别再手撸K8s集群联邦了,今天带你用Kurator把多云管理、边缘计算和流量治理一锅端,实战干货满满绝无尿点!
别再手撸K8s集群联邦了,今天带你用Kurator把多云管理、边缘计算和流量治理一锅端,实战干货满满绝无尿点!
今天咱们不扯那些在大厂高层会议上才会出现的“降本增效”黑话。今天咱们就聊点实实在在的——如果你手头上有好几个Kubernetes集群,或者你正准备把业务往多云环境、边缘节点上铺,那你是不是觉得头发掉得比平时更快了?配置在这个集群跑得好好的,推到那个集群就报错;想做个统一的策略限制,结果得登录十几个控制台手动敲命令。说实话,这种苦日子我以前也熬过。
直到我碰到了Kurator。这玩意儿说白了,就是给咱们这些苦逼运维和DevOps准备的一把“瑞士军刀”。它不是为了造轮子而造轮子,而是把Karmada、Istio、Volcano这些咱们耳熟能详的神器,用一种非常优雅的方式串联在了一起。你可以把它想象成一个经验丰富的老管家,你只管下命令,它负责去跟下面那些脾气各异的集群(无论是公有云的、私有云的还是边缘的)打交道。今天,我就手把手带着大家,从零开始,在你的机器上把Kurator跑起来,顺便把它的那些核心黑科技——什么统一策略、流量治理、边缘计算——统统撸一遍。准备好咖啡,咱们开整!
一、 揭开Kurator的面纱:它到底是不是你的那盘菜?
在咱们正式敲命令之前,我得先给大伙儿理一理思路。咱们现在面临的环境,早就不再是单打独斗的时代了,这是一个分布式云原生架构横行的年代。
1.1 分布式云原生架构的“诸侯割据”时代
以前咱们玩K8s,顶多就是Master节点挂了修一修,Worker节点资源不够了扩一扩。但现在呢?业务方一会要求“在这个区域要低延迟”,一会要求“那个数据不能出境”,逼得咱们不得不搞多集群。结果呢,集群之间就像是战国时期的诸侯,各自为政。版本不一致、CNI插件不同、甚至连CRD的定义都有微妙的差别。这就是典型的“诸侯割据”。
这时候,你需要一个“盟主”。Kurator架构的设计初衷,就是为了当这个盟主。它不是简单地把工具堆在一起,而是基于开源生态,构建了一个统一的分布式云原生控制平面。你可以去Kurator开源项目的GitHub主页上看看它的Roadmap,那上面画的饼……啊不,规划,非常清晰:从基础设施的统一,到应用的统一分发,再到流量和策略的统一治理,它全包了。
这是Kurator开源项目的GitHub主页概览,展示了其统一分布式云管理的核心定位、活跃的开发动态及社区贡献情况: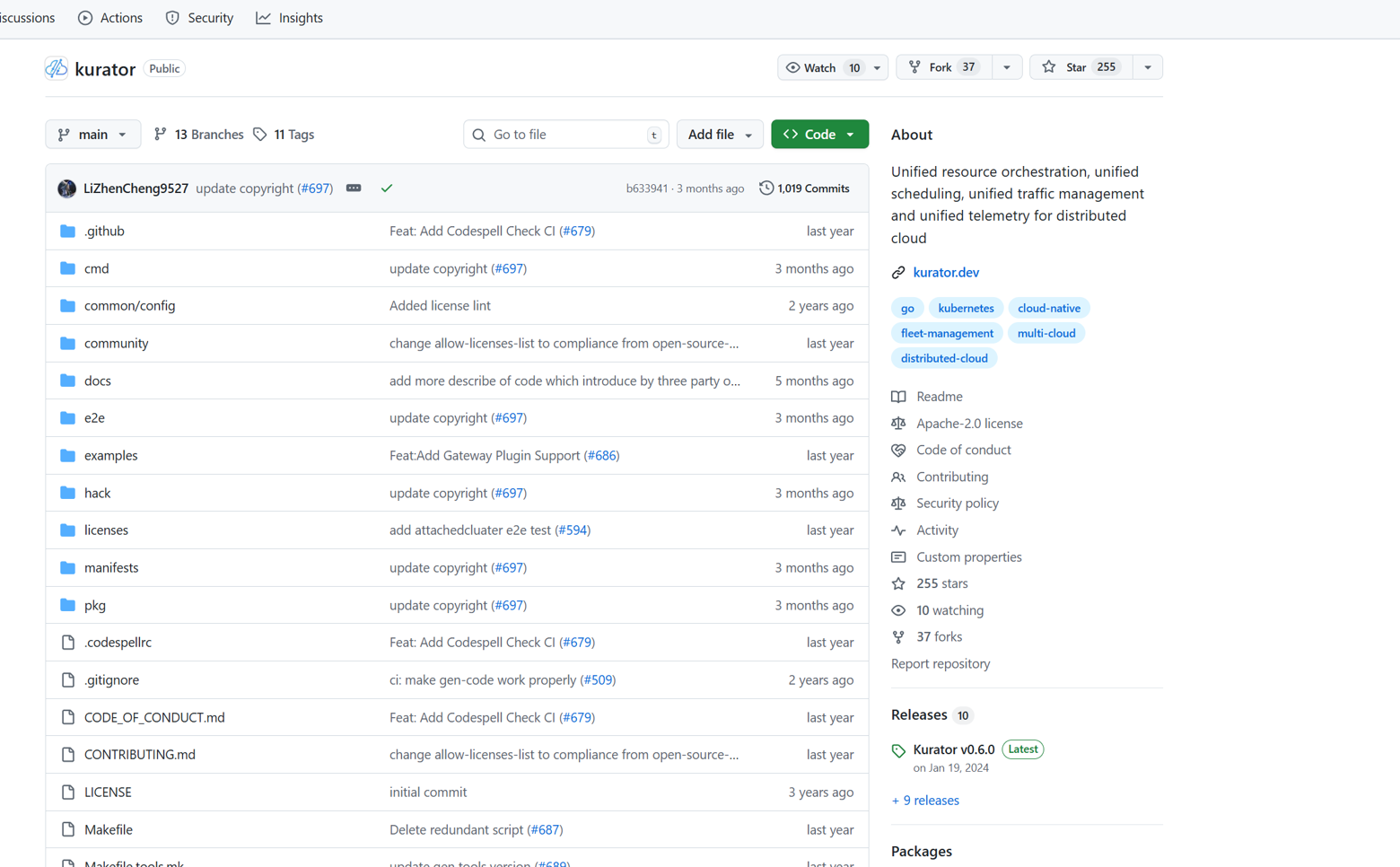
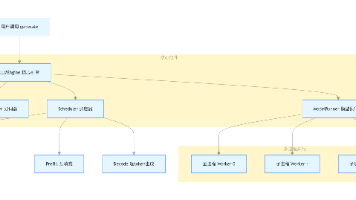
1.2 Kurator的统一策略管理架构
这张图展示了Kurator的统一策略管理架构,用户只需要在一处定义策略,就能通过Fleet和FluxCD自动同步到多个集群,配合Kyverno实现跨集群的一致性治理,真正做到“一次配置,全栈生效”: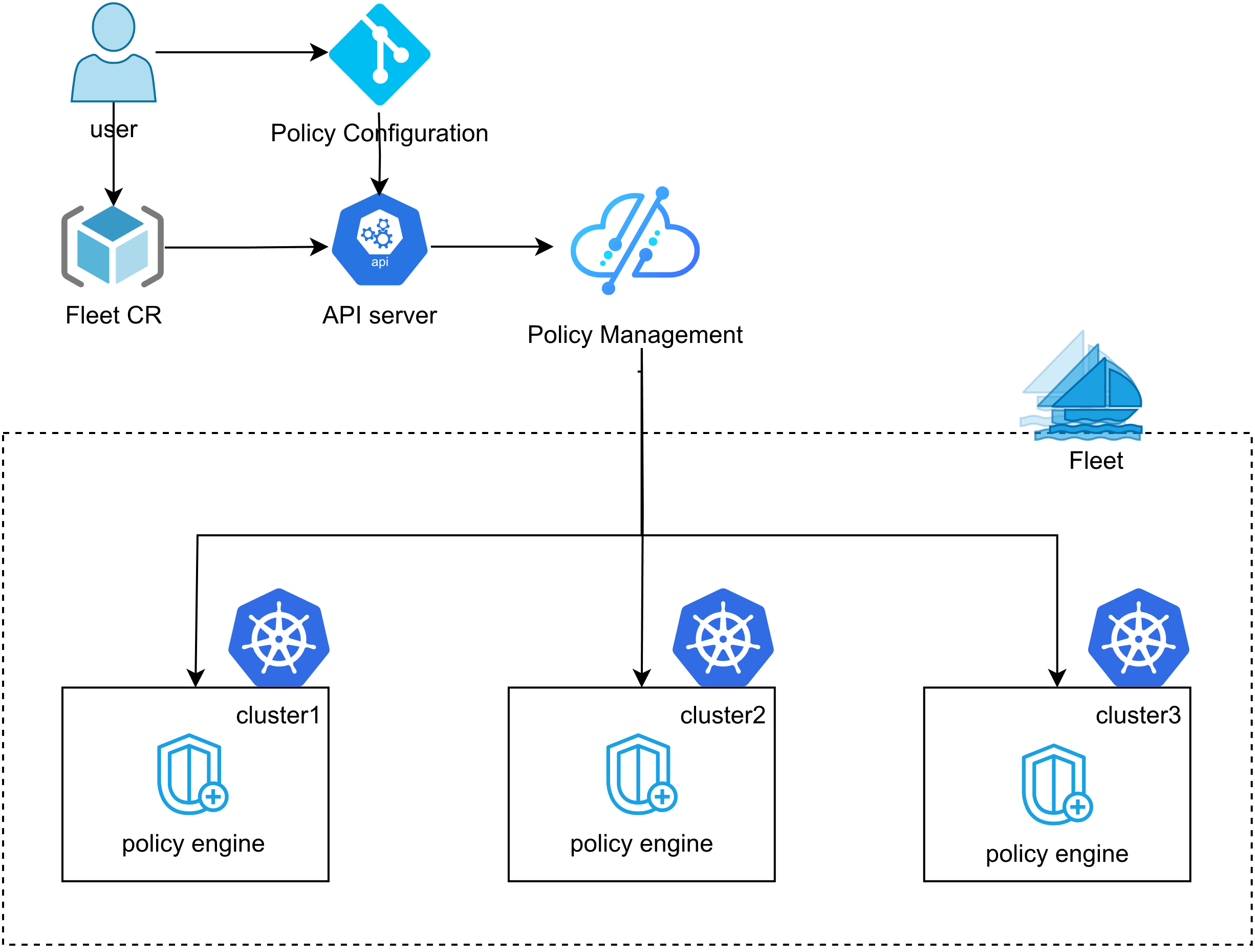
我最喜欢Kurator的一点,就是它的Kurator统一策略管理架构。咱们做运维的最怕什么?怕“漏网之鱼”。你在A集群封锁了特权容器,结果B集群忘了配,黑客就从B集群进来了。Kurator允许你定义一次策略,然后像撒网一样,自动把这些规则同步到所有纳管的集群里。它底层整合了OPA Gatekeeper或者Kyverno(看你喜好,不过Kurator在Fleet集成上对Kyverno支持得挺有意思,后面细说),让你在中心端就能看到所有集群的合规状态。这感觉,就像是站在指挥塔上,看着底下的士兵整齐划一地执行命令,贼爽。
二、 撸起袖子干:从零搭建你的Kurator控制平面
光说不练假把式。现在,打开你的终端,咱们开始干活。别担心环境复杂,只要你有一台能联网的Linux机器(甚至虚拟机都行),装着Docker和Kind,咱们就能搞定。
2.1 环境准备与仓库克隆
这一步是所有神话开始的地方。咱们得先把Kurator的源码搞下来。注意了,网络环境不好的兄弟,我特意给你们找了个国内的加速地址,别总是盯着GitHub转圈圈了。
来,跟着我敲:
# 创建一个工作目录,保持习惯良好
mkdir -p ~/workspace/kurator-lab
cd ~/workspace/kurator-lab
# 这一步很关键,克隆代码仓库
# 咱们用gitcode的镜像,速度杠杠的
git clone https://gitcode.com/kurator-dev/kurator.git
# 进目录,准备开搞
cd kurator
# 看看分支,确保咱们在主干或者稳定分支上
git branch
如果这个方法拉取不到的话,也可以用wget的方法拉取
# 下载最新源代码zip包
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
然后再解压文件
unzip main.zip
源码下载下来以后我们可以开始玩耍啦,接下来我们拿着源码就可以进行其他设置操作了。
2.2 Kurator分发流程的状态机机制
在等待依赖下载的时候(这通常取决于你的网速),我得跟你们聊聊Kurator安装过程中一个很精妙的设计:Kurator分发流程的状态机。
很多部署工具是脚本式的,跑错了就挂在那,你也不知道它卡在第几步。Kurator引入了状态机(State Machine)的概念来管理集群和组件的生命周期。比如,当你发出一路“创建一个集群”的指令时,系统内部会生成一个对象,这个对象的状态会从 Provisioning(准备中)流转到 Bootstrapping(引导中),再到 Ready(就绪)。如果中间哪一步卡住了,比如网络不通,它会停留在 Stalled 或者 Error 状态,并且会告诉你卡在哪了。
这种设计让排错变得非常容易。你在实操中如果发现安装卡住了,直接去查相关CRD的状态字段,一目了然。
2.3 实战:初始化控制平面
咱们假设你已经装好了Go环境和Kind。下面我们用Kurator提供的Makefile来快速拉起一个本地的测试环境。
这里我给大家提供一段我自己常用的、略带“手搓感”的Makefile覆盖配置,用来加速本地的镜像拉取(这可是实战摸索出来的坑啊):
# 这是一个临时的配置覆盖片段,建议放在你自己的local.mk里
# 主要是为了替换掉那些死慢死慢的gcr.io镜像源
export KURATOR_IMAGE_REGISTRY ?= registry.cn-hangzhou.aliyuncs.com/google_containers
export ISTIO_HUB ?= docker.io/istio
# 启动本地集群的快捷指令
.PHONY: setup-local-cluster
setup-local-cluster:
@echo "正在启动Kurator控制平面,老铁稍安勿躁..."
@kind create cluster --name kurator-control-plane --config ./config/kind-config.yaml
@echo "集群已就绪,开始注入灵魂(安装组件)..."
@kubectl apply -f ./config/crds/
@echo "组件安装完毕,准备起飞!"
你运行 make setup-local-cluster 后,稍等片刻,一个包含Kurator核心组件的控制平面就在你的Docker里跑起来了。
三、 给集群装上“大脑”:Karmada的多集群调度艺术
控制平面有了,接下来咱们得纳管集群。这时候,Kurator背后的核心引擎——Karmada多集群管理平台的核心架构就该登场了。
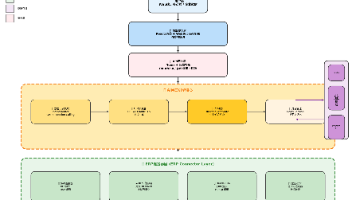
3.1 深入Karmada多集群管理平台的核心架构
这是Karmada多集群管理平台的核心架构图,展示了控制平面如何通过推送和拉取两种模式与成员集群进行协同管理: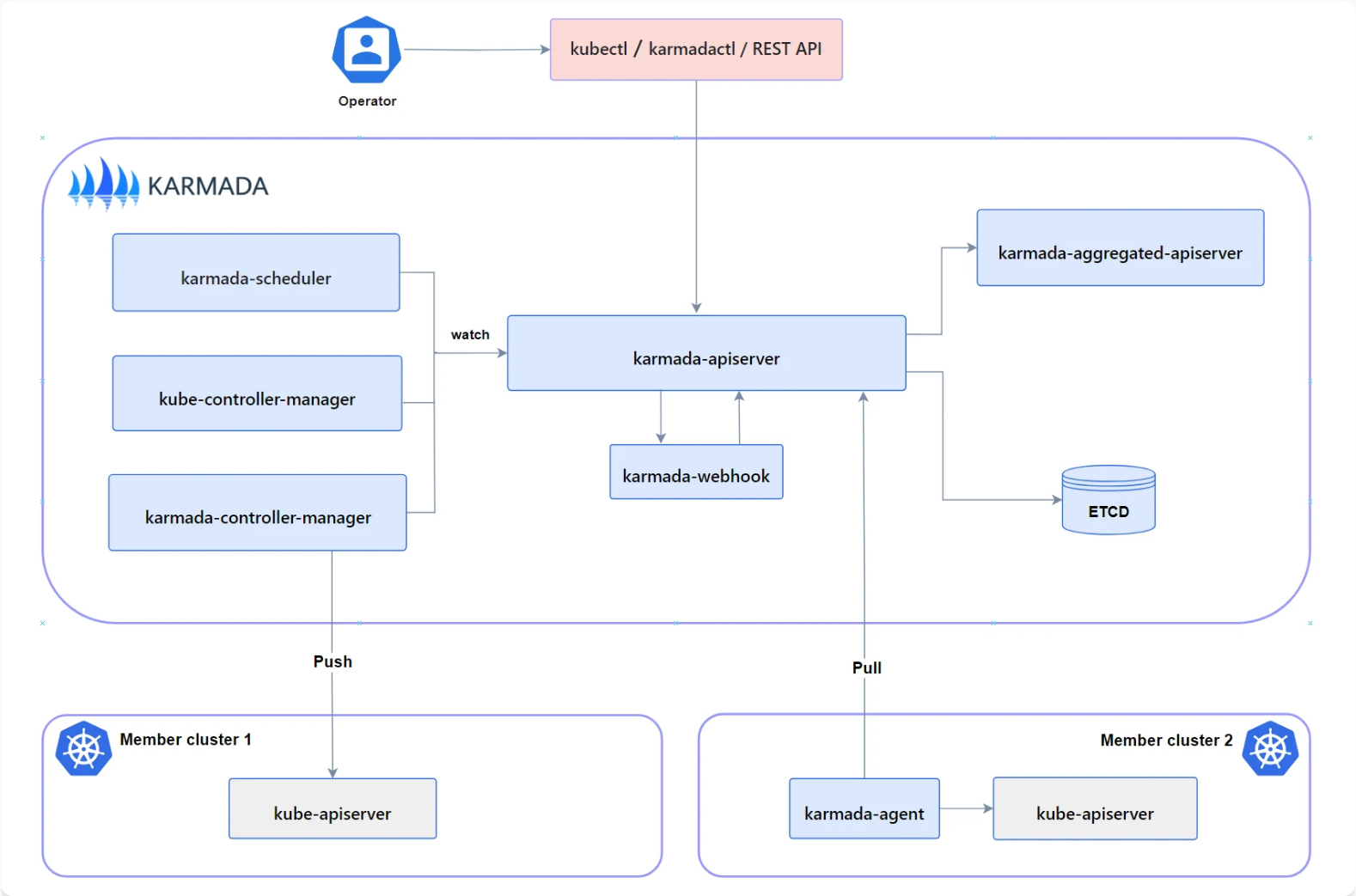
Kurator之所以强大,是因为它并没有重复造轮子,而是站在了Karmada的肩膀上。Karmada的核心架构其实就做了一件事:把“资源模板”和“部署策略”分开。
在单集群里,你写个Deployment,它就跑了。在多集群里,你写个Deployment,Karmada会把它拦截下来,把它变成一个“资源模板”(Resource Template)。然后,你再写一个“传播策略”(PropagationPolicy),告诉Karmada:“嘿,把这个模板给我发到区域A的集群和区域B的集群去。”
Karmada的调度器会根据集群的剩余资源、污点容忍度等信息,动态地决定把Pod发到哪。这就是所谓的“上帝视角”。
3.2 玩转Karmada跨集群弹性伸缩策略
这是Karmada跨集群弹性伸缩策略参考图,展示了其如何通过FederatedHPA策略在多个成员集群间协调Pod副本数实现统一伸缩: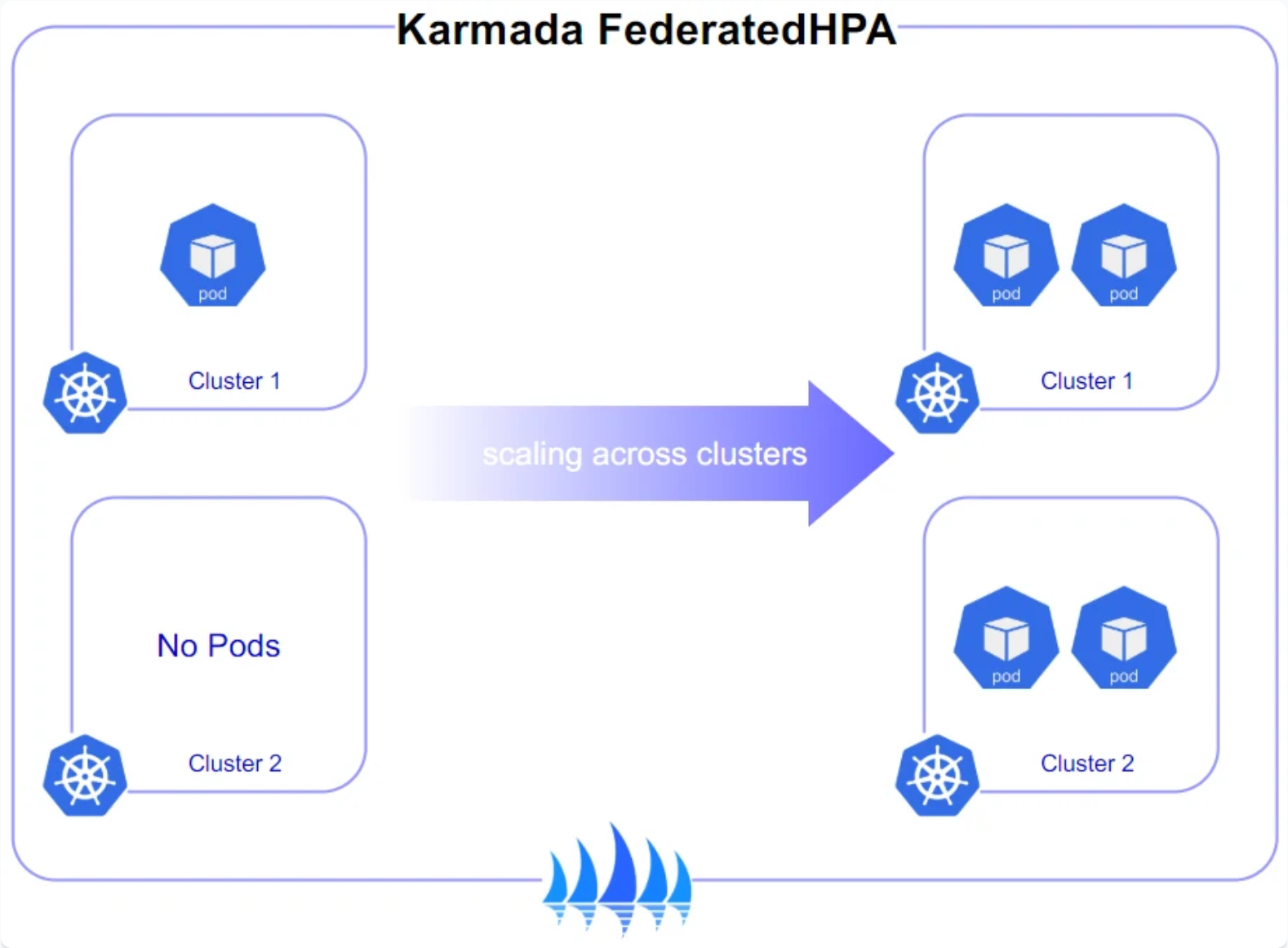
实战中,我们最常用的功能就是Karmada跨集群弹性伸缩策略(FederatedHPA)。想象一下,你的业务在阿里云上爆了,资源吃紧,而你在腾讯云上的备用集群还空着大把资源。
通过Kurator配置FederatedHPA,你可以实现这样的效果:当主集群CPU使用率超过80%时,自动把扩容出来的Pod调度到备用集群去。这完全是自动的,应用层毫无感知。
下面这段代码,展示了如何定义一个跨集群的传播策略,这可是生产环境级别的配置:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-cross-cloud-spread
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx-app
placement:
clusterAffinities:
- policy:
fieldSelection:
# 这里利用Label选择特定的集群组
expression: provider in (aliyun, tencent)
replicaScheduling:
# 动态权重策略:优先填满aliyun,剩下的去tencent
# 这就是省钱的秘诀啊兄弟们!
replicaDivisionPreference: Weighted
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member-aliyun
weight: 10
- targetCluster:
clusterNames:
- member-tencent
weight: 1
把这个YAML一贴,Karmada就会按照10:1的比例把流量(通过Pod数量)分摊到两个云厂商的集群里。
四、 进阶玩法:流量治理与算力优化的双重奏
集群管好了,Pod分发出去了,但事儿还没完。网络通不通?算力浪费没浪费?这就涉及到了Istio服务网格和Volcano分组调度。
4.1 Istio服务网格的跨集群互通
这是Istio服务网格的参考架构图,展示了服务间通过Envoy代理进行通信,并由统一控制平面提供发现、配置与安全策略: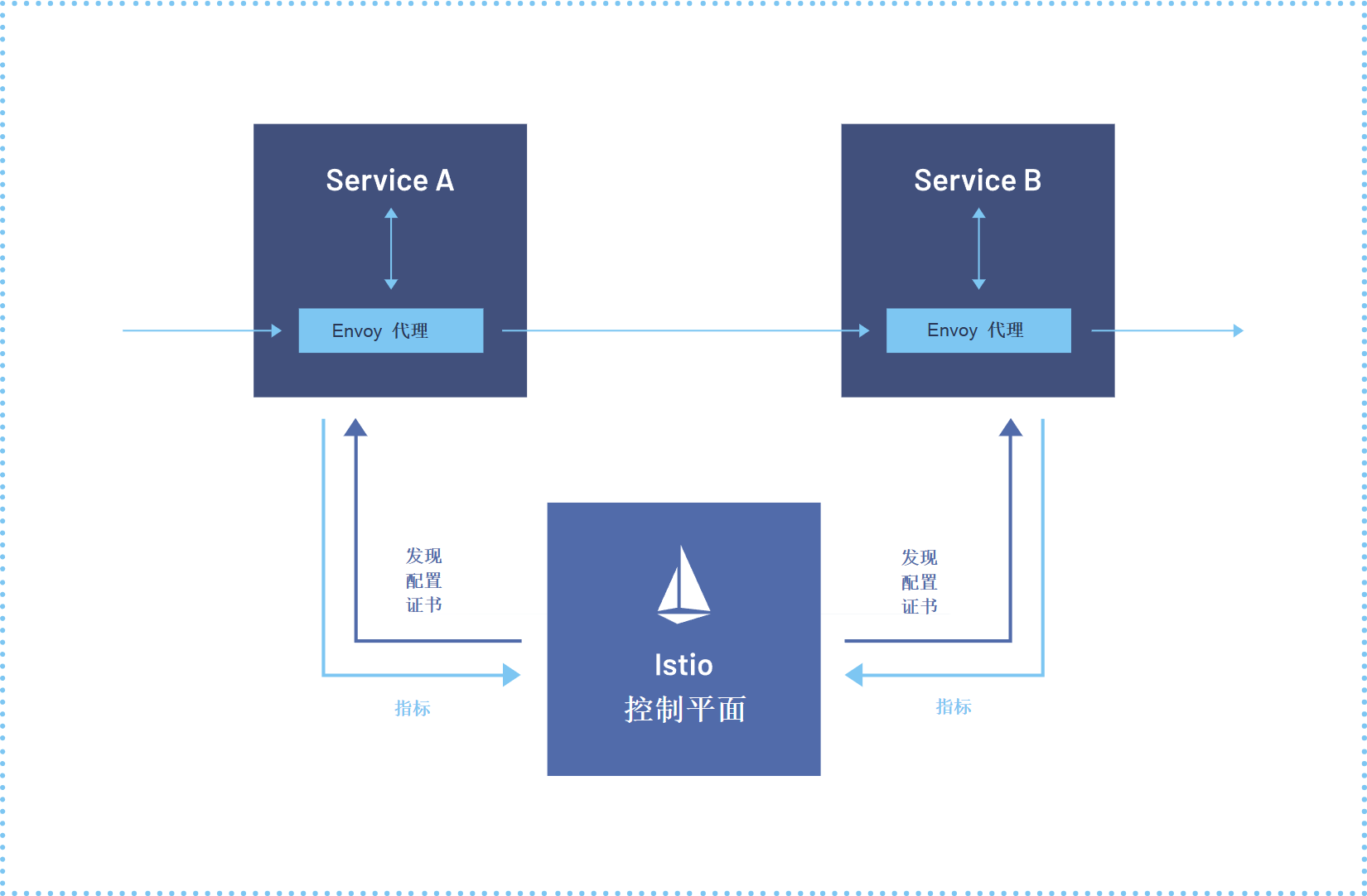
Kurator集成了Istio,这让跨集群的服务治理变得简单多了。在没有Kurator之前,你要打通两个集群的Pod网络,得配一堆东西:Gateway、VirtualService、DestinationRule,还得搞定证书信任问题,搞得人头大。
Kurator通过内置的Istio Operator,帮你自动处理了多集群Mesh的配置。它采用的是多主架构或者主从架构(看你配置),核心目标就是让集群A里的服务访问 service-b.default.svc.cluster.local 时,能透明地路由到集群B去。
实操心得:一定要注意Global Sidecar的配置。如果你的Pod要跨集群调用,必须保证它们在同一个Trust Domain下,否则MTLS握手直接失败,查日志能查到你怀疑人生。
4.2 Volcano分组调度在AI训练中的应用
这是Volcano分组调度参考图,展示了其如何通过整体资源检查与阈值判断,实现批处理作业的成组调度与资源保障: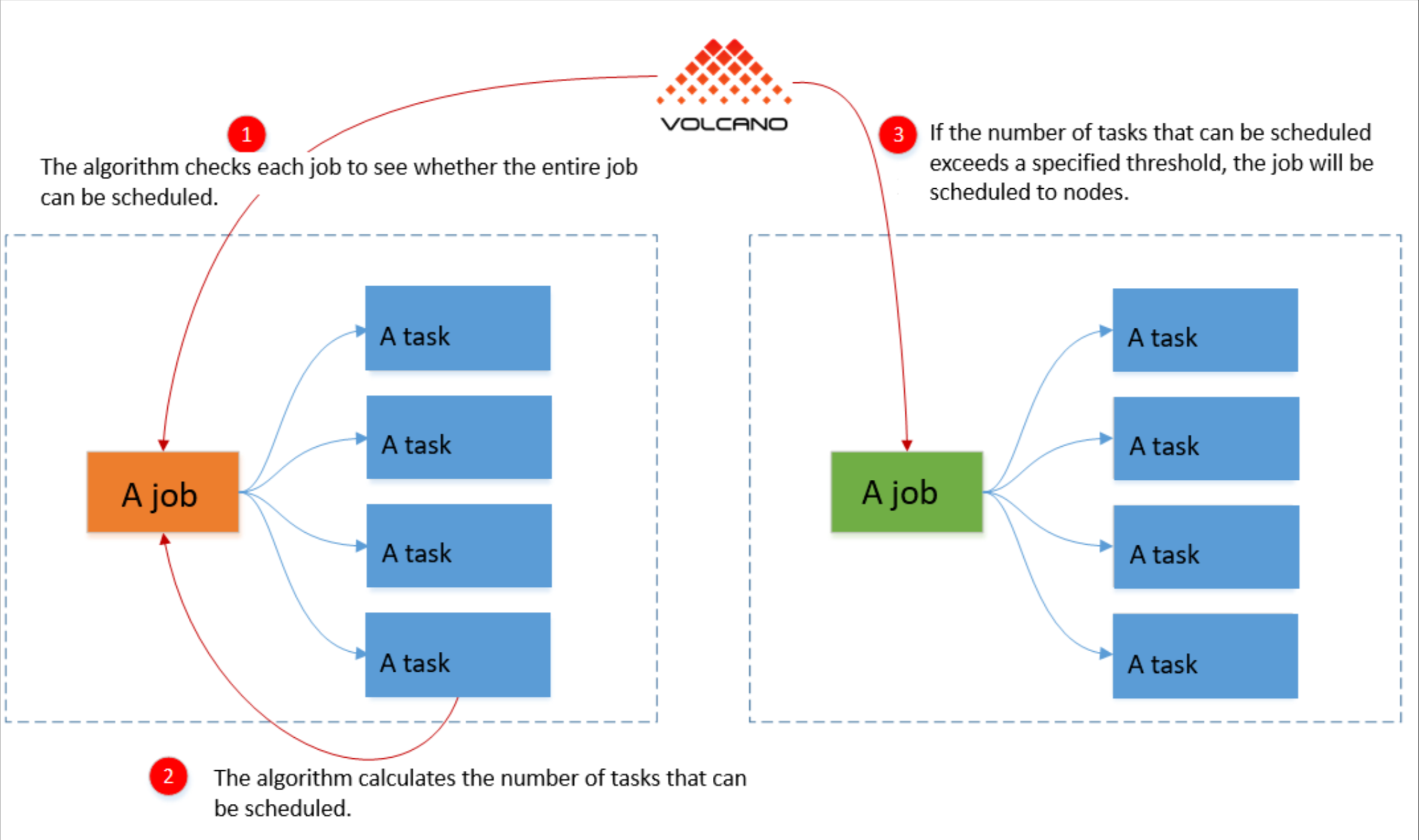
现在AI这么火,很多公司都在K8s上跑训练任务。默认的K8s调度器对于批处理任务其实挺笨的——它是一个个调度Pod的。如果你有一个TensorFlow任务需要10个Pod同时跑,K8s凑够了5个就先跑起来,结果这5个傻等着另外5个,死锁了,资源还占着。
这就是Volcano分组调度(Gang Scheduling)的用武之地。Kurator集成了Volcano,允许你定义一个“作业组”。要么这10个Pod都有资源,一起启动;要么就一个都别动,排队等着。
我们在Kurator中启用Volcano后,只需要在Pod的Annotation里加一行 scheduling.k8s.io/group-name,就能立刻享受到这种高效的调度策略,对于昂贵的GPU资源来说,这简直就是救命稻草。
五、 守好最后一道防线:策略统一与边缘GitOps
最后,咱们聊聊安全和边缘计算。这年头,不提边缘计算都不好意思说自己是搞云原生的。
5.1 Fleet队列中身份相同性与Kyverno架构
这里有个比较深的概念,叫Fleet队列中身份相同性。Fleet是Rancher开源的一个GitOps工具,Kurator用它来做大规模的集群管理。当管理成千上万个集群时,如何确认“你就是你”?Fleet通过一种独特的Agent机制,确保每个注册上来的集群在控制平面都有唯一的Identity,而且这个Identity在队列处理中是保持一致的。
基于这个身份,Kurator结合了Fleet基于Kyverno的多集群策略管理架构。Kyverno是K8s原生的策略引擎。Kurator利用Fleet的管道,把Kyverno的ClusterPolicy分发到每一个边缘集群。
比如,你想禁止所有边缘节点拉取 latest 标签的镜像。你只需要在Kurator中心写一条策略,Fleet就会利用它的GitOps机制,把这条策略同步到每一个边缘集群的Kyverno里。
5.2 GitOps边缘计算的落地姿势
GitOps边缘计算的核心在于“弱网环境的容忍度”。边缘节点(比如工厂里的工控机、高速公路上的摄像头网关)网络经常断。如果你用传统的Push模式,网络一断,运维就瞎了。
Kurator推崇的GitOps模式是Pull模式。边缘节点的Agent只要网通了,就会主动去Git仓库(或者OCI仓库)拉取最新的配置。断网了没事,保持现状运行;网通了,自动通过Kurator分发流程的状态机进行自愈和更新。
最后,给大家展示一段针对边缘环境的Kyverno策略代码,这可是防止边缘节点被小白乱搞的利器:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: disallow-root-user-edge
annotations:
# 这是一个自定义注释,配合Kurator的UI展示
policies.kurator.dev/description: "边缘节点严禁使用Root用户运行容器,安全第一!"
spec:
validationFailureAction: Enforce
background: true
rules:
- name: check-runasnonroot
match:
resources:
kinds:
- Pod
validate:
message: "大哥,边缘环境咱别闹,禁止用Root跑容器,赶紧改Dockerfile!"
pattern:
spec:
securityContext:
runAsNonRoot: true
containers:
- =(securityContext):
=(runAsNonRoot): true
当你把这段代码提交到Kurator管理的Git仓库中,Fleet会感知到变化,并把它推送到所有打上了 env=edge 标签的集群中。如果有开发人员试图在边缘节点部署Root容器,Pod直接就会被拒绝创建,并收到上面那条“亲切”的报错信息。
结语:路漫漫其修远兮,Kurator带你飞
写到这,咱们这篇实操指南也差不多该收尾了。从环境搭建到Karmada调度,从Istio流量治理到Volcano算力优化,最后到Fleet+Kyverno的安全底座,咱们把Kurator的核心能力几乎摸了个遍。
说实话,云原生技术栈迭代太快了,今天学的东西明天可能就变了。但Kurator架构所倡导的这种“统一管理、分层治理”的思想,是未来很长一段时间的主流。
希望这篇博文能成为你上手Kurator的一块敲门砖。别光看不练,赶紧把上面的代码敲一遍,遇到坑了去GitHub提Issue,或者在社区里吼一嗓子。咱们做技术的,不怕遇到问题,就怕停在原地不动。
好了,今天的分享就到这。如果你觉得这文章对你有那么一点点帮助,别忘了去Kurator开源项目的GitHub主页点个Star,这对开源维护者来说就是最大的鼓励!咱们下次见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)