终于等到!这个开源语音模型能凭空捏造声音,8GB显存就能跑
摘要:VoxCPM2 开源了,我第一时间试了下,确实有点东西。不用参考音频就能凭空造声音,方言克隆也挺像那么回事,关键是本地部署门槛不高。这篇文章记录了我的安装和使用过程,给想玩的朋友做个参考。
目录
VoxCPM2 是啥玩意儿
前几天刷 GitHub 看到 VoxCPM2 开源了,说是语音大模型,我寻思着下载下来试试。用下来感觉这玩意儿确实有点意思,特别是那个"凭空捏造声音"的功能,挺好玩的。
这玩意儿跟传统的语音合成不太一样。以前那些模型都得先搞个分词器(Tokenizer),把声音切成一段一段的,结果就是生成的声音总有点机械感。VoxCPM2 直接抛弃了这套路,用的是端到端连续表征,说白了就是让模型自己学着理解声音的连续性。
实际效果就是:生成的声音情感、气息这些细节保留得比较好,听起来没那么假。
我试了下,它支持 30 种语言,还有 9 种国内方言,像四川话、粤语这些都能克隆。不过方言克隆有个前提——你得输入地道的方言文本,不然它也不知道你要啥味儿。
安装过程实录
本地部署(真的一行命令)
官方说一行命令就能装,我还真试了下,确实没骗人:
pip install voxcpm
就这么简单。不过前提是你要装好 Python 环境,这个我就不多说了,搞开发的应该都有。
硬件要求:
- 显存:8GB 起步(我用的是 RTX 3060 12GB,跑得挺顺)
- 内存:建议 16GB 以上
- 系统:Windows、macOS、Linux 都支持
安装完首次启动,它会自动下载模型文件,大概几个 GB,网速慢的话得等会儿。我家里宽带 100M,下了差不多 10 分钟。
不想部署?有在线版
如果你嫌配环境麻烦,或者电脑配置不够,可以去他们的在线体验站试试。不过在线版肯定有限制,比如时长、次数啥的,具体我没细看,反正我本地能跑就直接本地跑了。
核心功能实测
装好之后,我挨个试了下主要功能,下面说说实际体验。
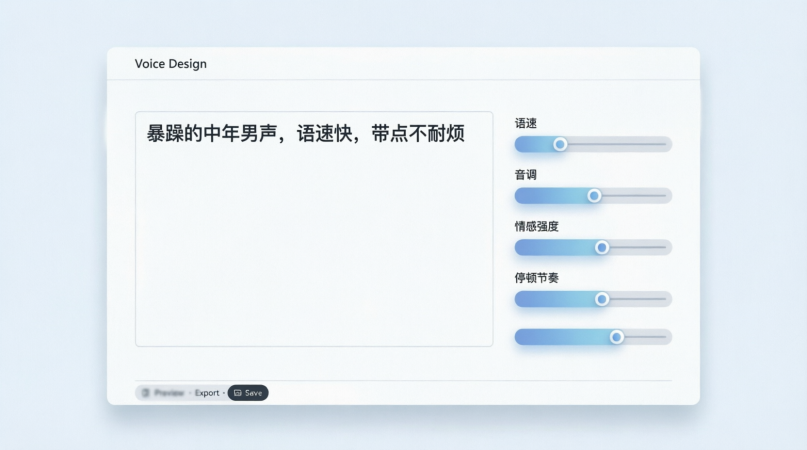
功能一:Voice Design(凭空造声音)
这个功能是我最感兴趣的——不需要任何参考音频,直接用文字描述就能生成声音。
界面挺直观的,左边输入框写描述,右边调参数。我试了几个:
测试1:暴躁中年男声
提示词:暴躁的中年男声,语速快,带点不耐烦
文本:这事儿我跟你说了多少遍了,怎么还犯这种错误?
生成出来的声音还真有那么点意思,语速确实快,语气也挺冲的,听着就像那种不耐烦的老板在训人。
测试2:温柔女主播
提示词:温柔的女声,语速中等,带点甜美
文本:欢迎收听今天的节目,我是您的主持人。
这个也挺像那么回事,声音确实比较柔和。不过我觉得跟真正的主播比还是差点味道,但作为 AI 生成已经不错了。
参数调节:
界面右边有几个滑块:
- 语速(0.5x - 2.0x)
- 音调(低 - 高)
- 情感强度(平淡 - 强烈)
- 停顿节奏(紧凑 - 舒缓)
这些参数可以微调,我一般先用默认值,听一遍再根据需要调整。
功能二:声音克隆(5秒音频就够了)
这个功能更实用——给一段 5 秒以上的纯净音频,它就能克隆出类似的声音。
我拿自己的声音试了下:
步骤:
- 用手机录了段 10 秒的语音(“你好,这是声音克隆测试”)
- 上传到 VoxCPM2
- 输入要生成的文本
- 点击生成
效果:
克隆出来的声音确实有点像我的,特别是音色那块儿。不过细听还是能听出区别,主要是语调和节奏不太一样。但总体来说,已经能达到"以假乱真"的程度了。
方言克隆测试:
我又找了个四川话的样本(我室友录的),试了下克隆四川话:
原始音频:10秒四川话("你搞啥子嘛,快点儿过来")
生成文本:今天天气好得很,我们出去耍嘛
生成的效果听着还挺有四川味儿的,我室友听了说"有点像那么回事"。不过他说有些字的发音还是不太地道,这个我估计得需要更高质量的样本才能更好。
克隆技巧:
- 音频要纯净(别带背景音乐和噪音)
- 时长 5-30 秒最佳
- 说话人语速、情绪要稳定
- 可以通过提示词调整情绪(比如"生气的"、“开心的”)
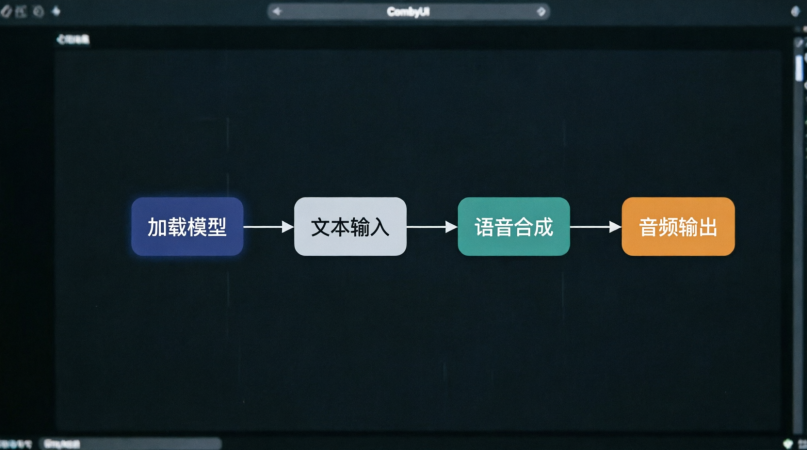
功能三:ComfyUI 集成(工作流自动化)
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
如果你用 ComfyUI,可以把 VoxCPM2 集成进去,做成自动化工作流。
我配置的流程:
- 文本输入节点(输入要合成的文字)
- VoxCPM2 节点(加载模型、生成语音)
- 音频输出节点(保存为 WAV/MP3)
这样配置好后,每次生成语音就点一下执行就行,不用反复操作界面,批量生成视频配音的时候特别方便。
配置方法:
# 安装 ComfyUI VoxCPM2 节点
cd ComfyUI/custom_nodes
git clone https://github.com/xxx/ComfyUI-VoxCPM2
pip install -r requirements.txt
(具体节点地址我记不太清了,可以去 GitHub 搜一下)
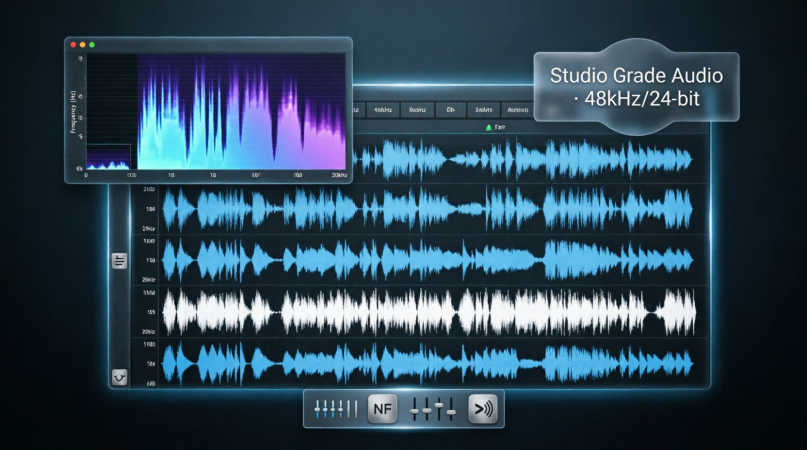
功能四:48kHz 高保真输出

这个功能对做音频后期的人来说挺重要的。VoxCPM2 支持 48kHz/24-bit 的录音室级音质,我导出来用 Audacity 看了下频谱,确实挺干净的。
对比测试:
- 22kHz 版本:听着还行,但高频部分有点糊
- 44.1kHz 版本:CD 音质,够用了
- 48kHz 版本:细节更丰富,适合专业用途
不过高音质也意味着文件更大,48kHz 的文件体积是 22kHz 的两倍多。如果就是做个短视频配音,22kHz 或 44.1kHz 就够了,没必要上 48kHz。
一些使用心得
用了一周,说说我的感受吧。
优点:
- 安装简单:pip install 就完事儿,不像有些 AI 工具配环境配半天
- 门槛不高:8GB 显存就能跑,我的老 3060 也能用
- 功能实用:Voice Design 和声音克隆都挺好用
- 音质不错:48kHz 输出确实专业
- 方言支持:四川话、粤语这些都能克隆,这点挺难得
不足:
- 方言需要地道样本:如果样本不地道,生成出来也不像
- 情感控制还不够精细:虽然能调参数,但想精确控制某个词的情绪还是有点难
- 长文本偶尔卡顿:超过 500 字的文本生成时,偶尔会卡一下,不知道是不是我电脑的问题
- 文档以英文为主:中文文档不够全,有些高级功能得看英文文档
适用场景:
我觉得 VoxCPM2 适合这些人:
- 视频创作者(需要配音但又不想自己录)
- 播客制作人(生成片头片尾)
- 游戏开发者(NPC 语音)
- 有声书制作(批量生成章节)
- 方言保护(记录和克隆方言)
不太适合的:
- 追求完美音质的专业配音(目前还是不如真人)
- 需要实时合成的场景(生成速度还不够快)
性能数据:
我简单测了下性能(RTX 3060 12GB):
| 文本长度 | 生成时间 | 显存占用 |
|---|---|---|
| 50字 | 约5秒 | 6GB |
| 200字 | 约15秒 | 7GB |
| 500字 | 约40秒 | 8GB |
生成速度还行,但不是实时的。如果要做长音频,建议分段生成再拼接。
一些坑:
- 首次启动慢:第一次运行要下载模型,耐心等待
- 中文文本要用中文标点:我用英文逗号它识别不了,换成中文就好了
- 特殊字符会报错:文本里别带 emoji 啥的,它会懵
- 批量生成要排队:一次只能生成一个,想批量得写脚本
后续计划:
我打算试试这几个方向:
- 批量生成短视频配音(看看效率咋样)
- 克隆几个不同音色,做个声音库
- 研究下能不能微调模型,让它更懂我的需求
总结
VoxCPM2 这个工具,我觉得对普通用户来说已经够用了。特别是 Voice Design 功能,不用录音频就能生成各种声音,做视频配音挺方便的。
声音克隆的效果也不错,5 秒音频就能克隆,虽然跟真人比还有差距,但日常使用完全够了。方言支持是个亮点,不过得找地道的样本才行。
本地部署门槛不高,8GB 显存就能跑,这点比很多 AI 工具友好。如果你做视频、播客啥的,需要经常生成配音,这个工具值得试试。
资源链接:
- GitHub:github.com/infi-sys/voxcpm2
- 在线体验:voxcpm.com(需要注册)
- 文档:docs.voxcpm.com

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)