【探索实战】用 Kurator 把多云多集群与边缘统一管起来:从搭建到分发、策略、发布治理实战
【探索实战】用 Kurator 把多云多集群与边缘统一管起来:从搭建到分发、策略、发布治理实战
- 【探索实战】用 Kurator 把多云多集群与边缘统一管起来:从搭建到分发、策略、发布治理实战
【探索实战】用 Kurator 把多云多集群与边缘统一管起来:从搭建到分发、策略、发布治理实战

这篇文章以「Kurator·云原生实战派」为主线:先把 Kurator 的“它到底解决什么问题、边界在哪里”讲清楚,再用一个可复现的本地多集群实验室环境,把集群生命周期、统一应用分发、统一策略管理、统一发布(灰度/金丝雀)串成一条“能落地的链路”。文中包含关键 YAML/命令,以及一段用 Go 调用 Kurator API 的小代码,帮助你把 Kurator 真正接进现有平台/流水线。
一、先把 Kurator 讲明白:它到底在“统一”什么
1.1 分布式云原生最常见的三类“割裂”
很多团队一开始做多集群/多云,会很自然地走向“组件拼装式”架构:
- 集群层割裂:每个云/每个地域一套 Kubernetes,安装方式、版本节奏、CNI/CSI 选型不同,升级靠脚本与经验。
- 应用层割裂:同一个应用在 A 集群用 Helm,在 B 集群用 Kustomize;参数靠人工维护多份 values;上线/回滚节奏不一致。
- 治理层割裂:监控、策略(准入/基线)、流量灰度各自一套控制面;运维遇到问题时,排障链路跨系统跳转,MTTR 拉长。
Kurator 的价值,不是“再造一个 Kubernetes”,而是把这些割裂用声明式 API + 统一控制面收敛成一套可持续演进的“分布式云原生底座”。
1.2 Kurator 的能力边界:四个统一 + 协同
从官方定位看,Kurator 聚焦在分布式场景下的四类能力:统一资源编排(Orchestration)、统一调度(Scheduling)、统一流量治理(Traffic)、统一可观测(Telemetry),并强调多云、云边、边边协同。
这里的关键点是:Kurator 并不“重复发明轮子”,而是站在 Kubernetes、Istio、Prometheus、FluxCD、Karmada、KubeEdge、Volcano、Kyverno 等开源能力之上做工程化整合与统一体验。
这是Kurator的核心价值参考图,可以看到Kurator的能力边界: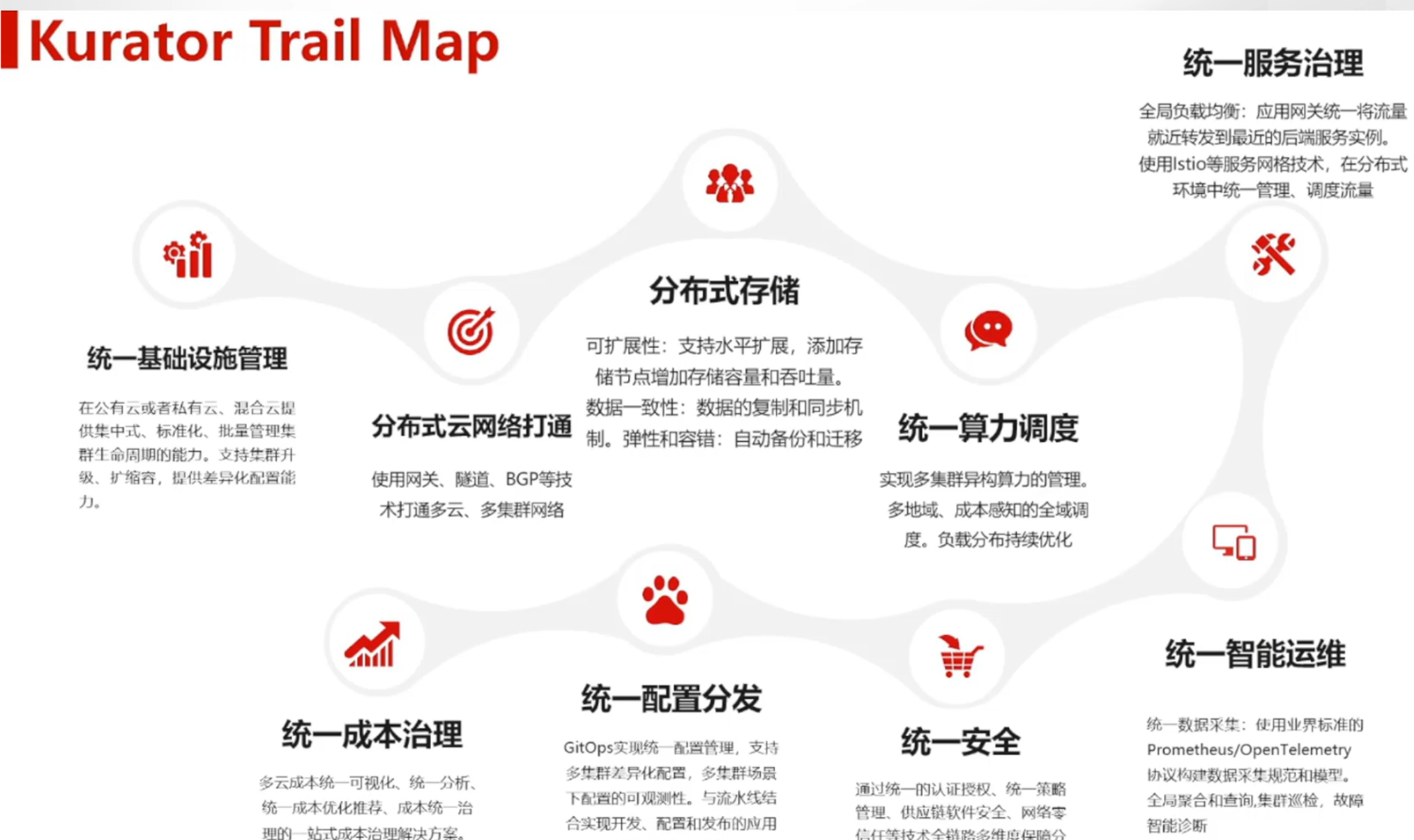
1.3 两大核心:Cluster Operator 管集群,Fleet Manager 管一组集群
如果把 Kurator 想象成“分布式云原生操作系统”,那它最关键的两个“进程”是:
- Kurator Cluster Operator:把“创建/升级/回收集群”这件事云原生化。它基于 Cluster API 与 KubeSpray(并能管理 CNI/CSI/Ingress 插件),让集群生命周期从脚本转成声明式对象。
- Kurator Fleet Manager:把多个物理集群抽象成逻辑单元
Fleet,并负责 fleet 控制面的生命周期、集群注册/注销、跨 fleet 的应用编排、服务一致性、跨集群服务发现通信、指标聚合、策略一致性等。
接下来我们用一个“本地三集群实验室”,把这两块真正跑起来。
二、搭一个可复现实验室:三套 Kind 集群模拟“管理面 + 两个成员集群”
2.1 拉源码
下面两种方式任选其一(我通常用 git clone,方便切分支、看 examples):
# 方式 A:wget 下载源码 zip(按题目要求)
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# 方式 B:git clone(按题目要求)
git clone https://github.com/kurator-dev/kurator.git
cd kurator
Kurator 官方安装 Cluster Operator 的第一步同样是从源码进入目录。
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
2.2 一键起本地多集群:hack/local-dev-setup.sh 的价值与常见坑
Kurator 提供了本地脚本 hack/local-dev-setup.sh 来拉起 Kind 集群:一个 kurator-host(管理集群)+ 多个 member 集群。
# 在 kurator 仓库根目录
hack/local-dev-setup.sh
# 脚本完成后会提示你切换 KUBECONFIG
export KUBECONFIG=/root/.kube/kurator-host.config
# 成员集群例如:
# export KUBECONFIG=/root/.kube/kurator-member1.config
我在入门体验里最常踩的两个坑:
-
坑 1:kubeconfig 里的 server 地址不可达
当你的集群不是脚本创建、或你在不同网络环境里使用 kubeconfig 时,可能需要把 kubeconfig 的server改成控制平面节点 IP,并把端口设为6443,否则 AttachedCluster 可能一直不 ready。这个注意事项在 AttachedCluster 管理指南里写得很明确。 -
坑 2:控制面依赖没装齐(尤其是证书组件)
Cluster Operator 依赖 cert-manager 的 CA injector,没装或没 ready 会导致 webhook/CRD 相关异常。官方安装步骤要求先装 cert-manager。
2.3 装“管集群”和“管一组集群”:Cluster Operator + Fleet Manager
(1)安装 cert-manager(Cluster Operator 前置)
helm repo add jetstack https://charts.jetstack.io
helm repo update
kubectl create namespace cert-manager
helm install -n cert-manager cert-manager jetstack/cert-manager \
--set crds.enabled=true --version v1.15.3
(2)安装 Kurator Cluster Operator(推荐走 helm repo)
helm repo add kurator https://kurator-dev.github.io/helm-charts
helm repo update
helm install --create-namespace kurator-cluster-operator kurator/cluster-operator \
--version=0.6.0 -n kurator-system
kubectl get pod -l app.kubernetes.io/name=kurator-cluster-operator -n kurator-system
(3)Fleet Manager 前置:安装 FluxCD(它用 GitOps 驱动分发)
Fleet Manager 依赖 FluxCD,官方示例使用 fluxcd-community/flux2 chart,并关闭 image 自动化与通知等部分 controller。
helm repo add fluxcd-community https://fluxcd-community.github.io/helm-charts
cat <<EOF | helm install fluxcd fluxcd-community/flux2 --version 2.7.0 \
-n fluxcd-system --create-namespace -f -
imageAutomationController:
create: false
imageReflectionController:
create: false
notificationController:
create: false
EOF
kubectl get po -n fluxcd-system
(4)安装 Fleet Manager(同样推荐 helm repo)
helm repo add kurator https://kurator-dev.github.io/helm-charts
helm repo update
helm install --create-namespace kurator-fleet-manager kurator/fleet-manager \
--version=0.6.0 -n kurator-system
kubectl get pod -l app.kubernetes.io/name=kurator-fleet-manager -n kurator-system
到这里,你已经具备了“能管理集群 + 能管理一组集群”的最小闭环。
三、集群生命周期治理:从“创建”到“升级/回收”都变成对象
详细可以见Kurator集群生命周期管理参考图,朋友们可以更清晰的了解: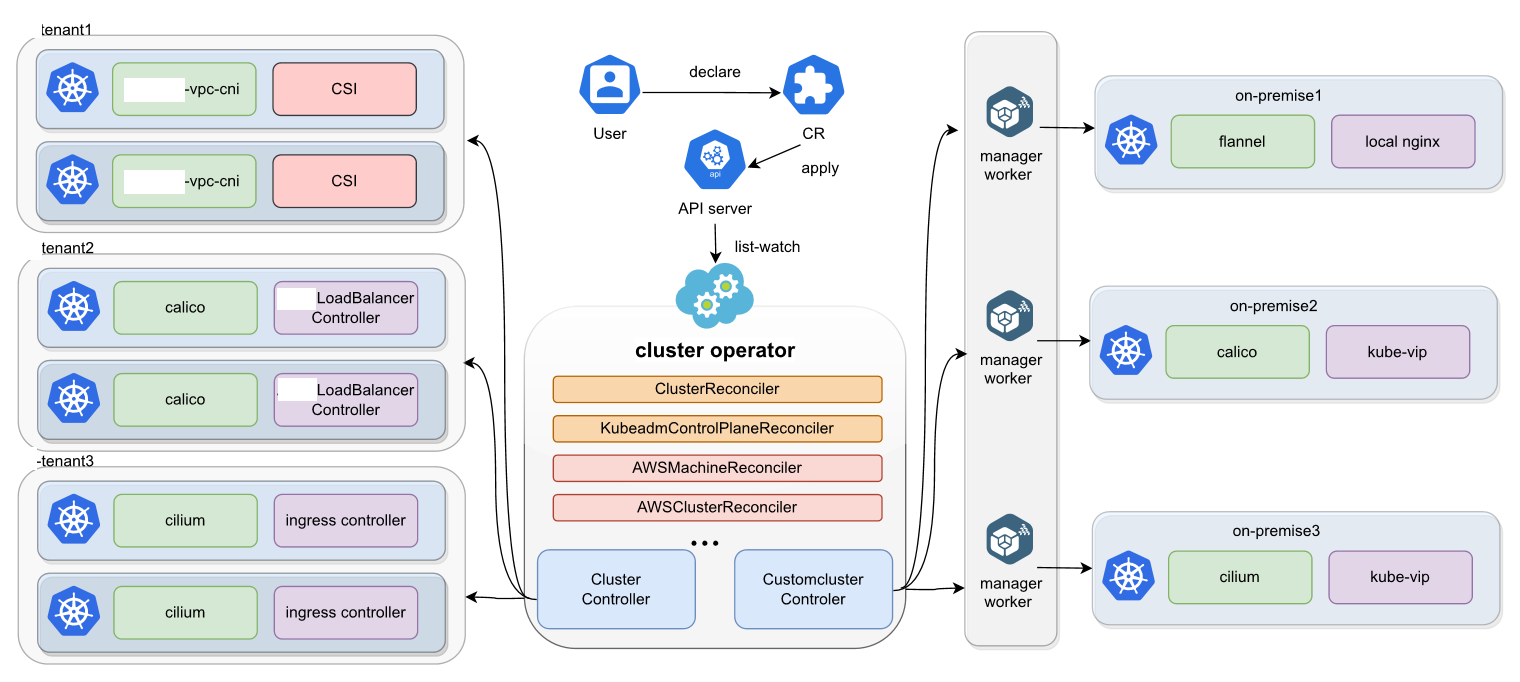
3.1 为什么说它更像“集群的 Operator”
Cluster Operator 的定位很直接:把集群当作一种可声明、可 reconcile 的资源来管理。它基于 Cluster API 与 KubeSpray,并能在集群 ready 后继续管理 CNI/CSI/Ingress 等插件。
这会带来两个工程收益:
- 可审计:集群配置是 CRD(或模板)而不是某个工程师电脑上的脚本。
- 可重复:环境一致性从“约定”变成“约束 + 自动校验”。
3.2 Quickstart:用 Kurator Cluster API 拉起一个 vanilla 集群
Kurator 文档给出了 quickstart:直接 apply 集群清单,然后 watch 集群状态,最后用 clusterctl 拉 kubeconfig。
kubectl apply -f examples/cluster/quickstart.yaml
kubectl get cluster -w
clusterctl get kubeconfig quickstart > /root/.kube/quickstart.kubeconfig
kubectl --kubeconfig=/root/.kube/quickstart.kubeconfig get nodes
专业建议:把 “cluster 对象 ready” 与 “插件 ready(CNI/CSI/Ingress)” 分开观测与告警。很多团队把集群 ready 当作一切结束,结果是应用上线时才发现缺了 CSI/Ingress,排障成本更高。
3.3 进阶实战:高可用控制面与升级策略(kube-vip + kubeadm)
在 on-prem 场景里,Kurator 提到:基于 KubeSpray 安装的集群在每个非 master 节点预装本地 nginx;如果想要更好的 HA,可以用 kube-vip 绑定 VIP 做控制面入口,并通过在 CRD 增加变量来启用。
此外,升级方面 Kurator 也强调其实现依赖 kubeadm,并建议不要跨小版本跳跃(例如 1.22->1.23 可以,但不建议一步到 1.24)。升级路径被固化为“改对象里的版本字段 -> 触发升级 worker”。
我的落地经验:
- 升级窗口要和业务发布窗口错开,且先做一组 canary 集群(比如 10% fleet)验证。
- 插件版本要与 Kubernetes 版本联动评估(CNI/CSI/Ingress),别只盯 apiserver。
四、统一应用分发:用 Fleet 把 GitOps “发射”到一组集群
Kurator 统一应用分发参考图大家可以看看,从user到集群的过程: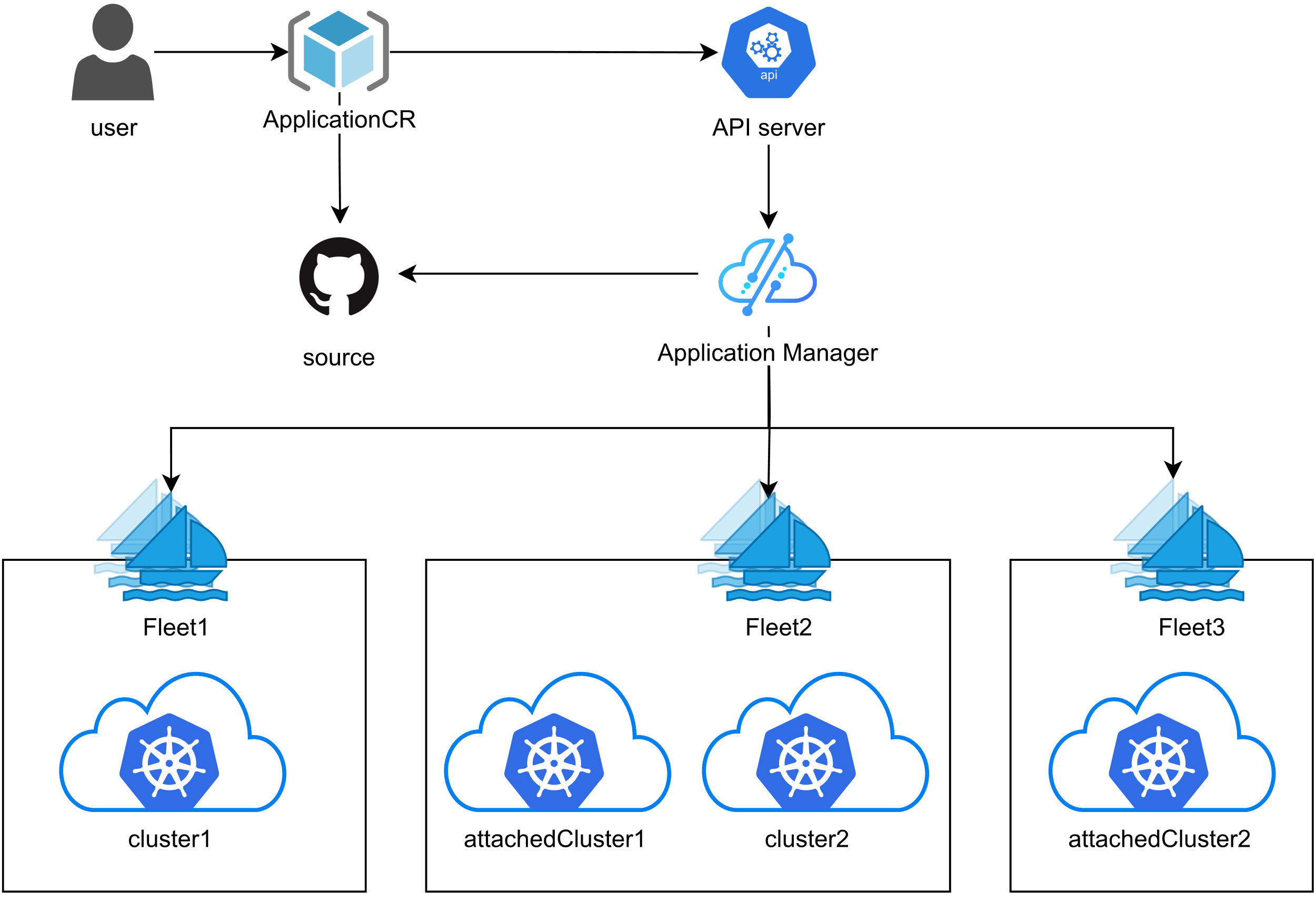
4.1 三个对象讲清楚:AttachedCluster、Fleet、Application
Kurator 对“外部集群”的称呼是 AttachedCluster:不是 Kurator 创建的集群,也可以通过加入 Fleet 纳管。
- AttachedCluster:描述“这个集群怎么连”(核心是 kubeconfig secret)
- Fleet:描述“一组集群”的逻辑单元(spec 里列出成员集群引用)
- Application:描述“我要把什么应用,以什么同步策略,分发到哪个 fleet/哪些集群”
这套对象模型的好处是:集群资产、集群编组、应用交付三者解耦。企业里你会频繁遇到“应用不变但集群组在变”“集群不变但交付策略在变”,解耦后才好演进。
4.2 实战:创建 AttachedCluster + Fleet,并分发一个 GitRepo/Kustomize 应用
(1)把 member 集群 kubeconfig 放进 secret
kubectl create secret generic kurator-member1 \
--from-file=kurator-member1.config=/root/.kube/kurator-member1.config
kubectl create secret generic kurator-member2 \
--from-file=kurator-member2.config=/root/.kube/kurator-member2.config
(2)创建 AttachedCluster
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: kurator-member1
namespace: default
spec:
kubeconfig:
name: kurator-member1
key: kurator-member1.config
---
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: kurator-member2
namespace: default
spec:
kubeconfig:
name: kurator-member2
key: kurator-member2.config
(3)创建 Fleet(把两个 AttachedCluster 编成一组)
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: quickstart
namespace: default
spec:
clusters:
- name: kurator-member1
kind: AttachedCluster
- name: kurator-member2
kind: AttachedCluster
(4)创建 Application:以 GitRepo 为源,用 Kustomize 同步到 fleet
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: gitrepo-kustomization-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: master
timeout: 1m0s
url: https://github.com/stefanprodan/podinfo
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./deploy/webapp
prune: true
timeout: 2m0s
分发成功后,你能在两个 member 集群里看到对应 workload(文档示例用 kubectl get po -A --kubeconfig=... 验证)。
4.3 深度思考:统一分发≠完全相同,关键在“差异化一致”
真正的企业交付往往需要“看起来统一,但允许差异”——我建议你把差异分成三类来治理:
- 环境差异(env):dev/test/prod 的副本数、资源配额不同。
- 地域差异(region):例如华东集群接入本地 DB,华北集群接入另一套。
- 能力差异(capability):边缘集群可能没 GPU、没某种 CSI,部署清单需要自动降级。
Kurator 的 Application 文档提到:可以通过给 AttachedCluster 打 label,并在应用策略里用 selector 来选择集群,这非常适合做“差异化一致”。
五、统一策略管理:把安全基线变成“默认出厂设置”
这是Kurator 统一策略管理官方参考图,可以看到统一策略管理带来的优势: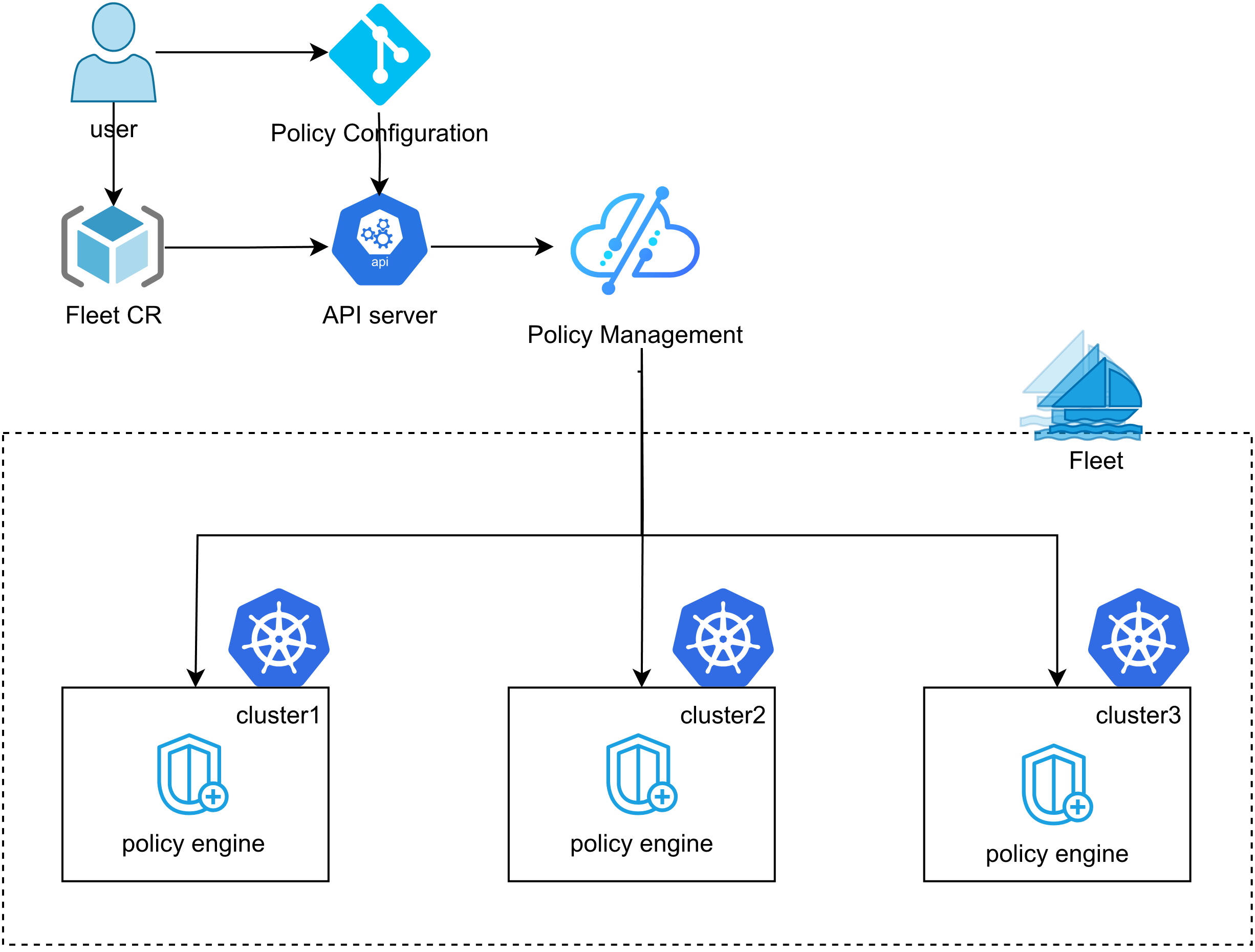
5.1 为什么 Kurator 选 Kyverno 做多集群策略底座
Fleet 的多集群策略管理是构建在 Kyverno 之上的:你可以把 Pod 安全基线、镜像准入、标签规范等作为“平台能力”下发到 fleet 内所有集群。
Kyverno 的优势在于:
- 策略本身也是 YAML,和 GitOps 天然契合;
- 既能 validate(拒绝/告警),也能 mutate(自动补齐字段),还能 generate(生成配套资源)。
对平台团队来说,这是“把经验固化成规则”的最佳载体。
5.2 实战:启用 baseline Pod Security,并让一个 bad pod 被扫描出违规
Kurator 的策略管理教程给出了一个很典型的演示:启用 baseline 的 PodSecurity 检查,然后通过 Application 分发一个“违规 pod”,最后在 member 集群里查看 policyreport,并在 pod event 里看到 PolicyViolation。
你可以直接按官方示例创建 fleet(启用 kyverno 插件)并验证:
kubectl apply -f examples/fleet/policy/kyverno.yaml
kubectl wait fleet quickstart --for='jsonpath={.status.phase}'=Ready
kubectl get policyreport --kubeconfig=/root/.kube/kurator-member1.config
kubectl describe pod badpod --kubeconfig=/root/.kube/kurator-member1.config | grep PolicyViolation
5.3 进阶建议:策略要“分层”,否则会把业务团队压垮
我见过不少平台做策略一上来就“强制 + 全量 + 一刀切”,最后结果往往是:业务方绕开平台、或者策略长期处于“全红但没人管”的状态。
更可持续的做法是三层:
- L0(默认基线):只做 PodSecurity baseline + 最小镜像安全约束(先告警不阻断)。
- L1(业务域基线):比如支付域更严格(必须只读根文件系统、强制非 root)。
- L2(集群特例):通过 label/selector 只对特定集群启用例外,且例外必须有过期时间(TTL),避免“临时开口子永久化”。
Fleet 把集群抽象为逻辑单元后,策略治理最重要的变化是:你可以在“fleet 级别”讨论安全一致性,而不是在“单集群”里打补丁。
六、统一发布与流量治理:让灰度从“手工改路由”变成“声明式发布”
6.1 Kurator Rollout 的本质:Application 扩展 + Flagger
Kurator 的 Rollout 方案是:借助 Flagger 做渐进式发布,并扩展 Kurator Application 的配置,使你能在一个地方同时声明“应用交付 + 发布策略”。
这解决了一个常见的组织问题:
- 应用 YAML 在应用团队手里
- 灰度策略在 SRE/网格团队手里
- 最后上线要跨团队同步,极易出错
Kurator 把它们收敛到同一份声明式对象里,让协作边界更清晰。
6.2 实战思路:同一份 Application 同时承载“交付 + 灰度”
Rollout 文档解释了流量迁移机制:rollout 插件会创建 service-primary / service-canary,其中 service-primary 是原 service 的深拷贝;通过修改 selector 与创建 VirtualService,把流量无中断迁移到 primary;当新版本触发时才出现 canary pod,并通过逐步调整 VirtualService 权重实现灰度。
你在落地时要抓住三个“控制点”:
- 触发发布:什么变化算“新版本”(镜像 tag、commit sha、Helm values)。
- 评价指标:灰度推进/回滚的信号来自哪里(Prometheus 指标、错误率、延迟、业务 SLI)。
- 流量提供方:目前 Provider 里强调 istio(以及其它路由方案的规划),你要先统一网格/Ingress 的标准栈。
6.3 专业落地建议:灰度不是功能,是“可验证的系统”
很多人把灰度当作“发一小部分流量试试”,但在分布式多集群时代,你必须把它系统化,否则你会遇到两类隐蔽风险:
- 指标不可比:A 集群有 sidecar,B 集群没有;A 的链路追踪采样 1%,B 是 100%,导致灰度决策失真。
- 回滚不可复现:回滚动作只改了路由,却没把配置/数据迁回去,导致“看似回滚成功但功能仍异常”。
建议你在 fleet 层面做统一约束:
- 统一可观测采集口径(指标名、label、采样率);
- 回滚不仅回镜像,还要回“配置与依赖版本”;
- 把灰度策略模板化(不同业务只填参数),而不是每个团队手写一套。
七、从实验室到企业落地:我会用三张“账”评估 Kurator 的长期价值
7.1 技术选型账:控制面放哪里、权限怎么收、网络怎么通
企业落地 Kurator,最先要回答三个工程问题:
- 管理控制面(kurator-host)部署在哪:放在中心云、还是主 Region?这关系到 API 延迟与可用性设计。
- 凭证与权限:AttachedCluster 通过 kubeconfig secret 连接集群;你要把它纳入密钥生命周期(轮转、审计、最小权限)。
- 跨集群网络:如果你的场景需要跨集群服务发现与通信,可以评估 fleet manager 提到的能力与 Submariner 插件路线。
7.2 场景收益账:哪些业务最先吃到红利
我建议按“收益密度”来选场景:
- 多地域同构微服务:最适合先用 Application 做统一分发,再叠加 Rollout 与策略。
- 云边协同/门店边缘:边缘集群数量多、版本碎,最需要“fleet 级一致性”。
- 合规强行业:把 Kyverno 基线做成默认交付物,效果往往立竿见影(因为减少了安全审计返工)。
7.3 生态与商业账:别只看功能列表,要看“运维成本曲线”
Kurator 的真正价值在于“把平台能力做成产品化交付”,降低长期运维成本曲线。你可以用这些可量化指标持续评估:
- 新增一个集群加入纳管所需时间(从天级降到小时/分钟级)
- 应用从提交到多集群一致上线的 lead time
- 重大故障 MTTR(尤其是跨集群问题)
- 安全基线覆盖率、违规数量趋势(是否真的下降而不是被忽略)
此外,Fleet API reference 把 Prometheus、Grafana、Kyverno、Velero、Rook、Flagger、Submariner 等插件配置都结构化为 Fleet.spec.plugin 的一部分(含默认 chart 来源与版本),这对“平台标准化交付”很关键:你不再靠 wiki 记忆“装什么、怎么装、装哪个版本”,而是靠对象状态对齐。
附:用 Go 代码把 Application 下发到 Kurator(示例)
这段代码的目标是展示:你可以把 Kurator 当作一个 API(而不是只能 kubectl apply),把它接入自研平台、流水线、Portal。
package main
import (
"context"
"flag"
"fmt"
"path/filepath"
"time"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/tools/clientcmd"
kuratorclient "kurator.dev/kurator/client-go/generated/clientset/versioned"
appsv1alpha1 "kurator.dev/kurator/apis/apps/v1alpha1"
)
func main() {
var kubeconfig string
flag.StringVar(&kubeconfig, "kubeconfig", filepath.Join("/root/.kube", "kurator-host.config"), "kubeconfig path")
flag.Parse()
cfg, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
if err != nil {
panic(err)
}
c, err := kuratorclient.NewForConfig(cfg)
if err != nil {
panic(err)
}
app := &appsv1alpha1.Application{
ObjectMeta: metav1.ObjectMeta{
Name: "api-created-app",
Namespace: "default",
},
Spec: appsv1alpha1.ApplicationSpec{
Source: appsv1alpha1.ApplicationSource{
GitRepository: &appsv1alpha1.GitRepositoryRef{
URL: "https://github.com/stefanprodan/podinfo",
Interval: metav1.Duration{Duration: 3 * time.Minute},
Ref: &appsv1alpha1.GitRepositoryRefRef{Branch: "master"},
Timeout: &metav1.Duration{Duration: 1 * time.Minute},
},
},
SyncPolicies: []appsv1alpha1.ApplicationSyncPolicy{
{
Destination: &appsv1alpha1.ApplicationDestination{
Fleet: "quickstart",
},
Kustomization: &appsv1alpha1.KustomizationSyncPolicy{
Path: "./deploy/webapp",
Prune: true,
Interval: metav1.Duration{Duration: 5 * time.Minute},
Timeout: &metav1.Duration{Duration: 2 * time.Minute},
},
},
},
},
}
created, err := c.AppsV1alpha1().Applications("default").Create(context.Background(), app, metav1.CreateOptions{})
if err != nil {
panic(err)
}
fmt.Printf("created application: %s/%s\n", created.Namespace, created.Name)
}
Kurator分布式云原生开源社区地址:https://gitcode.com/kurator-dev
Kurator分布式云原生项目部署指南:https://kurator.dev/docs/setup/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)