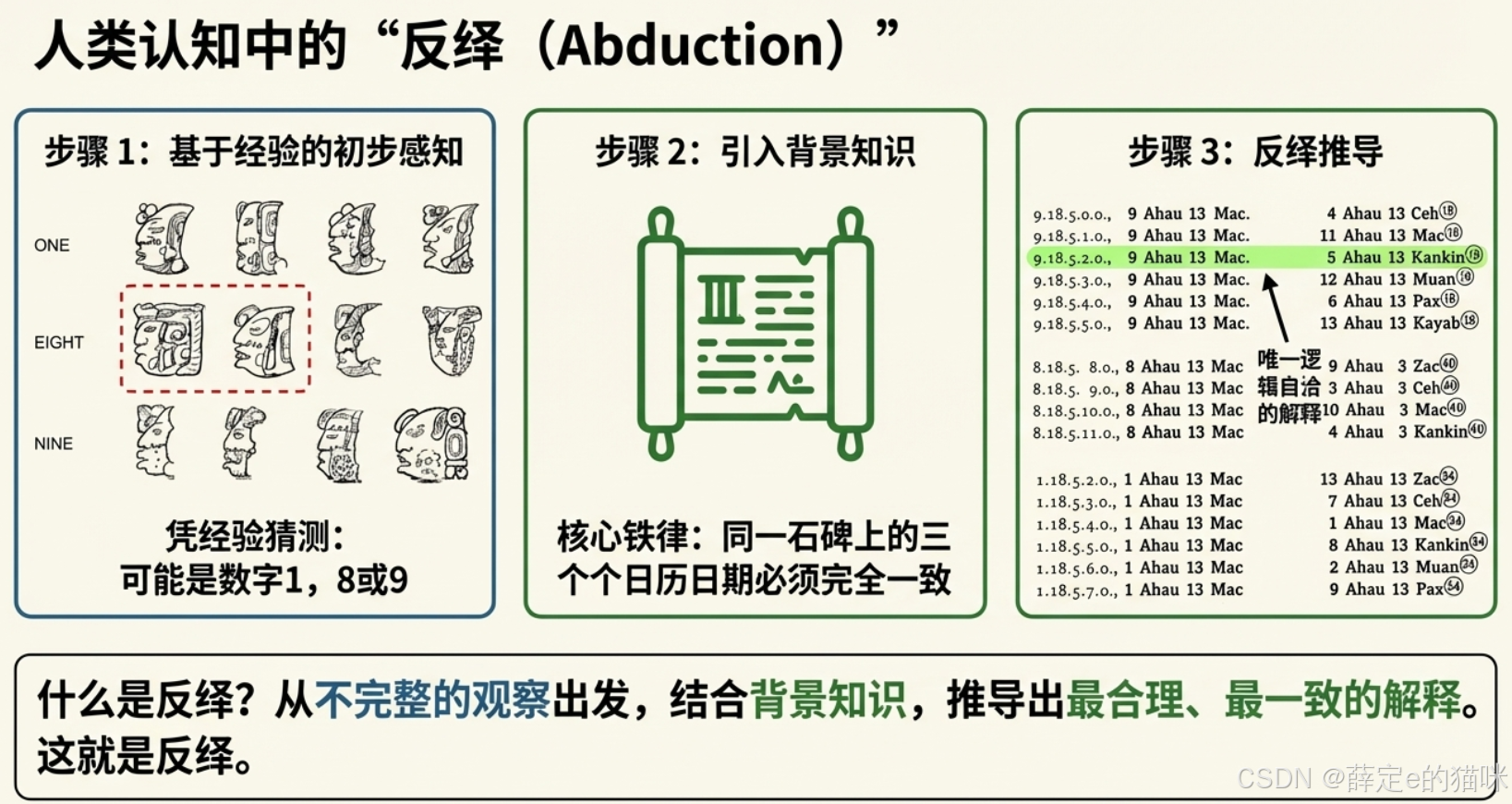
反绎学习的基本流程
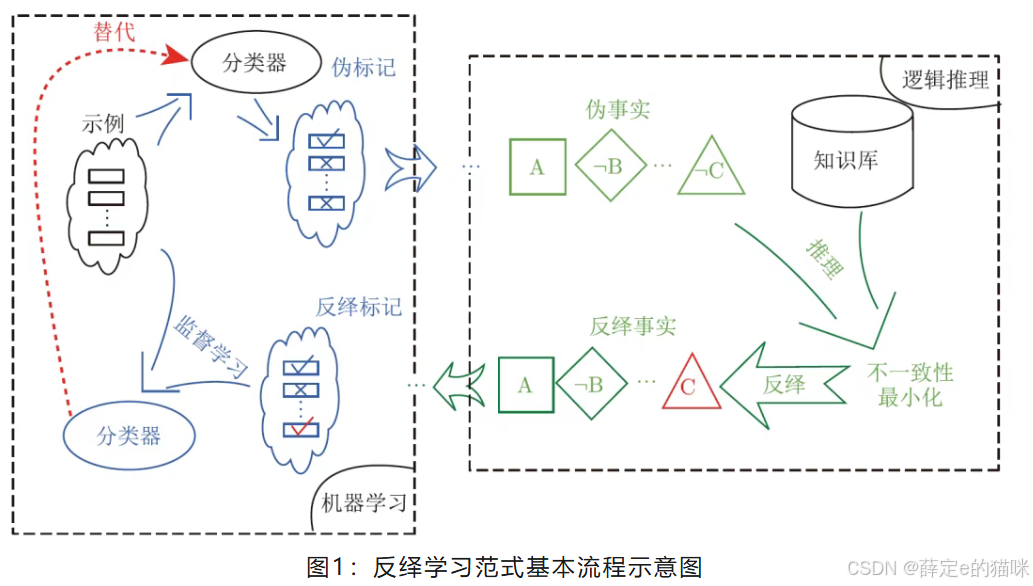
反绎学习的基本流程如下图所示。图中黑色部分是已知信息,包括训练示例集、知识库与初始分类器。
输入示例提交给分类器进行判别,得到示例的伪标记(pseudo-labels),它们被转换为相应的逻辑伪事实(pseudo-groundings),然后检验其与知识库的相容性。如果不相容(即存在不一致性),就寻找一个修正点,使得修正后的伪事实与知识库的不一致性最小化,例如图1中将伪事实 ¬ C修正为C。
随后,这个修正被传导为对伪标记的修正,从而产生反绎标记(abducted-label),配合输入示例来训练新的分类器。新分类器将替换原有的分类器,然后上述过程不断循环,形成一个机器学习与逻辑推理相互指导相互促进的“回路”,直至分类器不再更新,或机器学习产生的伪事实已经与知识库相容为止。

上面假设了初始训练示例并未伴随真实类别标记,但这仅是为了叙述方便。实际上,如果训练示例伴随着真实标记,即便仅是其中一部分示例,反绎学习也可以利用这些标记信息来提升性能。
例如,可以在训练分类器时使用这些带有真实标记的样本,还可以利用这些真实标记来辅助提升逻辑推理和反绎的有效性和可靠性,因为它们所对应的真实事实将有助于削减逻辑推理和反绎过程所面临的庞大假设空间。
图1中的初始分类器在实践中可以使用预训练模型,或者从相关任务迁移而来的模型,甚至可以通过示例聚类和最近邻分类产生,只要能“启动”循环过程即可,此时反绎学习可以被视为一种特殊的弱监督学习,其监督信息不仅来自于真实类别标记、更来自于知识库。
反绎学习范式具备良好的通用性与灵活性,可在图 1 所示的统一框架下,通过替换不同组件实现多样化模型。比如机器学习模块可选用神经网络、随机森林等任意模型;知识库也支持多种知识形式。
另外,如果拥有许多有标记样本,那么甚至可以直接基于有标记样本产生逻辑事实而进入逻辑推理环节,无需使用初始分类器。由此可见,与必须从机器学习端启动或必须从逻辑推理端启动的“单驱动”方式不同,反绎学习可以从任意端启动、是一种“双驱动”范式。
案例分析
项目地址:ABLkit: A Toolkit for Abductive Learning
ABLkit 是一个高效的 Python 工具包,用于实现 溯因学习(ABL)。这是一种新颖的机器学习范式,将数据驱动的神经网络与逻辑推理集成在统一的框架中。该工具包专为数据和领域知识同时可用的任务而设计,使开发者能够构建利用机器学习和符号推理互补优势的系统。
ABLkit 由四个核心模块组成,它们在一个协调的框架中协同工作:
学习模块 提供创建和管理机器学习模型的工具。推理模块 提供知识库实现和溯因推理功能。桥接模块 通过 ABL 训练循环协调学习和推理之间的交互。数据模块 定义数据结构和评估指标。
ABLkit/
├── ablkit/ │ ├── bridge/ # 学习-推理协调
│ ├── data/ # 数据结构和指标
│ ├── learning/ # ML 模型封装和工具
│ ├── reasoning/ # 知识库和推理器
│ └── utils/ # 日志、缓存、管理工具
├── examples/ # 可运行的示例和教程
│ ├── mnist_add/ # MNIST 加法任务
│ ├── hwf/ # 手写公式任务
│ ├── hed/ # 手写方程解密
│ └── zoo/ # Zoo 优化示例
├── tests/ # 单元测试和集成测试
├── docs/ # 综合文档
└── README.md # 快速参考和入门指南
MNIST 加法任务作为 ABLkit 用法的说明性示例。给定成对的手写数字图像及其和,目标是训练一个能够准确对图像中的数字进行求和的系统。领域知识(加法的原理)通过溯因推理指导学习过程。
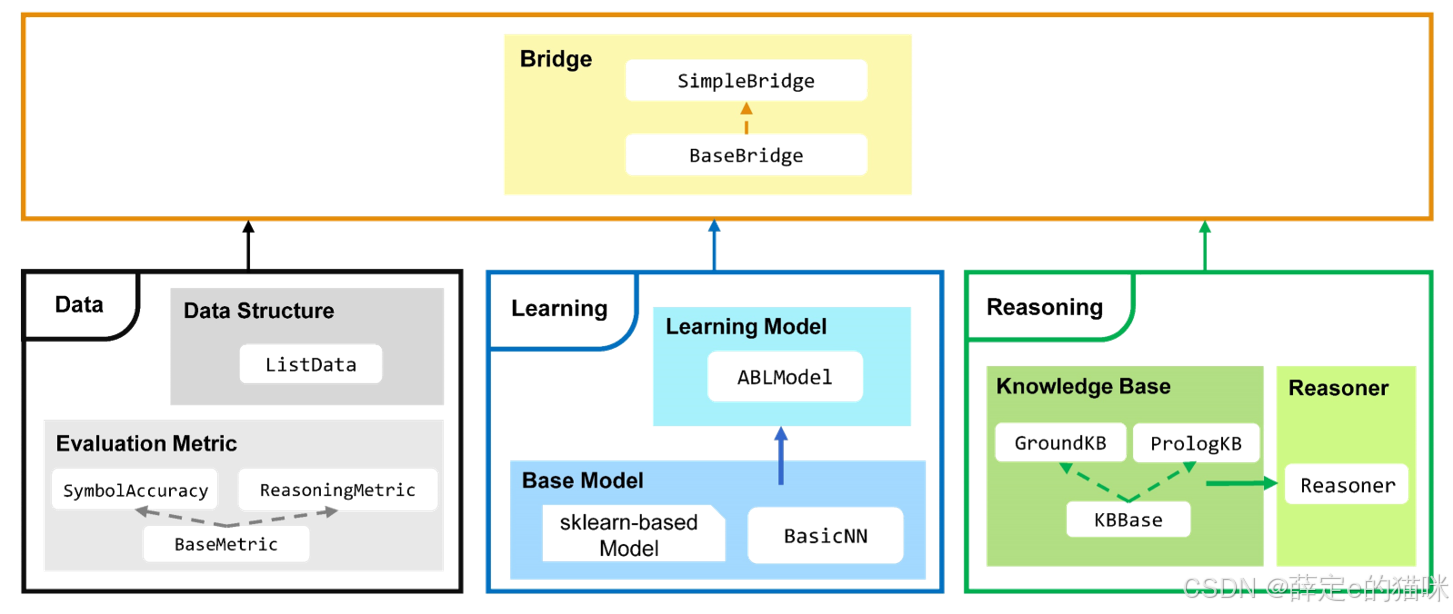
- 数据准备:以 (X, gt_pseudo_label, Y) 的格式加载数据,其中 X 包含实例,gt_pseudo_label 包含实例级真值,Y 包含推理结果
- 学习设置:创建一个基础模型(例如 LeNet5),用 BasicNN 封装,然后用 ABLModel 封装以兼容 ABL
- 推理设置:定义一个知识库(KBBase 的子类)并创建一个 Reasoner 来执行溯因推理
- 桥接训练:使用 SimpleBridge 编排带有评估指标的 ABL 训练循环
安装方法:
| 方法 | 命令 | 备注 |
|---|---|---|
| PyPI (推荐) | pip install ablkit | 最简单的方法,获取最新的稳定版本 |
| 源码 | git clone https://github.com/AbductiveLearning/ABLkit.git && cd ABLkit && pip install -v -e . | 获取最新的开发版本 |
如果你计划使用基于 Prolog 的知识库(PrologKB),你还需要单独安装 SWI-Prolog。对于 Linux 用户:sudo apt-get install swi-prolog。Windows 和 Mac 用户参考:https://github.com/yuce/pyswip/blob/master/INSTALL.md
| 示例 | 任务 | 知识库类型 | 难度 |
|---|---|---|---|
| MNIST Addition | 两个手写数字相加 | Python 算术 | 初学者 |
| Handwritten Formula (HWF) | 解析和计算数学表达式 | 基于 Prolog 的语法 | 中级 |
| Handwritten Equation Decipherment (HED) | 从损坏的公式中恢复方程 | 基于 Prolog 的推理 | 中级 |
| Zoo | 具有离散变量的优化任务 | 基于 Prolog 的约束 | 高级 |
每个示例都包含一个用于交互式探索的 Jupyter notebook 和一个用于命令行执行的 main.py 脚本。
下面以MNIST 加法任务快速上手:
MNIST 加法任务提出了一个独特的学习挑战:给定成对的手写数字图像及其和(例如,“7 + 5 = 12”),系统必须学会正确识别单个数字。困难在于缺乏直接的数字监督——模型仅接收关于最终和是否正确的反馈,而不接收关于哪些数字被错误识别的反馈。
该任务完美展示了溯因学习的力量,它连接了感知(用于图像识别的神经网络)和推理(用于算术的逻辑知识)。核心创新在于使用溯因推理来修正神经网络的初始数字预测,当这些预测无法得出正确的和时。
使用默认参数执行完整的 MNIST 加法示例:
cd examples/mnist_add
pip install -r requirements.txt
python main.py
使用命令行参数自定义训练:
python main.py --epochs 2 --loops 3 --segment_size 0.01 --batch-size 64
- no-cuda:禁用 GPU 加速
- prolog / --ground:使用 PrologKB 或 GroundKB 代替默认的 KBBase
- max-revision N:限制每个示例的伪标签修订次数
- label_smoothing VAL:调整交叉熵标签平滑(默认:0.2)
在训练期间,你将看到如下输出:
abl - INFO - Working with Data.
abl - INFO - Building the Learning Part.
abl - INFO - Building the Reasoning Part.
abl - INFO - Building Evaluation Metrics.
abl - INFO - Bridge Learning and Reasoning.
abl - INFO - loop(train) [1/2] segment(train) [1/100]
abl - INFO - model loss: 2.25980
abl - INFO - loop(train) [1/2] segment(train) [2/100]
abl - INFO - model loss: 2.14168
...
abl - INFO - Eval start: loop(val) [2]
abl - INFO - Evaluation ended, mnist_add/character_accuracy: 0.993 mnist_add/reasoning_accuracy: 0.986
日志显示随着循环的增加,字符准确率(数字识别)和推理准确率(正确求和)都在提高。
在测试集上评估最终模型:
bridge.test(test_data)
这将输出在未见数据上的性能指标,衡量泛化能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)