Obsidian + LLM Wiki 落地指南:从零搭建你的 AI 知识库
这篇是实操篇:怎么用 Obsidian + LLM 把这套模式跑起来。
不需要任何编程基础,跟着做就行。
如果你想快速上手,本文所述的内容已经在我的【llm-wiki】项目中完整实现,包含开箱即用的 Skill 定义、自动化脚本和规范模板。欢迎 Star 和关注,一起让知识持续生长。
我的LLM-Wiki项目:https://github.com/guanyang/llm-wiki
为什么是 Obsidian
在 LLM Wiki 模式中,你需要一个能浏览和管理 markdown 文件的工具。理论上任何文本编辑器都行,但 Obsidian[1] 是目前最合适的选择:
- • 纯本地存储:所有数据都是本地的
.md文件,没有云端锁定,随时可以用 Git 管理版本 - • 双向链接:原生支持
[[双链]]语法,这正是 wiki 页面之间交叉引用的基础 - • 图谱视图:可视化展示页面之间的关联关系,一眼看清知识结构
- • 插件生态:Dataview、Web Clipper 等插件完美配合 LLM Wiki 的工作流
用 Karpathy 的比喻:Obsidian 是"IDE",LLM 是"程序员",wiki 是"代码库"。你在 Obsidian 里浏览和审阅,LLM 负责编写和维护。
与传统 RAG 的区别
| 维度 | 传统 RAG | LLM Wiki |
|---|---|---|
| 知识存储 | 原始文档 + 向量索引 | 结构化、互相链接的 Markdown 页面 |
| 查询方式 | 每次从零检索、拼凑 | 基于已编译的知识综合回答 |
| 知识积累 | 无——每次重新推导 | 有——每次操作都让 wiki 更丰富 |
| 交叉引用 | 无 | 自动维护的 [[双链]] 网络 |
| 矛盾处理 | 不感知 | 主动标注、注明来源 |
LLM Wiki架构
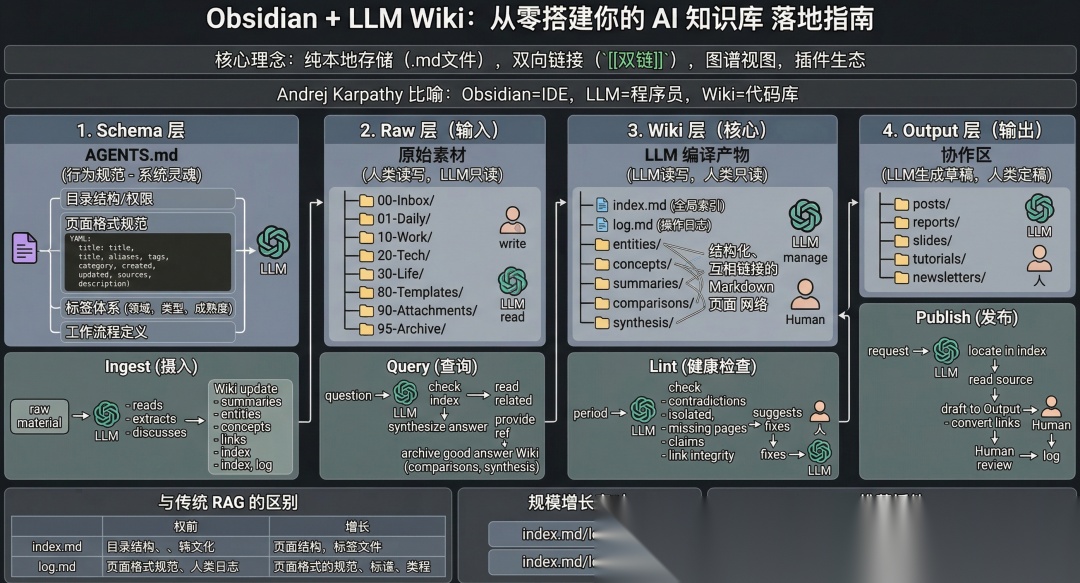
第一步:安装 Obsidian
从 obsidian.md[1] 下载安装,支持 macOS、Windows、Linux 和移动端。
打开后选择 Create new vault,起个名字(比如 my-wiki),选一个本地文件夹。Vault 就是一个普通文件夹,没有任何私有格式。
第二步:搭建目录结构
LLM Wiki 采用四层架构,每层职责清晰。在 vault 根目录下创建以下结构:
my-wiki/├── AGENTS.md # Schema:LLM 的行为规范├── skills/ # Agent Skill:工作流详细规则│ └── llm-wiki/ # LLM Wiki skill(按需加载)├── raw/ # 原始素材(人类写入,LLM 只读)│ ├── 00-Inbox/ # 快速收集箱│ ├── 01-Daily/ # 每日笔记│ ├── 10-Work/ # 工作相关│ ├── 20-Tech/ # 技术知识│ ├── 30-Life/ # 生活日常│ ├── 80-Templates/ # 笔记模板│ ├── 90-Attachments/ # 图片、PDF 等附件│ └── 95-Archive/ # 归档区├── wiki/ # LLM 编译产物(LLM 读写)│ ├── index.md # 全局索引(含 confidence、status)│ ├── log.md # 操作日志(最近 30 天)│ ├── lifecycle.md # 【可插拔】生命周期数据│ ├── entities/ # 实体页(工具、框架、人物)│ ├── concepts/ # 概念页(设计模式、方法论)│ ├── summaries/ # 素材摘要页│ ├── comparisons/ # 对比分析页│ └── synthesis/ # 综合分析页└── output/ # 成品输出(LLM 生成,人类审核) ├── posts/ # 博客文章 ├── reports/ # 研究报告 ├── slides/ # 演示文稿(Marp) ├── tutorials/ # 教程指南 └── newsletters/ # 知识简报
几个关键点:
- • raw/ 是你的领地,LLM 绝不修改这里的任何文件。你的笔记、剪藏、日记都放这里。
- • wiki/ 是 LLM 的领地,它负责创建和维护所有页面。你只浏览,不手动编辑。
- • output/ 是协作区,LLM 生成草稿,你审核定稿。
- •
raw/下的子目录可以根据你的实际需要增减,上面只是一个参考模板。
第三步:配置 Obsidian
打开 Obsidian 设置(左下角齿轮图标),调整以下几项:
附件路径:Settings → Files & Links → Default location for new attachments → 选择 “In the folder specified below”,路径填 raw/90-Attachments。这样你粘贴的截图、拖入的文件会统一存放。
每日笔记:Settings → Core plugins → 启用 Daily notes → New file location 设为 raw/01-Daily,Date format 设为 YYYY-MM-DD。
模板(可选):Settings → Core plugins → 启用 Templates → Template folder location 设为 raw/80-Templates。
第四步:安装推荐插件
进入 Settings → Community plugins → 点击 “Turn on community plugins” → Browse,搜索并安装以下插件:
Dataview(强烈推荐)
Dataview 可以对 wiki 页面的 YAML frontmatter 执行类 SQL 查询,动态生成表格和列表。
安装后,你可以在任意 markdown 文件中写查询。比如列出所有最近更新的 wiki 页面:
```dataviewTABLE description, updatedFROM "wiki"SORT updated DESCLIMIT 10```
或者按标签分类查看概念页:
```dataviewLIST descriptionFROM "wiki/concepts"WHERE contains(tags, "AI")```
LLM Wiki 的每个页面都有规范的 frontmatter(title、tags、category、created、updated、sources、description),这让 Dataview 的查询非常灵活。
Obsidian Web Clipper(强烈推荐)
这是 Obsidian 官方的浏览器扩展(支持 Chrome 和 Firefox),可以一键将网页文章转为 markdown 保存到 vault。
安装后,在浏览器中看到想收藏的文章,点击扩展图标,选择保存到 raw/00-Inbox/。文章会自动转为 markdown 格式。
一个小建议:剪藏后在 Obsidian 中打开文件,用"Download images locally"功能把图片下载到 raw/90-Attachments/,避免外链失效。
Excalidraw(可选)
手绘风格的图表工具,适合画架构图、流程图。如果你喜欢在笔记中画图,装上它。
Marp Slides(可选)
基于 markdown 生成幻灯片。如果你经常需要从知识库内容做汇报或分享,这个插件可以让你直接在 Obsidian 中写幻灯片,用 --- 分页,所见即所得。
第五步:编写 Schema 文件
Schema 是整个系统的灵魂——它告诉 LLM 如何维护你的 wiki。在 vault 根目录创建 AGENTS.md(通用)或 CLAUDE.md(Claude 专用),内容包括四个部分,把规则告诉LLM,让其帮忙生成Schema文件,再不断微调即可:
1. 目录结构和权限
告诉 LLM 每个文件夹的用途和读写权限。最重要的规则:raw 只读,wiki 读写,绝不修改原始素材。
2. 页面格式规范
定义每个 wiki 页面必须包含的 YAML frontmatter:
---title: 页面标题aliases: [别名1, 别名2]tags: [领域标签, 类型标签]category: entities | concepts | summaries | comparisons | synthesiscreated: YYYY-MM-DDupdated: YYYY-MM-DDsources: - "[[raw/路径/源文件名]]"description: 一句话摘要,不超过100字---
3. 标签体系
预定义一套标签,从三个维度选取:
- • 领域标签:AI、软件工程、数据库、架构、知识管理……
- • 类型标签:工具、框架、模式、概念、人物、对比分析……
- • 成熟度标签(可选):成熟、新兴、实验性、已废弃
标签用中文还是英文,取决于你的偏好,但要保持一致。
4. 工作流程定义
定义三个核心操作的具体步骤:
Ingest(摄入):读取素材 → 提取关键信息 → 与用户讨论 → 创建摘要页 → 更新实体/概念页 → 维护交叉引用 → 更新 index.md → 记录 log.md
Query(查询):读取 index.md 定位页面 → 阅读相关页面 → 合成答案 → 提供引用 → 询问是否存档
Lint(健康检查):矛盾检测 → 孤立页面 → 缺失概念页 → 过时声明 → 交叉引用完整性 → 生成修复建议
Publish(发布):确认输出类型和受众 → 从 index.md 定位相关 wiki 页面 → 阅读来源页面 → 生成草稿到 output/ 对应子目录 → 将 [[双链]] 转为标准 Markdown 链接(成品必须独立可读)→ 用户审核修改 → 记录 log.md
Refresh(联网重校验):针对怀疑过时的主题 → 联网检索最新信息 → 对比差异 → 用户确认后存为新 raw 素材 → 重新 ingest 更新 wiki
不需要一次写到完美。先写一个最小版本,用起来之后根据实际体验逐步迭代。Schema 本身就是人类和 LLM 共同演进的产物——你用着觉得哪里不顺,就改哪里。
第六步:初始化 Wiki
在 wiki/ 下创建两个基础文件:
wiki/index.md——全局索引:
# Wiki Index> 最后更新:YYYY-MM-DD | 页面总数:N | 素材总数:M## Entities- [[Obsidian]] - 基于本地 markdown 的知识管理工具 (sources: 1)## Concepts- [[RAG]] - 检索增强生成,LLM + 文档交互的主流方式 (sources: 1)## Summaries- [[raw-articles-llm-wiki]] - Karpathy 的 LLM Wiki 模式完整阐述 (2026-04-12)## Comparisons- [[LLM-Wiki-vs-RAG]] - LLM Wiki 模式与传统 RAG 的对比分析 (sources: 1)## Synthesis- [[index与log的扩展性分析]] - index.md 和 log.md 随规模增长的瓶颈及分阶段应对策略
wiki/log.md——操作日志:
# Wiki Log## [YYYY-MM-DD] ingest | 素材标题- 来源:`raw/路径/文件名`- 新建:[[页面1]]、[[页面2]]- 更新:[[页面3]](新增xxx章节)- 更新:index.md## [YYYY-MM-DD] query | 查询问题- 查阅:[[页面1]]、[[页面2]]- 产出:[[对比分析页]](已存入 wiki)## [YYYY-MM-DD] lint | 健康检查- 发现矛盾:[[页面A]] 与 [[页面B]] 关于xxx的描述不一致- 孤立页面:[[页面C]](无入链)- 缺失概念页:建议创建 [[概念X]]- 已修复:N 项 | 待修复:M 项## [YYYY-MM-DD] publish | 成品标题- 类型:post | report | slides | tutorial | newsletter- 输出:`output/posts/文件名.md`- 来源:[[wiki 页面1]]、[[wiki 页面2]]、...- 状态:草稿 | 已审核
这两个文件是 LLM 的导航入口。index.md 是内容导向的目录,log.md 是时间导向的操作记录。LLM 每次操作都会更新它们。
第七步:第一次 Ingest
万事俱备,开始消化第一篇素材。
-
- 把一篇你想消化的文章保存到
raw/00-Inbox/(用 Web Clipper 剪藏,或手动复制 markdown)
- 把一篇你想消化的文章保存到
-
- 打开你的 LLM 对话工具,把
AGENTS.md和素材文件的内容一起给它
- 打开你的 LLM 对话工具,把
-
- 说:“请消化这篇文章,按照 AGENTS.md 的规范执行 ingest。”
LLM 会:
- • 读取全文,提取关键信息
- • 向你汇报关键发现,确认重点
- • 创建摘要页(
wiki/summaries/) - • 创建或更新实体页(
wiki/entities/)和概念页(wiki/concepts/) - • 在页面之间建立
[[双链]]交叉引用 - • 更新
wiki/index.md和wiki/log.md
一次 ingest 可能触发 10-15 个文件的创建或更新——这正是人类不愿意做、但 LLM 毫不费力的事情。
完成后,回到 Obsidian 刷新,你会看到新生成的 wiki 页面。点击双链可以在页面之间跳转,打开图谱视图可以看到知识结构正在成形。
日常使用节奏
跑通第一次 ingest 之后,日常使用就很自然了:
收集:碰到好文章 → Web Clipper 一键剪藏到 raw/00-Inbox/ → 有空时告诉 LLM “ingest 这篇”
查询:有问题想查 → 告诉 LLM “查一下 xxx” → LLM 查阅 wiki 已编译的知识回答 → 好答案存回 wiki(对比分析存 comparisons/,综合洞察存 synthesis/)
维护:每周或每月告诉 LLM “做一次 lint” → 检查矛盾、孤立页面、缺失引用、过时声明 → 确认后 LLM 自动修复
输出:需要写博客或做汇报 → 告诉 LLM “把 xxx 主题整理成博客” → LLM 从 wiki 提炼成品到 output/ → 你审核定稿
关键心态:不需要一次消化所有存量笔记。从今天开始,每次碰到新素材就 ingest 一篇,wiki 会自然生长。存量笔记可以在需要时按需消化。
规模增长怎么办
一个常见的担忧:wiki 越来越大,index.md 和 log.md 会不会撑不住?
实际上这个问题来得比想象中晚:
| 阶段 | 页面数 | 状态 |
|---|---|---|
| 起步期 | < 300 | 单文件 index.md 完全够用,不需要任何改动 |
| 中期 | 300-1000 | 可以把 index 拆分为分类子索引(index-entities.md、index-concepts.md),主 index 保留入口 |
| 后期 | 1000+ | 引入 qmd[2] 语义搜索(支持 BM25 + 向量混合搜索,全部本地运行),index 降级为辅助导航;用 Dataview 从 frontmatter 动态生成视图 |
log.md 更简单:按年归档即可。年初把上一年的 log 移入 wiki/logs/log-YYYY.md,当前 log 重新开始。
而且,这些优化操作本身也可以交给 LLM 执行,几分钟就能完成。
常见问题
Q:我已经有很多 Obsidian 笔记了,怎么迁移?
把现有笔记放到 raw/ 对应的子目录下即可。不需要一次性全部 ingest,按需消化。LLM Wiki 的 raw 层本来就是为了容纳你已有的笔记。
Q:LLM 生成的 wiki 页面质量不好怎么办?
调整 Schema。Schema 是你和 LLM 之间的"合同",如果输出不符合预期,大概率是 Schema 的描述不够清晰。迭代几次就会越来越好。
Q:多设备同步怎么办?
Obsidian vault 就是一个普通文件夹,用 Git、iCloud、Syncthing、Obsidian Sync 都可以同步。推荐 Git——既能同步,又有版本历史。
Q:能不能多人协作?
可以。多人共享同一个 Git 仓库,各自往 raw/ 放素材,通过 LLM 统一消化进 wiki。Schema 文件是共享的规范。
Q:和 NotebookLM 比有什么优势?
NotebookLM 是典型的 RAG 模式——扔文件进去就能问,但知识不会积累。LLM Wiki 需要多一步 ingest,但换来的是持续复利的知识库。判断标准:这个知识以后还会用到吗?会 → LLM Wiki;不会 → NotebookLM 问完即走。
小结
整个搭建过程大约 30 分钟:装 Obsidian、建目录、装插件、写 Schema、初始化 wiki、跑第一次 ingest。之后就是日常的收集-消化-查询-输出循环。
最重要的不是一开始就搭建完美的系统,而是开始用起来。Schema 会迭代,目录会调整,标签会演化——这些都是正常的。LLM Wiki 的核心价值在于:每一次 ingest 和 query 都让知识库变得更丰富,知识在持续复利。
开始养你的知识花园吧。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献227条内容
已为社区贡献227条内容

所有评论(0)