Northeastern:揭示VLM空间数字理解的缺陷
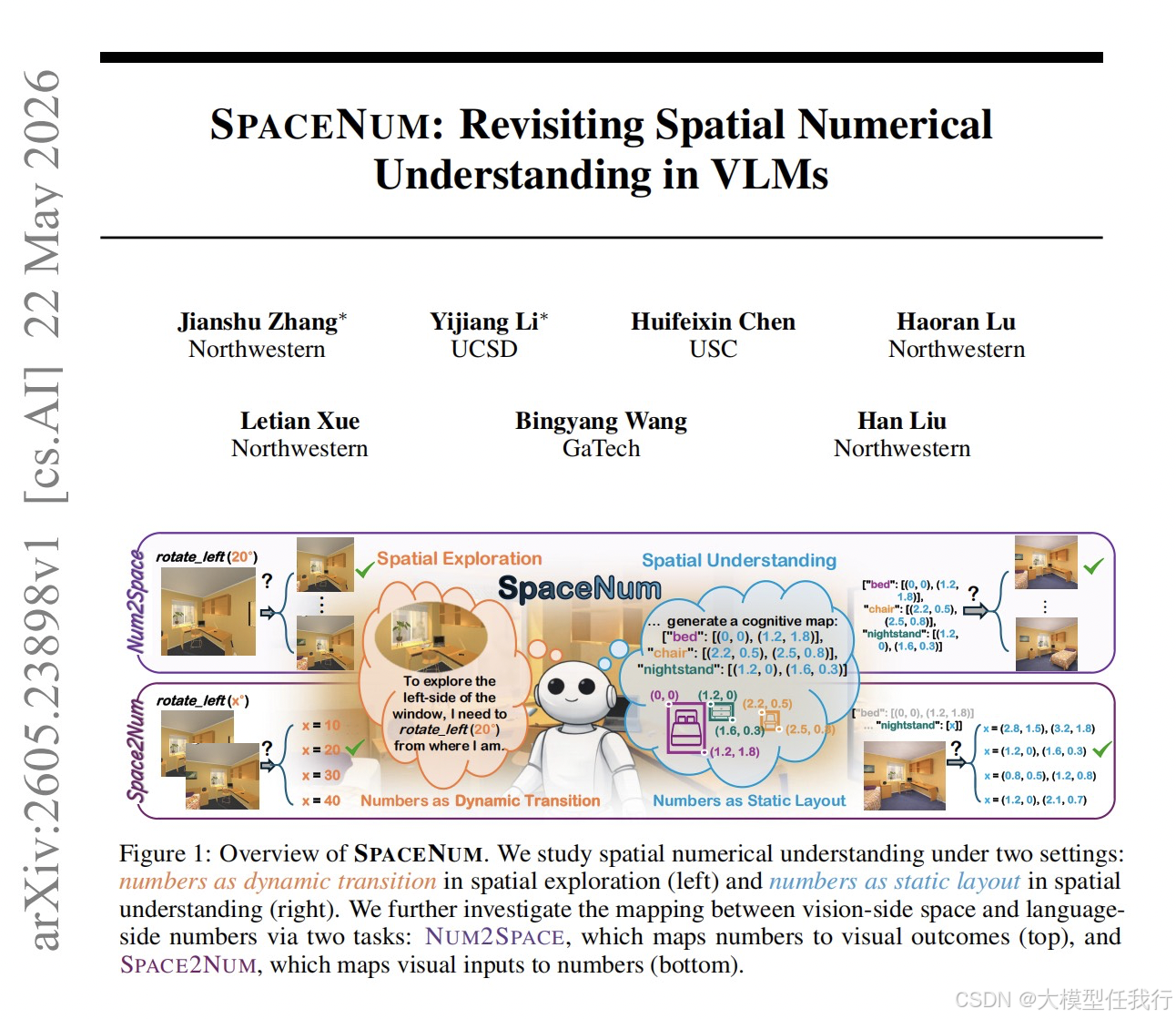
📖标题:SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
🌐来源:arXiv, 2605.23898v1
🛎️文章简介
🔸研究问题:视觉语言模型是否真正理解数字在空间中的含义,还是仅仅生成看似合理但缺乏空间根基的数值输出?
🔸主要贡献:论文提出SPACENUM统一评估框架,通过NUM2SPACE和SPACE2NUM双向任务系统评估18个VLM在动态空间转移和静态空间布局中的空间数字理解能力,揭示当前模型严重缺乏真正的空间数值根基。
📝重点思路
🔸提出两种空间数字场景:将数字定义为动态转移量(如机器人旋转20度)和静态布局坐标(如认知地图中物体的位置坐标),覆盖空间探索和空间理解两类核心任务。
🔸设计NUM2SPACE和SPACE2NUM双向任务:前者给定数字判断对应的视觉结果,后者给定视觉场景推断对应数值,从两个方向全面评估数字与空间的映射能力。
🔸基于AI2-THOR和NVIDIA Isaac Sim构建可控数据集,涵盖移动、旋转等参数化动作以及1D/2D/3D多种坐标表示,共3800个评估样本和77000余个训练样本。
🔸通过结构化错误分析、推理轨迹分析和可控干预实验,深入剖析模型失败的根源。
🔎分析总结
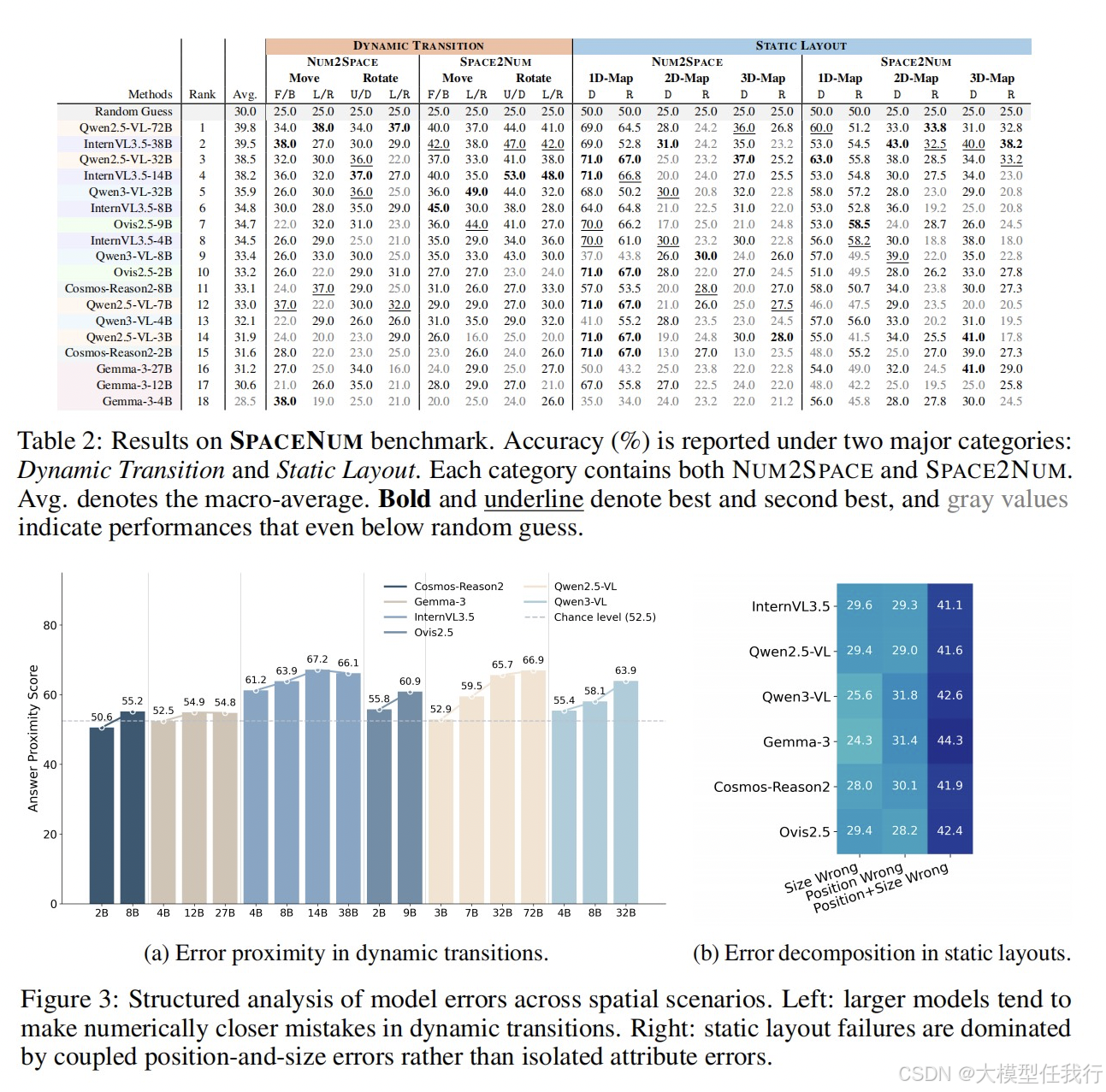
🔸18个VLM在SPACENUM上普遍接近随机猜测水平,最佳模型平均准确率仅约39.8%,远未实现真正的空间数字根基。
🔸大模型虽然精确匹配能力有限,但错误更接近正确答案,说明规模提升带来了粗粒度的空间敏感性。
🔸静态布局的失败以位置与尺寸耦合错误为主,表明模型依赖粗粒度整体匹配而非解耦的空间推理。
🔸启用显式推理仅带来不到1%的提升,模型倾向于在粗浅空间线索处停止推理,缺乏反事实比较和坐标系对齐能力。
🔸SPACE2NUM普遍优于NUM2SPACE,且模型在旋转等价变换下表现不一致,说明空间映射缺乏几何一致性。
🔸将布局图像替换为结构化抽象(点、2D/3D框)可大幅提升SPACE2NUM性能,表明核心瓶颈在于从原始图像到结构化空间表征的抽象能力。
🔸微调可部分提升空间数字理解能力,且能迁移至外部空间推理基准,最优数据配比为转移数据25%加布局数据75%。
💡个人观点
本文的创新点在于首次将"数字"作为核心研究对象审视VLM的空间理解能力,而非将数字视为辅助标签。通过双向任务和多种控制实验,系统揭示了模型"会输出数字但不理解数字"这一根本缺陷,为具身智能中数值输出的可靠性研究提供了重要的评估范式和分析框架。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)