AI通识:Token、提示词、多模态到底是什么?一个开发者的认知笔记
认识AI
从豆包开始,这是聊天交互式问答。
人工智能(Artificial Intelligence,简称 AI),就是让机器模仿人类的思考、感知、判断、学习、表达能力,完成原本需要人类智慧才能做的事。
AI分类
弱人工智能:只能单一领域完成特定任务,没有自我意识,不会自主思考、没有情感。
生活里随处可见:
聊天 AI:豆包、ChatGPT
图像识别:人脸识别、拍照搜图、美颜、车牌识别
语音 AI:语音转文字、导航语音助手、翻译软件
推荐算法:短视频、电商、音乐推荐
工具 AI:AI 绘图、AI 剪辑、办公自动写文案、自动驾驶辅助
强人工智能,也称为:通用人工智能(AGI 全称是 Artificial General Intelligence)指能够像人类一样,理解和执行任何智力任务的AI。它不需要针对每个任务单独训练,而是具备跨领域的推理、学习、规划和创造能力。
实现底层算法
要使用计算机完成模拟人类智慧的工作就需要特定算法。这个特定算法发展如下:
-
基于规则: 按照语法说话
-
基于连接:深度学习,统计学
| 维度 | 第一阶段:符号主义 | 第二阶段:连接主义(当前主流) | 第三阶段:具身智能/因果推断(未来) |
| 主流时间 | 1950s - 1980s(繁荣期) (90年代后沉寂) |
2012年 - 至今 (ImageNet竞赛夺冠为引爆点) |
现在 - 未来10年 (尚处早期探索阶段) |
| 主要算法 | 规则库 + 逻辑推理 (如:If-Then决策树、谓词逻辑、知识图谱) |
深度神经网络(DNN) (Transformer、Diffusion、MoE混合专家模型) |
世界模型 + 因果图 + 强化学习 (如:Sora的视频物理模拟、Judea Pearl的因果演算) |
| 本质(一句话说清) | “死记硬背” 把人类的显性知识写成代码规则,让电脑照章办事。 |
“完形填空” 通过海量数据统计词与词、像素与像素之间的关联概率。 |
“动手试错” 在模拟环境或现实物理世界中互动,理解“因为A所以B”的逻辑。 |
| 典型应用 | 银行审批系统、老式专家问诊、传统ERP的审批流引擎。 | ChatGPT、Midjourney、Cursor代码生成、自动驾驶的环境感知。 | 通用家务机器人、AI科学家(自动做实验搞科研)、高级经营决策参谋。 |
| 核心不足(与人类的差距) | 极度脆弱且僵化。 遇到规则库里没有的例外情况,直接报错崩溃,毫无泛化能力。 |
毫无因果与常识。 不“理解”物理世界。能生成吃面的图,但不知道面进嘴要闭上;能写代码,但看不懂“库存负数”背后的资金链危机。 |
尚未成熟,算力消耗极大。 目前只能在极其简单的游戏或模拟环境中跑通,复杂真实世界的数据采集太难。 |
算法实现过程
有了底层的算法,就在这个算法上面构建应用。
深度学习是算法理论,实现这个算法的实现框架之一是Transformer。基于Transformer框架按照不同的用途训练就会产生善于处理什么问题的模型。
大语言模型(Large Language Model),简称LLM。就是Transformer为了处理文本预测进行的训练得到的产品。当然还能造人脸识别、自动驾驶、AlphaFold(蛋白质折叠)等产品。
大模型应用开发:大模型LLM可以进行文本的预测,基于这个功能就可以进行任务规划思考,比如输入:
linux环境 遇到/smartshell/health接口访问慢问题,底层能力有连接ssh,访问db能力。 当然访问哪个组件,访问哪个DB数据库 可以通过Function Calling提供,或者直接上下文给你。对这个问题核查进行步骤规划,不要罗列细节,只罗列步骤,以及需要的工具和参数,不要其他多余内容。 按照{步骤:,工具:,参数:* 等}这样的机构化数据输出
就会输出如下步骤,如果再约束步骤类型,那么软件可以更加不同的类型执行,比如:查询一个接口;访问Linux中Nginx的日志文件;执行一条Linux命令等。

最后再讲执行结果返回给LLM看,这样核查问题可能是一个图,这就利用大模型开发出了一个智能问题核查平台。
基于LLM大模型的应用开发问题
产品级的大模型开发远远不止上述几句话,需要考虑问题如下:
-
大模型是自己部署,还是用外部服务;
-
本地化部署是用公有云,还是私有云
-
部署什么大模型,只处理文字还是得处理图片,视频等
-
自己部署应该满足什么硬件条件,如果太过看看大模型服务商价格
-
购买水果按照一斤一斤算,使用别人的大模型用什么单位衡量价格
-
大模型有什么功能,是否可以调用我自己的接口,以及访问网络的功能
-
如果需要基于我自己的数据进行回答问题,那么怎么实现
-
将数据训练到模型中肯定行,但如果文档有变化可以撤销这种训练吗。如一项规定现在成立,过段时间就废止
-
访问大模型是否有状态,即会话。微服务为了提高并发量不支持状态,那么大模型呢
-
如果没有状态,那么应用需要实现回话,怎么进行会话的保持
-
会话保持是不是每次将前面的问答数据全部给大模型,那么消耗token太浪费了,应该怎么处理
-
如果是智能系统,基于LLM大模型概率统计结果,可能循环,怎么控制不要进入死循环
-
跟LLM对话前怎么进行约定,比如不要执行高危命令
-
基于LLM模型实现的不同智能系统是否有抽象为平台的可能,如果可能应该怎么抽象。毕竟实现一套系统经过配置就可以解决不同的问题多好
……
以上就是基于LLM大预言模型应用开发需要解决的问题。
认识大模型
怎么交互
调用模型的HTTP接口。类似WEB页面接口一样,通过HTTP接口访问大模型,大模型会按照数据流方式返回。
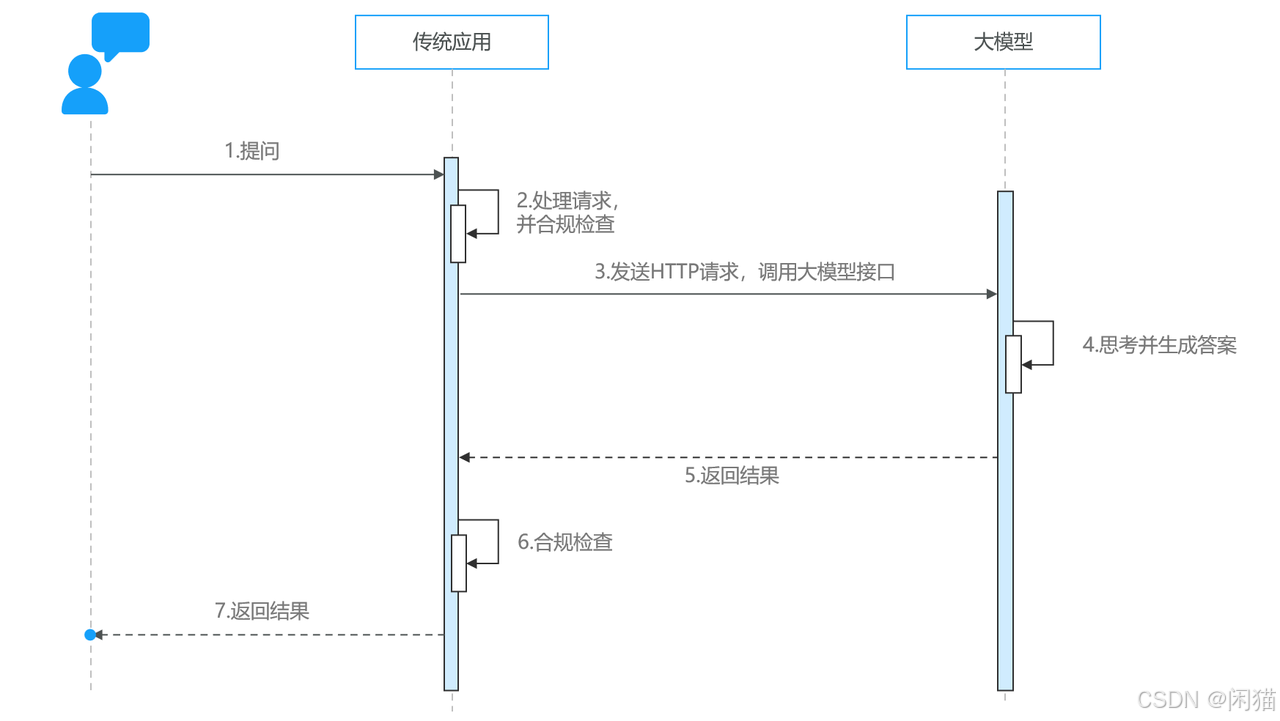
举例:DeepSeek交互接口详细参考:对话补全 | DeepSeek API Docs
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\n \"messages\": [\n {\n \"content\": \"You are a helpful assistant\",\n \"role\": \"system\"\n },\n {\n \"content\": \"Hi\",\n \"role\": \"user\"\n }\n ],\n \"model\": \"deepseek-v4-pro\",\n \"thinking\": {\n \"type\": \"enabled\"\n },\n \"reasoning_effort\": \"high\",\n \"max_tokens\": 4096,\n \"response_format\": {\n \"type\": \"text\"\n },\n \"stop\": null,\n \"stream\": false,\n \"stream_options\": null,\n \"temperature\": 1,\n \"top_p\": 1,\n \"tools\": null,\n \"tool_choice\": \"none\",\n \"logprobs\": false,\n \"top_logprobs\": null\n}");
Request request = new Request.Builder()
.url("https://api.deepseek.com/chat/completions")
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer <TOKEN>")
.build();
Response response = client.newCall(request).execute();大模型调用我的接口
以Deepseek开发平台为例:
Tool Calls | DeepSeek API Docs
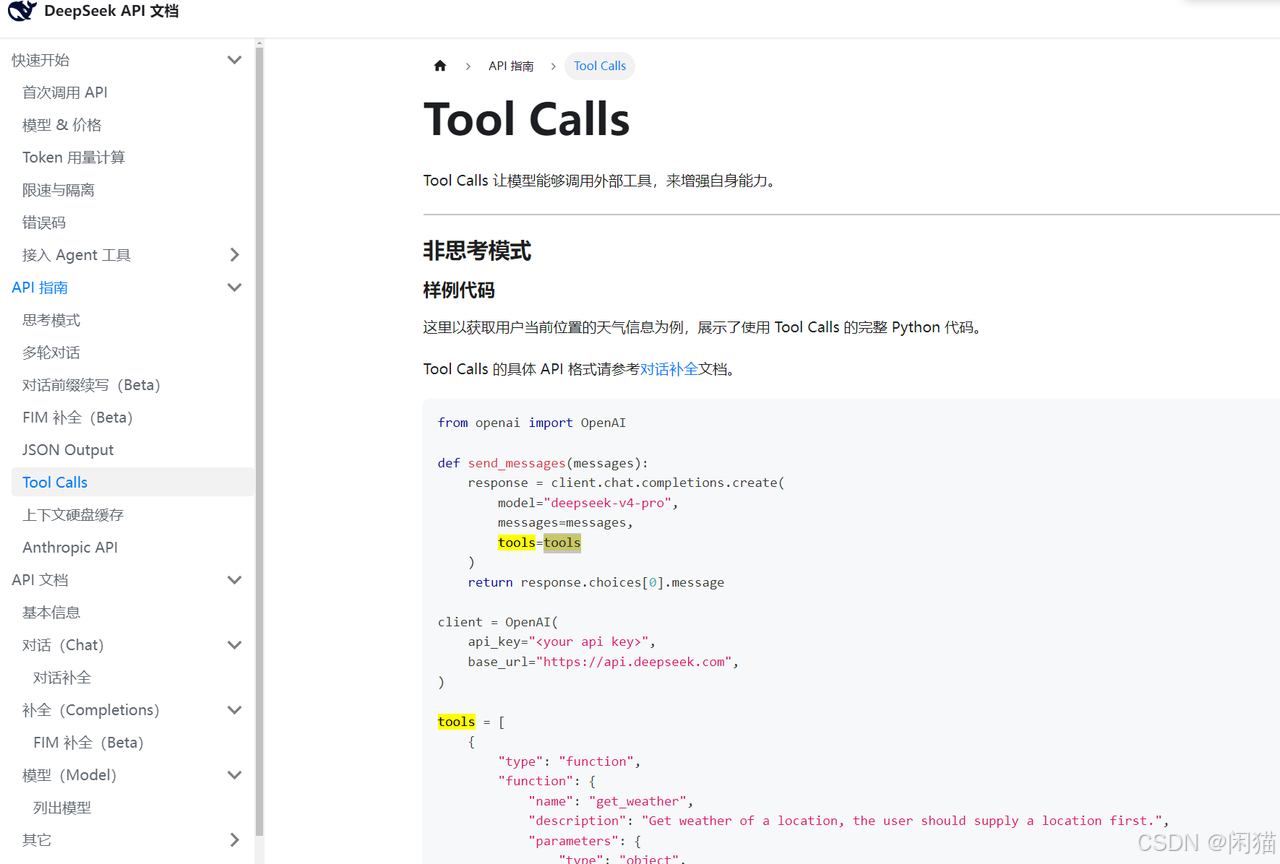
外部工具跟大模型交互智能通过这个来实现。如果使用Java Spring AI来访问效果是,大模型调用了我的getWeather方法了。实际上大模型并不清楚客户端地址,是不会回调的。大模型只是告诉客户端应该调用getWeather方法,参数为***。是客户端自己完成调用的。
认识大模型费用
这就要从大模型的成本说起,做个大模型包括前期一次性投入的研发费用,以及上线后的运营费用。
研发费用:你的“一次性投入” (CAPEX)
这是指在模型能够上线运行之前,所有“打地基”的花费。虽然你叫它“一次性”,但更准确的说法是高门槛的固定成本,它主要包括:
-
算力硬件:购买或租赁数千甚至上万张顶级GPU(如NVIDIA H100/A100)的集群。这是最烧钱的部分,单张卡价格就高达数万到数十万人民币。
-
数据工程:数据的采集、清洗、标注、脱敏。构建一个高质量的训练数据集,其成本可能不低于硬件费用。
-
研发团队薪酬:顶尖的算法研究员、系统工程师、数据科学家的高昂人力成本。
-
实验性试错:在模型架构、超参数上的大量“失败”实验。这些都是沉默成本,但也是必经之路。
关键点:这笔费用投入完成后,你得到的是一个“初始模型”。它就像一个刚刚大学毕业的学霸,知识渊博但缺乏实际工作的“经验”。
运营费用:你的“按使用量计算” (OPEX)
当模型部署上线,开始对外提供服务后,就进入了你提到的运营阶段。这笔费用与使用量直接挂钩,是持续性的现金流支出。它并非单一的“算力费”,而是由三部分构成:
| 费用构成 | 通俗解释 | 对应你提到的点 |
| 推理算力费 (核心) | 每一次用户提问,模型都需要用GPU重新计算一遍,这个计算过程直接消耗电力和GPU寿命。这就是Token计费的根本原因。 | “每次使用量”、“GPU费用”、“电费” |
| 基础运维费 | 服务器机房的租赁、制冷散热、网络带宽、以及运维工程师的7x24小时值班监控。 | “维护等费用” |
| 持续优化费 | 为了让模型更好,需要定期用新数据做二次微调(Fine-tuning) 或增量训练。这也需要消耗额外的算力,但不计入每次推理的成本中。 |
对大模型厂商而言:得降低运营费用才可以具有竞争力
对于开发者而言:产品设计就需要非常精细:如何通过更好的Prompt设计,用最少的Token完成任务?如何通过缓存机制,避免对同一问题的重复计算?这些优化直接决定了你的产品能否盈利。
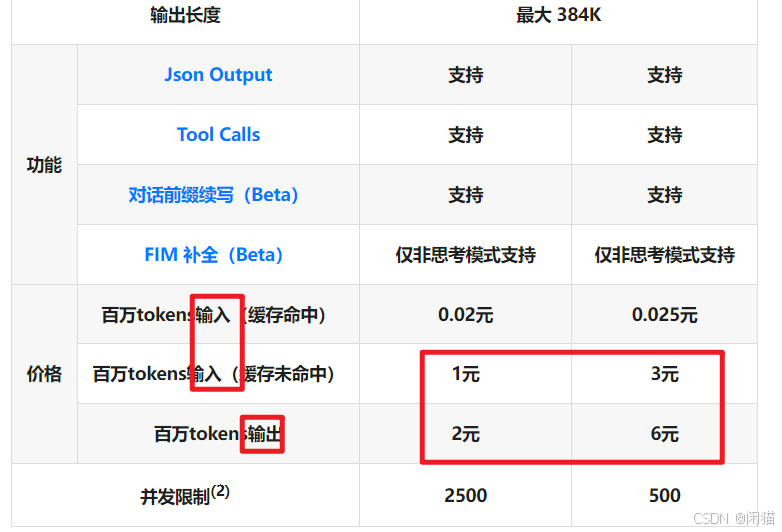
Deepseek API价格
可以看出输出比输入贵。在设计应用时,尽量让模型“少说废话”。通过Prompt明确限制输出长度(如max_tokens),能直接帮你省钱。模型 & 价格 | DeepSeek API Docs
认识 Token
大模型的输入字符串 代表 大模型需要理解的内容。输出字符串 代表 大模型需要运行得出的结果。
输入输出的字符长度就代表运算的多少。
Token是模型能够理解和生成的最小文本单元。它不直接等于一个字或一个单词,而是介于“字符”和“单词”之间的一种“切片”。
举个例子,对于中文“你好世界”:
-
在很多模型(如DeepSeek、GPT)的分词器中,它可能被切分为
["你", "好", "世界"]这3个Token。 -
但对于英文
"Hello world",它可能被切分为["Hello", " world"]这2个Token(注意空格也算)。
Prompt 提示词
跟大模型交互的输入文本,以及对大模型的参数控制 就是提示词。
类似你跟一个人沟通:
用不超过20个字,描述一下公司的愿景,不清楚就说不清楚,别瞎逼逼
你对别人的要求是:描述公司的愿景
限制呢:字数<20; 不清楚就说不清楚,不要自我理解的说
要想大模型回答的准确就需要一次性将问题描述清楚,比如:大模型站的角度扮演的角色;问的问题;输出要求是什么,以及一些限制,比如字数等,也可以给个样本; 是否有背景知识(上下文)介绍;如果有思考思路,可以将思考输入给大模型,先做什么后做什么; 最后强调知道就说知道,不清楚别瞎逼逼。
提示词工程可以说是当前AI应用开发中投入产出比最高的技能之一。它不需要你训练模型,只需调整语言,就能几十倍地提升效果。
状态 & 会话
每次调用都是没状态的,类似:你去医院看病,需要每次都说清楚前因后果(或者医生查询病例),医生不会每次记着你的情况。
怎么实现会话呢?
每次访问大模型的时候需要将前面沟通的信息全部放在提示词内。这样医生一看就知道你们聊到哪了。
而“前面沟通的信息”成为上下文,所以不是上下文越多越好,长上下文特别消耗Token
如果上下文是一个文档,难道把文档直接给大模型LLM吗?
从实现上说:可以,但太消耗Token
应该怎么搞:将文档切片,向量化,每次查询文档相关的内容为向量集合,给大模型输入这个集合。这种方法就是RAG,Retrieval-Augmented Generation,检索增强生成。
如果每次处理文档比较慢,可以提前向量化后存储到向量数据库中,每次使用的时候使用。
向量数据库有内存向量数据库; 外置向量数据库。
多模态
如果你的大模型可以处理文字,图片,音频,视频等多中类型的信息,那么就称为大模型支持多模态。
大模型在哪里
常见大模型
下面我把常见的一些大模型对话产品及其模型的关系给大家罗列一下:
|
大模型 |
对话产品 |
公司 |
地址 |
|---|---|---|---|
|
GPT-3.5、GPT-4o |
ChatGPT |
OpenAI |
|
|
Claude 3.5 |
Claude AI |
Anthropic |
|
|
DeepSeek-R1 |
DeepSeek |
深度求索 |
|
|
文心大模型3.5 |
文心一言 |
百度 |
|
|
星火3.5 |
讯飞星火 |
科大讯飞 |
|
|
Qwen-Max |
通义千问 |
阿里巴巴 |
|
|
Moonshoot |
Kimi |
月之暗面 |
|
|
Yi-Large |
零一万物 |
零一万物 |
私有化部署
Ollama:本地化部署,是一个模型管理工具,有点像Docker,而且命令也很像。
当然你可以直接使用代码部署。
大模型应用场景
Agent
工作流
大模型对外接口调用:Function Calling;MCP
工作流WorkFlow

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)