Embedding 模型选错了,RAG 再怎么调也白费
RAG 系统调了半个月,检索准确率一直上不去。换了分块策略、调了相似度阈值、加了 Rerank,还是差口气。
最后发现问题出在最底层:Embedding 模型选错了,对中文支持不好,把"辞职"和"离职"编码成距离很远的两个向量。
Embedding 模型是 RAG 的地基,地基不稳,上面建再高也会歪。这篇讲怎么选、怎么评估。
一、Embedding 模型在 RAG 里干什么
RAG 的检索链路:
用户提问 → Embedding 模型 → 查询向量文档库 → Embedding 模型 → 文档向量 ↓ 向量相似度计算 ↓ 召回最相关文档
Embedding 模型决定了"语义距离"的计算方式。如果模型认为"退款"和"退货"很相似(应该),但又认为"年假"和"带薪假期"差距很大(不应该),检索结果就会出问题。
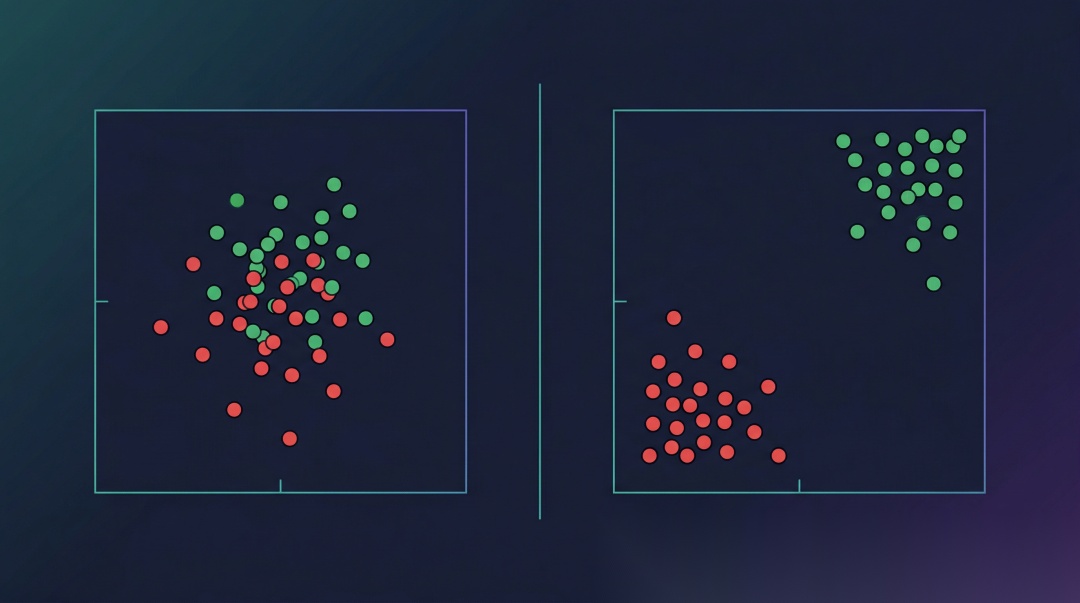
二、主流 Embedding 模型对比
import osimport numpy as npfrom openai import OpenAI# 这里用 OpenAI API 演示,你也可以换成 DeepSeek/智谱等兼容接口client = OpenAI( api_key=os.getenv("OPENAI_API_KEY") # 或 DEEPSEEK_API_KEY + base_url)
当前主流选项(价格以官方最新为准):
| 模型 | 提供方 | 维度 | 中文支持 | 适合场景 |
|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536(支持截断) | 可用,建议实测 | 通用场景、成本敏感 |
| text-embedding-3-large | OpenAI | 3072(支持截断) | 可作为候选 | 高精度需求 |
| BAAI/bge-m3 | BAAI | 1024 | 很强 | 中文/多语言 RAG |
| BAAI/bge-large-zh | BAAI | 1024 | 很强 | 纯中文场景 |
| Qwen 系列 embedding | 阿里 | 1536 | 很强 | 中文商业场景 |
| voyage-3 / voyage-3-lite | Voyage AI | 1024 | 较好 | 英文高精度、长文本 |
说明:OpenAI 的
text-embedding-3-*系列采用 Matryoshka 训练,支持通过dimensions参数灵活截断维度(如截到 512),精度损失小于传统 PCA 降维。
中文 RAG 场景里,bge-m3、Qwen embedding 往往值得优先纳入候选;如果你已经在用 OpenAI 栈,text-embedding-3-large 也不该跳过实测。
价格和模型能力会变化,正式选型前请以官方最新文档和你自己的评测结果为准。
三、自己评估:五分钟测出好坏
不要相信别人的 benchmark,在你自己的数据上测:
def cosine_similarity(vec1: list[float], vec2: list[float]) -> float: """计算余弦相似度""" a = np.array(vec1) b = np.array(vec2) return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))def get_embedding_openai(text: str, model: str = "text-embedding-3-small") -> list[float]: """调用 OpenAI Embedding API""" response = client.embeddings.create(model=model, input=text) return response.data[0].embeddingdef evaluate_embedding_quality(get_embedding_func, test_cases: list[dict]) -> dict: """ 评估 Embedding 质量 test_cases 格式:[{ "query": "用户查询", "positive": "应该匹配的文档", # 相似度应该高 "negative": "不该匹配的文档", # 相似度应该低 }] 返回:平均正例相似度、负例相似度、区分度 """ pos_scores = [] neg_scores = [] for case in test_cases: q_vec = get_embedding_func(case["query"]) p_vec = get_embedding_func(case["positive"]) n_vec = get_embedding_func(case["negative"]) pos_sim = cosine_similarity(q_vec, p_vec) neg_sim = cosine_similarity(q_vec, n_vec) pos_scores.append(pos_sim) neg_scores.append(neg_sim) avg_pos = np.mean(pos_scores) avg_neg = np.mean(neg_scores) discrimination = avg_pos - avg_neg # 区分度:越大越好 return { "avg_positive_similarity": round(float(avg_pos), 4), "avg_negative_similarity": round(float(avg_neg), 4), "discrimination_score": round(float(discrimination), 4), "pass_rate": sum(1 for p, n in zip(pos_scores, neg_scores) if p > n) / len(pos_scores) }# 构造中文测试集(针对你自己的业务场景,建议写 10 个以上)chinese_test_cases = [ { "query": "怎么申请年假", "positive": "带薪年假申请流程:工作满一年可享有5天年假,需提前在OA系统提交申请", "negative": "公司班车路线:每天早8点从地铁站出发,晚6点返回" }, { "query": "辞职流程", "positive": "员工离职手续:提前30个工作日提交书面申请,经HR审核后办理工作交接", "negative": "入职培训安排:新员工需参加3天的公司文化培训" }, { "query": "产品有质量问题怎么退款", "positive": "退款政策:商品存在质量问题可在30天内申请全额退款,无需承担运费", "negative": "物流跟踪:订单发货后可在APP查看实时物流信息" }, # ... 根据你的业务场景补充更多测试用例]print("=== OpenAI text-embedding-3-small 评估 ===")result_openai = evaluate_embedding_quality( lambda text: get_embedding_openai(text, "text-embedding-3-small"), chinese_test_cases)print(f"正例平均相似度:{result_openai['avg_positive_similarity']}")print(f"负例平均相似度:{result_openai['avg_negative_similarity']}")print(f"区分度得分:{result_openai['discrimination_score']}")print(f"正确区分率:{result_openai['pass_rate']:.0%}")
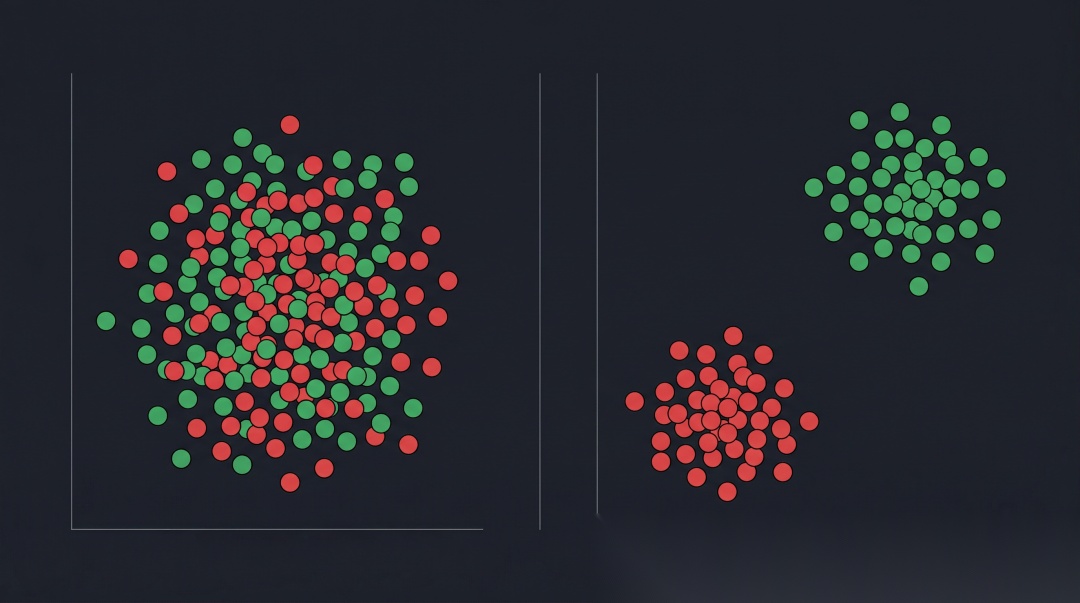
四、本地部署开源模型(bge-m3)
不想调 API 付费,或者数据不能出内网,用开源模型本地部署。
注意:本节代码依赖第三节定义的
cosine_similarity和evaluate_embedding_quality函数,请确保先执行。
# pip install sentence-transformers# 首次运行会自动下载模型(约 2GB)from sentence_transformers import SentenceTransformerimport numpy as np# 加载 bge-m3(常见的中文/多语言候选)bge_model = SentenceTransformer("BAAI/bge-m3")def get_embedding_bge(text: str) -> list[float]: """本地 bge-m3 Embedding""" # bge 模型推荐在查询前加 "Represent this sentence: " 前缀(英文任务) # 中文任务不需要 embedding = bge_model.encode(text, normalize_embeddings=True) return embedding.tolist()# 批量 Embedding(效率更高)def get_embeddings_batch(texts: list[str], batch_size: int = 32) -> list[list[float]]: """批量获取 Embedding,比逐条调用快很多""" embeddings = bge_model.encode( texts, batch_size=batch_size, normalize_embeddings=True, show_progress_bar=len(texts) > 100 ) return embeddings.tolist()# 对比 bge-m3 在中文测试集上的表现print("\n=== BAAI/bge-m3 评估 ===")result_bge = evaluate_embedding_quality(get_embedding_bge, chinese_test_cases)print(f"正例平均相似度:{result_bge['avg_positive_similarity']}")print(f"负例平均相似度:{result_bge['avg_negative_similarity']}")print(f"区分度得分:{result_bge['discrimination_score']}")print(f"正确区分率:{result_bge['pass_rate']:.0%}")# 很多中文业务测试里,bge-m3 的区分度会高于 text-embedding-3-small,但请以你自己的数据为准
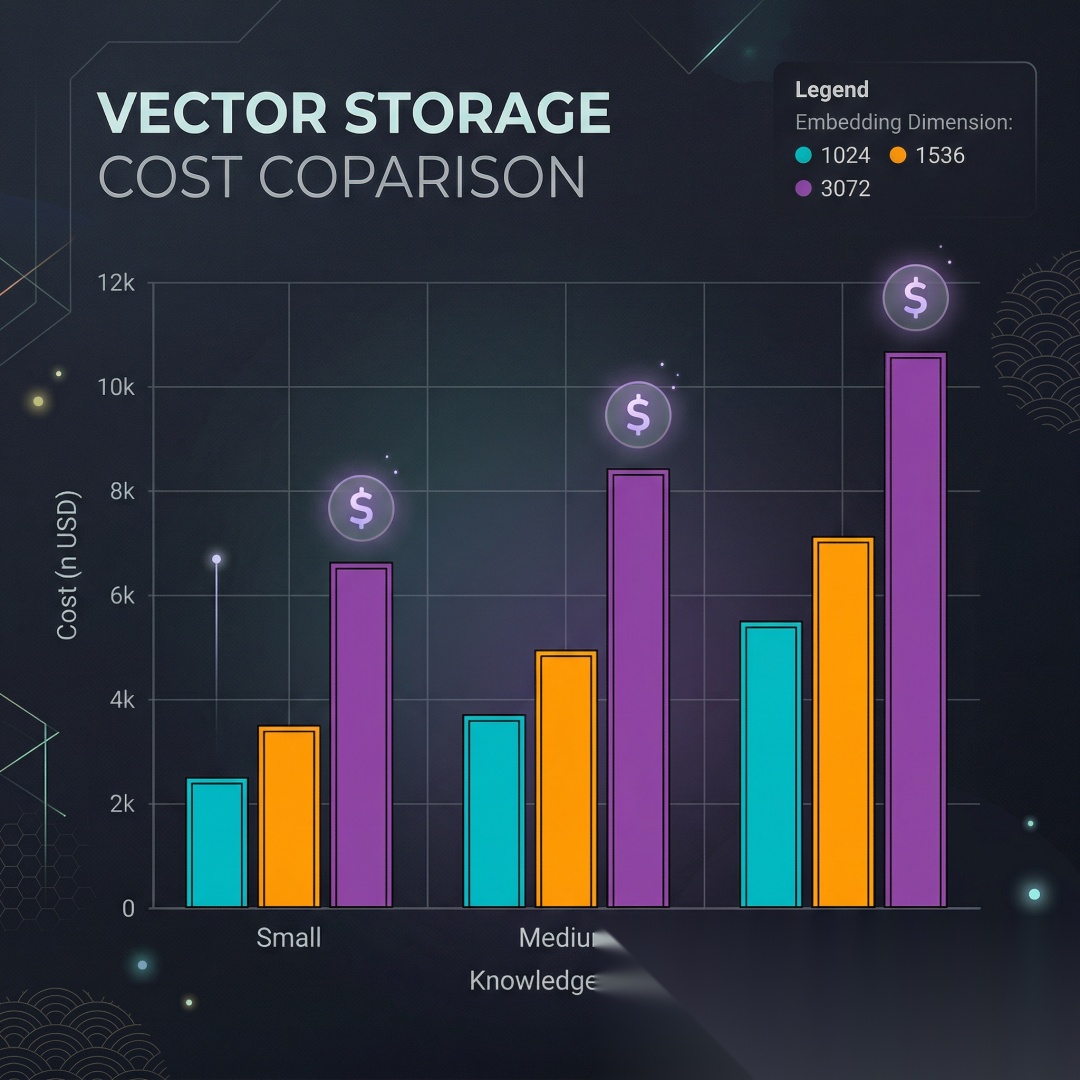
五、向量维度与存储成本
Embedding 维度越高,表达能力越强,但存储和检索成本也越高:
def estimate_vector_storage( num_documents: int, avg_chunks_per_doc: int, embedding_dim: int, bytes_per_float: int = 4 # float32) -> dict: """估算向量存储成本""" total_vectors = num_documents * avg_chunks_per_doc storage_bytes = total_vectors * embedding_dim * bytes_per_float storage_gb = storage_bytes / (1024 ** 3) return { "total_vectors": total_vectors, "storage_gb": round(storage_gb, 3), "storage_mb": round(storage_gb * 1024, 1) }# 对比不同模型的存储需求scenarios = [ ("小型知识库", 1000, 5), ("中型知识库", 10000, 8), ("大型知识库", 100000, 10),]models = [ ("bge-m3 (1024维)", 1024), ("text-embedding-3-small (1536维)", 1536), ("text-embedding-3-large (3072维)", 3072),]print("\n=== 存储成本对比 ===")for scenario_name, num_docs, chunks in scenarios: print(f"\n{scenario_name}({num_docs} 篇文档,每篇 {chunks} 个 chunk):") for model_name, dim in models: cost = estimate_vector_storage(num_docs, chunks, dim) print(f" {model_name}: {cost['storage_mb']} MB")
六、维度压缩:省空间会不会丢精度
OpenAI 的 text-embedding-3-* 系列支持 dimensions 参数,直接在 API 层面截断维度。听起来很诱人——维度砍半,存储省一半。但精度呢?
def compare_dimensions(test_cases: list[dict], full_dim: int = 1536, reduced_dim: int = 512): """对比不同维度下的区分度变化""" def get_emb(text, dim): resp = client.embeddings.create( model="text-embedding-3-small", input=text, dimensions=dim ) return resp.data[0].embedding results = {} for dim in [full_dim, reduced_dim]: scores = [] for case in test_cases: q = get_emb(case["query"], dim) p = get_emb(case["positive"], dim) n = get_emb(case["negative"], dim) scores.append(cosine_similarity(q, p) - cosine_similarity(q, n)) results[dim] = round(float(np.mean(scores)), 4) print(f" {full_dim} 维区分度:{results[full_dim]}") print(f" {reduced_dim} 维区分度:{results[reduced_dim]}") print(f" 精度损失:{round((1 - results[reduced_dim] / results[full_dim]) * 100, 1)}%") return resultsprint("\n=== 维度压缩 vs 精度 ===")compare_dimensions(chinese_test_cases, 1536, 512)
结论因数据而异,但常见规律是:从 1536 压到 768,精度损失通常在 2%-5%,可以接受;压到 256 以下,区分度会明显下降。 别凭直觉拍,跑一遍你自己的测试用例再决定。
七、换模型的代价:算清楚再动手
很多人选型时想着"先用着,不行再换"。但换 Embedding 模型的真实代价比你以为的大:
换模型 = 全量文档重新向量化 + 向量库全量写入 + 索引重建 + 回归测试
算一笔账:10 万篇文档,每篇切 8 个 chunk,共 80 万条向量。如果用 API 重新编码,按 text-embedding-3-small 的价格,光 API 调用费大约 $2-5(便宜),但实际瓶颈在时间——跑完全量可能要几个小时,期间要么停服,要么新旧索引并行(复杂度又上来了)。
所以选型时多花一天做评估,比上线后换模型折腾一周划算得多。
八、选型决策建议
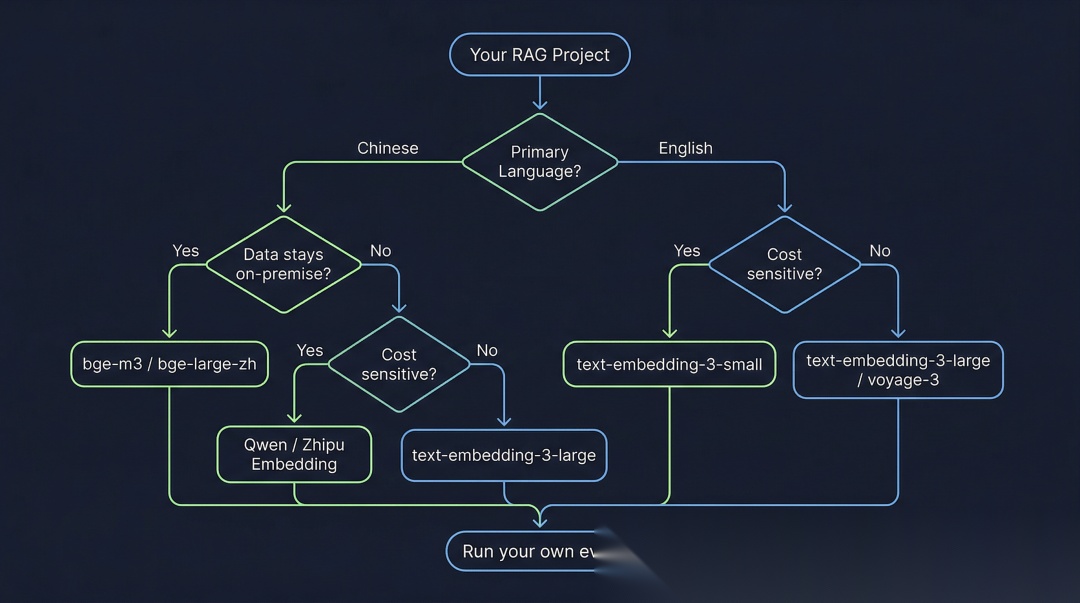
按语言选:
- 以中文为主
- 数据不能上云 → bge-m3 / bge-large-zh(先测效果,再看部署成本)
- 可以调 API,成本敏感 → 智谱 / Qwen Embedding
- 已有 OpenAI 账号 → 把 text-embedding-3-large 纳入候选并做实测
- 以英文为主
- 成本优先 → text-embedding-3-small
- 精度优先 → text-embedding-3-large / voyage-3
实践建议:
- 先在业务数据上测:用
evaluate_embedding_quality写 10 个测试用例跑一遍,5 分钟的评估能省几个月的迷惑。 - 不要轻易换模型:换了之后所有文档都要重新向量化,选型时多花时间,上了生产就稳住。
- 维度可以压缩:
text-embedding-3-*支持dimensions参数截断,但要在业务数据上验证精度损失。 - 查询和文档必须用同一个模型:不同模型的向量空间不兼容,混用必出问题。
Embedding 模型是 RAG 的地基。选对了,分块策略、检索算法、Rerank 都能发挥作用;选错了,上层再怎么优化也事倍功半。别在上层花一个月调参,先花五分钟跑一下评估脚本。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)