InfiniteTalk 数字人生成框架 部署与使用完整技术教程
一、项目概述
InfiniteTalk 是由美团基础研发平台视觉智能团队开源的音频驱动数字人视频生成框架,项目代码托管于 GitHub,模型权重发布在 Hugging Face,整体遵循 Apache 2.0 开源协议,允许商用。
该工具核心作用为:基于静态图片或已有视频,搭配音频素材生成数字人动态视频。区别于传统仅实现嘴部动作的数字人方案,本框架可同步驱动面部表情、头部、肢体等多维度动作,人物动态更贴合真人表现。同时支持超长时长视频生成、多人同画面驱动等能力,目前提供 ComfyUI、WebUI 两种运行版本,适配不同使用人群。
二、核心功能介绍
-
无限时长视频生成 采用分段处理技术,突破常规 AI 视频模型的时长限制,可稳定生成一小时以上连续视频,全程保证人物形象、动作不出现崩坏。
-
双输入模式
- 图片 + 音频:以静态人像图为基础,结合音频生成说话、演唱类视频,适用于虚拟主播、口播内容制作;
- 视频 + 音频:为已有视频替换配音,常用于视频翻译、音频二次修改场景。
-
全维度动作同步 可同步驱动嘴唇动作、面部表情、头部转动、身体姿态,解决传统数字人动作僵硬、姿态固定的问题。
-
多人画面支持 单条视频内可同时识别多张人脸,并绑定独立音轨,适配多人对话、访谈类视频制作场景。
-
多客户端适配 同步提供 ComfyUI 节点版与 WebUI 简易版,WebUI 无需掌握节点操作,零基础用户也可快速上手。
-
音频兼容 除人声对话外,框架可正常解析歌曲音频,实现数字人唱歌效果。

三、版本核心更新说明
本次迭代在画面稳定性、生成速度、硬件适配三方面完成优化,主要更新内容如下:
3.1 长视频画面优化
引入软条件控制机制,系统会根据视频帧之间的相似度、上下文内容动态调整控制强度,有效解决长视频运行过程中画面变形、帧跳变、内容崩坏的问题。 针对多人场景新增标签旋转位置嵌入(L-RoPE) 技术,依托自注意力机制,将音轨与对应人脸精准绑定,避免人物与音频错位。
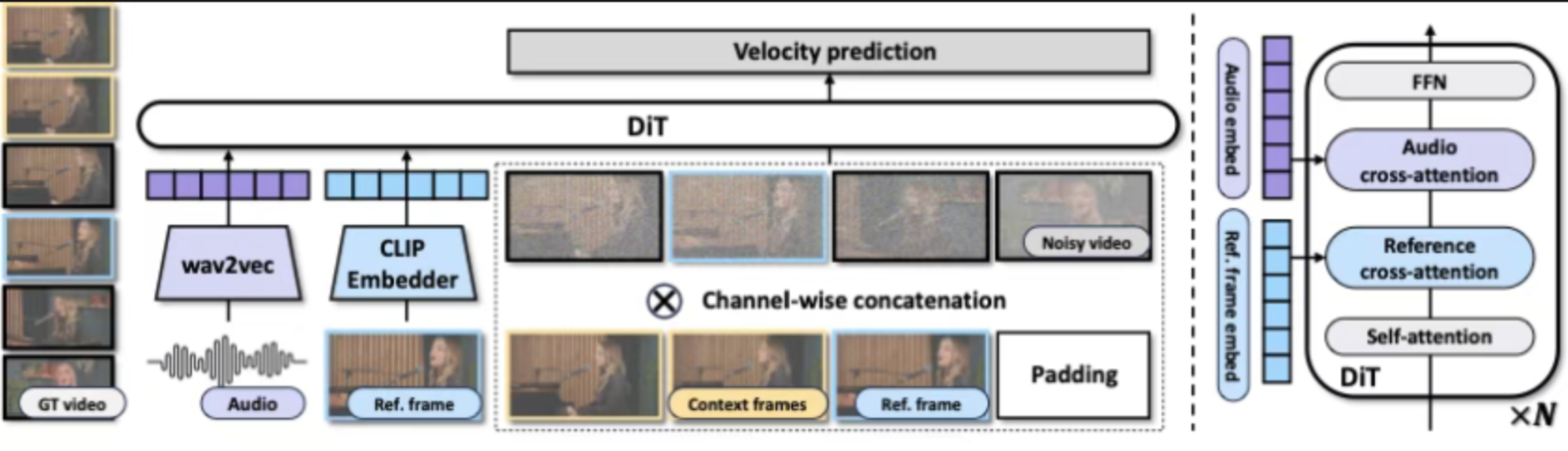
3.2 生成效率提升
- FusionX LoRA 加速 采样步数可从原有 30~40 步压缩至 4~8 步,整体生成速度接近翻倍;该方案在短视频场景表现优异,时长超过 1 分钟的视频可能出现轻微色偏。
- GGUF 量化支持 推出低精度量化模型,大幅降低显存占用,普通 8GB 显存显卡可正常运行,画质损失处于可接受范围。
- 批量任务队列 支持批量添加生成任务,程序自动按顺序执行,无需手动逐个启动,提升批量内容生产效率。
3.3 8GB 显存设备参数参考
针对低显存设备,推荐配置如下:
表格
| 参数项 | 推荐配置值 |
|---|---|
| 输出分辨率 | 优先 360p,可选 480p |
| 标准采样步数 | 30 ~ 40 |
| LoRA 加速采样步数 | 4 ~ 8 |
| 模型版本 | Q4 量化版(显存占用最低) |
| 音频 CFG 参数 | 3 ~ 5(保证口型匹配精度) |
四、硬件环境要求
4.1 基础硬性要求
- 显卡:仅限 NVIDIA 显卡,需支持 CUDA,推荐 CUDA 版本 ≥ 12.8;
- 显存:最低 8GB;
- 系统内存:建议 32GB 及以上;
- 磁盘空间:模型体积较大,建议预留 40GB 以上可用空间。
4.2 硬件档位划分
表格
| 硬件档位 | 显卡型号 | 显存 | 适配分辨率 |
|---|---|---|---|
| 入门可用 | RTX 3060 / RTX 4060 | 8GB | 360p / 480p |
| 标准推荐 | RTX 3080 / RTX 407 | 12GB+ | 480p / 720p |
| 专业高配 | RTX 4090 / A100 | 24GB+ | 720p,支持超长视频 |
补充说明
- AMD 显卡官方未做专项适配,社区可用案例较少,不建议入门用户使用;
- 苹果 M 系列芯片可基于 CoreML 运行,但生成速度远低于 NVIDIA 显卡;
- 实测参考:RTX 3060 标准模式下,生成 10 秒视频约耗时 40~60 秒,开启量化与 LoRA 后速度可进一步提升。
五、同类工具横向对比
| 对比项 | InfiniteTalk | MultiTalk | SadTalker | HeyGen |
|---|---|---|---|---|
| 开源状态 | 开源免费(Apache 2.0) | 开源免费(Apache 2.0) | 开源免费(CC-BY) | 闭源订阅收费 |
| 视频时长限制 | 无限制 | 约 15 秒 | 存在限制 | 存在限制 |
| 口型同步精度 | 高 | 高 | 中等 | 高 |
| 头部 / 肢体动作 | 完整支持 | 部分支持 | 仅基础头部动作 | 完整支持 |
| 多人画面 | 支持 | 支持 | 不支持 | 部分支持 |
| 8GB 显存适配 | 支持(量化版) | 适配有限 | 支持 | 云端运行,无需本地显卡 |
| 商用权限 | 允许商用 | 允许商用 | 有限商用 | 需单独购买授权 |
| 安装难度 | 中等 | 中等 | 低 | 零门槛(在线使用) |
工具区分说明
- MultiTalk:同团队产品,主打短视频、多人对话场景,资源占用低、速度快,偏向 “短距离竞速”;
- InfiniteTalk:基于 MultiTalk 迭代优化,侧重长视频稳定性与全维度动作同步,偏向 “长距离运行”;
- SadTalker:早期经典方案,上手简单,但动作类型单一,长视频表现较差;
- HeyGen:云端商业服务,无需本地硬件,按使用时长 / 次数计费,长期使用成本较高。
六、完整部署教程
提供三种部署方式,可根据自身技术基础选择。
6.1 方式一:社区整合包(新手推荐)
- 下载地址:夸克网盘分享
- 将压缩包解压至纯英文路径,目录禁止包含中文、空格、特殊字符;
- 把整合包内的模型文件夹移入主程序对应目录;
- 双击启动脚本运行程序;
- 程序启动后,浏览器自动访问
http://127.0.0.1:8188进入 ComfyUI 界面; - 左侧选择单人、多人、视频驱动等对应工作流,上传图片 / 视频与音频文件,调整参数后点击运行即可。
补充:WebUI 版本操作更简易,无需节点配置,上传素材直接生成,适合零基础用户。
6.2 方式二:GitHub 源码部署(适合有 Python 基础用户)
- 克隆项目代码
bash
运行
git clone https://github.com/MeiGen-AI/InfiniteTalk
cd InfiniteTalk
- 创建并激活 Python 虚拟环境(推荐 Python 3.10)
bash
运行
conda create -n infinitetalk python=3.10
conda activate infinitetalk
- 安装项目依赖
bash
运行
pip install -r requirements.txt
- 下载模型权重(需提前安装
huggingface_hub)
bash
运行
huggingface-cli download Wan-AI/Wan2.1-I2V-14B --local-dir ./weights/Wan2.1-I2V-14B-480P
huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base
huggingface-cli download MeiGen-AI/InfiniteTalk --local-dir ./weights/InfiniteTalk
- 启动项目,等待环境加载完成后即可使用。
提示:模型文件体积庞大,网络不稳定时可使用断点续传。
6.3 方式三:云端体验(无适配本地硬件临时使用)
目前已有第三方平台部署该项目,可直接通过浏览器访问云端服务,上传素材完成测试。该方式仅适合临时体验,不建议用于批量生产。
七、常见问题与解决方案
-
程序运行报错 原因:文件路径包含中文 / 特殊字符。 解决:重新解压至纯英文目录,全程保证素材、模型、输出路径无中文。
-
驱动 / CUDA 版本报错 原因:NVIDIA 驱动版本过低,CUDA 未达到 12.8 要求。 解决:前往官网升级显卡驱动,适配对应 CUDA 版本。
-
显存不足、程序中断 解决:切换至 Q4 量化模型;调低输出分辨率至 360p;关闭批量任务,单次仅运行一个任务。
-
开启 LoRA 后视频出现色偏 原因:FusionX LoRA 加速方案对长视频存在兼容性问题。 解决:视频时长超过 1 分钟时,关闭 LoRA 加速,使用标准采样模式。
八、应用场景说明
- 数字人口播:知识、教育类账号制作虚拟出镜视频,批量生成内容,保护个人隐私;
- 视频本地化配音:为外文视频替换中文配音,实现口型与音频同步;
- 直播素材制作:生成数字人循环视频,用于直播间背景播放,搭配 TTS 工具可实现全流程自动化;
- 技术接单:依托工具制作短视频、口播类数字人视频,提供相关制作服务。
九、项目地址
- GitHub 源码地址:https://github.com/MeiGen-AI/InfiniteTalk
- 模型权重地址:https://huggingface.co/MeiGen-AI
- 开源协议:Apache 2.0(支持个人及商业用途)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)