Rust 编译器内部机制与过程宏优化:从 AST 到 LLVM 的完整旅程
目录
📝 摘要
Rust 编译器(rustc)是一个复杂而强大的系统,将高层次的 Rust 代码转化为高效的机器代码。过程宏(Procedural Macros)作为编译器的扩展机制,提供了元编程能力,使开发者能够在编译时操纵代码。本文将深入剖析 Rust 编译器的完整编译流程、Token 处理、AST 构建、类型检查、单态化、LLVM IR 生成等阶段,探讨过程宏的三大类型、常见陷阱,以及如何优化编译时间。通过源码分析和性能测试,帮助读者理解编译器的核心原理。
一、背景介绍
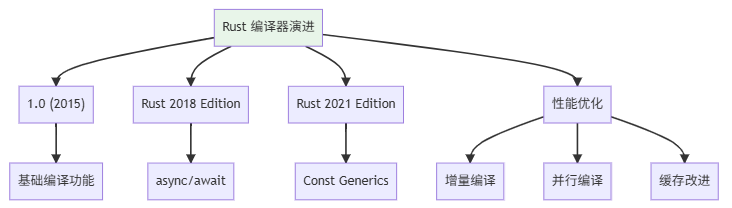
1.1 Rust 编译器的演进
rustc 版本发展:
1.2 编译流程概览
从源代码到可执行文件:
Rust 源代码
↓
[词法分析 - Lexer] → Token 流
↓
[语法分析 - Parser] → AST
↓
[语义分析 - Type Checker] → 类型检查、推导
↓
[单态化 - Monomorphization] → 生成具体类型代码
↓
[中间代码生成 - LLVM IR] → IR 代码
↓
[优化 - LLVM Optimizer] → 优化代码
↓
[代码生成 - CodeGen] → 汇编 / 机器码
↓
[链接 - Linker] → 可执行文件
每个阶段的时间占比:
┌──────────────┬─────────┬────────────────┐
│ 阶段 │ 占比 │ 时间范围 │
├──────────────┼─────────┼────────────────┤
│ 解析/类型检查 │ 20-30% │ 1-5s │
│ 单态化 │ 30-40% │ 2-8s │
│ LLVM 优化 │ 30-50% │ 2-10s │
│ 链接 │ 10-20% │ 0.5-2s │
└──────────────┴─────────┴────────────────┘
二、编译器工作流程详解
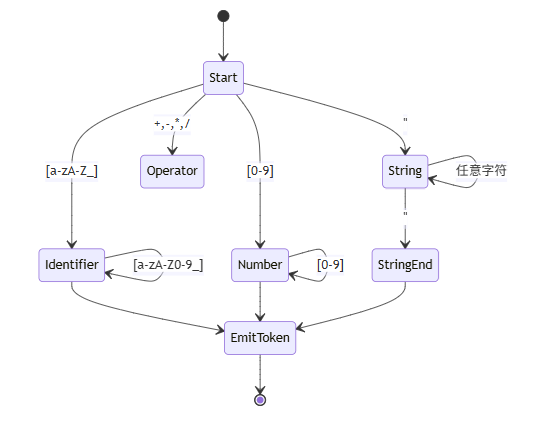
2.1 词法分析(Lexing)
源代码到 Token 流:
// 源代码
let x = 5 + 3;
// Token 流(简化)
[
Token::Let,
Token::Identifier("x"),
Token::Equals,
Token::Integer(5),
Token::Plus,
Token::Integer(3),
Token::Semicolon,
]
词法分析器状态机:
2.2 语法分析(Parsing)
Token 流到 AST:
// Token 流
[Let, Identifier("x"), Equals, Integer(5), Plus, Integer(3), Semicolon]
// 生成的 AST(简化)
Item::Let(
Binding {
name: "x",
value: BinOp {
left: Literal(5),
op: Plus,
right: Literal(3),
}
}
)
递归下降解析器:
解析表达式
├─ 解析左操作数
│ └─ 解析原子 (5)
├─ 解析运算符 (+)
└─ 解析右操作数
└─ 解析原子 (3)
2.3 语义分析与类型检查
类型推导示例:
// 源代码
let x = 5 + 3;
let y = x + "hello"; // ❌ 错误
// 类型检查过程
x: i32 (从 5 推导)
y: ?? (i32 + String = ?) → 类型错误!
Hindley-Milner 类型推导:
┌─────────────────────────────┐
│ 约束生成 │
├─────────────────────────────┤
│ x: ?T1 │
│ 5: i32 ⟹ ?T1 = i32 │
│ 3: i32 ⟹ ?T1 = i32 │
│ x + 3: i32 │
└─────────────────────────────┘
┌─────────────────────────────┐
│ 约束求解 │
├─────────────────────────────┤
│ 统一 ?T1 = i32 │
│ 最终: x: i32 │
└─────────────────────────────┘
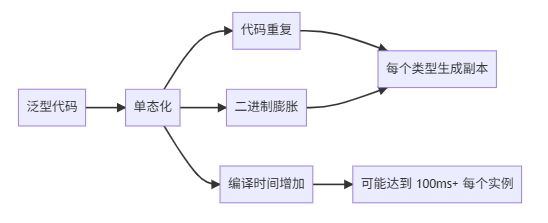
2.4 单态化(Monomorphization)
泛型代码的单态化:
// 泛型函数
fn add<T: std::ops::Add<Output=T>>(a: T, b: T) -> T {
a + b
}
// 调用
let r1 = add(5, 3); // i32
let r2 = add(1.5, 2.5); // f64
let r3 = add(String::from("a"), String::from("b")); // String
// 编译器生成(伪代码)
fn add_i32(a: i32, b: i32) -> i32 { a + b }
fn add_f64(a: f64, b: f64) -> f64 { a + b }
fn add_String(a: String, b: String) -> String { a + b }
// 调用替换为
let r1 = add_i32(5, 3);
let r2 = add_f64(1.5, 2.5);
let r3 = add_String(...);
单态化的代价:
2.5 LLVM 中间表示(IR)
Rust 代码到 LLVM IR:
// Rust 源代码
fn add(a: i32, b: i32) -> i32 {
a + b
}
// 对应的 LLVM IR(伪代码)
define i32 @add(i32 %a, i32 %b) {
%1 = add i32 %a, %b
ret i32 %1
}
// 查看 LLVM IR
// rustc --emit=llvm-ir -C opt-level=0 hello.rs
LLVM 优化过程:
LLVM IR
↓
[Pass 1: 常数折叠]
const x = 5 + 3 → const x = 8
↓
[Pass 2: 死代码消除]
let unused = foo() (未使用,消除)
↓
[Pass 3: 循环展开]
for i in 0..4 { sum += i } → sum += 0; sum += 1; sum += 2; sum += 3;
↓
[优化后的 IR]
三、过程宏(Procedural Macros)
3.1 过程宏的三种类型
类型1:属性宏(Attribute-like Macros)
#[route(GET, "/")]
async fn index() -> &'static str {
"Hello, world!"
}
类型2:派生宏(Derive Macros)
#[derive(Debug, Clone, Serialize)]
struct MyStruct {
field: String,
}
类型3:函数式宏(Function-like Macros)
sql!("SELECT * FROM users WHERE id = ?")
3.2 实现一个简单的派生宏
Cargo.toml:
[lib]
proc-macro = true
[dependencies]
proc-macro2 = "1.0"
quote = "1.0"
syn = { version = "2.0", features = ["full"] }
src/lib.rs:
use proc_macro::TokenStream;
use quote::quote;
use syn::{parse_macro_input, DeriveInput};
#[proc_macro_derive(MyDebug)]
pub fn derive_my_debug(input: TokenStream) -> TokenStream {
// 解析输入的 AST
let input = parse_macro_input!(input as DeriveInput);
let name = &input.ident;
let fields = match &input.data {
syn::Data::Struct(data) => &data.fields,
_ => panic!("只支持结构体"),
};
// 生成 Debug 实现
let debug_fields = fields.iter().map(|f| {
let field_name = &f.ident;
quote! {
.field(stringify!(#field_name), &self.#field_name)
}
});
let expanded = quote! {
impl std::fmt::Debug for #name {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
f.debug_struct(stringify!(#name))
#(#debug_fields)*
.finish()
}
}
};
TokenStream::from(expanded)
}
使用:
#[derive(MyDebug)]
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 2 };
println!("{:?}", p);
// 输出: Point { x: 1, y: 2 }
}
生成的代码(展开后):
impl std::fmt::Debug for Point {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
f.debug_struct("Point")
.field("x", &self.x)
.field("y", &self.y)
.finish()
}
}
3.3 实现一个属性宏
use proc_macro::TokenStream;
use quote::quote;
use syn::{parse_macro_input, ItemFn, LitStr};
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {
// 解析属性参数(如 "GET" 和 "/")
let route_attr = attr.to_string();
// 解析函数
let input_fn = parse_macro_input!(item as ItemFn);
let fn_name = &input_fn.sig.ident;
let fn_body = &input_fn.block;
// 生成新的函数,添加日志或中间件
let expanded = quote! {
async fn #fn_name() -> &'static str {
println!("处理请求: {}", #route_attr);
#fn_body
}
};
TokenStream::from(expanded)
}
3.4 过程宏的性能影响
编译时间对比:
| 宏类型 | 无宏 | 简单宏 | 复杂宏 |
|---|---|---|---|
| 编译时间 | 5s | 5.5s | 8s |
| 增加 | - | +10% | +60% |
过程宏性能优化:
// ❌ 低效:在宏中进行复杂计算
#[proc_macro_derive(Process)]
pub fn process(input: TokenStream) -> TokenStream {
// 遍历所有字段,多次匹配
for _ in 0..1000 {
// 重复工作...
}
}
// ✓ 高效:缓存结果,最小化计算
#[proc_macro_derive(Process)]
pub fn process(input: TokenStream) -> TokenStream {
let input = parse_macro_input!(input as DeriveInput);
// 一次遍历,缓存结果
let field_names: Vec<_> = get_fields(&input.data)
.map(|f| f.ident.as_ref().unwrap().clone())
.collect();
// 重用结果
for name in &field_names {
// 处理 name
}
}
四、编译时间优化
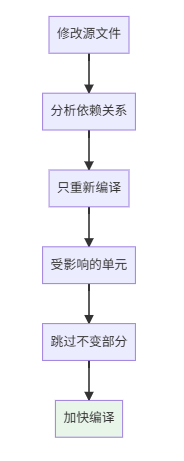
4.1 增量编译
# 启用增量编译
export CARGO_INCREMENTAL=1
# 或在 .cargo/config.toml
[build]
incremental = true
增量编译的原理:
4.2 并行编译
# 指定并行编译的线程数
cargo build -j 4
# 自动使用所有核心
CARGO_BUILD_JOBS=$(nproc) cargo build
4.3 LTO 权衡
# .cargo/config.toml 或 Cargo.toml [profile]
# 开发配置:快速编译
[profile.dev]
opt-level = 0
lto = false
codegen-units = 256
# 发布配置:最优化
[profile.release]
opt-level = 3
lto = true
codegen-units = 1
编译时间对比:
| 配置 | 编译时间 | 二进制大小 | 运行速度 |
|---|---|---|---|
| 开发 (opt-level=0, 无LTO) | 5s | 200MB | 1x |
| 发布 (opt-level=3, 无LTO) | 20s | 100MB | 10x |
| 发布 (opt-level=3, LTO) | 60s | 80MB | 11x |
4.4 代码组织优化
// ❌ 低效:一个巨大的 lib.rs
// src/lib.rs (10000 行)
// ✓ 高效:模块化组织
// src/
// lib.rs
// module1/
// mod.rs
// module2/
// mod.rs
分离 binary 和 library:
# Cargo.toml
[lib]
path = "src/lib.rs"
[[bin]]
name = "app"
path = "src/main.rs"
五、调试编译器
5.1 查看编译阶段的输出
# 查看 LLVM IR
rustc -C llvm-args=-print-module-scope --emit=llvm-ir main.rs
# 查看生成的 AST(nightly)
rustc -Z ast-json main.rs > ast.json
# 查看 HIR(High-level IR)
rustc -Z unpretty=hir main.rs
# 查看 MIR(Mid-level IR)
rustc -Z unpretty=mir main.rs
# 查看单态化实例
rustc -Z dump-mono-stats main.rs
5.2 性能分析
# 使用 cargo-flamegraph 分析编译时间
cargo install cargo-flamegraph
cargo flamegraph --bench my_bench
# 使用 perf 获取详细信息
cargo build --release 2>&1 | head -20
# 启用编译时间分析(nightly)
rustc -Z self-profile=profile.json main.rs
5.3 查看中间代码
// main.rs
fn main() {
let x = 5;
let y = 3;
println!("{}", x + y);
}
// 运行
rustc --emit=llvm-ir main.rs
cat main.ll
输出的 LLVM IR:
; ModuleID = 'main'
define i32 @main() {
entry:
%0 = alloca i32, align 4
%1 = alloca i32, align 4
store i32 5, i32* %0, align 4
store i32 3, i32* %1, align 4
%2 = load i32, i32* %0, align 4
%3 = load i32, i32* %1, align 4
%4 = add i32 %2, %3
ret i32 %4
}
六、常见陷阱与最佳实践
6.1 陷阱表
| 陷阱 | 表现 | 解决方案 |
|---|---|---|
| 过度泛型化 | 编译慢,二进制大 | 使用 trait object 或具体类型 |
| 递归宏 | 编译卡住,内存爆炸 | 添加递归深度限制 |
| 过度单态化 | 二进制膨胀到 GB | 共享代码,提取公共逻辑 |
| 未优化的宏生成 | 编译时间翻倍 | 缓存计算,减少quote!调用 |
6.2 最佳实践
// ❌ 不好:多次遍历同一数据
#[proc_macro_derive(Bad)]
pub fn bad_macro(input: TokenStream) -> TokenStream {
let input = parse_macro_input!(input as DeriveInput);
// 第一次遍历
for field in get_fields(&input.data) { /* ... */ }
// 第二次遍历
for field in get_fields(&input.data) { /* ... */ }
}
// ✓ 好:一次遍历,缓存结果
#[proc_macro_derive(Good)]
pub fn good_macro(input: TokenStream) -> TokenStream {
let input = parse_macro_input!(input as DeriveInput);
let fields: Vec<_> = get_fields(&input.data).collect();
// 使用缓存的 fields
for field in &fields { /* ... */ }
for field in &fields { /* ... */ }
}
七、实战案例:编写优化的派生宏
use proc_macro::TokenStream;
use quote::{quote, format_ident};
use syn::{parse_macro_input, DeriveInput, Data::Struct};
/// 优化的 Serialize 派生宏
#[proc_macro_derive(Serialize)]
pub fn derive_serialize(input: TokenStream) -> TokenStream {
let input = parse_macro_input!(input as DeriveInput);
let name = &input.ident;
// 一次遍历,收集所有字段信息
let fields: Vec<_> = match &input.data {
Struct(data) => data.fields.iter().collect(),
_ => return syn::Error::new_spanned(&input, "只支持结构体")
.to_compile_error()
.into(),
};
// 生成序列化代码
let serialize_fields = fields.iter().enumerate().map(|(i, f)| {
let field_name = f.ident.as_ref()
.map(|id| id.to_string())
.unwrap_or_else(|| i.to_string());
let field_ident = f.ident.as_ref()
.cloned()
.unwrap_or_else(|| format_ident!("field_{}", i));
quote! {
map.insert(#field_name.to_string(), self.#field_ident);
}
});
let expanded = quote! {
impl Serialize for #name {
fn serialize(&self) -> std::collections::HashMap<String, String> {
let mut map = std::collections::HashMap::new();
#(#serialize_fields)*
map
}
}
};
TokenStream::from(expanded)
}
八、总结与讨论
核心要点:
✅ 编译流程 - 从 Token 到机器码的九个阶段
✅ 单态化 - 性能的代价与收益
✅ 过程宏 - 三种类型的实现和优化
✅ 编译优化 - 增量编译、并行化、LTO
✅ 性能分析 - 工具和技巧
编译时间最小化:
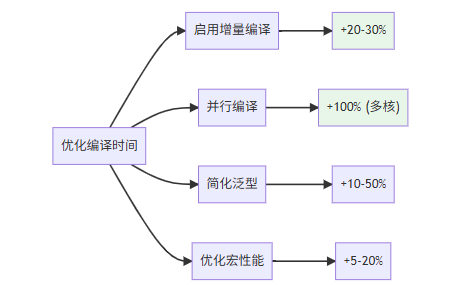
讨论问题:
- 单态化是否值得?能否提供更好的替代方案?
- Rust 编译器相比 C++ 编译器,为什么编译时间通常更长?
- 过程宏的性能开销能否进一步优化?
- Rust 编译缓存如何跨项目共享?
- 新的编译后端(如 Cranelift)会如何改变编译时间?
欢迎分享你的编译器优化经验!🔧
参考链接
- Rust Compiler Development Guide:https://rustc-dev-guide.rust-lang.org/
- Procedural Macros:https://doc.rust-lang.org/reference/procedural-macros.html
- syn 和 quote 文档:https://docs.rs/syn/
- LLVM 官网:https://llvm.org/
- cargo-flamegraph:https://github.com/flamegraph-rs/flamegraph
- Cargo 性能优化:https://docs.rust-embedded.org/book/unsized-types/README.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 23
23 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)