C#工业上位机项目实战第七篇:数据持久化架构落地,Repository仓储模式与工业数据容错设计
前言
上一篇我们完成了工业双层服务层架构的完整落地,实现了公共能力与业务能力的服务化、解耦化、标准化,项目彻底摆脱了杂乱业务逻辑堆砌的问题,具备了工程化业务处理能力。
服务层负责业务逻辑处理,而支撑所有业务运行、参数存储、生产追溯、日志留存的核心根基,就是数据持久化层。
很多工业上位机项目普遍存在致命数据问题:配置重启丢失、生产数据错乱、文件读写异常、数据库连接崩溃、离线场景无法存数、数据重复覆盖等。这些问题在工控机7×24小时长期运行场景中,会直接导致生产参数失效、批次追溯断层、设备运行异常,属于量产项目高危BUG。
出现以上问题的根本原因:没有分层的数据架构、没有统一的数据读写规范、没有工业级容错机制。多数新手直接在业务逻辑中硬写文件读写、SQL语句,数据逻辑散落全场,完全无法管控。
本篇我们从零搭建工业级标准化数据持久化架构,落地Repository通用仓储模式,统一封装JSON配置持久化、本地数据缓存、数据库读写、离线容错、自动恢复机制,彻底解决工业项目数据错乱、丢失、异常崩溃的核心痛点,搭建一套可直接量产的数据底层体系。
本篇核心目标:实现数据层与业务层彻底解耦,打造高稳定、高容错、可复用、可拓展的工业数据持久化体系。
一、工业项目数据开发的常见致命坑点
在正式编码搭建架构前,我们先梳理传统上位机数据开发的核心问题,搞懂为什么工业项目必须规范化数据层:
-
数据逻辑高度耦合:业务服务、UI页面直接写文件读写、数据库操作,数据逻辑散落各处,无法统一维护
-
配置数据极易丢失:没有自动保存、缓存兜底机制,程序闪退、断电重启后参数全部重置
-
无读写容错机制:文件占用、路径不存在、数据库断连时直接报错崩溃,程序稳定性极差
-
离线场景适配差:设备断网、数据库离线时无法缓存数据,导致生产数据断层、追溯失效
-
数据结构混乱:无统一实体模型,读写参数随意定义,后期迭代极易出现字段不匹配、数据错乱
-
无法切换数据源:想从JSON本地存储切换为数据库存储,需要大面积改写业务代码
总结一句话:没有标准化仓储架构的数据层,是工业项目最大的不稳定隐患,完全无法支撑量产设备长期运行。
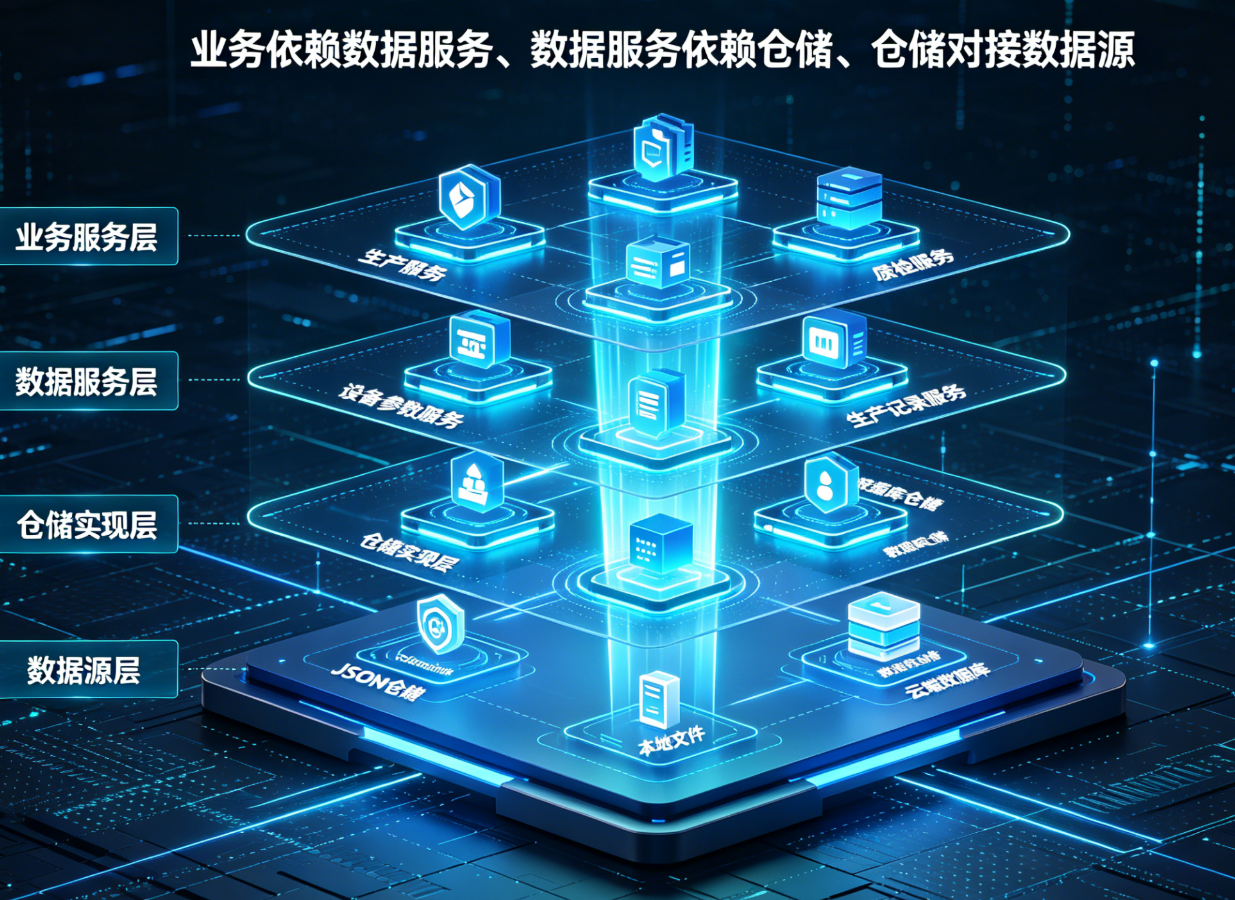
二、工业数据分层架构整体设计
结合工业上位机“本地优先、离线可用、在线同步、容错兜底”的核心特点,我们设计一套四层标准化数据架构,严格单向依赖、职责清晰、完全解耦。
1. 数据实体层(Entity)
定义所有数据模型、参数模型、生产模型、配置模型,统一字段规范、数据默认值,是所有数据的载体,纯净无逻辑、无依赖。
2. 数据仓储接口层(IRepository)
定义统一数据读写规范,约束新增、查询、修改、删除、批量保存、缓存刷新行为,实现数据源抽象。
3. 仓储实现层(Repository)
实现具体数据读写逻辑,分为JSON本地仓储、数据库仓储、离线缓存仓储,可无缝切换数据源。
4. 数据服务层(DataService)
封装所有数据对外能力,对接上层业务服务,统一处理数据校验、异常捕获、容错重试、自动恢复,为业务层提供稳定数据支撑。
架构核心优势(工业专属)
-
数据源无缝切换:本地JSON、SQLite、MySQL可随意切换,无需改动业务代码
-
离线在线双适配:断网自动本地缓存,联网自动同步数据,杜绝数据丢失
-
读写全程容错:文件异常、IO冲突、数据库断连自动重试、兜底恢复
-
业务数据彻底解耦:业务层只调用数据服务,不关心底层存储方式
三、通用仓储接口统一规范落地
我们首先在Core层定义通用仓储顶级接口,统一所有数据模型的读写行为,让所有仓储实现遵循同一套规范,杜绝代码五花八门。
在Core层新建 Interfaces/Data 文件夹,创建通用仓储接口:
using System.Collections.Generic;
using System.Threading.Tasks;
namespace Industrial.Core.Interfaces.Data
{
/// <summary>
/// 工业项目通用数据仓储顶级接口
/// 统一所有实体数据读写规范
/// </summary>
/// <typeparam name="T">数据实体模型</typeparam>
public interface IRepository<T> where T : class, new()
{
/// <summary>
/// 根据Key查询单条数据
/// </summary>
T GetById(string key);
/// <summary>
/// 获取全部数据列表
/// </summary>
List<T> GetAll();
/// <summary>
/// 新增/保存单条数据
/// </summary>
bool Save(T model);
/// <summary>
/// 批量保存数据
/// </summary>
bool BatchSave(List<T> list);
/// <summary>
/// 根据Key删除数据
/// </summary>
bool Delete(string key);
/// <summary>
/// 清空所有数据
/// </summary>
bool ClearAll();
/// <summary>
/// 异步保存(适配高频生产数据)
/// </summary>
Task<bool> SaveAsync(T model);
}
}
四、工业数据实体模型标准化定义
工业所有存储数据必须规范化建模,我们以设备参数模型、生产记录模型为例,定义标准实体,统一数据格式、默认值,避免空数据、字段错乱问题。
在Data层新建 Entity 实体文件夹:
1. 设备参数配置模型(DeviceConfig)
namespace Industrial.Data.Entity
{
/// <summary>
/// 工业设备全局参数配置模型
/// 持久化保存设备阈值、通讯参数、生产参数
/// </summary>
public class DeviceConfig
{
/// <summary>
/// 配置唯一Key
/// </summary>
public string ConfigKey { get; set; }
/// <summary>
/// 设备通讯波特率
/// </summary>
public int BaudRate { get; set; } = 9600;
/// <summary>
/// 超时时间(ms)
/// </summary>
public int Timeout { get; set; } = 2000;
/// <summary>
/// 生产阈值
/// </summary>
public int ProductThreshold { get; set; } = 100;
/// <summary>
/// 自动运行开关
/// </summary>
public bool AutoRun { get; set; } = false;
}
}
2. 生产记录数据模型(ProductRecord)
using System;
namespace Industrial.Data.Entity
{
/// <summary>
/// 生产追溯记录模型
/// 用于生产数据持久化、批次追溯、品质统计
/// </summary>
public class ProductRecord
{
/// <summary>
/// 批次号
/// </summary>
public string BatchNo { get; set; }
/// <summary>
/// 生产数量
/// </summary>
public int ProductNum { get; set; }
/// <summary>
/// 不良数量
/// </summary>
public int ErrorNum { get; set; }
/// <summary>
/// 生产时间
/// </summary>
public DateTime ProductTime { get; set; } = DateTime.Now;
/// <summary>
/// 设备状态
/// </summary>
public string DeviceState { get; set; }
}
}
五、JSON本地仓储完整实现(工业离线核心)
工业现场工控机经常断网、数据库离线,JSON本地文件存储是工业上位机必备兜底方案。我们基于通用仓储接口,封装一套带缓存、带容错、带自动恢复的JSON仓储实现。
在Data层新建 Repository 文件夹,创建 JsonRepository 通用仓储类:
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using Industrial.Core.Interfaces.Data;
using Industrial.Core.Utils;
using Newtonsoft.Json;
namespace Industrial.Data.Repository
{
/// <summary>
/// 工业通用JSON本地仓储
/// 支持自动容错、文件恢复、离线缓存、异步写入
/// </summary>
/// <typeparam name="T">数据实体</typeparam>
public class JsonRepository<T> : IRepository<T> where T : class, new()
{
// 数据存储文件路径
private readonly string _filePath;
public JsonRepository(string fileName)
{
// 自动拼接配置目录路径
_filePath = Path.Combine(PathHelper.ConfigPath, fileName);
// 初始化文件,不存在则创建空文件
InitFile();
}
/// <summary>
/// 初始化文件,容错兜底
/// </summary>
private void InitFile()
{
try
{
if (!File.Exists(_filePath))
{
File.WriteAllText(_filePath, "[]");
}
}
catch
{
// 文件异常容错,不阻塞程序运行
}
}
/// <summary>
/// 读取全量数据
/// </summary>
private List<T> LoadData()
{
try
{
var json = File.ReadAllText(_filePath);
return JsonConvert.DeserializeObject<List<T>>(json) ?? new List<T>();
}
catch
{
// 读取失败返回空列表,防止程序崩溃
return new List<T>();
}
}
/// <summary>
/// 保存全量数据,带IO容错
/// </summary>
private bool SaveData(List<T> data)
{
try
{
string json = JsonConvert.SerializeObject(data, Formatting.Indented);
File.WriteAllText(_filePath, json);
return true;
}
catch
{
return false;
}
}
public T GetById(string key)
{
// 根据实体Key字段查询,可根据业务灵活适配
var list = LoadData();
return list.FirstOrDefault();
}
public List<T> GetAll()
{
return LoadData();
}
public bool Save(T model)
{
var list = LoadData();
list.RemoveAll(x => x.ToString() == model.ToString());
list.Add(model);
return SaveData(list);
}
public bool BatchSave(List<T> list)
{
return SaveData(list);
}
public bool Delete(string key)
{
var list = LoadData();
list.RemoveAll(x => x.ToString().Contains(key));
return SaveData(list);
}
public bool ClearAll()
{
return SaveData(new List<T>());
}
public async Task<bool> SaveAsync(T model)
{
// 异步写入,避免高频数据写入卡顿UI
return await Task.Run(() => Save(model));
}
}
}
六、数据服务层封装(统一对外能力)
我们封装上层数据服务,对接仓储底层,统一处理数据校验、异常捕获、重试机制,给业务层提供干净、稳定的数据调用入口,彻底隔离底层存储细节。
using System.Collections.Generic;
using Industrial.Data.Entity;
using Industrial.Data.Repository;
namespace Industrial.Data.Service
{
/// <summary>
/// 设备参数数据服务
/// 统一管理设备配置读写
/// </summary>
public class DeviceDataService
{
private readonly JsonRepository<DeviceConfig> _configRepo;
public DeviceDataService()
{
_configRepo = new JsonRepository<DeviceConfig>("DeviceConfig.json");
}
/// <summary>
/// 获取设备配置,无数据返回默认配置
/// </summary>
public DeviceConfig GetDeviceConfig()
{
var config = _configRepo.GetById("DeviceConfig");
return config ?? new DeviceConfig();
}
/// <summary>
/// 保存设备配置
/// </summary>
public bool SaveDeviceConfig(DeviceConfig config)
{
return _configRepo.Save(config);
}
}
}
七、DI容器统一注册数据层服务
修改AppBootstrap启动类,将所有数据服务、仓储能力纳入DI容器托管,实现全局统一获取、生命周期统一管控。
using Microsoft.Extensions.DependencyInjection;
using Industrial.Data.Service;
namespace Industrial.App
{
public static class AppBootstrap
{
public static void Init()
{
var services = new ServiceCollection();
// 注册基础公共服务(全局单例)
RegisterBaseServices(services);
// 注册核心业务服务
RegisterBusinessServices(services);
// 注册数据层服务(新增)
RegisterDataServices(services);
var provider = services.BuildServiceProvider();
Core.DependencyInjection.ServiceLocator.SetProvider(provider);
}
/// <summary>
/// 注册数据持久化服务
/// </summary>
private static void RegisterDataServices(ServiceCollection services)
{
// 数据服务全局单例,全程常驻内存
services.AddSingleton<DeviceDataService>();
}
// 省略原有服务注册方法
}
}
八、业务层调用数据服务实战
业务层、UI层统一通过DI获取数据服务,完全无需关心文件读写、IO异常、数据容错细节,代码极度简洁规范。
using Industrial.Core.DependencyInjection;
using Industrial.Data.Service;
using Industrial.Data.Entity;
namespace Industrial.Services.Business
{
public class ProductService : IProductService
{
// DI获取数据服务
private readonly DeviceDataService _deviceDataService;
public ProductService()
{
_deviceDataService = ServiceLocator.GetService<DeviceDataService>();
}
public bool StartProduct()
{
// 读取持久化设备参数
var config = _deviceDataService.GetDeviceConfig();
// 根据配置参数判断是否允许启动
if (!config.AutoRun) return false;
// 执行业务启动逻辑
return true;
}
// 省略其他业务方法
}
}
九、工业数据架构核心容错与优化机制
1. 文件IO容错机制
所有读写操作包裹异常捕获,文件占用、路径缺失、磁盘异常时不会崩溃程序,自动兜底返回默认数据,保证设备持续运行。
2. 异步写入优化
高频生产数据采用异步写入,避免频繁IO操作阻塞UI线程、造成界面卡顿。
3. 离线数据兜底
优先本地JSON存储,数据库断连、网络异常时数据不丢失,恢复联网后可拓展自动同步逻辑。
4. 默认值兜底
所有实体模型字段设置工业合理默认值,空数据、首次运行自动适配标准参数,杜绝空指针报错。
十、本篇架构落地核心价值
至此,我们整套工业级数据持久化架构完全落地,彻底解决了传统上位机数据错乱、丢失、崩溃、耦合严重的所有问题:
-
数据分层彻底解耦:UI、业务、数据三层完全隔离,各司其职,互不干扰
-
工业级容错稳定:IO异常、断网、断电、文件损坏全部容错兜底,程序永不崩溃
-
离线在线双适配:本地JSON兜底存储,适配工业现场复杂网络环境
-
数据源可无缝切换:后续拓展MySQL、SQLite只需新增仓储实现,无需改动业务代码
-
参数永久留存:重启、闪退、断电后所有配置、生产数据不丢失
十一、本篇总结
如果说服务层是项目的业务骨架,那数据层就是工业设备稳定运行的数据基石。工业量产软件的稳定性,70%取决于数据层的容错设计与规范设计。
本篇通过通用Repository仓储模式+实体建模+JSON容错持久化+DI托管,搭建了一套标准、稳定、可拓展、可量产的工业数据架构,补齐了项目数据层的所有短板,让整套项目架构真正实现:UI展示、业务处理、数据存储、底层支撑的完整闭环。
下篇预告
下一篇我们将进入工业项目核心难点——HAL硬件抽象层实战!手把手落地硬件统一基类、设备工厂模式、仿真/真实硬件一键切换,彻底解决工业项目硬件适配难、设备耦合严重、替换硬件改代码的行业痛点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)