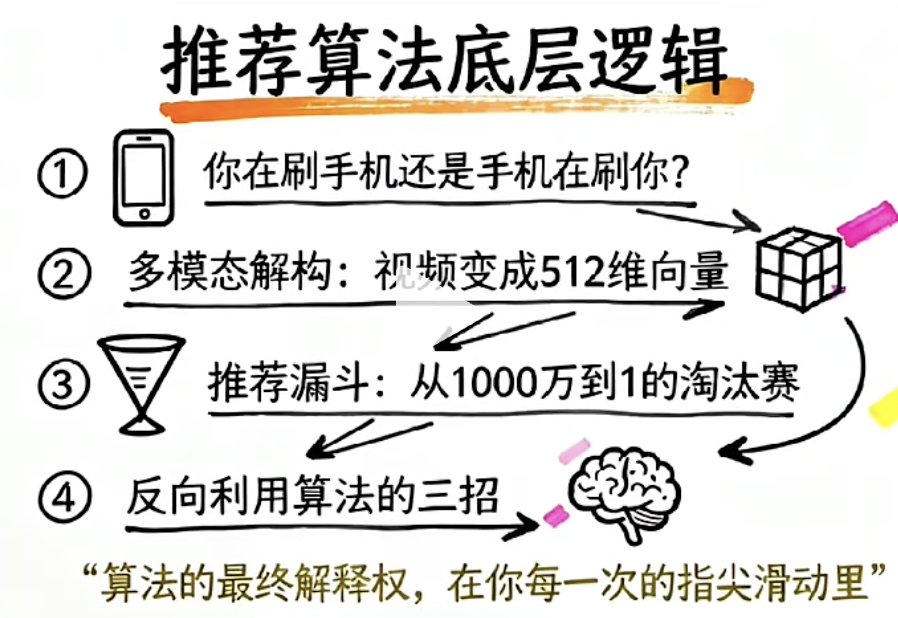
抖音推荐算法深度解析:当你刷抖音时,抖音在“刷“什么?
📱 我们在刷手机,手机也在"刷"我们。
每天,数千万用户上传海量视频到抖音,面对如此庞大的内容池,抖音如何做到"千人千面"——让每个人刷到的内容都精准命中自己的兴趣?答案藏在一条精密的算法流水线中。本文将从👤 用户画像、🧩 多模态解构和🔽 推荐漏斗三个层面,带你理解抖音推荐系统背后的技术逻辑。
一、👤 用户画像:用向量"刻画"一个人
推荐系统的第一步,是理解"你是谁"。
抖音为每个用户构建了一套用户画像,它不是一个简单的标签列表,而是一个高维数学对象——📐 向量(Vector)。每个用户被表示为一个 512 维的浮点数数组,每一维代表一个兴趣方向的强度:
[
0.85, // 💻 科技
0.05, // 😂 幽默
0.03, // 🇬🇧 英语
// ... 共 512 个维度
]
🤔 这个向量是怎么来的?它来自你的每一次行为:你在哪个视频上多停留了 1 秒、你点赞了什么、你评论了什么、你快速划走了什么。每一条行为数据都在悄悄地更新这个向量,让你越来越"被算法看透"。
同理,每一个视频也被表示为一个 512 维向量。当你刷抖音时,本质上就是你的用户向量与海量视频向量在做📏 相似度运算——最经典的方式是余弦相似度(Cosine Similarity),即计算两个向量夹角的余弦值,值越接近 1,代表你和这个视频越"投缘"。
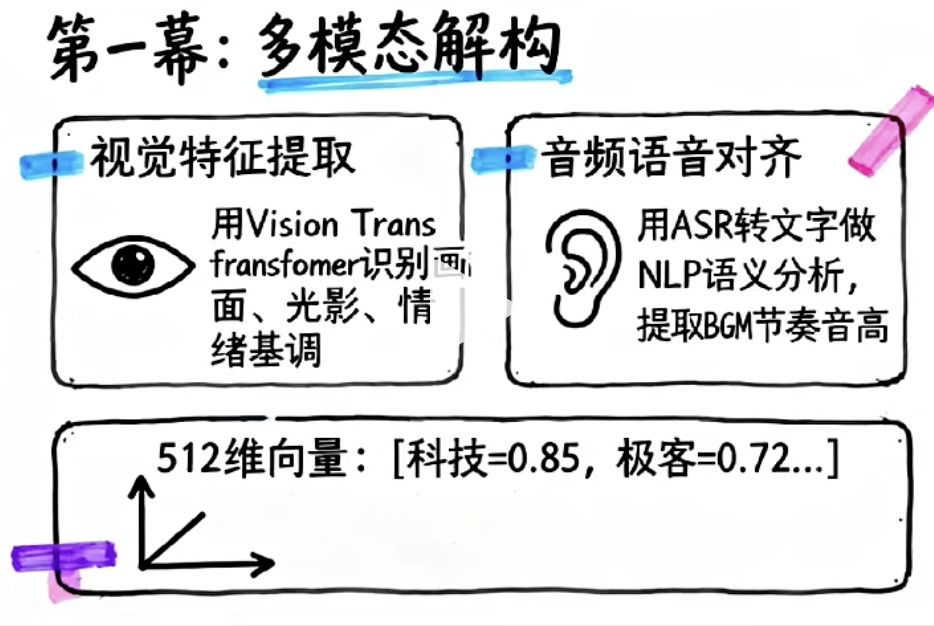
二、🧩 第一步:多模态解构——让机器"看懂"视频
要让机器判断一个视频是否适合你,首先得让机器"理解"视频的内容。抖音采用多模态(Multi-modal)技术,同时从四个维度解构一段视频,最终将其融合为一个 512 维向量。
💡 多模态是当前大语言模型(LLM)的主要发展方向,抖音正是这一技术在大规模工业场景中的典型应用。
2.1 👁️ 视觉特征:逐帧"看"画面
抖音使用 Vision Transformer(ViT) 作为底层模型,对视频逐帧提取视觉特征,生成张量(Tensor)表示。它能识别出:
- 🐱 这是一只猫;
- 👨💻 这是一个程序员在写代码;
- ⚽ 这是一群室友围着看世界杯。
更进一步,它还能通过画面的色彩分布、光影对比,判断视频的情绪基调——是 🌸 温暖治愈的暖色调,还是 ⚙️ 冷酷硬核的暗色系。视觉特征是抖音数据量最大的处理环节,背后依赖海量的机器学习训练和大数据计算。
2.2 🎵 音频特征:听懂声音里的"情绪"
音频维度的处理包含几个层次:
- 🗣️ ASR(自动语音识别):将语音转换为文本,再通过 NLP(自然语言处理) 做语义分析,理解"说了什么"。
- 📊 声学特征分析:提取声音的音量、语速、音调、情绪等特征——同样是说话,激昂的演讲和轻柔的独白,传达的信息完全不同。
- 🎶 音乐识别:依托字节跳动收购的 Musical.ly 积累的音乐训练数据,识别背景音乐的曲风、节奏、流行度。
2.3 📝 文本特征:理解"写了什么"
视频的标题、字幕、评论区热词等文本信息,通过 NLP 技术被转换为向量表示。语义分析模型从中提取话题关键词、情感倾向、信息密度等特征。
2.4 🖼️ 图片特征:封面和关键帧
视频封面和关键帧图片同样经过图像识别模型处理,提取内容标签和美学特征,作为向量中的补充维度。
🔗 最终输出
以上四个模态的特征被融合,最终形成一个统一的 512 维向量——这就是机器对这个视频的"全部理解",也是下一步推荐漏斗的输入。
三、🔽 第二步:推荐漏斗——从 1000 万到 10 条的四层筛选
有了用户向量和视频向量,接下来就是从千万级候选池中筛选出你屏幕上那短短几十条视频的过程。抖音采用经典的漏斗架构,逐层收窄,兼顾效率与精度。
📦 1000 万条视频
↓ 🔍 召回(Recall)
📋 1000 条
↓ ⚡ 粗排(Pre-Ranking)
📋 300 条
↓ 🎯 精排(Ranking)
分数排序
↓ 🔀 重排(Re-Ranking)
✨ 最终 10~20 条
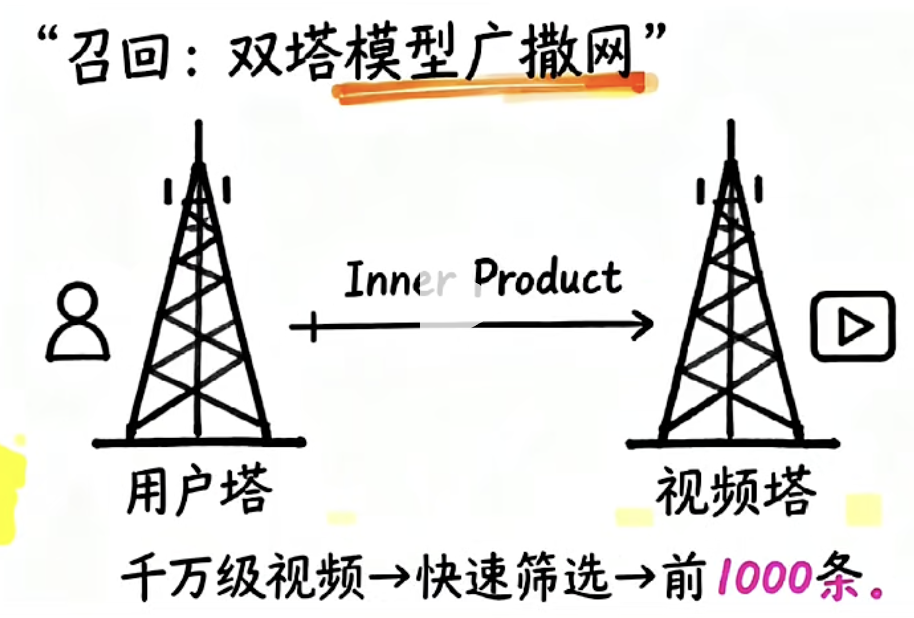
3.1 🏗️ 双塔模型与召回
漏斗的第一层叫召回(Recall),目标是从千万级候选池快速筛选出约 1000 条候选视频。这里使用经典的双塔模型(Two-Tower Model):
- 👤 User Tower(用户塔):将用户画像编码为向量。
- 🎬 Item Tower(物品塔):将视频特征编码为向量。
召回阶段的核心操作是向量点积运算和余弦相似度计算——在巨大的向量空间中,找到与用户向量最"近"的那些视频向量。这一步要求极致的速度,通常借助向量检索引擎(如 Faiss 🚀)来实现毫秒级响应。
3.2 ⚡ 粗排:轻量模型的快速过滤
经过召回得到 1000 条候选后,进入粗排(Pre-Ranking)阶段。这里使用相对轻量的机器学习模型,计算一些粗粒度的内部特征,将候选集从 1000 条缩减到约 300 条。
💰 粗排的意义在于性价比——精排模型虽然精准,但计算成本高昂,不能对 1000 条视频都跑一遍。粗排用"小模型"先做一轮快速筛选,把明显不合适的淘汰掉。
3.3 🎯 精排:多目标优化模型
精排是漏斗中最"聪明"的一环。它对粗排输出的 300 条候选视频,逐一预测用户的多项行为概率:
- 👆 点击率(CTR):你会不会点进去?
- ✅ 完播率:你会不会把视频看完?
- ❤️ 点赞概率
- 💬 评论概率
- 🔗 分享概率
最终,每个视频得到一个综合分数:
Score = w₁ × 点击率 + w₂ × 完播率 + w₃ × 点赞率 + w₄ × 评论率 + w₅ × 分享率
各权重通过海量用户行为数据训练得到,目标是最大化用户停留时长和互动深度。
3.4 🔀 重排:打破信息茧房的艺术
如果算法只按分数排序,你可能会连续刷到 10 条同类型的 AI 视频——这虽然精准,却容易让人产生审美疲劳 😴。重排(Re-Ranking)机制就是为了解决这个问题:
- 🃏 打散策略:每两个硬核内容之间,强制插入一条不同类型的视频(比如一段舞蹈 💃),打破内容同质化。
- 🧭 探索与利用(Explore & Exploit):80% 的内容来自你已知的兴趣(利用 🎯),20% 的内容用于探索潜在的新兴趣(探索 🔭)。如果你在一条野外求生 🏕️ 视频上多停留了 1 秒——一个全新的兴趣标签就被悄悄记录了下来。
这种机制保证了推荐既精准又不"窄",让你在舒适区和新鲜感之间保持平衡。
四、📌 总结
抖音推荐算法的本质,可以浓缩为三句话:
- 🧮 一切皆向量:无论是用户还是视频,最终都被抽象成高维空间中的一个点。
- 🔗 相似即推荐:你喜欢什么,就给你推什么——通过向量之间的余弦相似度来度量"喜欢"。
- ⚖️ 探索与利用并重:既满足已知偏好,也留出 20% 的空间探索未知——在让你上瘾的同时,不断拓展你的兴趣边界。
这一切的背后,是 🖥️ 巨量的算力支撑、🤖 大规模机器学习训练和 🧠 多模态 AI 模型在工业级的落地实践。你每划走一条视频、每多停留的 1 秒,都在为这个庞大系统提供新的训练数据——📱 你在刷抖音,抖音也在"算"你。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)