大模型面试必备6-看懂 PPO、DPO、GRPO、DAPO 与 GSPO
大模型对齐进化史:一文看懂 PPO、DPO、GRPO、DAPO 与 GSPO
在大模型(LLM)的训练中,如果说预训练(Pre-training)是让模型“读书识字”,微调(SFT)是让模型“学会特定格式”,那么 RLHF(基于人类反馈的强化学习) 就是给模型“树立价值观”,让它的回答更符合人类的偏好。
近年来,对齐算法经历了飞速的迭代。从最经典的 PPO,到简单粗暴的 DPO,再到针对推理模型优化的 GRPO、DAPO 和 GSPO。今天,我们就来扒一扒这些算法的底层逻辑,助你轻松应对大厂面试!
一、 PPO (近端策略优化):对齐算法的“开山鼻祖”
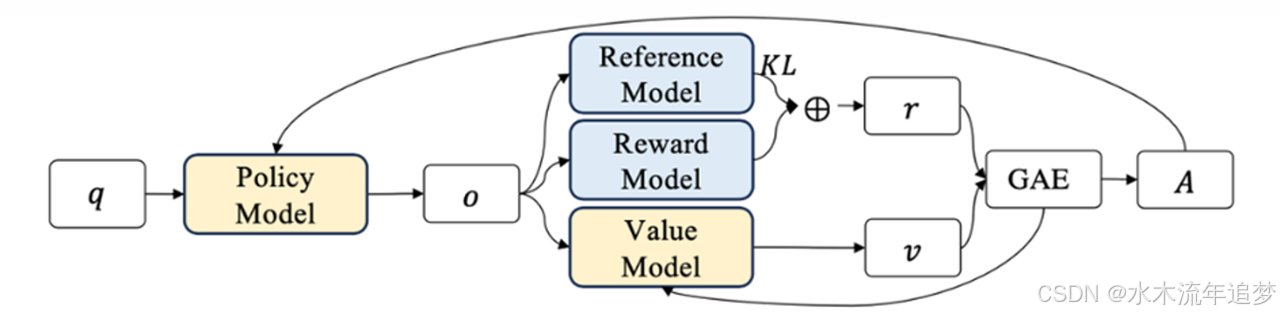
PPO 是 OpenAI 在 ChatGPT 早期使用的核心对齐算法。它的逻辑非常严密,但工程实现相当复杂。
1. 运行机制:四大模型同台竞技
PPO 的训练需要同时跑 4 个模型 :
- Policy Model (策略模型 - 需更新):当前正在训练的大模型,负责生成回答。
- Reference Model (参考模型 - 冻结):初始状态的大模型。用来计算 KL 散度,防止现在的模型“放飞自我”、偏离初衷。
- Reward Model (奖励模型 - 冻结):评委。负责给 Policy 生成的回答打分(实际收益 rrr)。
- Value Model (价值模型/Critic - 需更新):预言家。负责预测当前状态下能拿到多少分(预期收益 vvv)。
2. 核心思想:霸总逻辑
PPO 的核心在于计算优势 (Advantage):优势 = 实际收益 - 预期收益 。
如果优势大于 0,说明当前生成的 Token 表现超出了预期,模型以后就会增加生成这个 Token 的概率;反之则减少 。
整个 Reward 的计算逻辑是典型的“霸总逻辑”:除非你能拿到好结果(整句话得分高),否则你每走一步都得给我守规矩(受 KL 散度惩罚约束) 。
3. 面试痛点
- 缺点:训练极度繁琐,需要同时加载 4 个模型,显存占用极大,且超参数极难调 。
二、 DPO (直接偏好优化):简单粗暴的“显存救星”
为了解决 PPO 占用显存大、训练不稳定的问题,DPO 横空出世,彻底颠覆了 RLHF 的玩法 。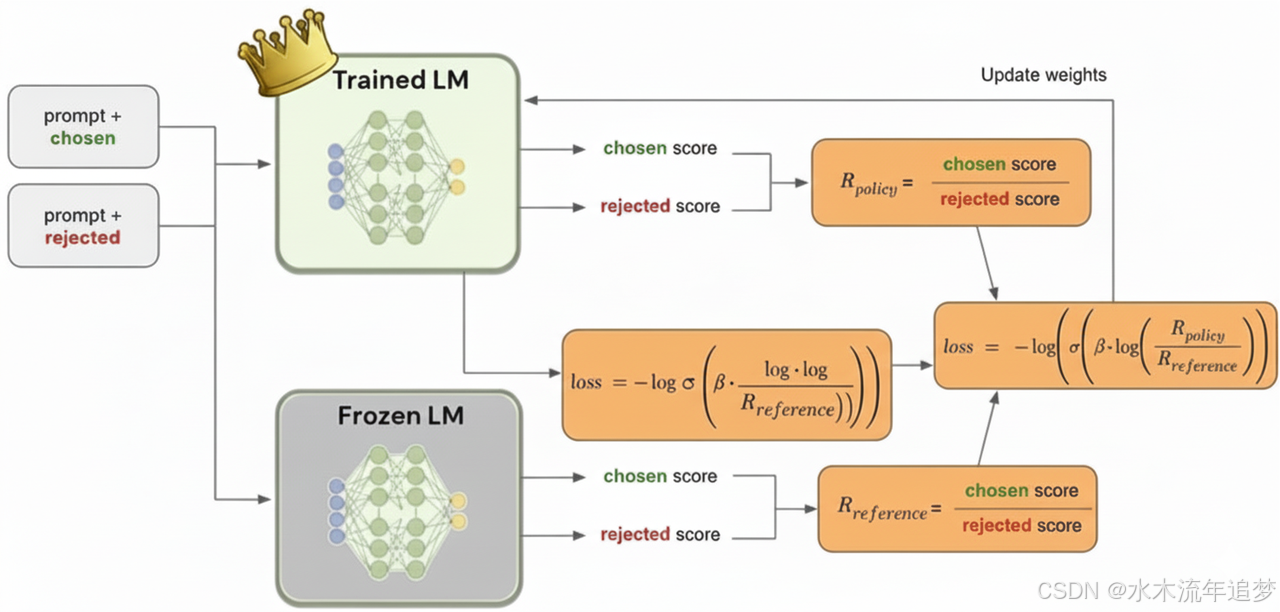
1. 核心改进:干掉奖励模型和 Critic
DPO 巧妙地绕过了构建 Reward Model 和强化学习的过程,直接通过偏好数据进行微调 。你只需要保留 Policy Model 和 Reference Model 即可 。
2. 数据与目标
-
数据格式:三元组数据
[输入, 优选回答 (chosen), 次选回答 (rejected)]。 -
优化目标:最大化模型对 chosen 数据和 rejected 数据的概率差值 。简单来说,就是让模型越来越喜欢“好回答”,越来越讨厌“坏回答”。
3. 面试痛点
- 优点:高效、省显存、调试极其简单(不需要强化学习算法)。
三、 GRPO (组内相对策略优化):DeepSeek-R1 的核心功臣
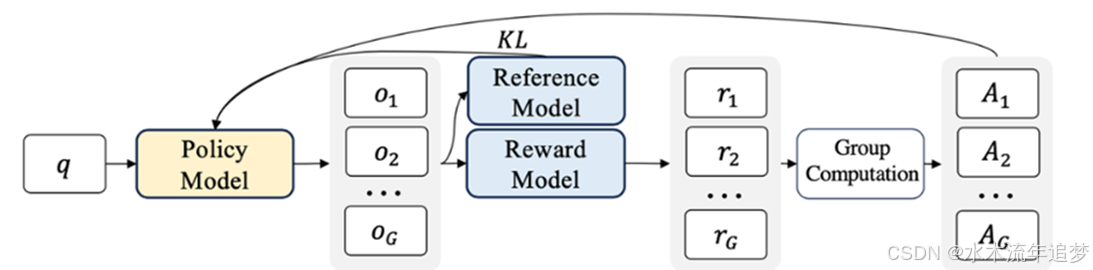
GRPO 是 PPO 的升级版,特别适合用于激发大模型的复杂推理能力。
1. 核心改进:关注群体,干掉 Critic
-
一对多采样:输入一个问题,模型会一次性生成多个回答(一个 Group)。
-
相对优势计算:不用 Critic 模型来预测预期收益了,而是直接计算这组回答的均值和标准差。把单条响应的得分减去均值再除以标准差,得出“标准化优势值” 。
2. 面试痛点
- 优点:省去了庞大的 Critic 模型(省显存);利用群体统计量计算相对优势,能一次性提升整个“团队”的表现,比 PPO 更稳 。
四、 DAPO (动态采样策略优化):深究细节的“打补丁”大师
GRPO 虽然好,但在实际训练长文本推理模型时,常常会浪费训练信号。DAPO 针对 GRPO 提出了 6 项硬核改进 :
-
提高 Clip 上界:释放低概率但关键的 Token 的上涨空间,防止好不容易蒙对的 Token 被截断抑制 。
-
动态采样 (Dynamic Sampling):如果一批次采样出来的得分全一样(全 0 或全 1),优势就会变成 0。DAPO 强制要求重新采样,保证得分多样性,防止梯度消失 。
-
Token 级梯度聚合:解决长文本回答中,Token 权重被严重稀释的问题,让长短回答的 Token 享受公平的权重 。
-
软惩罚机制 (Soft Punishment):设置双阈值,回答过长先线性扣分,长得离谱直接分数清零,治理大模型“啰嗦”的毛病 。
-
移除 KL 散度:在长文本推理中,允许模型放飞自我,不再强求它和初始模型保持一致 。
-
引入规则奖励:针对代码和数学题,直接用规则校验结果对错,放弃使用 Reward Model,彻底杜绝模型“讨好裁判 (Reward Hacking)”的作弊行为 。
五、 GSPO (分组序列策略优化):整句优化的终极形态
不管是 PPO 还是 GRPO,本质上都是在 Token 级别(逐词)进行优化的 。
1. 痛点:MoE 架构的“水土不服”
在 MoE(混合专家)架构下,逐词优化会遇到大麻烦。因为模型更新后,路由(Router)可能会把同样的词分配给不同的“专家” 。这种结构的底层变动会导致概率比率严重失真,梯度充满高方差噪声,最终导致训练崩溃 。
2. GSPO 的解法:Sequence-Level 优化
阿里通义团队提出的 GSPO 认为:我们平时评价一个答案,本来就是看完整句话的。所以 GSPO 放弃了逐词打分,直接对整句进行裁剪和优化 。
- 优点:减少了词级波动带来的噪声,让 MoE 模型也能稳定收敛;并且根据句子得分筛选纯净样本,收敛更快 。
🎯 面试一分钟总结速记 (Cheat Sheet)
如果你在面试中被问到对齐算法的发展,请直接抛出以下总结 :
- PPO:四模型齐上阵,基于“实际收益 - 预期收益”计算优势,通过 Clip 限制更新步幅,经典但笨重。
- DPO:化繁为简,干掉奖励模型和强化学习,直接用“好坏对比数据”微调策略模型。
- GRPO:DeepSeek 核心算法,一个问题生成一组答案,用组内均值和方差算优势,干掉 Critic 模型省显存。
- DAPO:GRPO 的精修版,通过提高 Clip 上限、引入长文本软惩罚和纯规则奖励,解决长序列梯度稀释和作弊问题。
- GSPO:阿里提出的整句级优化方案,解决 MoE 架构在 Token 级优化中路由突变导致的训练崩溃问题。
print('hello world')

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)