昇腾多机训练中HCCL通信问题的分析与解决
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
在大规模深度学习训练任务中,多机多卡分布式训练已成为提升训练效率的主流方式。在实际使用PyTorch框架结合昇腾CANN进行8机训练任务时,我们遇到了任务拉起失败的问题。本文记录了该问题的详细排查过程与解决方案,旨在为遇到类似问题的开发者提供参考。
问题描述
在使用8台训练服务器进行分布式训练时,任务启动失败。关键报错信息显示HCCL(Heterogeneous Computing Communication Library)建链过程中出现socket超时(timeout[120s])。初步日志显示,部分设备在初始化集合通信时未能正常完成握手。
相关环境信息如下:
- PyTorch 版本:2.6.0
- CANN 版本:8.3.RC1
- HDK 版本:25.3.rc1.2
问题根因与解决方案
经分析,问题主要由以下两方面原因导致:
- 通信网卡名未指定:HCCL在初始化时会自动选择通信网卡,在某些多网卡环境中可能选中非预期网卡,导致建链异常。
- 模型参数量大,通信延迟高:训练任务中的模型较大(显存占用约53GB),数据传输时间较长,默认的HCCL超时设置(120秒)不足,造成建链超时。
解决方案:
- 手动指定HCCL通信使用的网卡名,避免网卡选择冲突;
- 增大HCCL建链及通信的超时配置,确保大规模数据传输时可完成初始化。
关键配置示例:
export HCCL_CONNECT_TIMEOUT=7200
export HCCL_SOCKET_TIMEOUT=3600
排查过程
4.1 最小化复现与节点排查
我们首先尝试缩小问题范围:
- 单机及部分双机训练任务可正常执行;
- 4机训练任务运行正常,但扩展至5机时出现失败;
- 通过替换节点进行交叉测试,初步排除单机硬件问题,判断为通信或配置类问题。
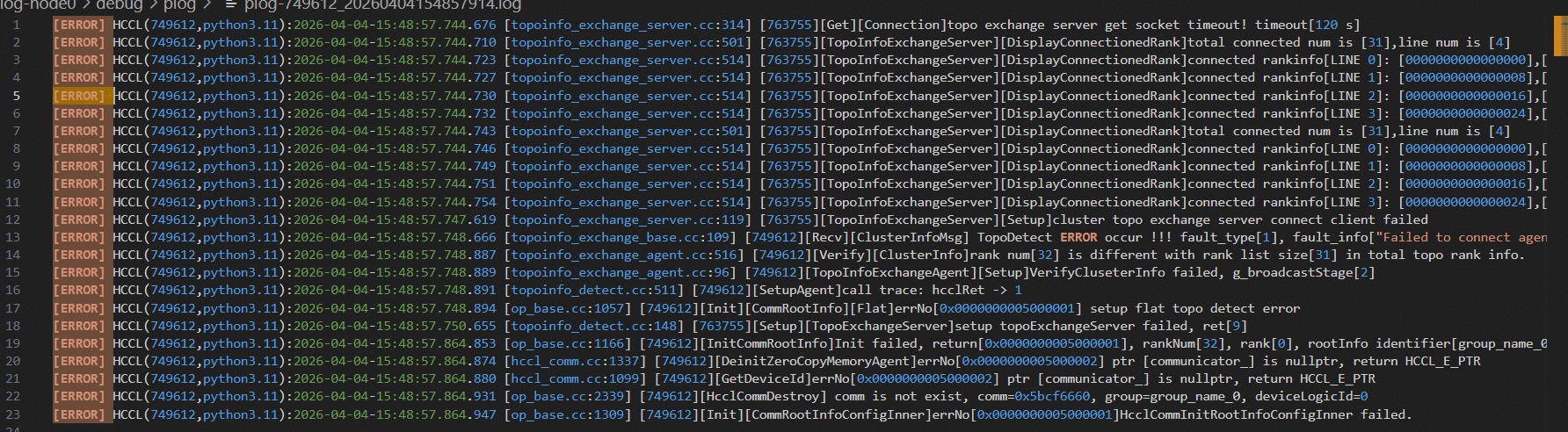
4.2 定位HCCL网卡选择问题
日志中多次出现以下典型错误:
该报错
表明HCCL建链阶段发生超时。我们参考官方文档,为HCCL显式配置通信网卡,排除了网卡选择不一致所导致的问题。完成该配置后,双机训练任务稳定执行,但扩展至6机时仍会失败。
4.3 调整HCCL超时配置
继续分析6机训练失败的日志:
发现训练进程阻塞在数据传输阶段,显存占用高达53GB。由于模型较大、通信延迟较高,默认的HCCL超时设置已不适用。通过适当增大HCCL_CONNECT_TIMEOUT和HCCL_SOCKET_TIMEOUT参数值,最终8机训练任务可正常拉起并执行:
总结
本文分析了基于PyTorch和CANN进行多机分布式训练时出现的HCCL建链超时问题,并提供了通过指定通信网卡和调整超时配置的有效解决方案。在类似的大规模训练场景中,建议用户根据模型大小和网络状况合理设置HCCL参数,以保证训练任务顺利执行。
相关参考:
- HCCL 网卡配置:https://www.hiascend.com/document/detail/zh/canncommercial/850/commlib/hcclug/hcclug_000093.html
温馨提示:如您在使用中遇到类似问题,可优先检查网卡配置与超时参数,并根据训练规模适当调整相关环境变量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)