LightGCN:简单却强大的图卷积协同过滤模型
在推荐系统领域,协同过滤(Collaborative Filtering)是最经典的技术之一。近年来,图神经网络(GNN)的兴起让基于图的协同过滤模型大放异彩,其中 NGCF(Neural Graph Collaborative Filtering)率先将GCN引入用户-物品交互图中,但随后的研究发现,NGCF中很多复杂的特征变换和非线性激活其实是冗余的。LightGCN 应运而生,它通过极简的设计,大幅简化了模型,不仅更容易训练,效果还显著优于NGCF和许多其他模型。本文将深入浅出地解析LightGCN的设计思路、数学原理、代码实现和实际应用。
1. 背景:从矩阵分解到图协同过滤
在推荐系统中,用户和物品的交互通常表示为一个二部图(bipartite graph)。传统的矩阵分解(MF)只学习用户和物品的独立嵌入,然后通过内积来预测评分。这种方法忽略了用户与物品之间的高阶连接关系。
例如,用户 u1u_1u1 喜欢物品 i1i_1i1,而 i1i_1i1 又被用户 u2u_2u2 喜欢,那么 u1u_1u1 和 u2u_2u2 就有协同相似性。NGCF 试图通过GCN的消息传递来捕捉这种高阶协同信号。然而,NGCF中包含了特征变换矩阵 W1,W2W_1, W_2W1,W2 和非线性激活函数 σ\sigmaσ,这些在标准GCN中是为了节点分类设计的,但在协同过滤中,输入特征通常只是用户/物品的ID嵌入,没有丰富的语义信息,过多的非线性变换反而会增大训练难度且容易过拟合。
2. LightGCN 的极简主义设计
He et al. 在论文《LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation》中大胆地提出:去掉NGCF中的特征变换矩阵和非线性激活函数,只保留邻居聚合(neighborhood aggregation),模型反而更强大。这就是LightGCN的核心思想:轻量级的图卷积。
2.1 模型结构
LightGCN的层传播公式极其简单:
- 第0层:用户嵌入 eu(0)\mathbf{e}_u^{(0)}eu(0) 和物品嵌入 ei(0)\mathbf{e}_i^{(0)}ei(0) 就是可学习的ID嵌入。
- 第 k+1k+1k+1 层的用户/物品嵌入更新规则为:
eu(k+1)=∑i∈Nu1∣Nu∣⋅∣Ni∣ei(k) \mathbf{e}_u^{(k+1)} = \sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{|\mathcal{N}_u| \cdot |\mathcal{N}_i|}} \mathbf{e}_i^{(k)} eu(k+1)=i∈Nu∑∣Nu∣⋅∣Ni∣1ei(k)
ei(k+1)=∑u∈Ni1∣Nu∣⋅∣Ni∣eu(k) \mathbf{e}_i^{(k+1)} = \sum_{u \in \mathcal{N}_i} \frac{1}{\sqrt{|\mathcal{N}_u| \cdot |\mathcal{N}_i|}} \mathbf{e}_u^{(k)} ei(k+1)=u∈Ni∑∣Nu∣⋅∣Ni∣1eu(k)
这里 Nu\mathcal{N}_uNu 和 Ni\mathcal{N}_iNi 分别表示用户 uuu 和物品 iii 的邻居集合。对称平方根归一化 1∣Nu∣⋅∣Ni∣\frac{1}{\sqrt{|\mathcal{N}_u|\cdot|\mathcal{N}_i|}}∣Nu∣⋅∣Ni∣1 是标准GCN的归一化方式,能够防止度数高的节点在传播中主导嵌入。
可以看到,这里 没有任何权重矩阵,也没有 tanh\tanhtanh/ReLU 等激活函数,纯粹是对邻居嵌入进行加权求和。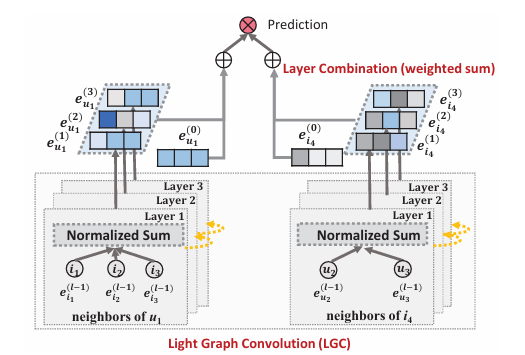
2.2 最终嵌入与预测
经过 KKK 层传播后,LightGCN将每一层得到的嵌入进行加权求和作为最终的嵌入表示:
eu=∑k=0Kαkeu(k),ei=∑k=0Kαkei(k) \mathbf{e}_u = \sum_{k=0}^K \alpha_k \mathbf{e}_u^{(k)}, \quad \mathbf{e}_i = \sum_{k=0}^K \alpha_k \mathbf{e}_i^{(k)} eu=k=0∑Kαkeu(k),ei=k=0∑Kαkei(k)
其中 αk≥0\alpha_k \ge 0αk≥0 是组合权重。论文中设置 αk=1K+1\alpha_k = \frac{1}{K+1}αk=K+11 就能取得很好的效果,即简单的平均池化。
最终预测分数为用户嵌入和物品嵌入的内积:
y^ui=eu⊤ei \hat{y}_{ui} = \mathbf{e}_u^\top \mathbf{e}_i y^ui=eu⊤ei
2.3 训练
LightGCN采用BPR(Bayesian Personalized Ranking)损失进行优化,这是一个成对排序损失,鼓励已交互的预测分数高于未交互的:
L=−∑(u,i,j)∈Dlnσ(y^ui−y^uj)+λ∥E(0)∥2 \mathcal{L} = -\sum_{(u,i,j) \in D} \ln \sigma(\hat{y}_{ui} - \hat{y}_{uj}) + \lambda \|\mathbf{E}^{(0)}\|^2 L=−(u,i,j)∈D∑lnσ(y^ui−y^uj)+λ∥E(0)∥2
其中 (u,i,j)(u,i,j)(u,i,j) 是一个三元组,用户 uuu 与物品 iii 有交互,与物品 jjj 无交互;σ\sigmaσ 是sigmoid函数,λ\lambdaλ 控制 L2L_2L2 正则化,正则化仅施加在第0层的ID嵌入上(避免过拟合且实验证明有效)。
3. 为什么LightGCN有效?
去掉NGCF的权重矩阵和激活函数后,模型失去了特征变换和非线性表达能力,为什么反而更好?可以从几个角度理解:
- 协同过滤中的特征是浅层的:用户和物品的输入特征只是one-hot ID,没有像CV或NLP那样的丰富语义。过多的非线性变换就像是用力过猛,会引入噪声并导致过拟合。
- 简化后的传播本质上是平滑操作:LightGCN等价于对交互图进行线性平滑,通过多层聚合可以自然地学习到高阶协同相似性。这其实与经典的矩阵分解有更深层的联系——LightGCN最终可以看作是一个学习良好的图滤波器的矩阵分解。
- 更易训练,收敛更快:没有额外的变换参数,模型的优化面更平滑,训练更稳定,内存占用也更少。
论文通过消融实验证明,去掉特征变换(尤其是自连接变换)是效果提升的关键。
4. LightGCN 与其他模型的对比
| 模型 | 传播公式 | 参数复杂度 | 主要优势 |
|---|---|---|---|
| MF/BPR | 无图传播, y^ui=puTqi\hat{y}_{ui}=\mathbf{p}_u^T\mathbf{q}_iy^ui=puTqi | 低,仅ID嵌入 | 简单,但忽略图结构 |
| NGCF | 包含 W1,W2\mathbf{W}_1,\mathbf{W}_2W1,W2 和 σ\sigmaσ | 高,每层都有变换 | 引入GCN,但过于复杂 |
| LightGCN | 仅归一化邻居聚合,无变换、无激活 | 低,仅ID嵌入+组合权重 | 简单高效,效果更好 |
| PinSage | 在节点特征丰富时使用GCN+采样 | 较高,有变换 | 工业级图推荐,依赖内容特征 |
| SGC | 去除GCN中的非线性,但与LightGCN场景不同 | 低 | 在图分类中有效,但未针对CF优化 |
在多个基准数据集(如Gowalla, Yelp2018, Amazon-Book)上,LightGCN在Recall和NDCG指标上均大幅超过NGCF、Mult-VAE等模型。
5. LightGCN 的实际应用场景
由于其轻量性和高效性,LightGCN非常适合以下场景:
- 大规模隐式反馈推荐:如电商网站点击、视频观看、音乐试听等隐式反馈数据。
- 冷启动辅助:图传播可以聚合多跳邻居信息,相对纯MF模型对冷启动物品的表示更鲁棒(但仍需初始交互)。
- 召回阶段:由于模型简单,可以快速生成用户和物品嵌入,用于线上近线召回。
- 多行为、多模态扩展的基座:由于其简单的设计,很容易扩展为处理社交关系、知识图谱、物品内容特征的混合模型(如LightGCN+特征融合)。
6. 代码实现示例(PyTorch + PyG)
下面用PyTorch Geometric实现一个最简版的LightGCN,以便理解其核心。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import degree
class LightGCNConv(MessagePassing):
def __init__(self):
super().__init__(aggr='add') # 使用求和聚合
def forward(self, x, edge_index, norm):
# x: [num_users+num_items, emb_dim]
# norm: 对称归一化因子 1/sqrt(|N_u|*|N_i|)
return self.propagate(edge_index, x=x, norm=norm)
def message(self, x_j, norm):
# x_j 为邻居的嵌入,norm是对应边的归一化因子
return norm.view(-1, 1) * x_j
class LightGCN(nn.Module):
def __init__(self, num_users, num_items, emb_dim=64, num_layers=3):
super().__init__()
self.num_users = num_users
self.num_items = num_items
self.emb_dim = emb_dim
self.num_layers = num_layers
# 用户和物品的初始嵌入
self.users_emb = nn.Embedding(num_users, emb_dim)
self.items_emb = nn.Embedding(num_items, emb_dim)
self.convs = nn.ModuleList([LightGCNConv() for _ in range(num_layers)])
# 初始化参数
nn.init.normal_(self.users_emb.weight, std=0.1)
nn.init.normal_(self.items_emb.weight, std=0.1)
def forward(self, edge_index):
# edge_index 形状: [2, E], 其中用户ID从0开始,物品ID加上了num_users
# 预先计算归一化因子
src, dst = edge_index
deg_src = degree(src, self.num_users + self.num_items).float()
deg_dst = degree(dst, self.num_users + self.num_items).float()
norm = 1.0 / torch.sqrt(deg_src[src] * deg_dst[dst])
ego_emb = torch.cat([self.users_emb.weight, self.items_emb.weight], dim=0)
all_embs = [ego_emb]
for conv in self.convs:
ego_emb = conv(ego_emb, edge_index, norm)
all_embs.append(ego_emb)
# 层组合:平均所有层的嵌入
final_emb = torch.stack(all_embs, dim=0).mean(dim=0)
users_final = final_emb[:self.num_users]
items_final = final_emb[self.num_users:]
return users_final, items_final
def bpr_loss(self, users_emb, items_emb, users, pos_items, neg_items):
# users, pos_items, neg_items 是mini-batch索引
u_emb = users_emb[users]
pos_emb = items_emb[pos_items]
neg_emb = items_emb[neg_items]
pos_scores = torch.sum(u_emb * pos_emb, dim=1)
neg_scores = torch.sum(u_emb * neg_emb, dim=1)
loss = -torch.log(torch.sigmoid(pos_scores - neg_scores) + 1e-10).mean()
# L2正则化仅施加在第0层嵌入(此处简化)
l2_reg = torch.norm(u_emb, p=2) + torch.norm(pos_emb, p=2) + torch.norm(neg_emb, p=2)
return loss + 0.0001 * l2_reg
使用上述模型进行训练时,只需构建用户-物品交互图的边索引(注意物品ID需偏移),并按批次采样正负样本即可。
7. 实验效果与调参建议
- 层数 KKK:一般取2~4层。层数过深会导致过度平滑,性能下降。很多实验表明3层表现最佳。
- 嵌入维度:64或128通常足够,更大的维度提升有限。
- 归一化方式:对称平方根归一化(上面所用)通常优于均值归一化或不定归一化。
- 组合权重 α\alphaα:直接使用 1/(K+1)1/(K+1)1/(K+1) 简单有效,也可以设置为可学习参数,但差别不大。
- 正则化系数:需要根据数据集调整,通常在 10−410^{-4}10−4 量级。
8. 局限性与未来方向
尽管LightGCN简洁高效,但它仍有一些局限:
- 缺乏对时间动态性的建模:无法直接利用时间戳信息捕捉用户兴趣漂移。
- 冷启动问题:依然需要一定交互数据,纯协同过滤对于没有历史行为的新用户/物品无能为力。
- 缺乏特征增强:无法直接利用用户/物品的内容属性(如年龄、价格等)。
在LightGCN的基础上,后续出现了许多有意义的扩展,比如:
- SGL (Self-supervised Graph Learning):引入自监督学习增强嵌入质量。
- UltraGCN:进一步将图卷积推向极致,直接在损失函数中近似无穷层。
- LightGCN + 多模态:结合文本、图像特征,构建多模态图协同过滤。
9. 总结
LightGCN用“做减法”的哲学证明了:在协同过滤推荐场景下,图卷积的核心价值是邻居聚合带来的平滑协同信号,而非复杂的特征变换。 它以极简的结构实现了SOTA性能,成为现代图推荐系统的基石之一。无论是学术研究还是工业实践,LightGCN都是一个必知必会的基础模型。
如果你正在构建推荐系统,不妨从LightGCN开始,它既简单又强大,是你理解图神经网络在推荐中如何工作的最佳入口。
参考文献
- He, X., Deng, K., Wang, X., Li, Y., Zhang, Y., & Wang, M. (2020). LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. SIGIR 2020.
希望这篇博客能帮助你深入理解LightGCN。如有疑问或交流,欢迎在评论区留言。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)