【C++】C++ 二叉搜索树完全指南:从原理到实现
📌 相关文章推荐

很高兴你点开这篇文章✨
这里会持续更新更多有用的内容,关注我,一起慢慢变好呀
👍 点赞 ⭐ 收藏 💬 评论
前言
二叉搜索树(Binary Search Tree,BST)是一种兼具有序性和高效操作的树形数据结构。它是 C++ 标准库中 set、map、multiset、multimap 等容器的底层实现基础让增删查操作的时间复杂度,在理想的情况下可达到 O(log₂N) 但是最坏情况仍然是 O(N)。
BST 与二分查找的对比
| 特性 | 二分查找(数组) | 二叉搜索树 |
|---|---|---|
存储结构 |
连续数组 | 链式节点 |
查找效率 |
O(log n) | O(log n) 平均 |
插入效率 |
O(n) 需移动元素 | O(log n) 平均 |
删除效率 |
O(n) 需移动元素 | O(log n) 平均 |
动态扩容 |
需要 | 本身自然支持 |
1. 二叉搜索树概述
1.1 什么是二叉搜索树?
是一种兼具“有序性”和“高效操作”的树形结构,是一种特殊的二叉树
- 它通过特定的节点值排列规则,让增删查操作的时间复杂度在理想的情况下可达到 O(log₂N) 但是最坏情况仍然是 O(N)

性质总结
-
若它的左⼦树不为空,则左⼦树上所有结点的值都
“⼩于等于”根结点的值 -
若它的右⼦树不为空,则右⼦树上所有结点的值都
“⼤于等于”根结点的值 -
它的左右⼦树也分别为⼆叉搜索树
-
⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值,具体看使⽤场景定义,后续我们学习map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set不⽀持插⼊相等值,multimap/multiset⽀持插⼊相等值
1.2 为什么不用二分查找?
二分查找虽然查找效率高(O(log n)),但它有以下缺陷:
- 需要存储在支持下标随机访问的结构中(如数组)
- 需要数据有序
- 插入和删除效率低(需要挪动数据,O(n))
🐾二叉搜索树完美解决了动态插入删除的问题。
2. 核心性质与性能分析
2.1 节点结构定义
namespace key
{
template<class K>
class BSTNode
{
public:
// 构造函数:初始化列表指针为空,键值为传入值
BSTNode(const K& key = 0)
:_key(key)
, _left(nullptr)
, _right(nullptr)
{
}
K _key; // 节点键值
BSTNode<K>* _left; // 左子树指针
BSTNode<K>* _right; // 右子树指针
};
//封装二叉树单个节点,每个节点自带数据、左/右孩子指针,构造时默认空指针、初始化key
2.2 性能分析
| 情况 | 树形态 | 高度 | 时间复杂度 |
|---|---|---|---|
最优情况 |
完全二叉树 | log₂ N | O(log N) |
最差情况 |
单支树(退化为链表) | N | O(N) |
所以综合⽽⾔⼆叉搜索树增删查改时间复杂度为: O(N)

结论 :二叉搜索树的性能取决于树的平衡程度。极端情况下退化为链表,这也是为什么后续会有 AVL 树和红黑树的出现。
3. Key 模型实现
Key 模型只存储键值,用于判断元素在不在集合中(如 set 容器)。
3.1 插入操作(Insert)
(1) 树为空,则直接新增结点,赋值给root指针
(2) 树不空,按⼆叉搜索树性质
- 插入值比当前结点
大则往右走,找到空位置,插入新结点 - 插入值比当前结点
小则往左走,找到空位置,插入新结点
(3) 如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点。
(要注意的是要保持逻辑⼀致性,插⼊相等的值“不要⼀会往右⾛,⼀会往左⾛”)
bool Insert(const K& key)
{
// 1. 树为空:直接新增结点作为根
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
// 2. 树不空:按 BST 性质找到插入位置
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > key) // 比当前结点小 -> 往左走
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < key) // 比当前结点大 -> 往右走
{
father = cur;
cur = cur->_right;
}
else // 键值已存在 -> 插入失败
{
return false;
}
}
// 3. 创建新节点并连接到父节点
cur = new Node(key);
if (father->_key > key)
father->_left = cur;
else
father->_right = cur;
return true;
}
🐾 插入过程演示(插入 6) :

3.2 查找操作(Find)
(1)从根节点(_root)开始⽐较,查找x,x⽐根的值⼤则往右边⾛查找,x⽐根值⼩则往左边⾛查找。
(2)最多查找⾼度次,⾛到到空,还没找到,这个值不存在。
(3)如果不⽀持插⼊相等的值,找到x即可返回
(4)如果⽀持插⼊相等的值,意味着有多个x存在,⼀般要求查找中序的第⼀个x。
bool Find(const K& x)
{
//从根节点(_root)开始,用cur指针遍历
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
{
cur = cur->_left; //往左走
}
else if (cur->_key < x)
{
cur = cur->_right; //往右走
}
else
{
return true; //目标值找到了
}
}
return false; //该值不存在
}
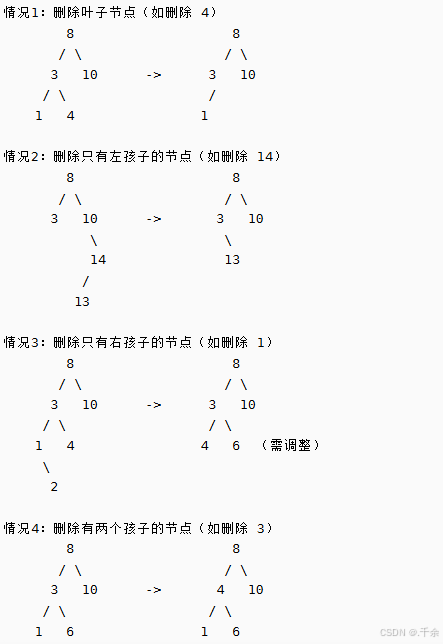
3.3 删除操作(Erase)
删除操作是 BST 中最复杂的部分,需要分情况处理 :
-
⾸先查找元素是否在⼆叉搜索树中,如果不存在,则返回false。
-
如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
(1)要删除的结点N左右孩⼦均为空
(2)要删除的结点N左孩⼦位空,右孩⼦结点不为空
(3)要删除的结点N右孩⼦位空,左孩⼦结点不为空
(4)要删除的结点N左右孩⼦结点均不为空🐾
对应以上四种情况的解决⽅案:(1)把N结点的⽗亲对应孩⼦指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是⼀样的)
(2)把N结点的⽗亲对应孩⼦指针指向N的右孩⼦,直接删除N结点
(3)把N结点的⽗亲对应孩⼦指针指向N的左孩⼦,直接删除N结点
(4)⽆法直接删除N结点,因为N的两个孩⼦⽆处安放,只能⽤替换法删除。- 找N左⼦树的值最⼤结点R(最右结点)或者N右⼦树的值最⼩结点R(最左结点)替代N,
- 因为这两个结点中任意⼀个,放到N的位置,都满⾜⼆叉搜索树的规则。
- 替代N的意思就是N和R的两个结点的值交换,转⽽变成删除R结点,R结点符合情况2或情况3,可以直接删除。
bool Erase(const K& x)
{
//cur:遍历节点,指向要删除的节点
//father:记录待删节点的父节点,用来删除之后连接后面的节点
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > x)
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < x)
{
father = cur;
cur = cur->_right;
}
else
{
//情况1:目标删除结点的左孩子为空
if (cur->_left == nullptr)
{
//删除的是根节点(没有父节点)
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
//判断cur是父节点的左孩子还是右孩子,直接用cur的右子树代替自己
//逻辑:左孩子为空,直接把自己的右子树交给父节点接管,自身释放
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_right;
}
}
delete cur;
return true;
}
//情况2:目标删除结点的右孩子为空
else if (cur->_right == nullptr)
{
//右孩子为空,直接把自己的左子树交给父节点接管
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_left;
}
else
{
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_left;
}
}
delete cur;
return true;
}
//情况3:目标删除结点的左、右孩子都不为空:替换法(找右子树的最小节点,将key值赋给目标删除结点并删除最小节点)
else
{
Node* min_right_father = nullptr; //min_right_father:保存右子树最小结点的父亲结点
Node* min_right = cur->_right; //min_right:获取右子树最小结点
while (min_right->_left)
{
min_right_father = min_right;
min_right = min_right->_left;
}
cur->_key = min_right->_key; //把最小值覆盖到目标删除节点,等价于删掉了原节点
if (min_right_father == nullptr) //若仍为空,说明右子树最小节点就是cur的右孩子节点
{
cur->_right = min_right->_right;
}
else //不为空,即最小节点有父节点,父节点的左指针接最小节点的右子树
{
min_right_father->_left = min_right->_right;
}
delete min_right;
return true;
}
}
}
return false;
}
3.4 删除的四种情况图解
4. Key-Value 模型实现
Key-Value 模型同时存储键和值,用于字典查询、统计词频等场景(如 map 容器)
4.1 节点结构
namespace key_value
{
template<class K, class V>
class BSTNode
{
public:
//构造:初始化key、value,左右指针置空
BSTNode(const K& key = 0, const V& value = 0)
: _key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
K _key; // 排序依据,唯一且不可重复
V _value; // 附带业务数据,可以重复
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
};
}
4.2 查找(返回节点指针)
Node* Find(const K& x)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
cur = cur->_left;
else if (cur->_key < x)
cur = cur->_right;
else
return cur; // 返回节点指针,可修改 value
}
return nullptr;
}
4.3 深拷贝与析构
// 析构:后序遍历删除所有节点
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
void Destroy(const Node* root)
{
if (root == nullptr) return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
// 深拷贝:前序遍历创建节点
BSTree(const BSTree<K, V>& bst)
{
_root = Copy(bst._root);
}
Node* Copy(Node* root)
{
if (root == nullptr) return nullptr;
Node* newroot = new Node(root->_key, root->_value);
newroot->_left = Copy(root->_left);
newroot->_right = Copy(root->_right);
return newroot;
}
// 默认构造
BSTree() = default; // C++11 强制生成默认构造函数
5. 实际应用场景
5.1 字典查询(中英文翻译)
void Test2()
{
//使用key/value二叉搜索树的情况(查字典)
key_value::BSTree<string, string> dict;
//BSTree<string, string> copy = dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "输入");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
}
//int main()
//{
// Test2();
// return 0;
//}
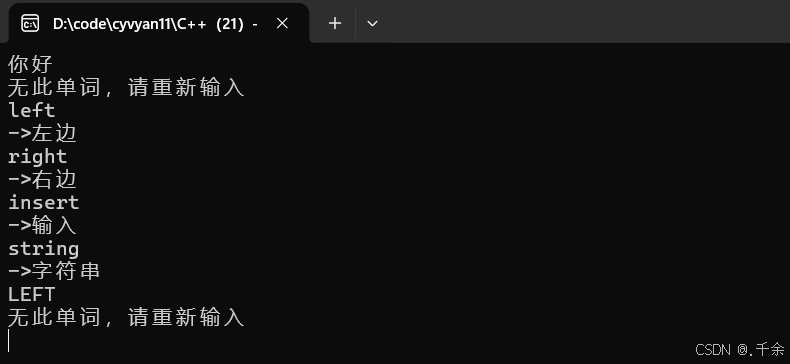
5.2 统计词频
void Test3()
{
//使用key/value二叉搜索树的情况(存放数据的个数)
string arr[] = { "西瓜", "葡萄", "苹果", "西瓜", "哈密瓜", "苹果", "香蕉", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> countTree; //int:不同string存放的次数
/*
先查找水果是否搜索树中
- 不在,说明水果第一次出现,则插入<水果, 1>
- 在,则查找到的结点中水果对应的次数++
*/
for (const auto& str : arr)
{
//STreeNode<string, int>* ret = countTree.Find(str);
auto ret = countTree.Find(str);
if (ret == nullptr)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;//若ret不为nullptr则已经存在,Find找到结点后直接访问_value再++即可
}
}
countTree.Print();
key_value::BSTree<string, int> copy = countTree;
}
int main()
{
Test3();
return 0;
}
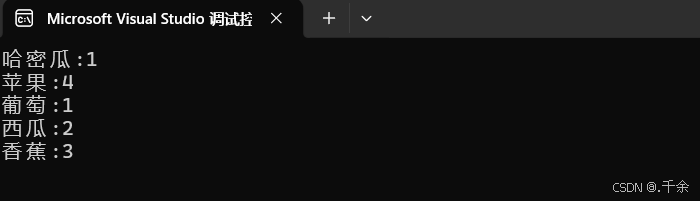
5.3 Key 模型测试
🐾 插入
void Test1()
{
//1. 插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print(); //1 3 4 6 7 8 10 13 14
}
int main()
{
Test1();
return 0;
}
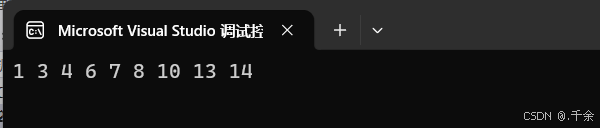
🐾 查找
void Test1()
{
//1. 插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print(); //1 3 4 6 7 8 10 13 14
//2. 查找
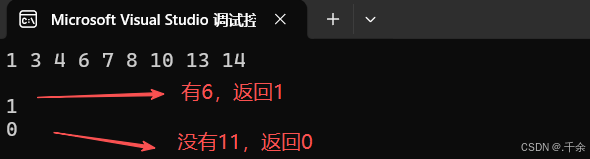
cout << bst1.Find(6) << endl; //有6,返回1(true)
cout << bst1.Find(11) << endl; //没有11,返回0(false)
}
int main()
{
Test1();
return 0;
}
🐾 删除
void Test1()
{
//1. 插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print(); //1 3 4 6 7 8 10 13 14
cout << " " << endl;
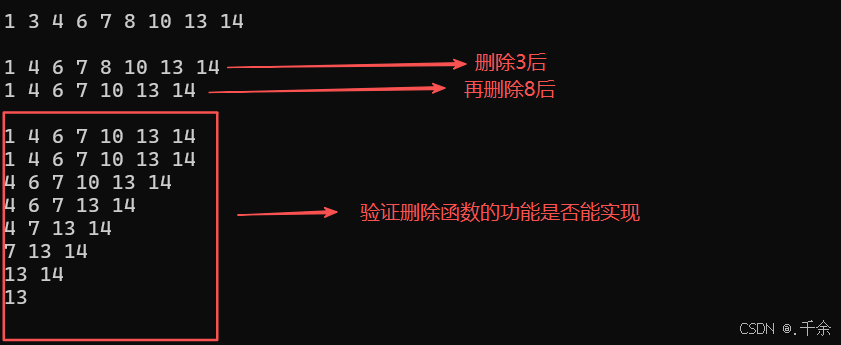
//3. 删除 // 1 3 4 6 7 8 10 13 14
bst1.Erase(3); //删掉 3 -> 1 4 6 7 8 10 13 14
bst1.Print();
bst1.Erase(8); //再删掉 8 -> 1 4 6 7 10 13 14
bst1.Print();
cout << " " << endl;
for (auto e : arr) //用于判断删除函数的实现是否成功:将所有的节点都删掉
{
bst1.Erase(e);
bst1.Print();
}
}
int main()
{
Test1();
return 0;
}
7. 总结
二叉搜索树的核心知识点:
| 分类 | 核心内容 |
|---|---|
核心性质 |
左子树 < 根 < 右子树,递归定义 |
性能 |
平均 O(log n),最差 O(n) |
插入 |
查找空位 -> 创建节点 -> 连接父节点 |
查找 |
从根开始,小于向左,大于向右 |
删除 |
三种情况:无子/单子/双子(替换法) |
两种模型 |
Key 模型(set)、Key-Value 模型(map) |
应用场景 |
字典查询、统计词频、去重排序 |
BST操作时间复杂度总结
| 操作 | 平均复杂度 | 最差复杂度 |
|---|---|---|
插入 |
O(log n) | O(n) |
查找 |
O(log n) | O(n) |
删除 |
O(log n) | O(n) |
中序遍历 |
O(n) | O(n) |
本文全部代码
🐾 Search.h
#pragma once
#include <iostream>
using namespace std;
/*
BST:Binary Search Tree(二叉搜索树)
是一种兼具“有序性”和“高效操作”的树形结构,它通过特定的节点值排列规则,让增删查操作的时间复杂度
在理想的情况下可达到 O(log₂N) 但是最坏情况仍然是 O(N)。
1.核心性质:
- 若它的左⼦树不为空,则左⼦树上所有结点的值都“⼩于等于”根结点的值
- 若它的右⼦树不为空,则右⼦树上所有结点的值都“⼤于等于”根结点的值
- 它的左右⼦树也分别为⼆叉搜索树
- ⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值,具体看使⽤场景定义,
后续我们学习map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set不⽀持插⼊相等值,
multimap/multiset⽀持插⼊相等值
2.性能分析:
- 最优情况下,⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为: log2 N
- 最差情况下,⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度为: N
所以综合⽽⾔⼆叉搜索树增删查改时间复杂度为: O(N)
3.二分查找的缺陷:
- 需要存储在⽀持下标随机访问的结构中,并且有序。
- 插⼊和删除数据效率很低,因为存储在下标随机访问的结构中,插⼊和删除数据⼀般需要挪动数据
4.二叉搜索树的插入(Insert):
(1) 树为空,则直接新增结点,赋值给root指针
(2)树不空,按⼆叉搜索树性质,插⼊值⽐当前结点⼤往右⾛,插⼊值⽐当前结点⼩往左⾛,找到空位置,插⼊新结点。
(3) 如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点。
(要注意的是要保持逻辑⼀致性,插⼊相等的值“不要⼀会往右⾛,⼀会往左⾛”)
5.二叉搜索树的查找(Find):
(1)从根节点(_root)开始⽐较,查找x,x⽐根的值⼤则往右边⾛查找,x⽐根值⼩则往左边⾛查找。
(2)最多查找⾼度次,⾛到到空,还没找到,这个值不存在。
(3)如果不⽀持插⼊相等的值,找到x即可返回
(4)如果⽀持插⼊相等的值,意味着有多个x存在,⼀般要求查找中序的第⼀个x。
6.二叉搜索树的删除(Erase):
- ⾸先查找元素是否在⼆叉搜索树中,如果不存在,则返回false。
- 如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
(1)要删除的结点N左右孩⼦均为空
(2)要删除的结点N左孩⼦位空,右孩⼦结点不为空
(3)要删除的结点N右孩⼦位空,左孩⼦结点不为空
(4)要删除的结点N左右孩⼦结点均不为空
对应以上四种情况的解决⽅案:
(1)把N结点的⽗亲对应孩⼦指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是⼀样的)
(2)把N结点的⽗亲对应孩⼦指针指向N的右孩⼦,直接删除N结点
(3)把N结点的⽗亲对应孩⼦指针指向N的左孩⼦,直接删除N结点
(4)⽆法直接删除N结点,因为N的两个孩⼦⽆处安放,只能⽤替换法删除。
- 找N左⼦树的值最⼤结点R(最右结点)或者N右⼦树的值最⼩结点R(最左结点)替代N,
因为这两个结点中任意⼀个,放到N的位置,都满⾜⼆叉搜索树的规则。
替代N的意思就是N和R的两个结点的值交换,转⽽变成删除R结点,R结点符合情况2或情况3,可以直接删除。
7.核心结论:
· 查找:从根开始比较,小于则向左,大于则向右。
· 插入:类似查找,最后将新节点挂在缺失孩子的位置。
· 删除:分三种情况处理
· 无子节点 → 直接删除
· 一个子节点 → 用子节点替换
· 两个子节点 → 找右子树中的最小节点(或左子树最大节点)替换值,再删除该节点
*/
/*
key命名空间:纯key模型(只存键,去重排序)、
规则:左子树 < 根 < 右子树,key不允许重复
成员:
- 公开成员:插入Insert、中序打印Print
- 私有成员:递归打印_Print、根节点指针_root
*/
namespace key
{
template<class K>
class BSTNode
{
public:
// 构造函数:初始化列表指针为空,键值为传入值
BSTNode(const K& key = 0)
:_key(key)
, _left(nullptr)
, _right(nullptr)
{
}
K _key; // 节点键值
BSTNode<K>* _left; // 左子树指针
BSTNode<K>* _right; // 右子树指针
};
//封装二叉树单个节点,每个节点自带数据、左/右孩子指针,构造时默认空指针、初始化key
template<class K>
class BSTree
{
public:
typedef BSTNode<K> Node; //重命名节点类,简化代码-> 用 Node 代替 BSTNode<K>
//1. 二叉搜索树的插入(Insert)
bool Insert(const K& key)
{
//1.树为空,则直接新增结点,赋值给root指针
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
/*
2.树不空,按二叉搜索树性质:
- 插入值比当前结点大则往右走,找到空位置,插入新结点
- 插入值比当前结点小则往左走,找到空位置,插入新结点
*/
Node* cur = _root; //cur : 遍历节点
Node* father = nullptr; //father:记录cur的父节点(后面用来挂新节点)
while (cur)
{
if (cur->_key > key)
{
father = cur; //先将当前cur位置存到father
cur = cur->_left; //再移动cur
}
else if (cur->_key < key)
{
father = cur;
cur = cur->_right;
}
else //相同则则不符合插入规则,返回false
{
return false;
}
}//while循环结束则说明找到了插入位置
//创建新节点
cur = new Node(key);
//判断一下cur位于father的左边还是右边
if (father->_key > key)
{
father->_left = cur;
}
else
{
father->_right = cur;
}
return true;
}//完成挂载,插入成功
//中序遍历
void Print()
{
_Print(_root);//类中可以访问私有成员变量_root
cout << endl;
}
//2. 二叉搜索树的查找(Find)
bool Find(const K& x)
{
//从根节点(_root)开始,用cur指针遍历
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
{
cur = cur->_left; //往左走
}
else if (cur->_key < x)
{
cur = cur->_right; //往右走
}
else
{
return true; //目标值找到了
}
}
return false; //该值不存在
}
//3. 二叉搜索树的删除(Erase)
bool Erase(const K& x)
{
//cur:遍历节点,指向要删除的节点
//father:记录待删节点的父节点,用来删除之后连接后面的节点
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > x)
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < x)
{
father = cur;
cur = cur->_right;
}
else
{
//情况1:目标删除结点的左孩子为空
if (cur->_left == nullptr)
{
//删除的是根节点(没有父节点)
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
//判断cur是父节点的左孩子还是右孩子,直接用cur的右子树代替自己
//逻辑:左孩子为空,直接把自己的右子树交给父节点接管,自身释放
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_right;
}
}
delete cur;
return true;
}
//情况2:目标删除结点的右孩子为空
else if (cur->_right == nullptr)
{
//右孩子为空,直接把自己的左子树交给父节点接管
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_left;
}
else
{
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_left;
}
}
delete cur;
return true;
}
//情况3:目标删除结点的左、右孩子都不为空:替换法(找右子树的最小节点,将key值赋给目标删除结点并删除最小节点)
else
{
Node* min_right_father = nullptr; //min_right_father:保存右子树最小结点的父亲结点
Node* min_right = cur->_right; //min_right:获取右子树最小结点
while (min_right->_left)
{
min_right_father = min_right;
min_right = min_right->_left;
}
cur->_key = min_right->_key; //把最小值覆盖到目标删除节点,等价于删掉了原节点
if (min_right_father == nullptr) //若仍为空,说明右子树最小节点就是cur的右孩子节点
{
cur->_right = min_right->_right;
}
else //不为空,即最小节点有父节点,父节点的左指针接最小节点的右子树
{
min_right_father->_left = min_right->_right;
}
delete min_right;
return true;
}
}
}
return false;
}
private:
//因为对象调用Print(const Node* root)函数时
//无法传_root(私有无法访问),所以在类中我们套一层_Print即可
void _Print(const Node* root)
{
if (root == nullptr)
{
return;
}
_Print(root->_left);
cout << root->_key << " ";
_Print(root->_right);
}
private:
Node* _root = nullptr;
};
}
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
//key_value
//区别纯key节点:多存一个业务数据 _value
namespace key_value
{
// key-value模型节点
template<class K, class V>
class BSTNode
{
public:
//构造:初始化key、value,左右指针置空
BSTNode(const K& key = 0, const V& value = 0)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{
}
K _key; //排序依据,唯一且不可重复
V _value; //附带数据,可以重复
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
};
// key-value模型BST类
template<class K, class V>
class BSTree
{
public:
typedef BSTNode<K, V> Node;
//二叉搜索树的析构(为了防止内存泄漏)
~BSTree()
{
//使用递归(后序遍历)将每个结点进行删除
//但由于递归需要传参所以我们可以再实现一个成员函数Destroy
Destroy(_root);
_root = nullptr;
}
//写了析构也就需要写深拷贝(否则就会出现同一块析构两次的情况)
BSTree(const BSTree<K, V>& bst)
{
_root = Copy(bst._root);
}
//因为实现了深拷贝,所以类中就没有默认构造了,需要手动实现
/*BSTree()
:_root(nullptr)
{ }*/
BSTree() = default; //强制生成构造
//1. 二叉搜索树的插入(Insert)
bool Insert(const K& key, const V& value)
{
//树为空,则直接新增结点,赋值给root指针
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
//树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点
//我们通过一个cur来记录要判断走哪的指针,father来记录之前的位置便于找到后连接cur
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > key)
{
father = cur; //先将当前cur位置存到father
cur = cur->_left; //再移动cur
}
else if (cur->_key < key)
{
father = cur;
cur = cur->_right;
}
else //相同则则不符合插入规则,返回false
{
return false;
}
}//while循环结束则说明找到了插入位置
cur = new Node(key, value);
//由于cur位于father的左边还是右边不确定,所以需要判断一下
if (father->_key > key)
{
father->_left = cur;
}
else
{
father->_right = cur;
}
return true;
}
//中序遍历
void Print()
{
_Print(_root);//类中可以访问_root
cout << endl;
}
//2. 二叉搜索树的查找(有返回类型是为了查找后满足需要修改_value的情况)
Node* Find(const K& x)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > x)
{
cur = cur->_left;
}
else if (cur->_key < x)
{
cur = cur->_right;
}
else
{
return cur;
}
}
return nullptr;
}
//3. 二叉搜索树的删除(Erase)
bool Erase(const K& x)
{
//cur:遍历节点,指向要删除的节点
//father:记录待删节点的父节点,用来删除之后连接后面的节点
Node* cur = _root;
Node* father = nullptr;
while (cur)
{
if (cur->_key > x)
{
father = cur;
cur = cur->_left;
}
else if (cur->_key < x)
{
father = cur;
cur = cur->_right;
}
else
{
//情况1:目标删除结点的左孩子为空
if (cur->_left == nullptr)
{
//删除的是根节点(没有父节点)
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_right;
}
else
{
//判断cur是父节点的左孩子还是右孩子,直接用cur的右子树代替自己
//逻辑:左孩子为空,直接把自己的右子树交给父节点接管,自身释放
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_right;
}
}
delete cur;
return true;
}
//情况2:目标删除结点的右孩子为空
else if (cur->_right == nullptr)
{
//右孩子为空,直接把自己的左子树交给父节点接管
if (cur == _root)
{
//直接修改根节点即可
_root = cur->_left;
}
else
{
if (father->_left == cur)
{
father->_left = cur->_right;
}
else
{
father->_right = cur->_left;
}
}
delete cur;
return true;
}
//情况3:目标删除结点的左、右孩子都不为空:替换法(找右子树的最小节点,将key值赋给目标删除结点并删除最小节点)
else
{
Node* min_right_father = nullptr; //min_right_father:保存右子树最小结点的父亲结点
Node* min_right = cur->_right; //min_right:获取右子树最小结点
while (min_right->_left)
{
min_right_father = min_right;
min_right = min_right->_left;
}
cur->_key = min_right->_key; //把最小值覆盖到目标删除节点,等价于删掉了原节点
if (min_right_father == nullptr) //若仍为空,说明右子树最小节点就是cur的右孩子节点
{
cur->_right = min_right->_right;
}
else //不为空,即最小节点有父节点,父节点的左指针接最小节点的右子树
{
min_right_father->_left = min_right->_right;
}
delete min_right;
return true;
}
}
}
return false;
}
private:
//因为对象调用Print()函数时无法传_root(私有无法访问),所以在类中我们套一层_Print即可
void _Print(const Node* root)
{
if (root == nullptr)
{
return;
}
_Print(root->_left);
cout << root->_key << ":" << root->_value << endl;
_Print(root->_right);
}
//后序遍历删除所有结点
void Destroy(const Node* root)
{
if (root == nullptr)
{
return;
}
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
//前序遍历深拷贝
Node* Copy(Node* root)
{
if (root == nullptr)
{
return root;
}
Node* newroot = new Node(root->_key, root->_value);
newroot->_left = Copy(root->_left);
newroot->_right = Copy(root->_right);
//深拷贝完根结点后,将根节点的左子树放入Copy函数进行深拷贝并且用newroot->_left进行连接
//再将根节点右子树放入Copy函数进行深拷贝并且用newroot->_right进行连接
//宏观角度:函数怎么将左右子树进行深拷贝我不关心,我只知道Copy能帮我完成
return newroot;
}
private:
Node* _root = nullptr;
//提供缺省值则无需再手动实现构造函数,用编译器默认生成的即可
};
}
🐾 Test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "Binary Search.h"
void Test1()
{
//1. 插入
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
key::BSTree<int> bst1;
for (auto e : arr)
{
bst1.Insert(e);
}
bst1.Print(); //1 3 4 6 7 8 10 13 14
cout << " " << endl;
////2. 查找
//cout << bst1.Find(6) << endl; //有6,返回1(true)
//cout << bst1.Find(11) << endl; //没有11,返回0(false)
//3. 删除 // 1 3 4 6 7 8 10 13 14
bst1.Erase(3); //删掉 3 -> 1 4 6 7 8 10 13 14
bst1.Print();
bst1.Erase(8); //再删掉 8 -> 1 4 6 7 10 13 14
bst1.Print();
cout << " " << endl;
for (auto e : arr) //用于判断删除函数的实现是否成功:将所有的节点都删掉
{
bst1.Erase(e);
bst1.Print();
}
}
//int main()
//{
// Test1();
// return 0;
//}
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////
void Test2()
{
//使用key/value二叉搜索树的情况(查字典)
key_value::BSTree<string, string> dict;
//BSTree<string, string> copy = dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "输入");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
}
//
//int main()
//{
// Test2();
// return 0;
//}
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////
void Test3()
{
//使用key/value二叉搜索树的情况(存放数据的个数)
string arr[] = { "西瓜", "葡萄", "苹果", "西瓜", "哈密瓜", "苹果", "香蕉", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> countTree; //int:不同string存放的次数
/*
先查找水果是否搜索树中
- 不在,说明水果第一次出现,则插入<水果, 1>
- 在,则查找到的结点中水果对应的次数++
*/
for (const auto& str : arr)
{
//STreeNode<string, int>* ret = countTree.Find(str);
auto ret = countTree.Find(str);
if (ret == nullptr)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;//若ret不为nullptr则已经存在,Find找到结点后直接访问_value再++即可
}
}
countTree.Print();
key_value::BSTree<string, int> copy = countTree;
}
int main()
{
Test3();
return 0;
}
- 欢迎留言交流
- 期待你的评论与建议
- 留下你的想法吧

谢谢你看到这里呀
如果喜欢这篇内容,点个关注,下次更新不迷路✨
👍 点赞 ⭐ 收藏 💬 评论

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)