大模型的“瘦身”秘籍:一文读懂量化技术
大模型的“瘦身”秘籍:一文读懂量化技术
什么是量化?
望文生义,我的朴素的理解是:粗略的记录,直接上例子:
一个整数:1234,量化一下,1000
看看差异:1234你需要记住4个字符,但是1000可以只记录2个:1、千
区别是什么?精度下降:
来做一道数学题:1234+1
不量化的答案是:1235,量化的答案是:1千
是不是错了?是的,但是他要是做这题呢:1234+1000
不量化答案是2234,量化的答案是2千
是不是错了?还是,有什么区别呢?没彻底错,千位数字还是对的,勉强可以说是近似!
这就是量化的目的:用可接受的精度损失,来降低资源的要求
理论的概念总结
量化是指减少表示模型参数所需比特数的过程
更详细点:就是将模型中那些高精度的浮点数(如32位浮点数FP32),转换为低精度的整数(如8位整数INT8,甚至4位整数INT4)
量化需要考虑的地方
-
量化目标 —— 权重、激活值
-
数据类型 —— 浮点数(FP32)、FP16、块浮点 FP16、INT8、INT4、MXFP4
-
量化时机 —— 训练后量化(PTQ)、量化感知训练(QAT)
-
工具 —— Quark、Olive、ONNX、Brevitas
量化的核心原理:缩放因子与零点
第一次读到理论概念,和我淳朴的想法还是有点不一样的,我的理解是1234量化成1000,毕竟还是近似的,但是概念是FP32量化未int8甚至是int4,这这么可能?一个12345678.123456怎么表示成1000?
这个就有点想当然了,是一个错误的理解,大模型用到的数据,从来不是绝对数据,而是相对值,表示的是关系:
期中考试,班级数学最高分100分,最低分10分,这是百分制,但是也可以精简成10分值的:10分和1分,还可以进一步精简为4分值:优、差(良、中)
所以,准确的来说,量化是数据范围到数据范围的映射,朴素的来理解,就是将班级考试百分制改成10分值
-
确定范围:首先,我们要找到模型参数(比如权重)的最小值和最大值。
-
计算缩放因子(Scale):这个因子就像一把“比例尺”。它决定了高精度的数值范围,如何映射到低精度的整数范围。
-
例如,一个参数范围是[-3.5, 4.2],我们要把它映射到8位整数的范围[-128, 127]。
-
缩放因子
scale = (4.2 - (-3.5)) / (127 - (-128)) ≈ 0.058。
-
-
计算零点(Zero Point):这是为了让“0”这个关键数值能精确地对应到整数“0”,避免因偏移导致的误差。
zero_point = round(-(-3.5) / 0.058) ≈ 60。
-
量化与反量化:
-
量化:将原始浮点数
x转换为整数q:q = round(x / scale + zero_point)。 -
反量化:在推理时,再将整数
q还原为近似的浮点数x':x' = (q - zero_point) * scale
-
通过这套“缩放+偏移”的机制,量化模型在存储和计算时使用低精度数据,但在推理时能精准还原,实现了效率与精度的完美平衡。
量化的优势
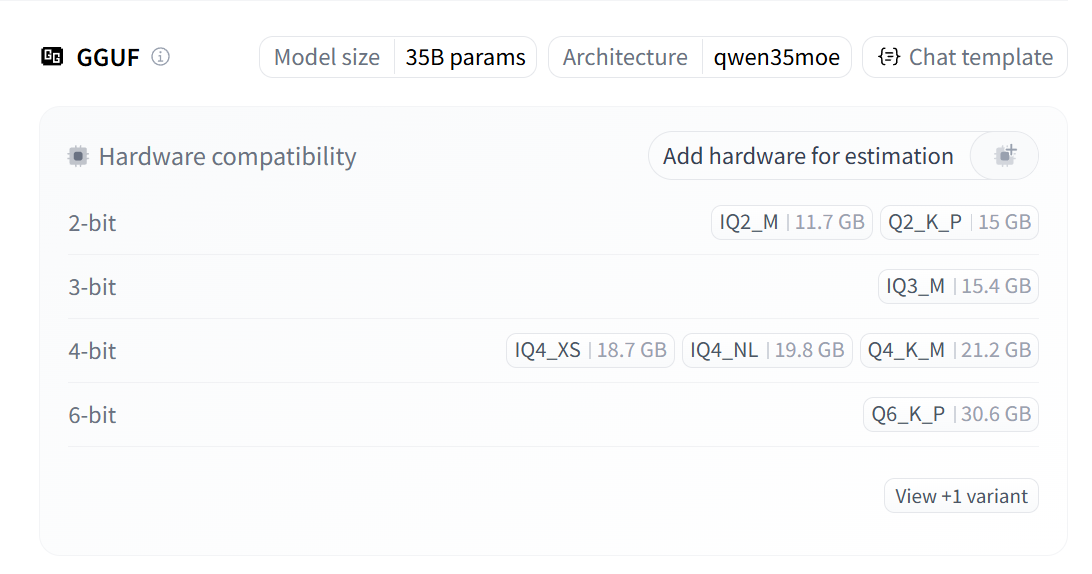
资源占用大幅度减少,内存和cpu,毕竟存储1000和存储1、计算1234x5678和计算1x5是完全不同的算力需求,直观的看一下抱脸上qwen3-35b-a3b的量化后的大小吧:
小结
突飞猛进的跟着大模型的学习,终于有空静下来思考一下:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)