别整那些虚的!老司机带你手搓Kurator,彻底搞定多云分布式K8s那个烂摊子
别整那些虚的!老司机带你手搓Kurator,彻底搞定多云分布式K8s那个烂摊子
咱就聊点实在的,聊聊怎么在现在这个多云、混合云满天飞的时代,还能稳坐钓鱼台,把手里那几百个Kubernetes集群管得服服帖帖。
这就得提到今儿的主角——Kurator。
你要问我Kurator是啥?简单说,它就是个“集群大管家”,专门治各种“分布式云原生综合症”。你手头要是只有个把集群,可能觉得也就是敲几行kubectl的事儿;但当你手里的业务分散在阿里云、AWS、还有自建机房,甚至还得管边缘端那些“骨瘦如柴”的小设备时,标准的那套玩法早就崩了。Kurator就是华为开源出来的一个专门搞分布式云原生平台的利器,它整合了Karmada、Volcano、Istio这些业界的扛把子项目,给你搓成了一套开箱即用的“全家桶”。它能让你像管一台电脑一样,去管这一堆分散在天南地北的集群。不吹不黑,这玩意儿在解决多云统一管理、统一调度、统一流量治理这些个“老大难”问题上,是真的有点东西。
咱们今儿就以此为题,把Kurator扒光了看个透,顺带手把手教你怎么把这套环境搭起来,跑通几个核心场景。安全带系好,发车了!
一、 从“单机王者”到“分布式噩梦”:咱们面临的烂摊子
咱们先得把底层的逻辑捋顺了。做云原生,Kubernetes(K8s)那是绕不开的坎儿。
1.1 Kubernetes集群的标准架构:梦开始的地方
这是Kubernetes集群的标准架构参考图,展示了包含控制平面组件、工作节点及云平台集成的完整集群部署模型: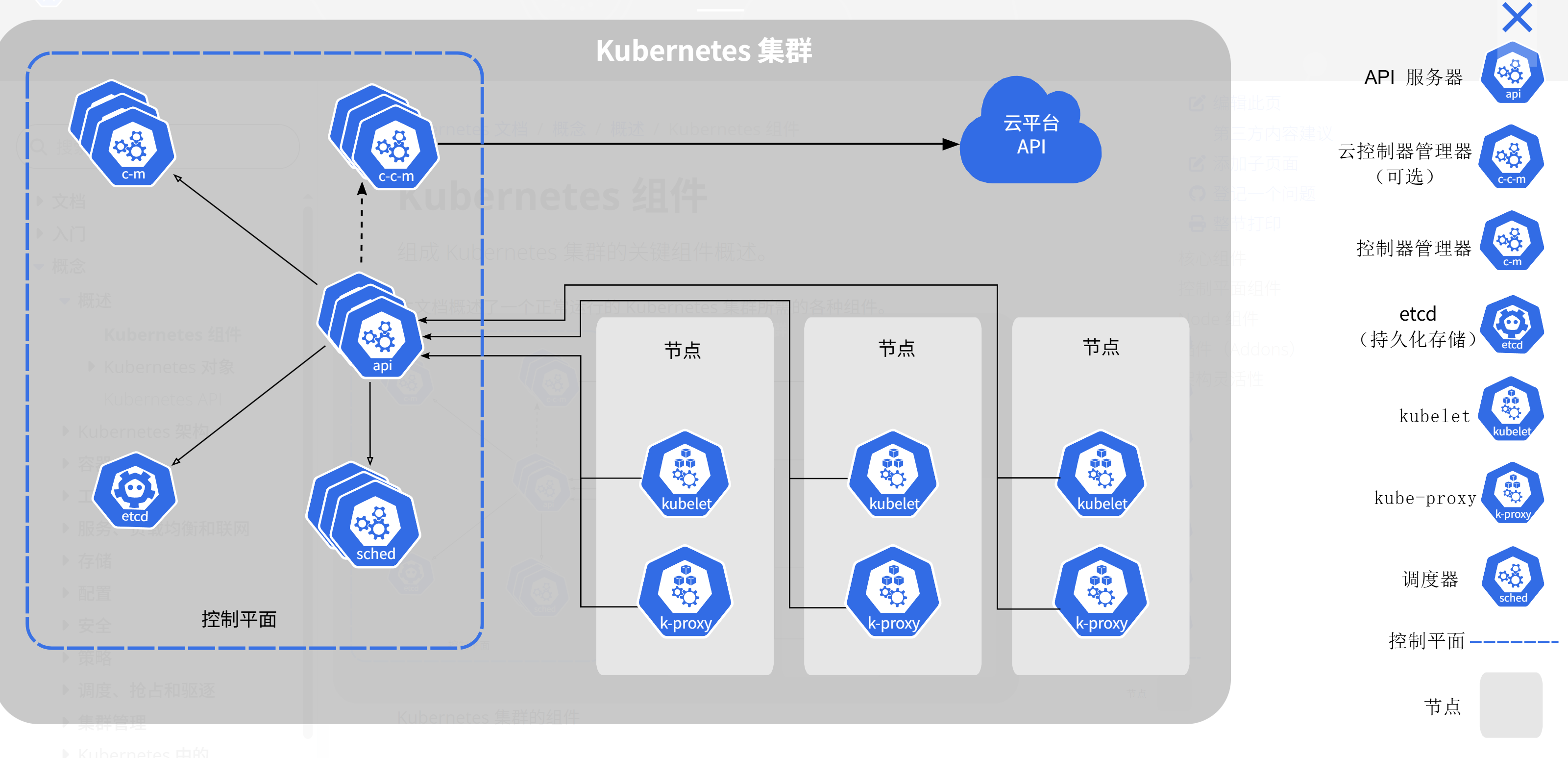
回想当年,咱们刚接触K8s的时候,那架构多标准、多清秀啊。Kubernetes集群的标准架构,说白了就是一个Master节点(Control Plane)带着一群Worker节点干活。Master上有API Server、Scheduler、Controller Manager还有那个存数据的etcd,这一套组合拳下来,无论是Pod的调度还是服务的发现,都安排得明明白白。那时候咱们觉得,只要把这个架构吃透了,天下大可去得。
但现实很快就教做人了。业务一扩张,这套“标准架构”就开始捉襟见肘。
1.2 分布式云原生架构:当梦想照进现实
这是分布式云原生架构的参考图,展示了如何通过统一应用治理、数据融合、安全及资源调度,实现对多云、本地及边缘异构集群的一体化管理: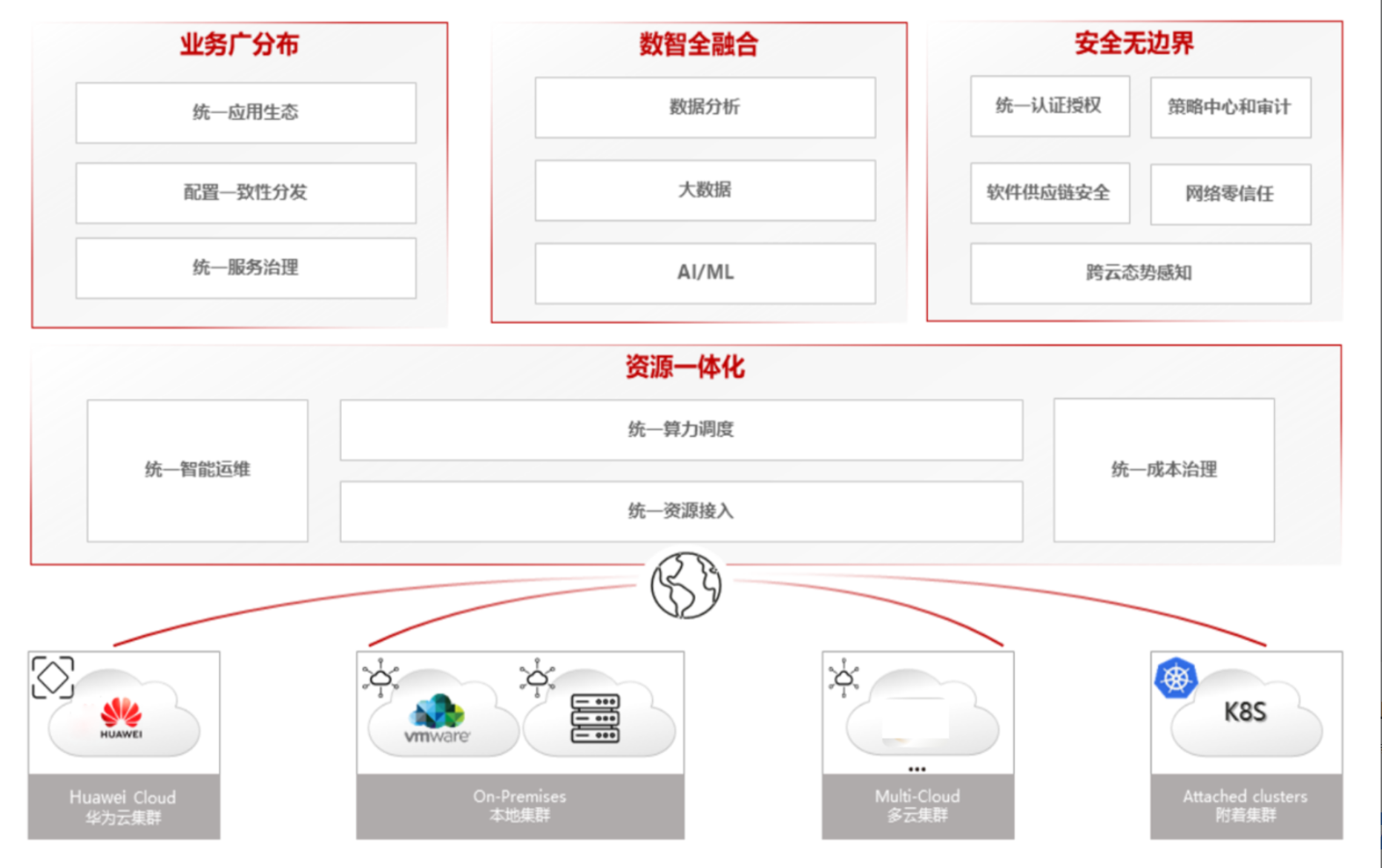
现在的业务,谁还敢把鸡蛋放一个篮子里?分布式云原生架构早就成了标配。啥叫分布式?就是你的业务不仅要在私有云里跑,还得去公有云上弹性扩容,还得去边缘节点上低延迟响应。这就导致了一个结果:你的K8s集群不再是一个孤独的岛屿,而变成了一个庞大的“群岛”。
这时候问题就来了:每个岛都有自己的Master,都有自己的API,你发个版本还得去每个岛上敲一遍命令?这要是有一百个集群,光发布版本就能把运维小哥累进ICU。而且,这些集群之间的网络通不通?策略能不能统一?资源怎么统筹?这就是Kurator要解决的根本问题——让这些零散的架构,在逻辑上变成“一整块”。
二、 既然要搞,就得搞懂它:Kurator的五脏六腑
咱们把Kurator这只“麻雀”解剖一下,看看它里面到底长啥样。
2.1 Kurator平台的总体架构与具体细节
这是Kurator平台的总体架构图,展示了控制平面、集群网络、成员集群及应用层在统一管理框架下的数据流与组件关系: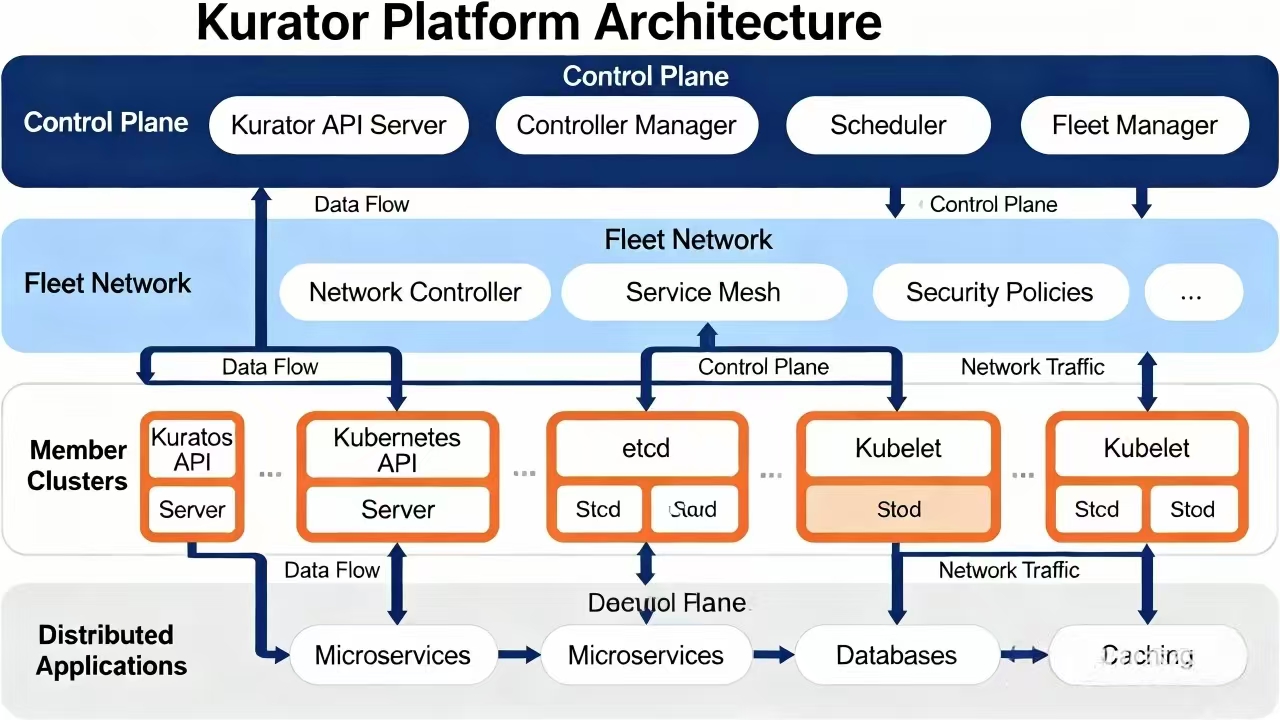
说实话,Kurator平台的总体架构设计得挺有“大厂风范”的。它不是从零造轮子,而是站在巨人的肩膀上。它最核心的一层,其实是基于Karmada搞的“多集群编排层”。在这一层之上,Kurator搞了一套自己的具体架构细节,把监控、策略、流量、存储这些全都抽象成了统一的API。
你可以把它想象成一个“三明治”结构:
- 最底层是你那些乱七八糟的基础设施(AWS、Azure、裸金属、边缘设备)。
- 中间层就是Kurator的核心,这里面有Fleet Manager(舰队管理)、Policy Enforcer(策略执行)、Unified Scheduler(统一调度)。
- 最上层就是给咱们用的统一入口,不管你是要部署应用,还是要切流量,都只跟这一层打交道。
它这个架构最骚的地方在于,它把很多复杂的开源组件(比如Prometheus、Thanos、Istio)的配置过程给屏蔽了,通过Operator的方式自动化管理,这对于咱们这种不想天天写几千行YAML配置文件的懒人来说,简直是福音。
2.2 动手时间:如何搭建环境(附实操命令)
光说不练假把式。咱们现在就来把环境搭起来。这一步是所有后续骚操作的基础。
首先,你得准备一台Linux机器(Mac也行,但有些底层依赖可能得折腾一下),Docker、Go环境、Kind或者Minikube得备好。
我们可以从github上面下载源码,我把源码标注出来啦
点击后拉到最下面就可以看到源码压缩包啦,不同需求的朋友可以下载不同平台的源码
下载下来解压就可以看到源码文件啦
代码拉下来之后,通常咱们需要编译一下或者直接用它提供的Makefile来启动一个本地的测试环境。 Kurator很贴心地提供了一键启动脚本,一般是 make deploy 或者类似的命令(具体看当时的README,开源项目变动快)。
咱们假设你已经通过官方的Guide把Control Plane跑起来了。这时候,你应该能通过 kubectl 看到一个特殊的Context,那是Kurator的控制面,而不是你本地某个具体的K8s集群。
三、 统领千军万马:舰队管理与生命周期
环境搭好了,咱们现在手里有了“帅印”,该怎么指挥底下这帮“诸侯”呢?
3.1 云原生舰队管理:把集群当宠物还是当牛马?
这张图讲的是云原生舰队管理,就是通过一个管理中心集群来统一管理多个下属集群,不管是创建、注册还是部署应用,都可以集中控制: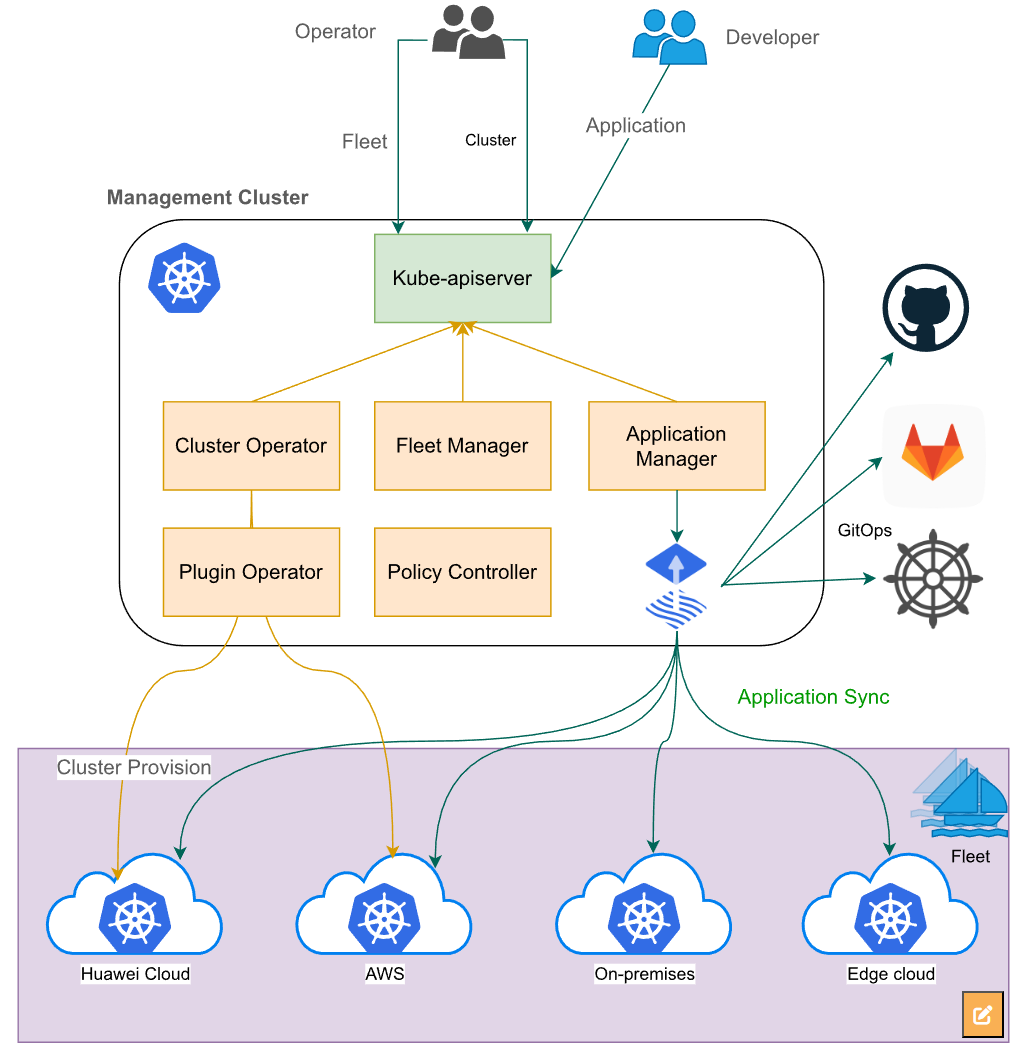
在Kurator的字典里,有个概念叫云原生舰队管理(Fleet Management)。这词儿听着挺科幻,其实道理很简单。就是把性质相似的集群打个标签,编成一个“舰队”。
比如,你可以把所有跑在边缘端的集群打上 region=edge 的标签,把所有跑AI训练任务的GPU集群打上 profile=gpu-heavy。有了这个舰队的概念,你下发任务的时候,就不用指定具体的集群名字了,直接对着舰队喊话:“喂,那个跑AI的舰队,给我腾点资源出来跑个新模型!”
这背后依靠的是Kurator强大的集群注册和发现机制。它能动态地感知到新加入的集群,并根据你预设的规则自动把它归到某个舰队里去。
3.2 Kurator集群生命周期管理与Cluster Operator的实现
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: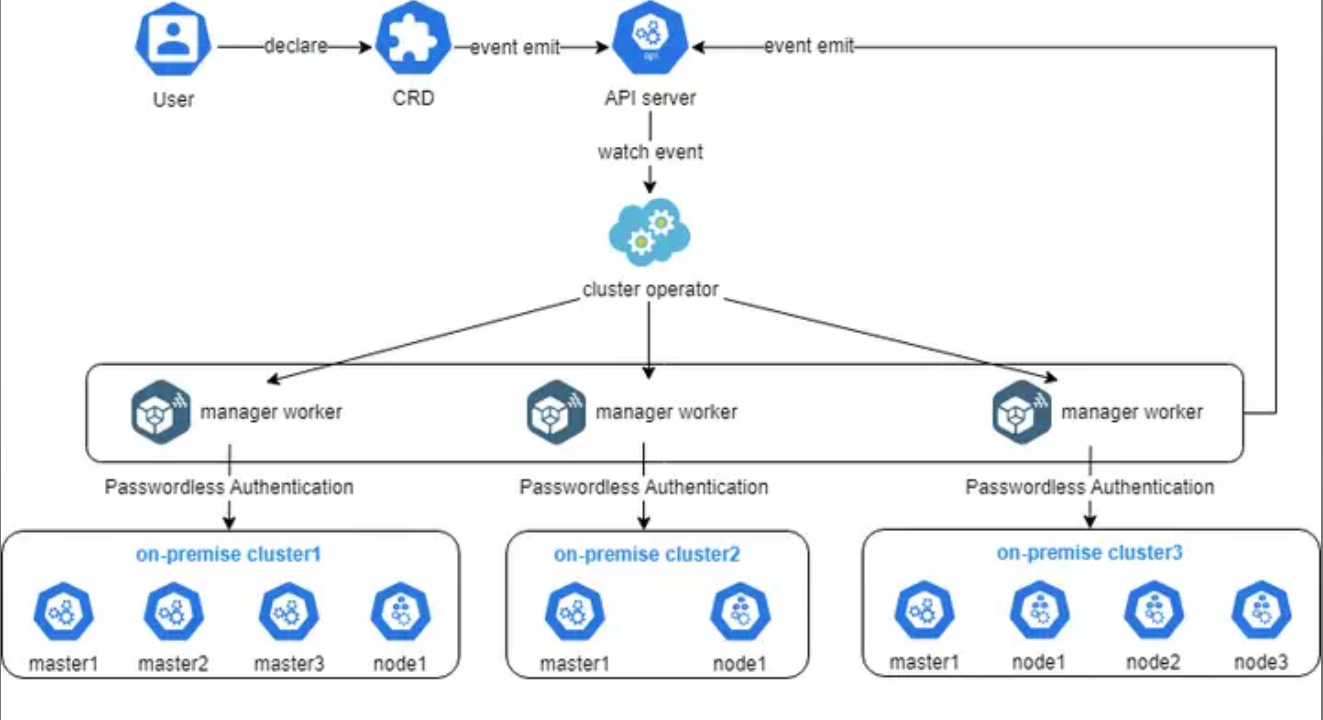
要管好舰队,首先得能把集群生出来,还得能送它走。这就是Kurator集群生命周期管理。
以前咱们建集群,要么用云厂商的控制台点点点,要么用Kubeadm自己撸。Kurator引入了一个叫Cluster Operator的实现。这玩意儿是个典型的Kubernetes Operator模式。
简单说,在Kurator眼里,一个K8s集群,就是一段YAML配置。你想建个集群?行,写个CRD(Custom Resource Definition)提交给Kurator,Kurator的Cluster Operator监听到这个请求后,就会根据你定义的驱动(比如是AWS的驱动还是裸金属的驱动),自动去调用底层的API,把机器拉起来,把K8s装好,顺便把监控探针插进去。
来看看这个Cluster定义的代码块,这可是核心中的核心,是不是一股浓浓的声明式风格:
apiVersion: clusters.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: my-edge-cluster-01
namespace: kurator-system
labels:
fleet: edge-prod
spec:
# 这里定义底层的云厂商或者驱动类型
kind: KubeadmControlPlane
# 咱们定义一下这个集群的“体格”
machineRef:
kind: MachineDeployment
spec:
replicas: 3
template:
spec:
# 就算是手搓,也得指定好镜像版本,别瞎搞
version: v1.29.0
# 网络插件一把梭,Calico走起
cni:
type: calico
# 这一段是Kurator特有的,状态同步配置
statusSync:
enabled: true
interval: 30s
这段代码扔进去,Kurator就在后台默默干活了。过一会,一个活蹦乱跳的集群就出来了。这就是“基础设施即代码”(IaC)的落地。
3.3 Kurator分发流程的状态机
你可能会问,Kurator怎么知道集群创建到哪一步了?这就涉及到Kurator分发流程的状态机。
在内部,每一个操作(创建、升级、销毁)都是一个状态机的流转。从 Pending 到 Provisioning,再到 Ready,或者不幸走到 Failed。Kurator的设计非常健壮,它会不断地Reconcile(调和)。如果中间网络断了,或者脚本卡住了,状态机会停在那个位置,不断重试,或者回滚。
这对于大规模分布式场景太重要了。你发个指令给100个集群,总有几个掉链子的。状态机保证了系统最终的一致性,不会出现“薛定谔的集群”——既存在又不存在的那种鬼样子。
四、 玩转流量与策略:不仅要管住,还得管好
集群管住了,接下来的重头戏是上面的应用怎么跑,流量怎么走。
4.1 Kurator的流量路由与AB测试配置
在多云环境下,Kurator的流量路由是基于Istio等Service Mesh组件封装的。但它不需要你写那些复杂的VirtualService或者DestinationRule。它提供了一套更上层的抽象。
咱们经常遇到的场景:新版本上线,不敢全量发布,想先让北京地区10%的用户试用一下。这就是Kurator中配置AB测试的经典场景。
你只需要定义一个简单的路由策略,Kurator会自动把它翻译成底层Istio的配置下发到各个集群的Ingress网关上。
来,看个实操的代码块,这比手写Istio配置爽多了:
apiVersion: traffic.kurator.dev/v1beta1
kind: GlobalTrafficRoute
metadata:
name: payment-service-canary
spec:
hosts:
- "payment.example.com"
gateways:
- public-gateway
http:
- match:
- headers:
# 只有带这个Header的请求才走灰度
# 比如咱们内部测试人员的特定Cookie
x-user-group:
exact: "internal-tester"
route:
- destination:
host: payment-service
subset: v2-beta
port:
number: 8080
- route:
# 其他吃瓜群众还是走老版本,稳字当头
- destination:
host: payment-service
subset: v1-stable
port:
number: 8080
这段配置一下发,流量瞬间就被精准切分了。在Kurator的架构里,这种策略是全局生效的,不管你的Service具体跑在哪个集群里,流量都能被准确地调度过去。
4.2 Kurator的统一策略管理架构
刚才说了流量策略,其实还有安全策略、配额策略等等。这就是Kurator的统一策略管理架构。它集成了OPA(Open Policy Agent)或者Kyverno。
这意味着你可以制定一条“天条”:所有生产环境的Pod,必须限制CPU和内存使用量,且镜像必须来自公司内部的Harbor仓库。这条策略一旦下发,所有被Kurator管理的集群都会生效。谁要是敢违规部署,直接被Admission Controller拦截,连门都进不去。这种“中央集权”式的策略管理,是治理大规模集群的必要手段。
4.3 Volcano分组调度:算力别浪费
最后,咱们得聊聊算力。对于搞AI或者大数据的老铁,Volcano分组调度绝对是个神器。标准的K8s调度器也就是按Pod一个个塞,而Volcano懂“业务逻辑”。
在Kurator里,集成了Volcano的能力。比如你有一个AI训练任务,需要10个Worker同时跑,少一个都跑不起来。标准调度器可能会傻乎乎地先调度5个,然后在那死等剩下5个资源,占着茅坑不拉屎。Volcano的Gang Scheduling(帮派调度)机制,要么这10个一起上,要么大家都别上,排队等着。
这就是在Kurator中定义Volcano Job的感觉:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: deep-learning-training-job
spec:
minAvailable: 3
schedulerName: volcano
# 这里定义了分组调度的核心逻辑
plugins:
gang: {}
env: []
svc: []
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- image: my-ai-repo/tensorflow:2.4
name: ps
command: ["sh", "-c", "python ps.py"]
- replicas: 2
name: worker
# 这里的配置要跟你实际的GPU资源对齐
template:
spec:
containers:
- image: my-ai-repo/tensorflow:2.4
name: worker
command: ["sh", "-c", "python worker.py"]
resources:
limits:
nvidia.com/gpu: 1
通过这种方式,Kurator不仅管了集群的生命,还管了集群里每一分算力的使用效率。
结尾:路漫漫其修远兮
写到这,你会发现,Kurator这东西,其实就是把咱们平时在多云、混合云环境里遇到的那些碎碎念的痛点,用一套系统化的架构给封装起来了。它不神秘,但很实用。
从底层的集群生命周期,到中间的策略治理,再到上层的流量和算力调度,Kurator提供了一整套“瑞士军刀”。当然,技术这东西,更新换代快得很。今儿咱们手搓的这些配置,可能明年就有了更简洁的写法。
但核心的思路是不变的:统一视图、自动化运维、策略驱动。掌握了这三点,不管它工具怎么变,你都能稳稳地做个“云原生老司机”。
行了,代码也敲了,原理也唠了。剩下的,就靠兄弟们自己去实战里摸爬滚打了。记住,报错了别慌,看日志,看状态机,总能找到坑在哪!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)