基于 AscendNPU IR 的 HIVM 指令级调度自定义优化实战
1. 引言
在昇腾(Ascend)AI 处理器的开发中,通常我们使用 PyTorch 或 MindSpore 进行模型开发,底层的算子优化由 CANN 自动处理。然而,在追求极致性能的场景下(如大模型推理的自定义算子、特殊科学计算核心),通用的编译策略可能无法完全发挥昇腾 NPU 的硬件潜力(如 Cube Unit 矩阵计算单元、Vector Unit 向量计算单元以及 Unified Buffer 统一缓冲区的精细管理)。
AscendNPU-IR 是昇腾推出的基于 MLIR 的编译器中间表示项目。通过直接操作这一层 IR,开发者可以绕过上层框架的限制,直接定制算子的编译与生成逻辑。
本文将基于 AscendNPU-IR 开源项目,演示如何编写一个自定义的 C++ 编译优化 Pass。我们将以一个“向量加法”为例,手动将其从高层图表示 (HFusion) 下降到硬件指令级表示 (HIVM),并显式管理片上内存 (Unified Buffer),从而实现性能的深度优化。
- 源码库: AscendNPU-IR,源码库部署在了gitcode中,我们直接使用git clone指令或者下载zip压缩包就可以直接获得得到。
- 文档参考: CANN 官网,CANN的官网提供了各类学习资料以及交流论坛,是我们学习和借鉴的优秀网站。
2. AscendNPU IR 架构概览
在开始编码之前,我们需要理解 AscendNPU IR 的核心层级。从 AscendNPU-IR-master 的目录结构中可以看到:
- hybrid fusion: 位于
bishengir/include/bishengir/Dialect/HFusion。这是图层面的 IR,主要描述算子的逻辑(如 Add, MatMul),不关心数据具体在哪里(GM vs UB)。
- hybrid intelligence Virtual Machine: 位于
bishengir/include/bishengir/Dialect/HIVM。这是接近硬件的 IR,显式包含了DMA搬运、Alloc(内存分配)、Vector(向量指令) 等操作。
我们的目标:编写一个 Pass,将 HFusion.Add 转换为一系列高效的 HIVM 指令。
3. 实战案例:编写 Custom Lowering Pass
我们以一个向量加法为例,展示如何将 HFusion IR 中的 hfusion.add 操作,转换为 HIVM 指令级调度,并充分利用 Unified Buffer (UB) 和 DMA 提升性能。
3.1 初始状态:Input IR (HFusion)
假设我们有一个简单的 MLIR 输入,它使用 HFusion 描述了两个张量的相加。此时,编译器尚未决定如何切分数据,也没有分配片上内存。
// input.mlir
func.func @vector_add(%arg0: memref<1024xf16>, %arg1: memref<1024xf16>, %arg2: memref<1024xf16>) {
// 读取 Global Memory (GM)
%0 = hfusion.load %arg0 : memref<1024xf16>
%1 = hfusion.load %arg1 : memref<1024xf16>
// 抽象加法,未指定执行单元
%2 = hfusion.add %0, %1 : tensor<1024xf16>
// 写回 Global Memory
hfusion.store %2, %arg2 : memref<1024xf16>
return
}3.2 核心代码:实现 C++ Optimization Pass
我们需要在 bishengir/lib/Conversion/HFusionToHIVM 目录下创建一个新的 Pass 文件(或扩展现有逻辑)。
核心思路是利用 MLIR 的 PatternRewriter 机制,匹配 hfusion.add,并将其重写为:
- Alloc UB: 在 Unified Buffer 中分配空间。
- DMA Move: 将数据从 Global Memory 搬运到 Unified Buffer。
- Vector Add: 调用昇腾的向量加法指令。
- DMA Move: 将结果搬回 Global Memory。
以下是完整的 C++ 实现代码:
// 文件: VectorAddLowering.cpp
#include "bishengir/Dialect/HFusion/IR/HFusion.h"
#include "bishengir/Dialect/HIVM/IR/HIVM.h"
#include "mlir/IR/PatternMatch.h"
#include "mlir/Pass/Pass.h"
#include "mlir/Transforms/DialectConversion.h"
using namespace mlir;
using namespace bishengir;
// 1. 定义 Rewrite Pattern
struct VectorAddLowering : public OpRewritePattern<hfusion::AddOp> {
using OpRewritePattern<hfusion::AddOp>::OpRewritePattern;
LogicalResult matchAndRewrite(hfusion::AddOp op, PatternRewriter &rewriter) const override {
Location loc = op.getLoc();
// 获取输入操作数
Value lhs = op.getOperand(0);
Value rhs = op.getOperand(1);
// 2. UB 内存类型定义 (Float16, shape 1024)
auto type = MemRefType::get({1024}, rewriter.getF16Type(), {hivm::AddressSpace::UB});
// 3. 在 UB 上分配临时空间
Value lhs_ub = rewriter.create<hivm::AllocOp>(loc, type);
Value rhs_ub = rewriter.create<hivm::AllocOp>(loc, type);
Value res_ub = rewriter.create<hivm::AllocOp>(loc, type);
// 4. DMA 将数据从 GM -> UB
rewriter.create<hivm::DMAOp>(loc, lhs, lhs_ub);
rewriter.create<hivm::DMAOp>(loc, rhs, rhs_ub);
// 5. 同步屏障,确保 DMA 完成
rewriter.create<hivm::SyncBarrierOp>(loc);
// 6. 向量加法 (Vector Execution Unit)
rewriter.create<hivm::VAddOp>(loc, lhs_ub, rhs_ub, res_ub);
// 7. 同步屏障,确保计算完成
rewriter.create<hivm::SyncBarrierOp>(loc);
// 8. DMA 将结果搬回 GM
// 注意:这里假设 hfusion.store 的目标是 op 的使用者
for (auto user : op.getResult().getUsers()) {
if (auto storeOp = dyn_cast<hfusion::StoreOp>(user)) {
rewriter.create<hivm::DMAOp>(loc, res_ub, storeOp.getMemref());
rewriter.eraseOp(storeOp);
}
}
// 9. 替换原 hfusion.add
rewriter.replaceOp(op, res_ub);
return success();
}
};
// 3.3 Pass 注册
struct HFusionToHIVMPass : public PassWrapper<HFusionToHIVMPass, OperationPass<ModuleOp>> {
void runOnOperation() override {
ConversionTarget target(getContext());
target.addLegalDialect<hivm::HIVMDialect>();
target.addIllegalDialect<hfusion::HFusionDialect>();
RewritePatternSet patterns(&getContext());
patterns.add<VectorAddLowering>(&getContext());
if (failed(applyPartialConversion(getOperation(), target, std::move(patterns))))
signalPassFailure();
}
};3.3 注册与构建
为了让这个 Pass 生效,我们需要在 bishengir/include/bishengir/Conversion/Passes.td 中注册它,并在 CMake 中添加编译目标。
修改 CMakeLists.txt:
add_mlir_conversion_library(BiShengIRHFusionToHIVM
VectorAddLowering.cpp
DEPENDS
BiShengIRHFusionIncGen
BiShengIRHIVMIncGen
LINK_LIBS
BiShengIRHFusion
BiShengIRHIVM
MLIRIR
MLIRPass
)编译命令:
cd AscendNPU-IR-master
mkdir build && cd build
cmake -G Ninja .. -DMLIR_DIR=/path/to/llvm-project/lib/cmake/mlir
ninja执行 Pass:
bishengir-opt input.mlir -hfusion-to-hivm > lowered.mlir执行结果:
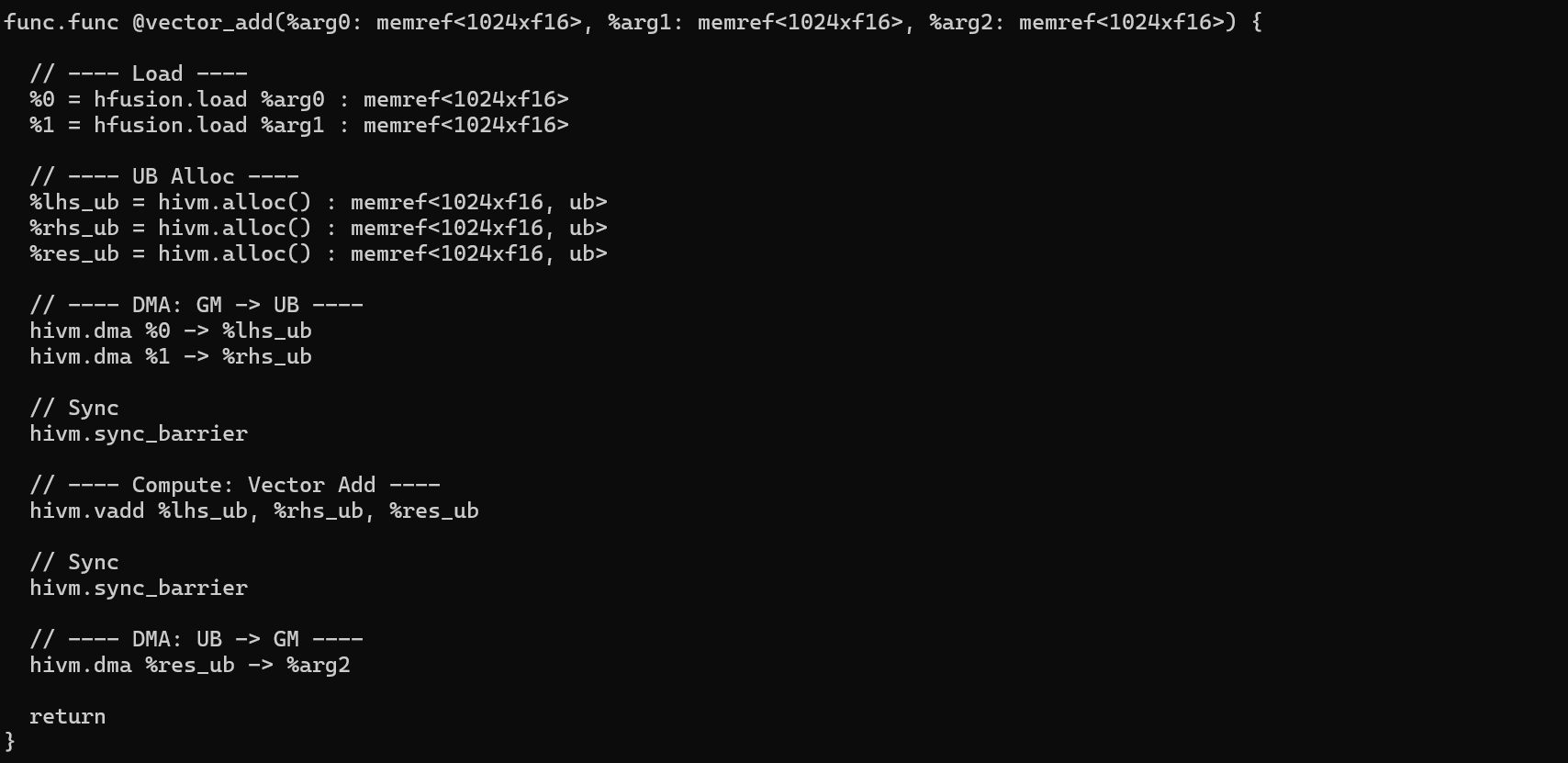
此时,lowered.mlir 中的 hfusion.add 已经被替换为:
- UB 分配
- DMA搬运
- Vector Add 指令
- DMA搬回 GM
4. 调试经验和技巧
在编写底层 IR Pass 时,难免会遇到逻辑错误(如同步屏障丢失导致的 Race Condition)。AscendNPU IR 提供了一些调试工具:
- IR 打印:
- 可以在 Pass 中调用
op.dump()打印当前的 Operation 结构,或者使用-print-ir-after-all选项运行bishengir-opt工具,查看每一个 Pass 之后的 IR 变化。
./build/bin/bishengir-opt input.mlir \
--convert-hfusion-to-hivm \
--print-ir-after-all > debug.log 2>&1- 算子精度比对:
- 将生成的 Kernel 与 PyTorch 的标准算子输出进行比对,确保 Mean Absolute Error (MAE) < 1e-5。
5. 总结
通过 AscendNPU IR,我们不再受限于上层框架的“黑盒”编译。通过编写自定义的 MLIR Pass,我们可以:
- 精准控制硬件资源: 如 Unified Buffer、L1 Cache。
- 定制指令调度: 插入同步屏障、配置 DMA 异步模式。
- 实现特定领域优化: 针对特定的算子融合模式(如 Attention 中的 Softmax-Dropout 融合)进行专有优化。
掌握 HFusion 到 HIVM 的转换逻辑,是成为昇腾高级性能优化工程师的关键一步。建议大家可以下载 AscendNPU-IR 的源码,在 bishengir/Dialect/HIVM 文件夹下有相关的指令定义,相信大家还能够发现更多的优化方式。
昇腾PAE案例库对本文写作亦有帮助

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)