【探索实战】把多集群运维变成声明式:Kurator分布式云原生从0到1深度实战指南
【探索实战】把多集群运维变成声明式:Kurator分布式云原生从0到1深度实战指南
【探索实战】把多集群运维变成声明式:Kurator分布式云原生从0到1深度实战指南

以“Kurator·云原生实战派”为主线,我会先把 Kurator 的能力拼图讲清楚,再给出一套可复刻的本地三集群实验环境,最后用集群生命周期治理 + 统一应用分发 + 统一流量治理 + 统一监控与统一策略串成一条完整的工程化闭环。
说明:文中命令与示例主要参考 Kurator 官方文档与仓库示例(例如文档中出现的 0.6.0 相关安装方式);不同版本细节可能会变化,落地时以你实际使用的版本与文档为准。
一、Kurator 到底在管什么:把“分布式云原生”讲透
1.1 分布式云原生的“真痛点”:不是多集群,而是多套标准
很多团队第一次接触“分布式云原生”时,关注点会落在“我有很多集群、很多云、还有边缘节点”。但真正的复杂度通常来自三类不一致:
- 资源与应用标准不一致:A 集群用 Helm,B 集群用 Kustomize,C 集群直接 kubectl apply;上线流程、回滚策略、审计路径都不一致,运维越做越像“手工艺”。
- 治理能力不一致:安全基线在生产集群做了,测试集群没做;指标在核心集群有,边缘集群没有;流量治理更是“各自为战”。
- 生命周期与责任边界不一致:谁来创建集群?谁来升级?谁能删?出了事怎么追溯?这些问题最后都会变成组织级摩擦成本。
Kurator 的价值,不是“再提供一个多集群工具”,而是把这些“不一致”变成可声明、可组合、可审计、可复制的能力单元。
1.2 Kurator 的能力拼图:集成不是堆料,而是“统一控制面”
官方对 Kurator 的描述很明确:它是一个开源的分布式云原生平台,集成 Kubernetes、Karmada、Istio、Prometheus、FluxCD、Kyverno、KubeEdge、Volcano 等生态组件,并提供多云多集群的统一能力(资源编排、调度、流量、可观测等)。
这里我给一个“实战派”解读:Kurator 更像是一个平台工程(Platform Engineering)风格的集成控制面——你不需要逐个拼装组件、再写胶水代码把它们串起来,而是通过 Kurator 的安装命令、CRD/API 与 Fleet 化的管理对象,把能力以“套餐”的方式落到多个集群上。
详细部分可以看看Kurator官网,可以查看一下Kurator组成部分和一些文献参考:
1.3 我眼里的 Kurator:把平台能力做成“可运营的产品”
如果把云原生平台当产品来做,Kurator 最有意思的点在于它强调:
- 可复制:一个 fleet(舰队)就是一套标准化能力的复制单元。
- 可组合:应用分发、策略、监控、备份、网络等能力以插件/配置的方式组合进 fleet(从 API 参考也能看到 plugin 的结构化配置)。
- 可运营:不仅“能装”,还强调统一状态视图、统一策略执行结果(例如 policy report)、统一应用交付过程等。
二、从源码到可跑:本地三集群实验环境搭建
目标:在一台开发机/VM 上搭出 1 个 host(管理/承载控制面)+ 2 个 member(成员集群) 的最小实验场。后续所有实战都在这个场里完成。
2.1 获取 Kurator 源码(按要求包含 wget 或 git clone)
你可以二选一(我建议直接 git clone,方便跟进 examples 与脚本;但内网环境用 wget zip 也很常见)。
# 方式1:wget 拉 zip(按题目要求)
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
# 方式2:git clone(按题目要求)
git clone https://github.com/kurator-dev/kurator.git
cd kurator
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
随后建议先粗看一下仓库里的 examples/ 与 hack/ 目录:前者是 CRD/能力示例的“素材库”,后者通常是快速拉起环境的“脚手架”。
2.2 一键创建三集群:本地脚本的价值是“把前置依赖压缩成固定动作”
Kurator 文档里给了一个典型路径:通过仓库脚本创建三个集群(一个用于承载 Karmada 控制面,两个作为 member 加入)。
# 在 kurator 仓库根目录
hack/local-dev-setup.sh
实战建议(经验向):
- 给 Docker/Container Runtime 足够资源:Kind 方案下常见问题是容器运行时资源不足导致核心组件 Pending / CrashLoop。
- 提前准备 kubeconfig 落盘位置:后面 Fleet/AttachedCluster 会用到 kubeconfig 文件创建 secret(这一步如果路径乱了,你会在“明明集群起来了但注册不上”里浪费时间)。
2.3 安装 CLI + 两个高频坑位(inotify 与 kubeconfig 路径)
Kurator CLI 官方文档支持从源码构建 kurator 可执行文件。
make kurator
sudo mv ./out/linux-amd64/kurator /usr/local/bin/
kurator version
坑位 A:inotify 限制导致控制器/组件行为异常
Kurator 在本地环境部署时提示过需要调整 fs.inotify.max_user_watches 与 fs.inotify.max_user_instances。
# 临时生效(重启后失效)
sudo sysctl -w fs.inotify.max_user_watches=524288
sudo sysctl -w fs.inotify.max_user_instances=8192
坑位 B:kubeconfig “看似存在但实际不可用”
很多人会踩:文件路径对了,但 kubeconfig 内的 server 地址在容器网络下不可达,导致后续 join 或 attachedCluster 访问失败。解决思路:
- 确认 kubeconfig 的 server 是对你当前执行命令的主机可达的地址;
- 如果是 Kind,检查是否需要
--kubeconfig指定到脚本生成的 host kubeconfig(文档也提示“用脚本部署 kubernetes 时 kubeconfig 是 kurator-host.config”)。
三、集群生命周期治理:Cluster Operator 把“装 K8s”变成声明式
Kurator 的“集群生命周期治理”不是一句口号。它把“创建/删除/升级/扩缩容”这类高风险动作,从手工脚本升级为声明式资源 + 控制器调谐。
详细可以见Kurator集群生命周期管理参考图,朋友们可以更清晰的了解: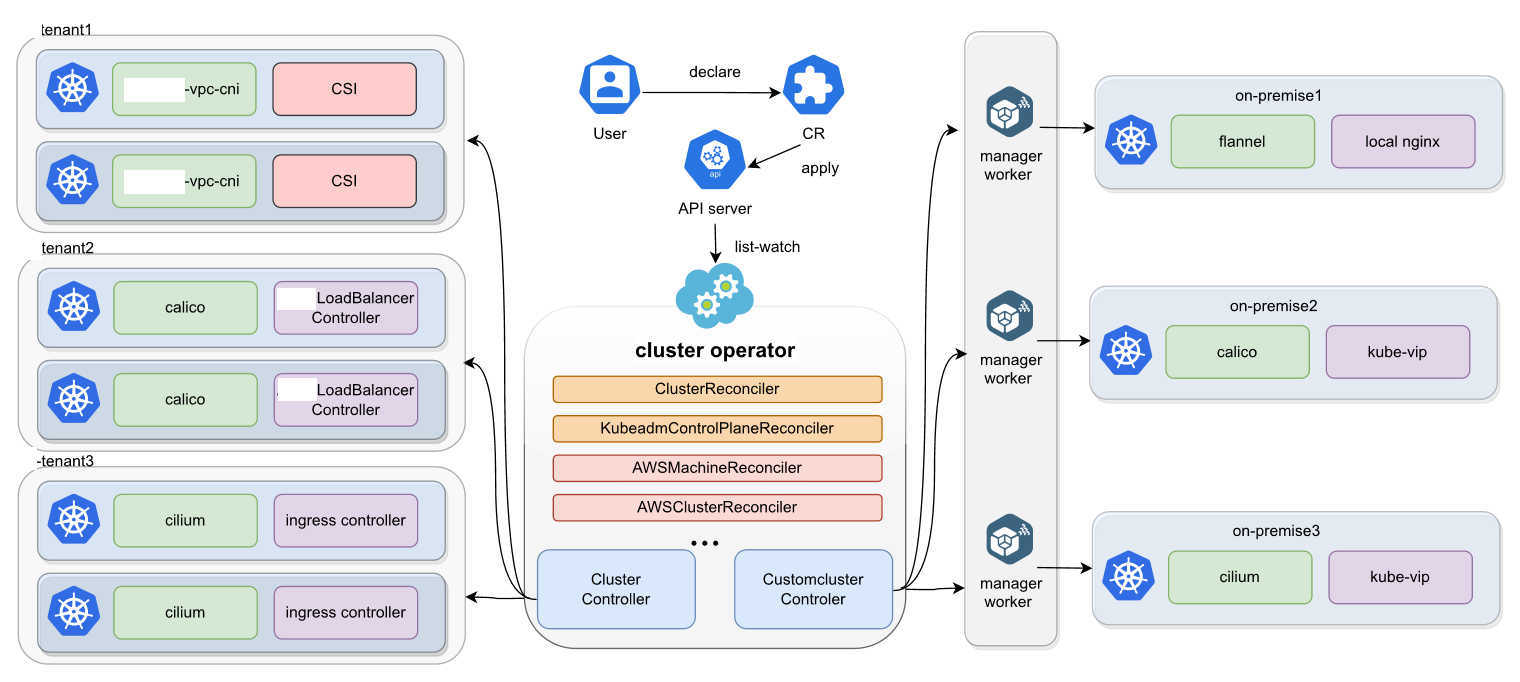
3.1 为什么我认为生命周期治理是分布式云原生的地基
分布式云原生最容易出现的失控点是:
- 集群越多,版本矩阵越复杂(K8s 版本、CNI、CSI、容器运行时、OS/Kernel…);
- 治理动作越频繁,人为操作误差越大;
- 宕机与事故不可避免,你需要的是可重复的恢复路径而不是“靠资深同学救火”。
所以“集群生命周期治理”要解决的不是“能不能装”,而是:能不能把集群当成可控资产。
3.2 On-Prem 场景:基于 Cluster API + KubeSpray 的声明式管理
Kurator 文档给出了 On-Prem 的生命周期管理路径:依托 Cluster API 与 KubeSpray,实现安装、删除、升级、扩缩容等能力。
下面给一个“最小可读”的资源结构示意(真实落地请以 examples 为准):
# 1) 先把 SSH 私钥做成 secret(文档示例)
# kubectl create secret generic cluster-secret --from-file=ssh-privatekey=/root/.ssh/id_rsa
# 2) CustomMachine:描述主机清单(master / node)与 SSH 访问方式
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha1
kind: CustomMachine
metadata:
name: demo-custommachine
namespace: default
spec:
master:
- hostName: master1
publicIP: 200.x.x.1
privateIP: 192.x.x.1
sshKey:
apiVersion: v1
kind: Secret
name: cluster-secret
node:
- hostName: node1
publicIP: 200.x.x.2
privateIP: 192.x.x.2
sshKey:
apiVersion: v1
kind: Secret
name: cluster-secret
专业思考:为什么这种方式更“平台化”
- 你把“机器清单、网络参数、K8s 版本、CNI 类型”等变成可审计资源;
- 升级/扩容不再靠“跑脚本”,而是靠控制器对期望态/实际态做收敛;
- 组织层面可以把权限做得更清楚:谁能改 CRD,谁就能变更集群。
3.3 升级与扩缩容:把高危动作拆成“可观察的工作流”
文档里强调升级依赖 kubeadm,建议避免跨 minor 跳跃升级,并给出了通过编辑 kcp(KubeadmControlPlane)声明目标版本来触发升级的方式。
工程化落地建议:
- 升级前置检查:etcd 空间、控制面 Pod 资源、API 延迟、关键 CRD 兼容性;
- 升级分批策略:先边缘/低优先级集群,再核心生产;
- 升级后验证清单:核心业务探针、CNI/CSI、HPA、PDB、Ingress/Gateway、监控告警链路。
四、多集群编排:用 Kurator 一键装 Karmada 并纳管成员集群
如果说上一节解决“集群怎么来的”,那么这一节解决“多个集群怎么一起被调度与编排”。
Karmada是一个有趣的东西,这个是karmada架构官方参考图,感兴趣的朋友们可以看看了解一下: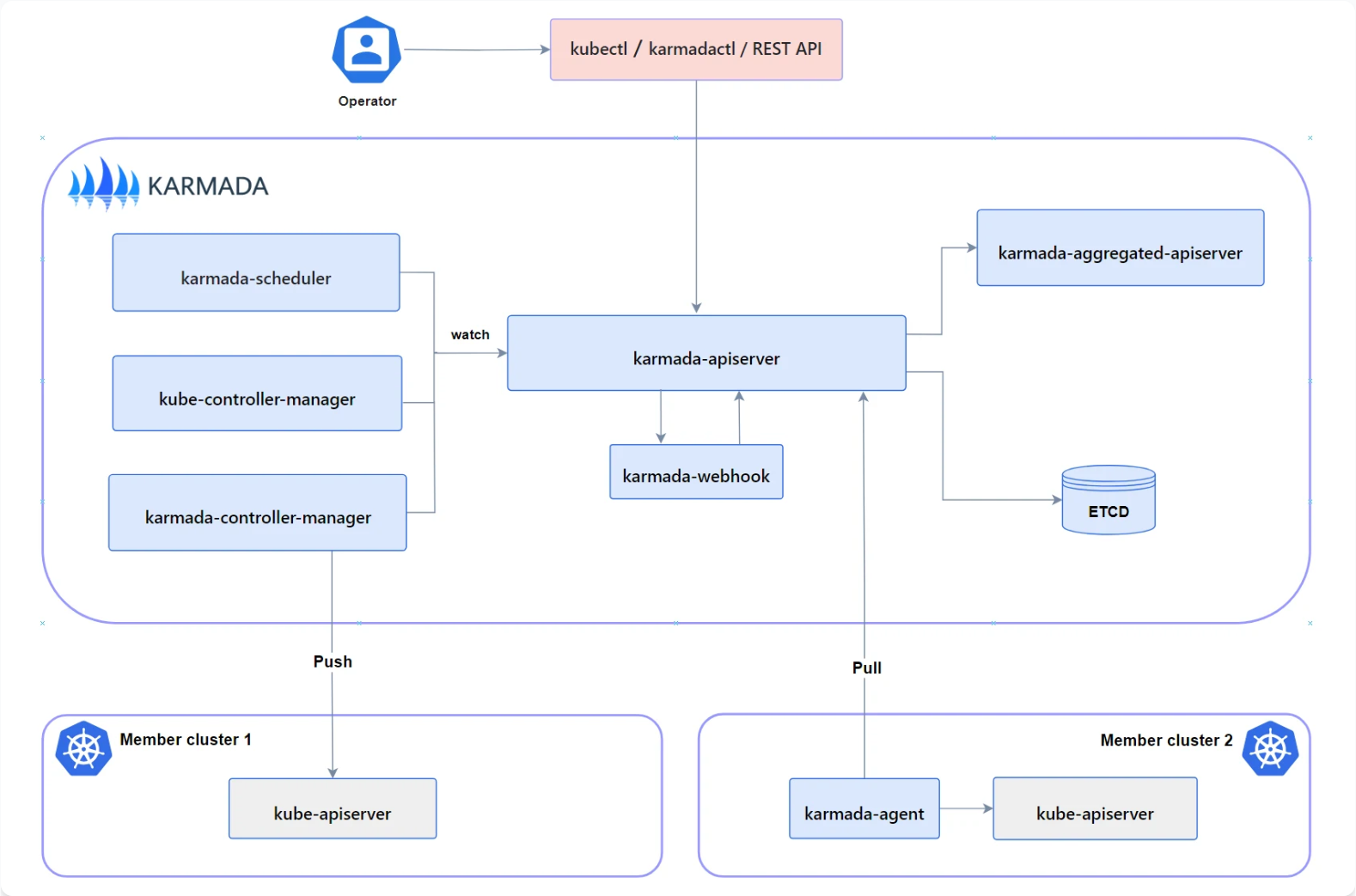
4.1 为什么是 Karmada:多集群编排需要一个“统一 API 入口”
Kurator 的 Karmada 集成路径非常直接:安装 Karmada 控制面,然后把 member 集群 join 进来。
这一步的关键意义是:后续你可以用一个控制面把策略/资源分发到多个成员集群(包括 Kurator 安装 Thanos 这类场景也会用到 Karmada 做编排)。
4.2 实操:安装 Karmada 控制面 + join 两个成员集群
按文档流程,先确保本地已经有 host + 两个 member 集群(上一节脚本),再编译 kurator 并安装 Karmada。
# 安装 karmada 控制面(示例)
kurator install karmada --kubeconfig=/root/.kube/config
# 将成员集群加入 karmada
kurator join karmada member1 \
--cluster-kubeconfig=/root/.kube/kurator-member1.config \
--cluster-context=kurator-member1
kurator join karmada member2 \
--cluster-kubeconfig=/root/.kube/kurator-member2.config \
--cluster-context=kurator-member2
# 查看已纳管集群
kubectl --kubeconfig /etc/karmada/karmada-apiserver.config get clusters
4.3 常见问题:K8s 版本兼容与“表面 join 成功但不可用”
文档明确提示:karmada v1.2.0 及以下不支持 Kubernetes v1.24.0 及以上加入控制面。
实战排查套路(我一般按这个顺序):
- 先查版本矩阵:Karmada 版本 vs member K8s 版本;
- 查网络连通:member 到控制面、控制面到 member;
- 查证书/凭据:kubeconfig 的证书是否过期、server 地址是否可达;
- 查控制器日志:比起盯着 “Pending/Unknown”,日志更快指向根因。
五、Fleet Manager 统一管理:把多个集群变成一个“舰队”

Karmada 更偏“多集群编排与调度入口”,而 Kurator 的 Fleet Manager 更偏“把多个集群当成一个运营单元去治理”:统一命名空间/账号、统一应用分发、统一策略、统一监控、统一网络、统一备份等。
5.1 Fleet 是什么:把“集群列表”升级成“可治理对象”
Kurator 文档对 Fleet Manager 的能力列表写得很具体:Fleet 作为逻辑单元、Fleet 控制面生命周期管理、集群注册/注销、跨 fleet 的应用编排、Service sameness、跨集群服务发现与通信、聚合多集群指标等。
我的实战理解:Fleet = 你的“标准化交付与治理边界”。
- 想把某批集群定义成同一条流水线、同一套基线、安全策略、监控插件?用 fleet。
- 想把 dev/test/prod 分离?fleet 天然适配组织结构。
这是Fleet架构官方参考图,想更多了解的朋友可以看看: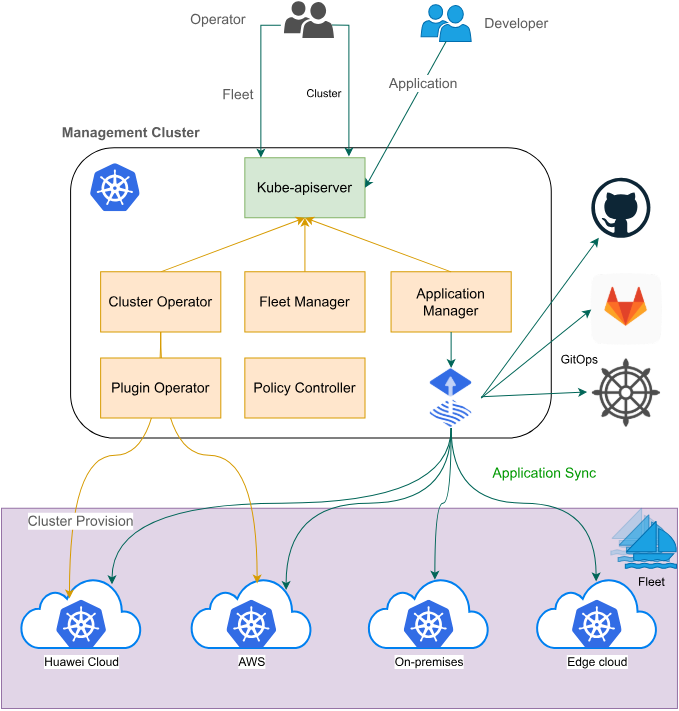
5.2 安装 Fleet Manager:FluxCD 是关键依赖(别跳过)
Fleet Manager 依赖 Cluster Operator,且依赖 FluxCD(Kurator 文档给了通过 Helm 安装 flux2 的命令,并明确了使用 fluxcd-community chart、指定版本等)。
helm repo add fluxcd-community https://fluxcd-community.github.io/helm-charts
cat <<EOF | helm install fluxcd fluxcd-community/flux2 --version 2.7.0 -n fluxcd-system --create-namespace -f -
imageAutomationController:
create: false
imageReflectionController:
create: false
notificationController:
create: false
EOF
kubectl get po -n fluxcd-system
然后再安装 fleet manager(可以走 helm repo、release 包或源码构建)。
这是FluxCD Helm 应用的示意图,我们通过这个可以看到具体工作流程: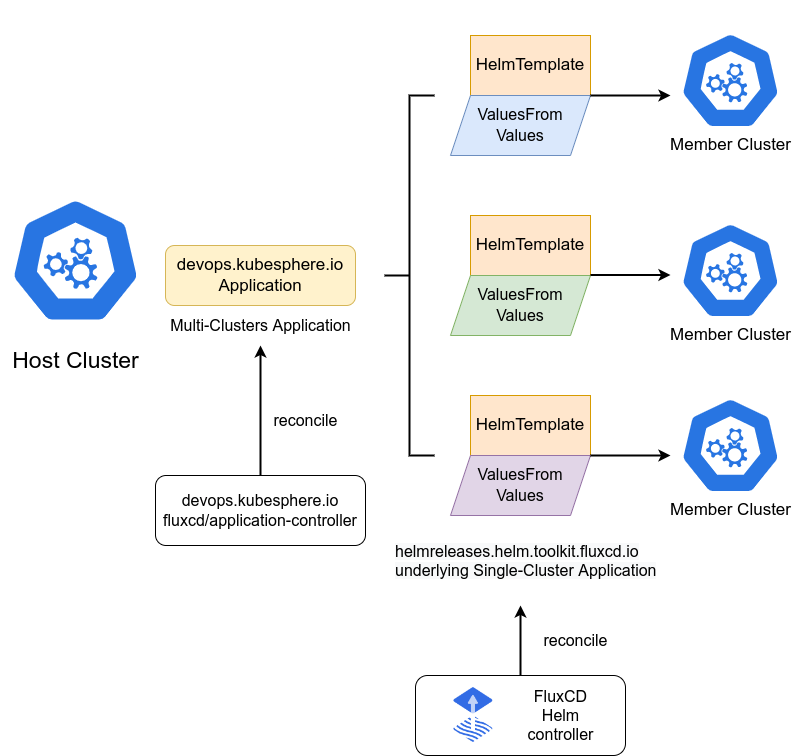
5.3 AttachedCluster:注册不是“加个 kubeconfig”这么简单
Kurator 的 policy 与 application 分发示例都强调:需要把成员集群 kubeconfig 做成 secret,然后用 AttachedCluster 资源把它们纳入管理。
kubectl create secret generic kurator-member1 \
--from-file=kurator-member1.config=/root/.kube/kurator-member1.config
kubectl create secret generic kurator-member2 \
--from-file=kurator-member2.config=/root/.kube/kurator-member2.config
实战注意点(很关键):
- secret 的 key 名与 AttachedCluster 引用方式要一致;
- kubeconfig 内的 server 地址必须对 fleet manager 所在集群可达;
- 给 AttachedCluster 打标签(env=dev/test/prod)会极大提升后续“按集群选择策略”的可控性(Kurator application 文档也专门讲了 selector)。
六、统一交付与流量治理:Application + Istio + 监控/策略组合拳
这一节我用“一个 fleet、两套 member 集群”的实验场,串起四件事:
1)统一应用分发(GitOps);2)统一流量治理(Service Mesh);3)统一监控(Thanos/Prometheus 思路);4)统一策略(Kyverno)。
6.1 统一应用分发:Application CRD 把 GitOps 交付变成跨集群标准动作
Kurator 的统一应用分发是“Fleet + FluxCD + GitOps”的组合:通过 Application CRD 定义源码与同步策略,把应用一致性分发到多个集群。
下面是一份“精简版”的 Application(结构与官方示例一致,便于理解):
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: gitrepo-kustomization-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: master
timeout: 1m0s
url: https://github.com/stefanprodan/podinfo
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./deploy/webapp
prune: true
timeout: 2m0s
为什么它对运维很“值钱”(实战视角):
- 一致性:同一份声明在多个集群落地,减少“人为漂移”;
- 可审计:Git commit + 控制器调谐日志,比口头/截图可追溯;
- 可回滚:回滚本质是回滚 Git 版本与同步策略,而不是“去每个集群手动改”。
进阶玩法:给 AttachedCluster 打标签,然后在 policy/应用策略里用 selector 做“同源不同发布节奏”(比如 test 快、prod 慢),Kurator 文档也明确支持这种按标签选择。
6.2 统一流量治理:用 Kurator 安装 Istio 多集群(Primary-Remote)
Kurator 提供了非常直接的 Istio 安装命令:指定 primary 集群与 remote 集群,按 Primary-Remote 模型部署,并将 Karmada API Server 作为 Istio 配置下发目标。
# 示例:member1 为 primary,member2 为 remote
kurator install istio --primary member1 --remote member2
专业思考:为什么要把流量治理纳入“平台交付链路”
- 当你有多个集群(甚至边缘)时,流量治理不是“装一个网格”就结束,而是:
- 服务发现、跨集群通信、东西向流量策略要统一;
- 灰度/熔断/限流/可观测要与发布系统联动。
- Kurator 的价值在于:把 Istio 这种复杂系统的安装与多集群拓扑配置,压缩成可重复动作。
6.3 统一监控与统一策略:Thanos(聚合视图)+ Kyverno(基线治理)
监控(Thanos)
Kurator 提供了安装 Thanos 的命令,并强调需要 object store 配置;同时也给了 port-forward 验证 query 的方式。
kurator install thanos \
--host-kubeconfig /root/.kube/kurator-host.config \
--host-context kurator-host \
--object-store-config /root/thanos/thanos-config.yaml
kubectl port-forward --address 0.0.0.0 svc/thanos-query -n thanos 9090:9090 \
--kubeconfig /root/.kube/kurator-host.config --context kurator-host
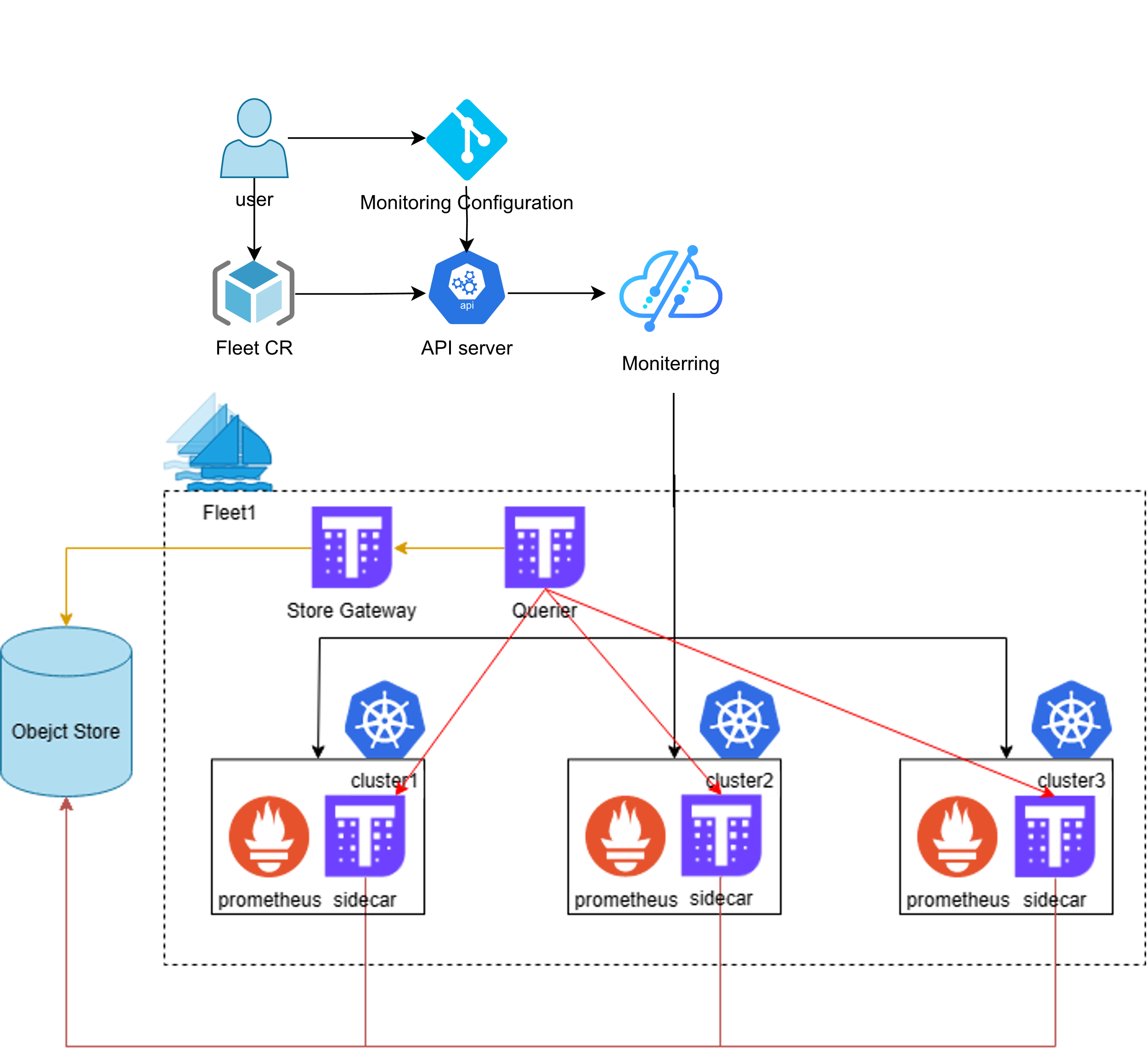
这是Kurator 统一监控参考图:
我在企业落地时会把“统一监控”拆成三层设计:
- 采集层:每个集群本地采集(Prometheus/Agent/OTel);
- 汇聚层:Thanos 这种全局查询视图 + 长期存储(对象存储);
- 消费层:统一仪表盘、统一告警路由、统一 SLO(Grafana/Alertmanager/Oncall)。
策略(Kyverno)
Kurator 的 fleet 策略管理是基于 Kyverno 的,并提供了启用 pod security baseline 检查、查看 policy report 的示例。
# 文档示例:创建启用 baseline pod security 的 fleet
kubectl apply -f examples/fleet/policy/kyverno.yaml
# 验证:在成员集群查看 policyreport
kubectl get policyreport --kubeconfig=/root/.kube/kurator-member1.config
实战方法论:监控回答“发生了什么”,策略回答“什么不该发生”
很多平台只做到了“看见问题”(监控),但没有把“预防问题”(策略)做成体系。Kurator 把两者都纳入 fleet 的一致性治理对象:
- 监控解决可观测统一;
- Kyverno 解决安全基线统一;
- 再配合应用分发与流量治理,你才能把“分布式云原生”真正运营起来。
七、落地复盘:用 Kurator 搭企业级分布式云原生平台的路线图
这一节给一个“可复用的落地模板”(偏方法论 + 工程化清单)。我不会虚构“某某公司真实收益数据”,但会把真实项目里常见的选型、攻坚点与价值链路讲清楚。
7.1 技术选型建议:先定“治理边界”,再选“组件菜单”
我建议把落地拆成三条线并行推进:
- 底座线(集群生命周期):用 Cluster Operator 把集群创建、升级、扩缩容收敛成声明式,先把“集群资产可控”建立起来。
- 运营线(Fleet 化管理):按组织/环境拆 fleet(例如 dev-fleet、prod-fleet、edge-fleet),把标准化能力(策略、监控、备份、网络)做成 fleet 的可组合插件。
- 交付线(GitOps + 流量治理):用 Application 统一分发,再用 Istio/渐进式发布把“上线风险”工程化消解。
一句话:Kurator 帮你把“组件选型”变成“能力装配”,把“能力装配”变成“可复制的标准单元”。
7.2 三个最容易卡住的攻坚点(提前准备就能省很多命)
攻坚点 A:网络互通与控制面可达性
- 多集群最大的问题往往不是 CRD 不会写,而是 kubeconfig 里 server 不可达、跨网段互通不可控。
- 建议在试点期就确定:跨集群通信(是否需要 Submariner 等)、控制面与成员集群的网络连通模型、DNS 策略。
攻坚点 B:版本矩阵与升级节奏
- Karmada 与 member K8s 版本兼容要先跑通(文档对 v1.2.0 与 k8s 版本有提醒)。
- Istio 多集群对网络拓扑/证书也敏感,建议把“升级窗口、回滚策略、兼容矩阵”写进平台 SRE 运行手册,而不是靠经验传承。
攻坚点 C:权限与责任边界(这是平台成败关键)
你需要提前定义:
- 谁能创建/修改 Fleet?
- 谁能注册 AttachedCluster?
- 谁能提交 Application?
- 谁能修改策略(Kyverno)与流量规则(Istio)?
这不是“流程问题”,而是“平台产品化”的根本:边界清晰,平台才可规模化推广。
7.3 生态协同与价值链路:把“技术收益”翻译成“业务收益”
Kurator 的生态价值,我通常会用四个关键词对齐业务侧:
- 上线效率:Application + GitOps 把多集群上线从“多次执行”变成“一次声明”。
- 稳定性:流量治理与渐进式发布降低变更风险(尤其在多集群、跨地域的发布场景)。
- 合规与安全:Kyverno 把基线策略变成平台能力,靠 policy report 输出治理结果。
- 可观测与复盘:Thanos 这类全局视图帮助你跨集群定位问题、做容量规划与趋势分析。
最终你会发现:Kurator 的“集成”不是目的,目的是把分布式场景里最难标准化的部分(生命周期、交付、治理、观测)变成平台可复用能力。
Kurator分布式云原生开源社区地址:https://gitcode.com/kurator-dev
Kurator分布式云原生项目部署指南:https://kurator.dev/docs/setup/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)