[AI]Spring AI Emoji 图标语义检索系统设计与实现
为了在网页或 App 中根据用户的抽象业务场景(如“支付”、“设置”、“购物车”)精准匹配直观的 Emoji 图标,pap4j-boot3 在 pap4j-boot3-example-spring-ai 模块中实现了一套 Emoji 图标语义检索系统。
本文档详细记录了该功能的核心设计方案、实现逻辑、响应式非阻塞调优以及在中文场景下的优化实践。
1. 核心设计方案
传统关键字匹配无法解决抽象概念的联想问题(例如输入“付款”无法匹配到标有“钱包”或“信用卡”的图标)。本项目通过 “LLM 语义改写 + 本地向量检索 + 元数据过滤” 的组合方案来解决这一问题:
┌──────────────┐ 输入业务词 ┌────────────────┐ 物理关联词组 ┌────────────────┐
│ 用户输入场景 ├────────────────>│ LLM 提示词翻译 ├────────────────>│ 本地向量数据库 │
│ (如: 支付付款) │ (语义概念翻译) │ (如: 钱包/钞票) │ (相似度向量检索) │ (SimpleStore) │
└──────────────┘ └────────────────┘ └────────┬───────┘
│ 过滤 type == 'emoji'
▼
┌──────────────┐ 返回相似度 Top-K ┌────────────────┐
│ 前端页面渲染 │<───────────────────────────────────────────────────┤ Emoji 图标集合 │
│ (显示图标列表) │ │ (携带相似度分数)│
└──────────────┘ └────────────────┘
- 数据初始化向量化:应用启动时,系统解析本地 Emoji 字典数据(
annotations.json),使用本地 Embedding 模型生成向量,并打上type: emoji元数据标签存入向量库。 - LLM 语义改写:当用户输入抽象场景词(如“我的”)时,利用大模型将其改写为具体的物理实体词汇(如“头像 人 用户 账号”),以契合 Emoji 的官方关键字描述。
- 向量检索与隔离:使用改写后的词组在向量库中进行相似度检索,通过元数据过滤器(
type == 'emoji') 限制召回范围,防止与常规 RAG 问答文档产生冲突。
🚀 2. 核心代码设计与实现
2.1 数据源解析与加载
在系统启动时,通过 loadAndVectorizeEmojis 方法解析本地 Emoji 描述字典,将其封装为 Document 对象并附加元数据:
Document doc = new Document(
combinedText, // 例如: "钱 信用卡 钱包 银行 钞票 支付"
Map.of("type", "emoji", "emoji", emojiChar) // 元数据携带 emoji 图标字符
);
2.2 无状态模型调用与向量检索
在 AiController.java 中,为了避免与常规对话共享 ChatMemory 顾问造成上下文干扰,使用注入的 ChatClient.Builder 创建一个不含 Advisor 的无状态 statelessChatClient 来执行关键词改写:
// 1. 调用大模型,将抽象功能描述翻译为具体的物理词汇
String rewrittenQuery = statelessChatClient.prompt()
.system(systemPrompt)
.user(request.prompt())
.call()
.content();
// 2. 将翻译词去向量库匹配对应的 Emoji 文档,并指定 type 过滤
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder()
.query(rewrittenQuery)
.topK(limit)
.filterExpression("type == 'emoji'") // 关键:指定过滤条件
.build()
);
💻 3. 核心调优实践
3.1 解决系统报错与性能卡顿 (WebFlux & 机械硬盘适配)
在功能开发完后,我们在测试时遇到了两个影响运行的问题,并针对性做了优化:
问题 1:调用大模型接口时系统直接报错崩溃
- 原因:Spring AI 向大模型发请求时是“原地等待”的。而我们的项目使用的是响应式(WebFlux)架构,它要求主处理通道必须“即时响应、不能卡着”。如果直接在主通道上等大模型慢悠悠地回答,系统为了防止整机卡死,就会主动拦截并报出
are blocking的安全错误。 - 解决办法:我们将代码改为了异步模式。把需要“等大模型回答”和“等数据库检索”的耗时工作,全部打包丢给专门的后台工作线程去跑,让出主通道,彻底解决了卡死报错问题。
@PostMapping("/emoji")
public Mono<List<EmojiResponse>> searchEmoji(@RequestBody EmojiRequest request) {
return Mono.fromCallable(() -> {
// ... (将等大模型回答、等向量库检索等耗时操作打包)
}).subscribeOn(Schedulers.boundedElastic()); // 丢给专门的后台工作线程去跑
}
3.2 中文向量检索表征模型 (Embedding Model) 优化
问题背景:Spring AI Transformers 默认自带的本地 ONNX 模型是英文专属的 all-MiniLM-L6-v2,其分词词表(tokenizer.json)中不含中文字符,导致输入中文词汇时的向量生成失真,语义检索准确率极低。
解决方案:将项目 src/main/resources/onnx/下的 model.onnx 与 tokenizer.json 文件替换为原生支持中文的 bge-small-zh-v1.5 向量模型。在保留纯 Java 离线部署、零网络开销优点的同时,大幅提升了中文语义检索的匹配率。
📊 4. 效果演示
目前系统在前端页面中提供了直观的交互体验,常见业务场景下的检索匹配效果如下:
场景 A:支付功能图标匹配
当输入“支付”或者“付款”等词汇时,大模型会成功将其翻译为“钱包”、“钞票”、“信用卡”、“银行”等物理概念,成功召回了相关的金融系图标: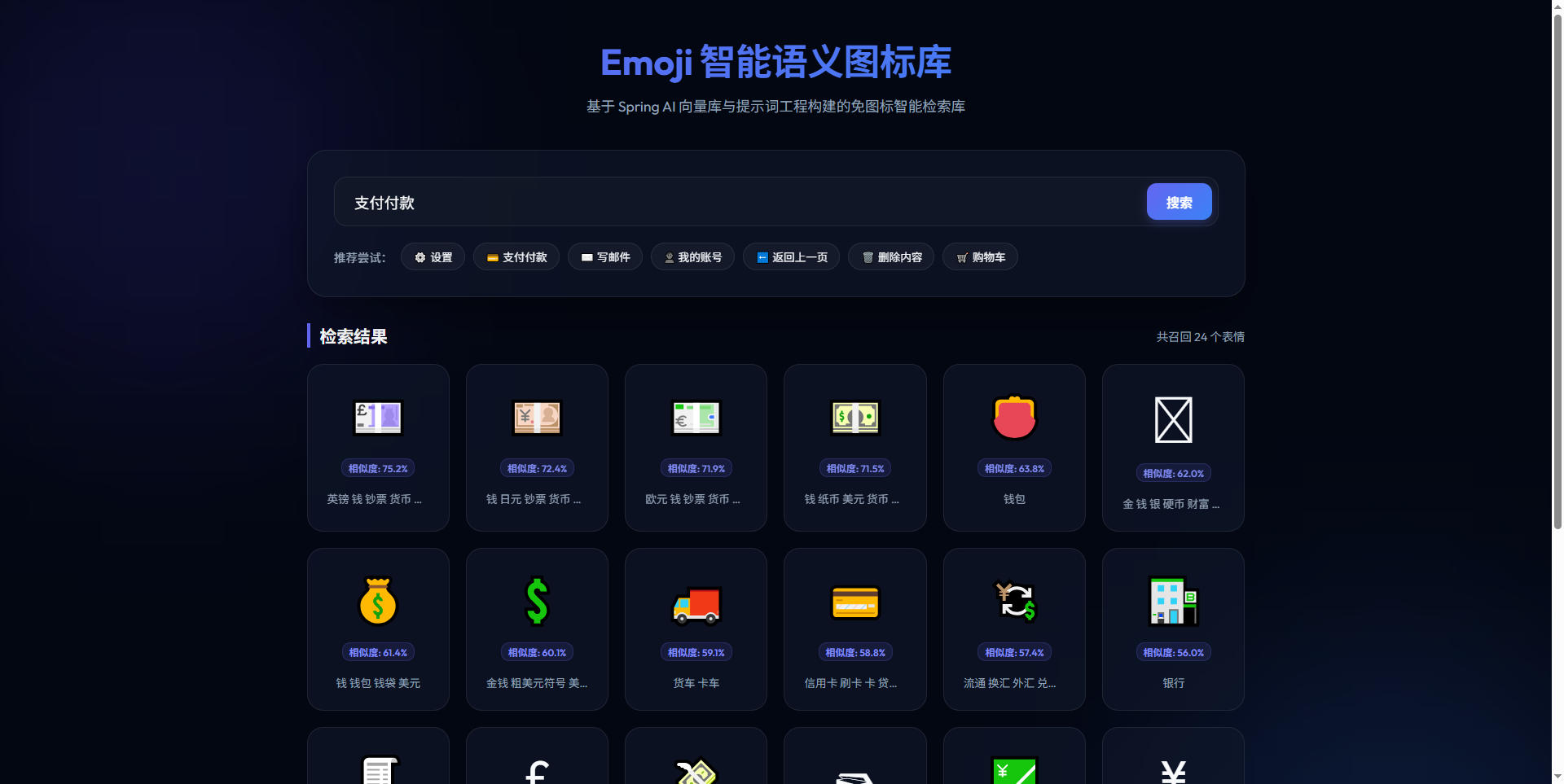
图像备份: 访问
场景 B:商城/购物车图标匹配
当输入“去商店买东西”等长句场景时,模型理解其代表购物意图,精准召回了店铺、袋子、购物车等图标: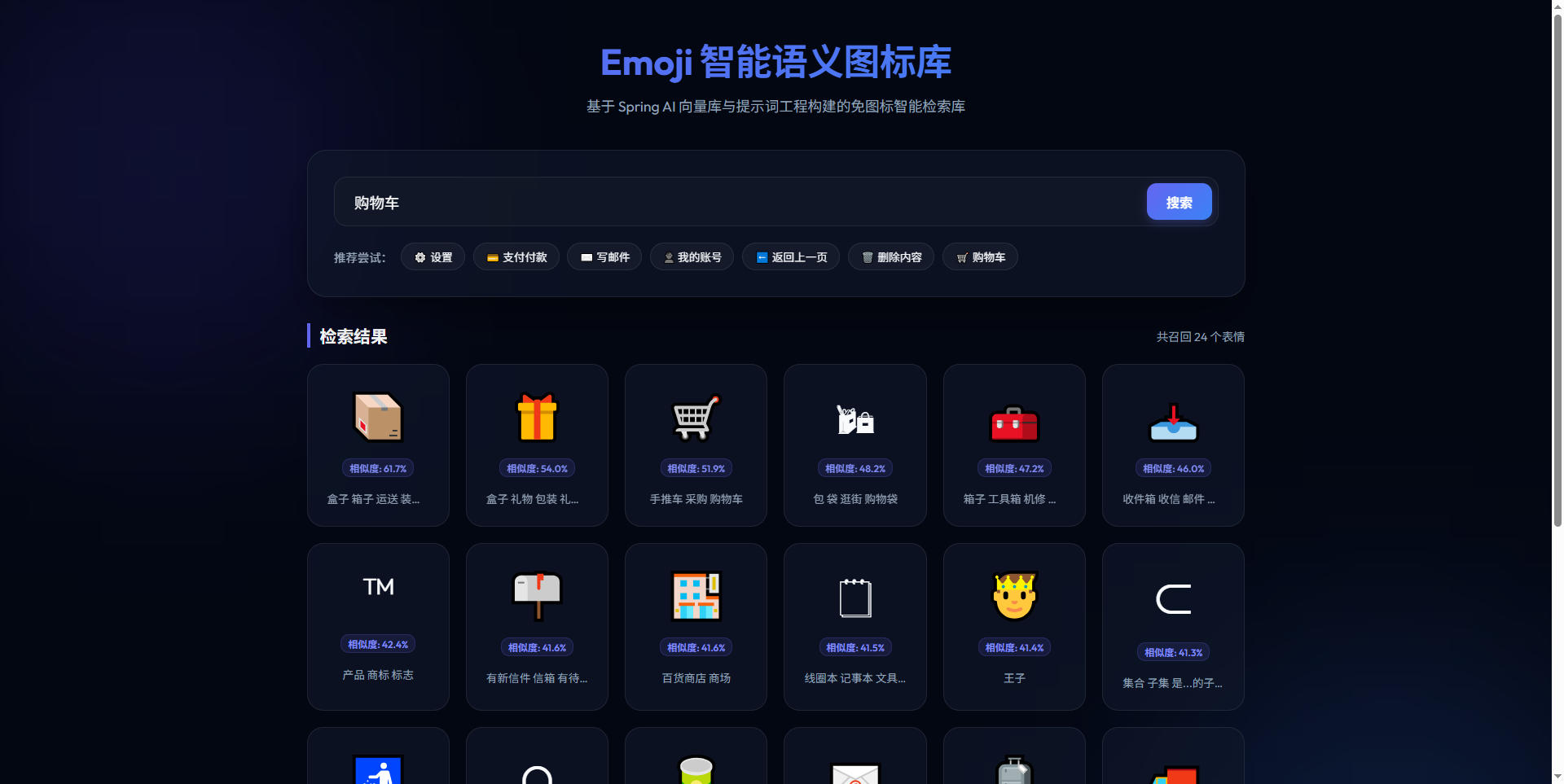
图像备份: 访问
场景 C:删除/清空图标匹配
当输入“清空列表”或“删除数据”等抽象指令时,智能匹配出了垃圾桶、交叉、乘号、禁止等视觉符号: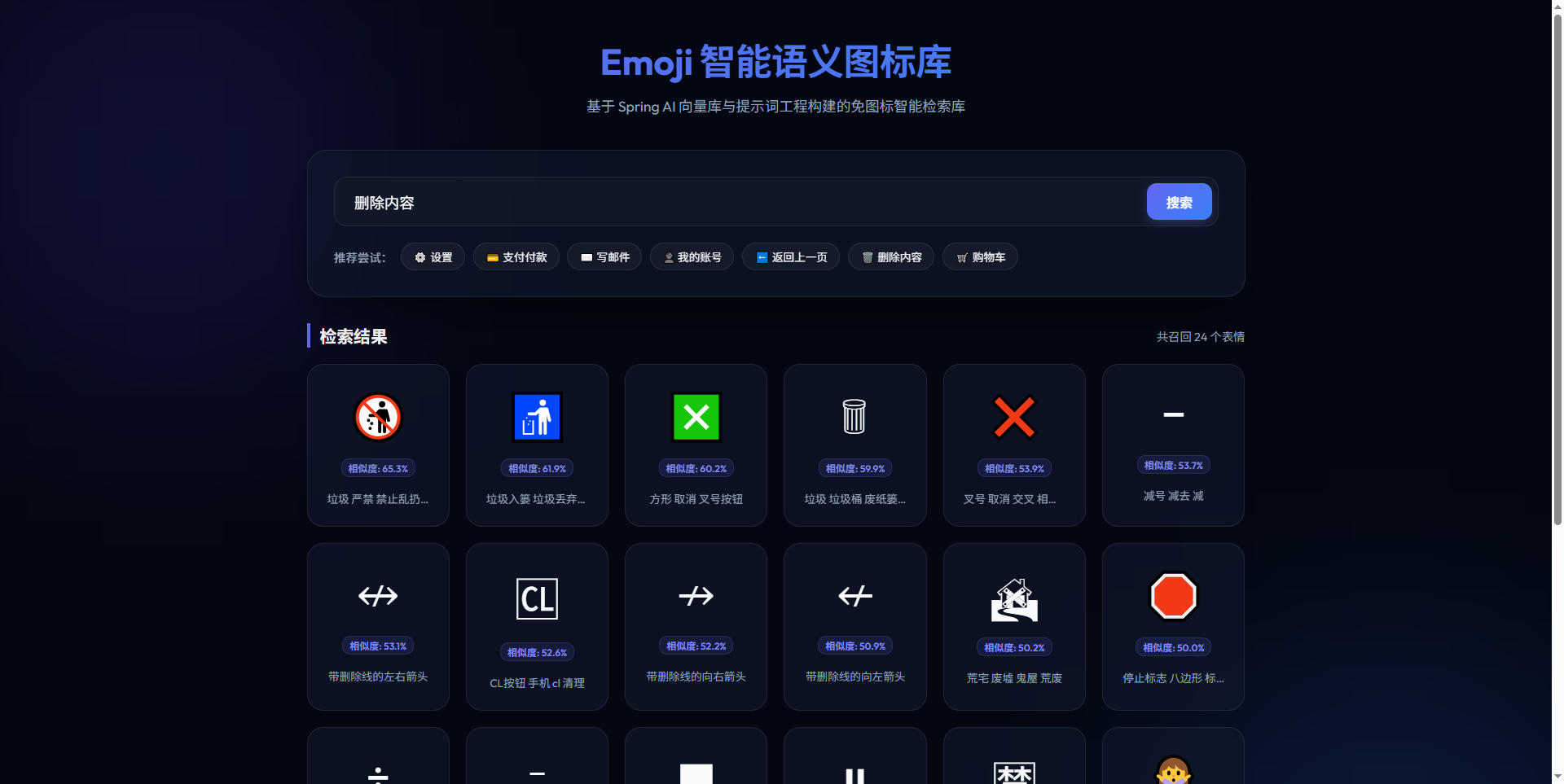
图像备份: 访问
场景 D:返回/后退图标匹配
当输入“回到上一页”等导航动作时,召回了各种指向左侧、撤销、回退的箭头图标: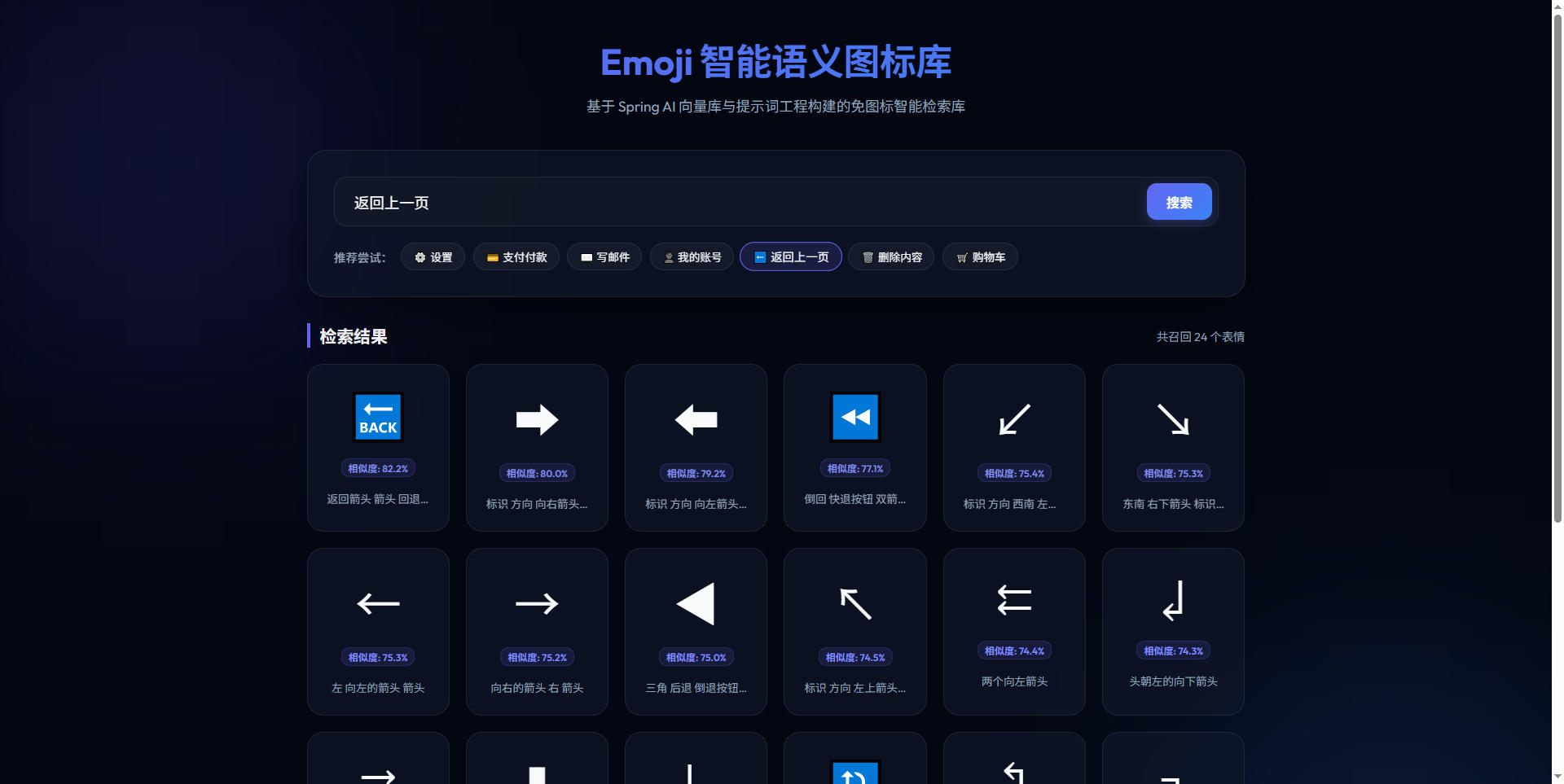
图像备份: 访问
📝 总结
通过 Spring AI 与本地 ONNX 向量数据库结合,本项目在完全本地化、私有化部署的前提下实现了一套低延迟的图标语义检索服务。该方案有效解决了抽象业务需求与直观视觉符号之间的匹配问题,是工程实践中的一个典型应用案例。
🔗 参考
- https://pap-docs.pap.net.cn/
- https://gitee.com/alexgaoyh/pap4j-boot3
- https://huggingface.co/Xenova/bge-small-zh-v1.5

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)