基于深度学习的辣椒叶片病害识别系统设计实现,融合CBAM注意力机制的改进ResNet-50模型和YOLO检测,准确率达96%
第1章 引言
1.1 选题背景及意义
1.1.1 选题背景
近年来,国家高度重视农业智能化发展,持续加大对智慧农业的政策支持力度。2026年1月,由天津农学院与天水市农业科学研究所联合承担的中央引导地方科技发展资金项目——“融合人工智能与大数据的辣椒病虫害精准识别与智慧防控技术研究”正式启动。该项目旨在通过人工智能与大数据技术推动辣椒产业提质增效,为东西部科技协作提供示范,标志着人工智能技术在辣椒病虫害识别领域的应用已进入实质性推进阶段。与此同时,农业农村部在2026年种植业行业标准申报工作中,明确将“蔬菜作物的病虫害绿色防控”列为重点支持方向,强调通过标准化生产技术提升作物抗病虫能力,为智能化识别与绿色防控技术的融合发展提供了政策指引。
1.1.2 选题意义
当前,国内外已有部分作物病害识别系统投入应用,但现有研究仍存在以下不足:一是识别对象多集中于大宗粮食作物,针对甜椒这类高附加值经济作物的专用系统较少,且病害类别覆盖不全,缺乏炭疽病、霜霉病等常见病害的识别能力;二是多数模型在实验室背景下表现优异,但在实际农田复杂环境(光照变化、背景干扰、叶片重叠)中鲁棒性下降,难以满足生产一线的实时诊断需求;三是现有系统功能单一,多为“识别即结束”,缺乏配套的病害知识库、防治建议及数据统计分析功能,无法形成“识别-预警-防治”的业务闭环;四是模型更新机制不完善,用户无法参与样本扩充与模型优化,导致系统长期使用后识别性能难以持续提升。
1.2 国内外发展现状
植物叶片病害识别系统是智慧农业的重要组成部分,其核心目标是通过图像处理与模式识别技术对作物病害进行快速、准确的诊断。近年来,深度学习技术的迅猛发展为这一领域带来了革命性突破。传统的机器学习方法依赖手工特征提取,在复杂环境下的泛化能力有限;而基于深度卷积神经网络(CNN)的方法能够自动学习病害特征,在多个公开数据集上取得了超越人工的识别精度。当前的研究趋势主要集中在以下几个方面:一是网络结构的创新,如引入残差连接、注意力机制、轻量化设计等;二是训练策略的优化,包括迁移学习、数据增强、超参数调优等;三是多任务学习的融合,将病害识别与严重程度分级、目标检测相结合;四是模型部署的轻量化,以适应移动端和嵌入式设备的实时应用需求。
1.3 论文研究目标和内容
本研究旨在构建一套基于深度学习的甜椒叶片病害智能识别系统,实现对多种常见病害的快速、准确识别,为智慧农业中的病害防控提供技术支撑。研究内容主要包括:构建涵盖13类甜椒叶片病害的高质量数据集,通过实地采集与公开数据整合,并进行数据增强与预处理;设计融合CBAM注意力机制的改进ResNet-50模型,引入Focal Loss损失函数以缓解类别不平衡问题;开展多组对比实验验证模型的有效性与鲁棒性,利用Grad-CAM进行可解释性分析;开发前后端分离的Web识别系统,集成YOLO叶片检测、病害分类、知识库查询、数据统计等功能,实现从图像上传到防治建议的全流程服务。
第2章 系统需求分析
2.1 系统功能需求分析
2.1.1 甜椒种植户需求分析
本系统为甜椒叶片病害智能识别系统,主要服务于甜椒种植户,旨在帮助他们快速、准确地诊断甜椒叶片病害,获取科学的防治建议,从而提高甜椒产量与品质。对于甜椒种植户而言,系统需要提供简洁易用的操作界面和直观的识别结果,满足其在田间地头实时检测病害的需求。具体功能需求包括:
用户认证:种植户需要注册并登录系统,以保存个人识别记录和偏好设置。
图像上传:支持种植户通过手机或电脑拍摄或上传甜椒叶片图像,可单张或批量上传。
病害识别:系统自动对上传图像进行分析,识别病害类型并输出置信度。
结果展示:以图文形式展示识别结果,包括病害名称、置信度、各类别概率分布、热力图以及防治建议。
历史记录:种植户可查看以往的识别记录,便于跟踪病害发展情况。
知识库查询:提供病害百科查询功能,种植户可按病害名称或症状关键词检索相关知识和防治方法。
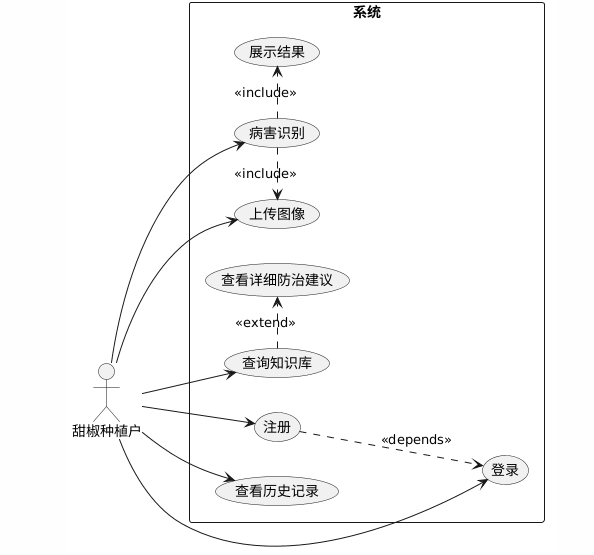
图3.1 用户用例图
2.1.2 系统管理员需求分析
系统管理员负责后台管理、数据维护和系统配置,是保障系统稳定运行和持续优化的关键角色。对于管理员而言,系统需要提供完善的管理功能,使其能够对用户、样本数据、模型版本和知识库进行有效管理,确保系统的安全性、可靠性和可扩展性。具体功能需求包括:
用户管理:管理员可以查看所有注册用户的列表,进行用户信息的查询、编辑、删除操作;可设置或撤销用户的管理员权限;监控用户活跃状态。
样本管理:管理员可上传新的训练样本图像,按病害类别进行分类存储;支持批量上传和格式校验;查看现有样本的类别分布和数量统计。
模型管理:管理员可查看模型版本历史,包括版本号、准确率、训练样本数、创建时间等信息;可激活或切换当前使用的模型版本;可启动模型训练任务,并监控训练进度和状态。
知识库管理:管理员可添加、编辑、删除病害知识条目,包括病害名称、症状描述、发病原因、发病规律、防治方法等内容;支持知识库的全文检索和批量导入导出。
系统监控:管理员可查看系统运行状态,包括总用户数、总识别次数、今日识别数等统计指标;可查看系统日志,监控异常情况。
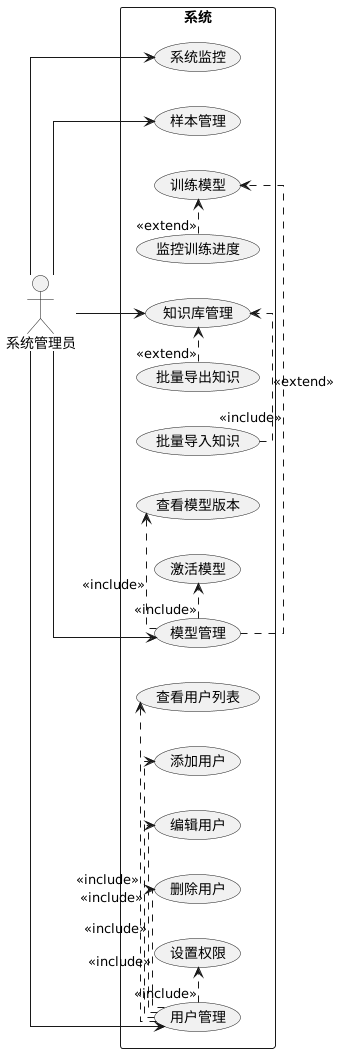
图3.2 管理员用例图
第3章 系统设计
3.1 系统总体设计
3.1.1 系统架构设计
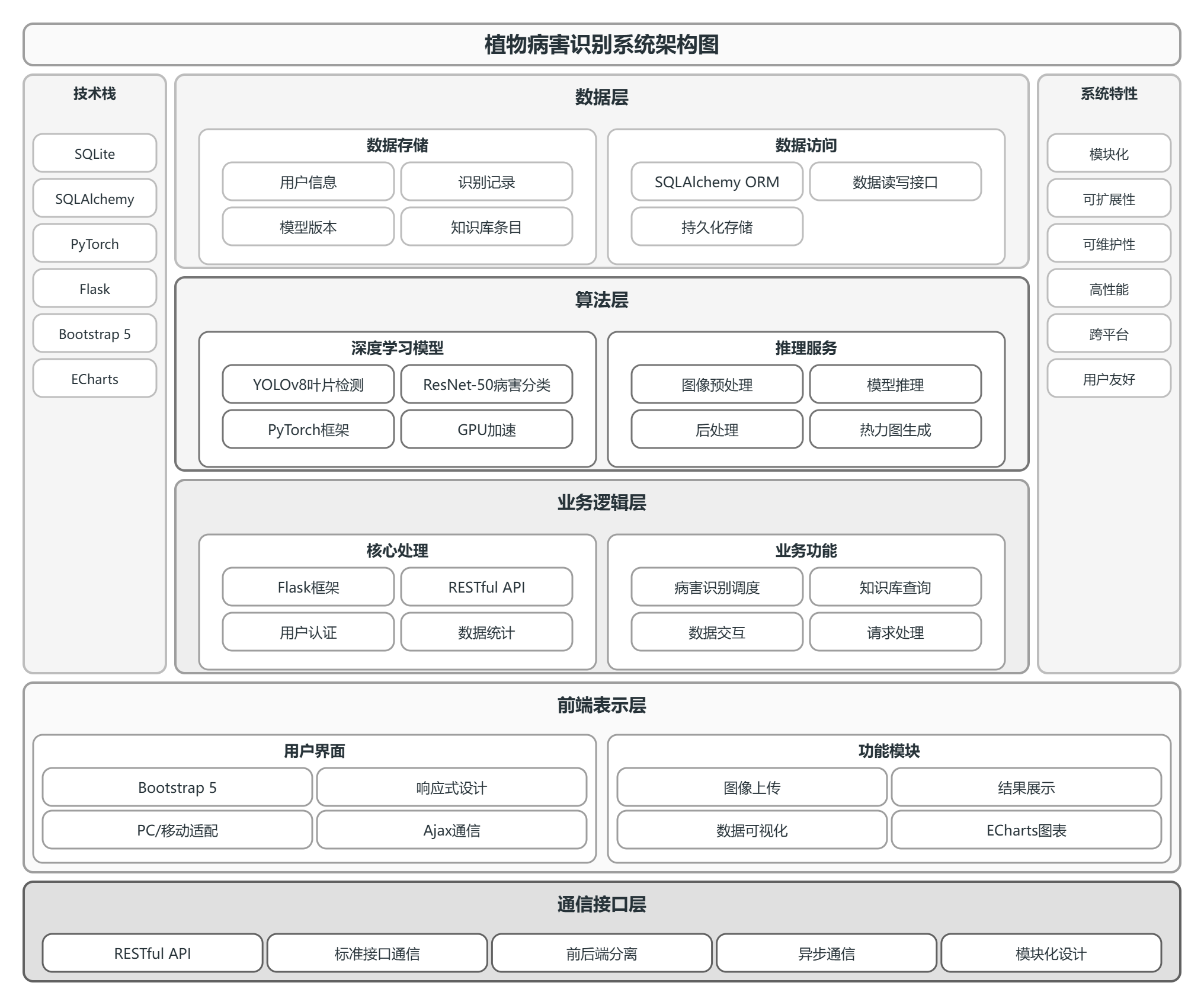
图3.1 系统架构图
本系统采用前后端分离的分层架构,自下而上依次为数据层、算法层、业务逻辑层和前端表示层,各层之间通过标准接口进行通信,确保系统的模块化、可扩展性和可维护性。系统架构如图3-1所示。
数据流向为:用户通过前端界面上传图像,请求发送至业务逻辑层;业务逻辑层调用算法层进行推理,算法层返回识别结果;业务逻辑层将结果存储至数据层,并向前端返回处理后的数据;前端接收结果并渲染展示。该分层架构有效分离了关注点,便于后续功能扩展和模型迭代。
3.1.2 系统总体功能设计
根据第2章的需求分析,系统划分为五大核心功能模块:用户管理模块、病害识别模块、知识库模块、数据统计模块和后台管理模块。系统功能结构如图3-2所示,各模块协同工作,共同完成甜椒叶片病害的智能识别与管理服务。
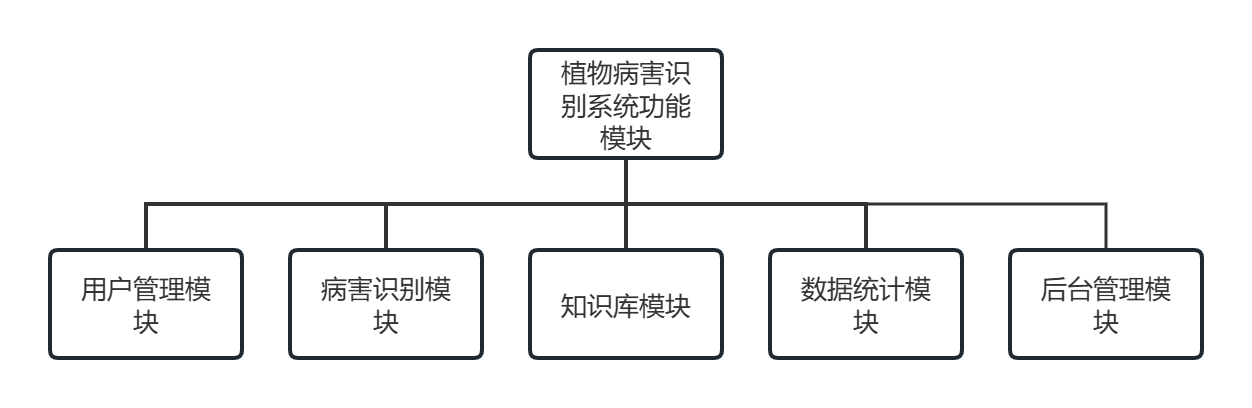
图3.2 系统功能结构图
3.2 系统功能模块设计
根据系统功能结构图(图3-2),系统划分为用户管理、病害识别、知识库、数据统计和后台管理五大核心模块,各模块的子功能设计如下。
3.2.1 用户管理模块设计
用户管理模块面向甜椒种植户和系统管理员,提供用户身份认证与权限控制功能。
用户管理模块的功能结构如图3-3所示。
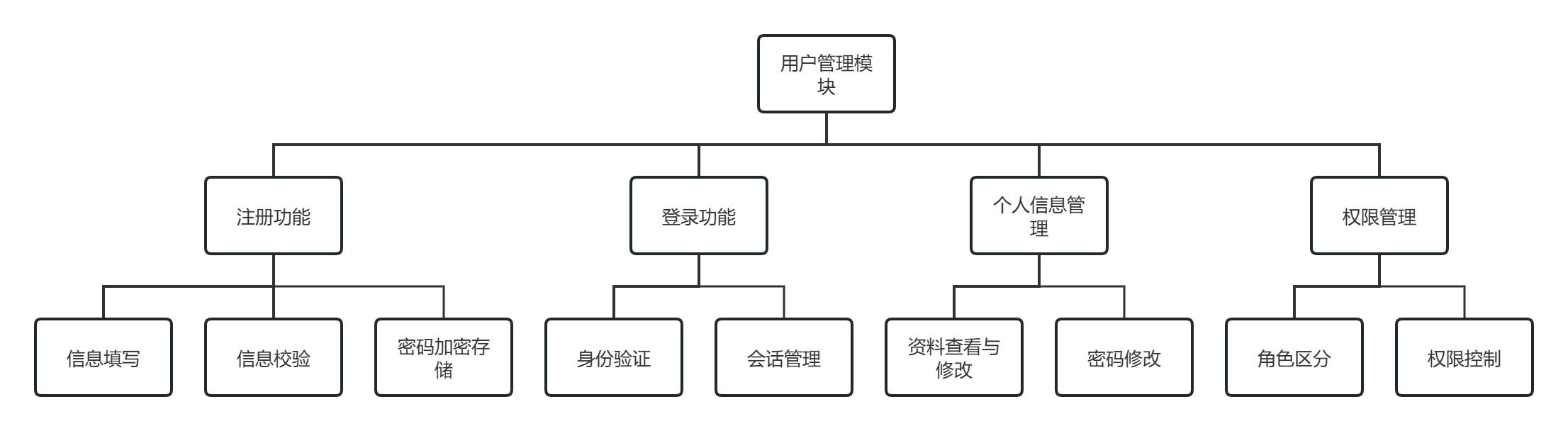
图3.3 系统功能结构图
3.2.2 病害识别模块设计
病害识别模块是系统的核心功能,为种植户提供从图像上传到结果展示的全流程服务。
病害识别模块的功能结构如图3-4所示。
为清晰描述用户与系统的交互流程,绘制病害识别活动流程图(图3-5),展示用户、前端、后端、算法层和数据库之间的协作关系。用户上传图像后,前端发起请求,后端接收图像并调用算法层进行检测与分类,最后将结果返回前端并存入数据库。
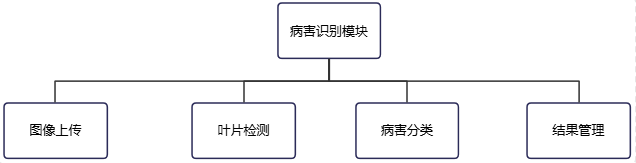
图3.4 病害识别模块功能结构图
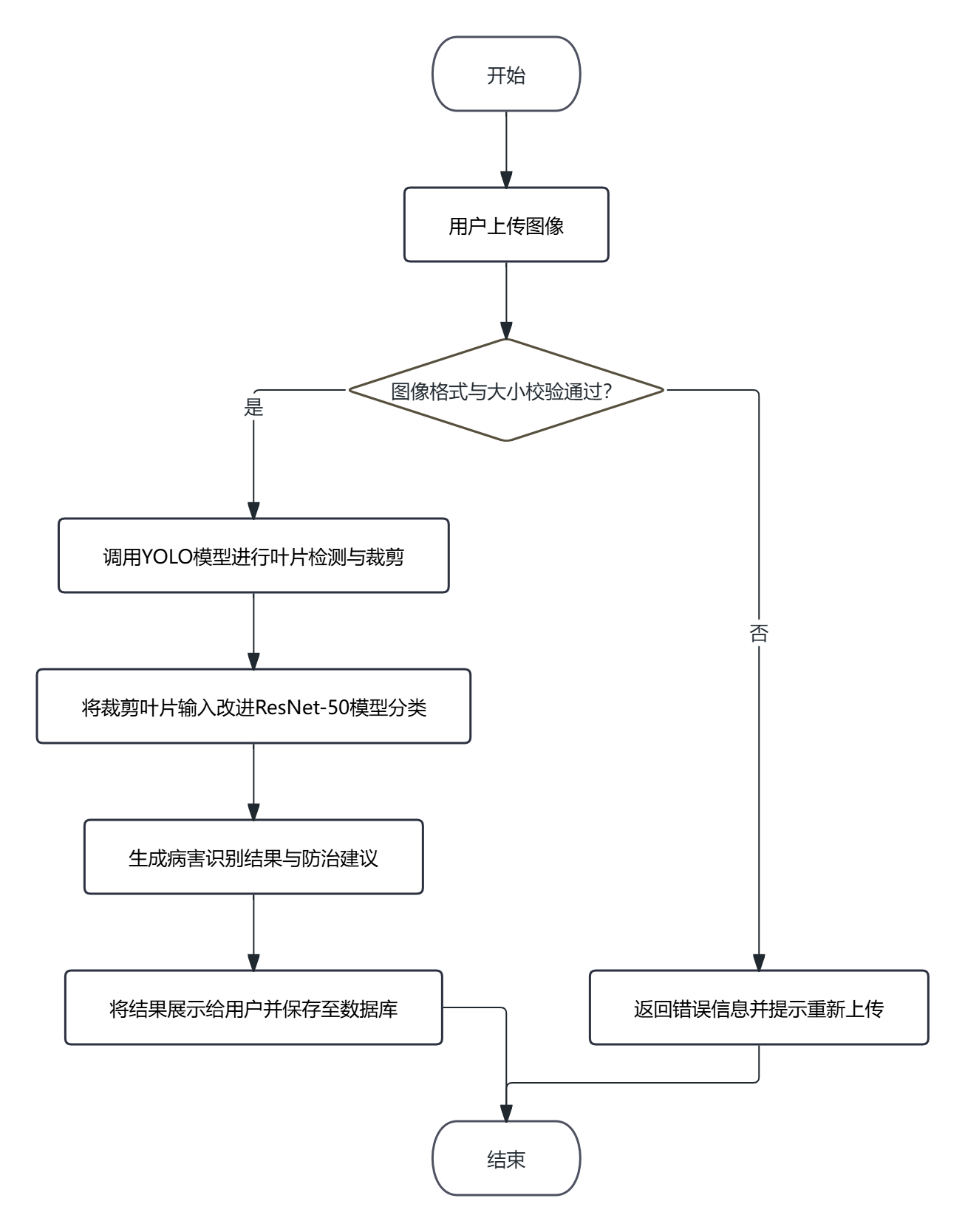
图3.5 病害识别活动流程图
3.2.3 知识库模块设计
知识库模块为种植户提供病害百科知识和防治指导
知识库模块的功能结构如图3-6所示。
图3.6 知识库模块的功能结构图
3.2.4 数据统计模块设计
数据统计模块对识别记录进行多维度分析,为种植户和管理员提供数据可视化支持。
数据统计模块的功能结构如图3-7所示。
3.2.5 后台管理模块设计
后台管理模块面向系统管理员,提供系统配置和数据维护功能。
后台管理模块的功能结构如图3-8所示。
3.3 数据库设计
3.3.1 数据库E-R模型设计
基于需求分析和功能设计,系统抽象出的核心实体包括:用户(User)、识别记录(DetectionRecord)、模型版本(ModelVersion)和知识库(KnowledgeBase)。各实体间的E-R关系如图3-9所示。
用户与识别记录之间存在一对多关系(1:n):一个用户可以拥有多条识别记录,每条识别记录仅属于一个用户。
识别记录与病害类别之间存在多对一关系(n:1):多条识别记录可对应同一种病害类别(通过病害名称关联)。
模型版本与识别记录无直接关系,独立存储。
知识库与病害类别存在一对一关系(1:1):每种病害对应一条知识条目。
图3-9中,矩形框表示实体,菱形框表示关系,连线上的标记表示关系类型(1或n)。
图
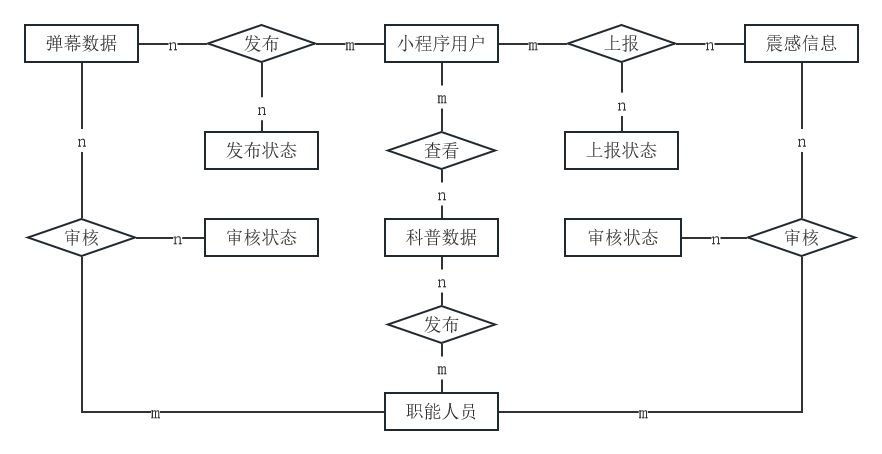 |
3.6 系统数据库E-R模型
3.3.2 实体属性设计
(1)用户实体属性设计
用户实体存储系统用户的基本信息,包括用户ID、用户名、邮箱、密码哈希值、是否管理员、创建时间等属性。用户实体属性如图3-11所示。
(2)识别记录实体属性设计
识别记录实体存储每次病害识别的详细信息,包括记录ID、用户ID(外键)、图像路径、病害名称、置信度、各类别概率、热力图路径、叶片边界框、处理耗时、创建时间等属性。识别记录实体属性如图3-12所示。
(3)模型版本实体属性设计
模型版本实体存储模型训练版本信息,包括版本ID、模型名称、版本号、模型文件路径、准确率、训练样本数、是否激活、创建时间等属性。模型版本实体属性如图3-13所示。
(4)知识库实体属性设计
知识库实体存储病害知识条目,包括知识ID、病害名称、症状描述、发病原因、发病规律、防治方法、相关图片路径、创建时间、更新时间等属性。知识库实体属性如图3-14所示。
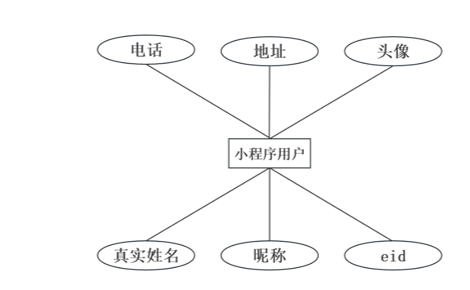
图3.7用户实体属性图
3.3.2 数据库详细表设计
根据上述实体属性设计,系统共包含4张数据表:User表、DetectionRecord表、ModelVersion表和KnowledgeBase表。各表的结构设计如下:
(1)User表(用户表)
表3.1 用户表
|
字段名 |
数据类型 |
长度 |
允许空 |
主键 |
说明 |
|
id |
INTEGER |
- |
NO |
PK |
用户ID,自增 |
|
username |
VARCHAR |
80 |
NO |
- |
用户名,唯一 |
|
|
VARCHAR |
120 |
NO |
- |
邮箱,唯一 |
|
password_hash |
VARCHAR |
128 |
NO |
- |
密码哈希值 |
|
is_admin |
BOOLEAN |
- |
NO |
- |
是否为管理员 |
|
created_at |
DATETIME |
- |
NO |
- |
创建时间 |
- DetectionRecord表(识别记录表)
表3.2 识别记录表
|
字段名 |
数据类型 |
长度 |
允许空 |
主键 |
说明 |
|
id |
INTEGER |
- |
NO |
PK |
记录ID,自增 |
|
user_id |
INTEGER |
- |
YES |
FK |
用户ID,关联User表 |
|
image_path |
VARCHAR |
256 |
NO |
- |
图像存储路径 |
|
disease_name |
VARCHAR |
50 |
NO |
- |
识别出的病害名称 |
|
confidence |
FLOAT |
- |
NO |
- |
置信度 |
|
all_probabilities |
TEXT |
- |
YES |
- |
JSON格式存储各类别概率 |
|
heatmap_path |
VARCHAR |
256 |
YES |
- |
热力图路径 |
|
leaf_bbox |
VARCHAR |
50 |
YES |
- |
叶片边界框坐标 |
|
processing_time |
FLOAT |
- |
YES |
- |
处理耗时(秒) |
|
created_at |
DATETIME |
- |
NO |
- |
识别时间 |
- ModelVersion表(模型版本表)
表3.3 模型版本表
|
字段名 |
数据类型 |
长度 |
允许空 |
主键 |
说明 |
|
id |
INTEGER |
- |
NO |
PK |
版本ID,自增 |
|
model_name |
VARCHAR |
50 |
NO |
- |
模型名称 |
|
version |
VARCHAR |
20 |
NO |
- |
版本号 |
|
model_path |
VARCHAR |
256 |
NO |
- |
模型文件路径 |
|
accuracy |
FLOAT |
- |
YES |
- |
模型准确率 |
|
training_samples |
INTEGER |
- |
YES |
- |
训练样本数 |
|
is_active |
BOOLEAN |
- |
NO |
- |
是否当前激活版本 |
|
created_at |
DATETIME |
- |
NO |
- |
创建时间 |
- KnowledgeBase表(知识库表)
表3.4 知识表
|
字段名 |
数据类型 |
长度 |
允许空 |
主键 |
说明 |
|
id |
INTEGER |
- |
NO |
PK |
知识ID,自增 |
|
disease_name |
VARCHAR |
50 |
NO |
- |
病害名称,唯一 |
|
symptoms |
TEXT |
- |
NO |
- |
症状描述 |
|
causes |
TEXT |
- |
YES |
- |
发病原因 |
|
occurrence_pattern |
TEXT |
- |
YES |
- |
发病规律 |
|
prevention_methods |
TEXT |
- |
NO |
- |
防治方法 |
|
images |
TEXT |
- |
YES |
- |
相关图片路径(JSON数组) |
|
created_at |
DATETIME |
- |
NO |
- |
创建时间 |
|
updated_at |
DATETIME |
- |
NO |
- |
更新时间 |
以上4张表通过外键关联,构成了系统的数据存储基础。User表与DetectionRecord表通过user_id建立一对多关系,其他表相互独立。数据库关系模型DMD图如图3-15所示。
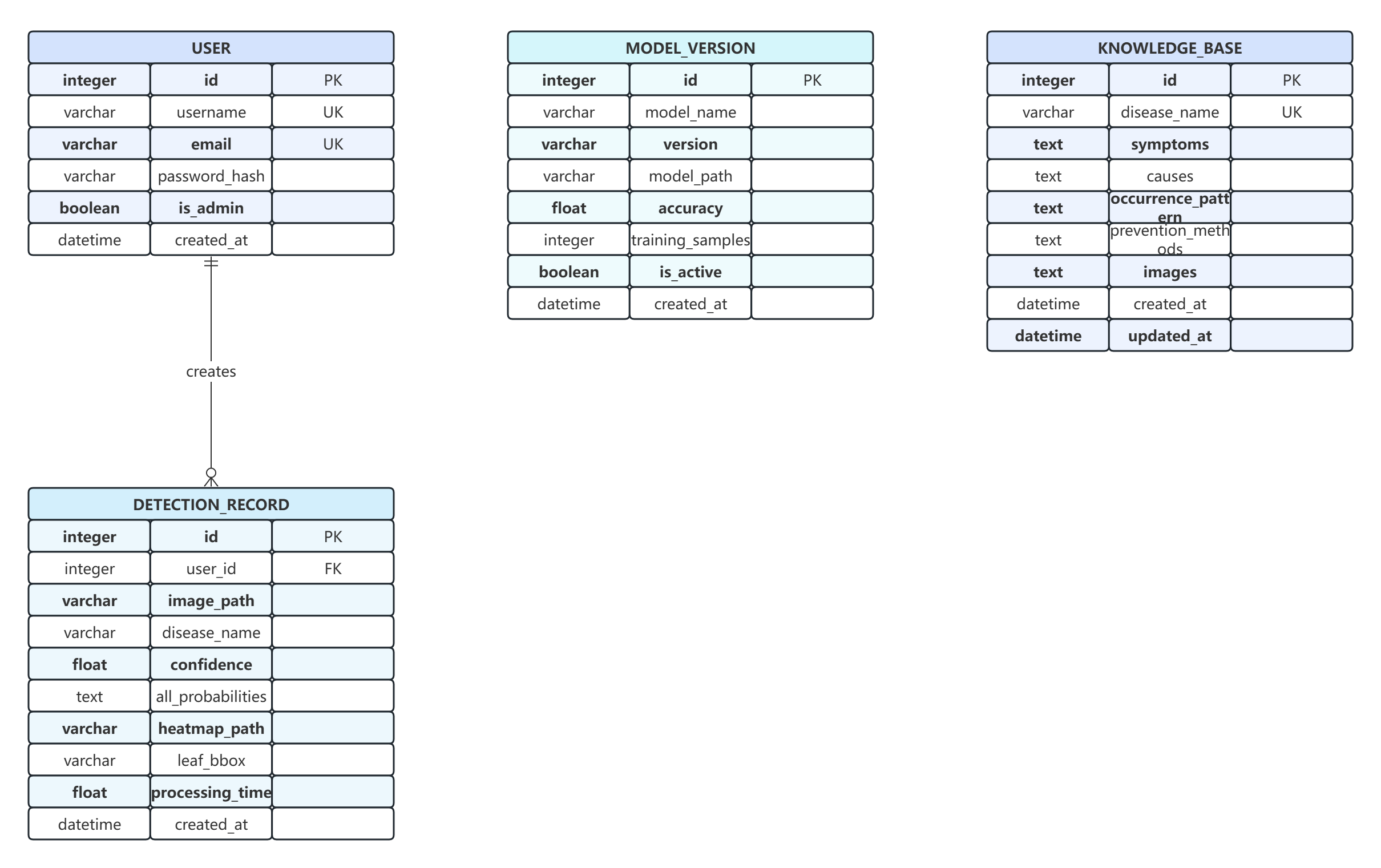
图3.15 本系统的数据库关系模型DMD图
第4章 基于改进ResNet的病害识别模型设计与实现
4.1 甜椒叶片病害数据集构建
本研究优先选用公开植物病害数据集作为基础数据来源,主要整合了以下公开数据集:
(1)PlantVillage数据集:该数据集包含14种作物、54304张叶片图像,背景单一、标注明确,是植物病害识别领域最常用的基准数据集。从中提取甜椒相关图像,包括健康(Healthy)和细菌性斑点病(Bacterial Spot)两个类别。
(2)13种辣椒病害目标检测数据集:该数据集包含辣椒炭疽病、叶斑病、病毒病等13类病害,总计66411个标注框,已标注为YOLO格式,可直接用于目标检测任务。
- Kaggle精炼叶片数据集:作为PlantVillage的精炼版本,包含约54000张图像,涵盖甜椒细菌性斑点病和健康叶片,约2500张。
4.2 图像数据处理
4.2.1 数据预处理与增强
采集到的原始图像需经过严格的清洗和标注流程,以确保数据质量:
(1)图像筛选:剔除模糊、过曝、失焦以及非目标叶片(如误拍其他作物)的图像。筛选标准包括:图像清晰度、叶片占比、病害特征可见性。
(2)类别标注:邀请植物病理学专家对图像进行病害类别标注。本数据集共包含13个类别,各类别的定义如表4.1所示。
表4.1 甜椒叶片病害数据集类别定义
|
类别名称(中文) |
类别名称(英文) |
症状描述 |
|
健康 |
Healthy |
叶片色泽均匀、无斑点或异常纹理 |
|
细菌性斑点病 |
Bacterial Spot |
叶片出现水渍状小斑点,后期扩大为褐色坏死斑 |
|
炭疽病 |
Anthracnose |
叶片呈凹陷黑斑且伴同心轮纹,后期病斑易破裂 |
|
叶斑病 |
Leaf Spot |
近圆形褐色斑点且边缘带黄色晕圈,多集中在叶片中部 |
|
白粉病 |
Powdery Mildew |
叶片正面出现白色粉状霉斑,严重时覆盖全叶 |
|
双生病毒病 |
Gemini Virus |
叶片皱缩变形,表面出现黄绿相间的斑驳状 |
|
黄化病 |
Yellowish |
叶片整体或局部变黄,叶脉可能保持绿色 |
|
营养缺乏症 |
Nutritional Deficiency |
叶片表现出缺素症状,如缺氮时老叶变黄、缺钾时叶缘焦枯 |
|
棕斑叶病 |
Daun Bercak Cokelat |
棕色或褐色斑点,形状不规则,可能伴随黄色晕圈 |
|
蚜虫危害 |
Aphid |
叶片背面有蚜虫聚集,叶片卷曲皱缩 |
|
粉虱危害 |
Whitefly |
叶片背面有白色小飞虫,叶片褪绿变黄 |
|
粘虫危害 |
Armyworm |
叶片被啃食出现缺刻或孔洞 |
|
穆尔达复合病 |
Murda Complex |
多种病害混合感染,症状复杂 |
边界框标注:对于目标检测任务,使用LabelImg工具对叶片区域进行边界框标注,保存为YOLO格式的TXT文件,每行包含类别ID和归一化的中心坐标(x, y)、宽度(w)、高度(h)。
数据增强的效果如图4-1所示。
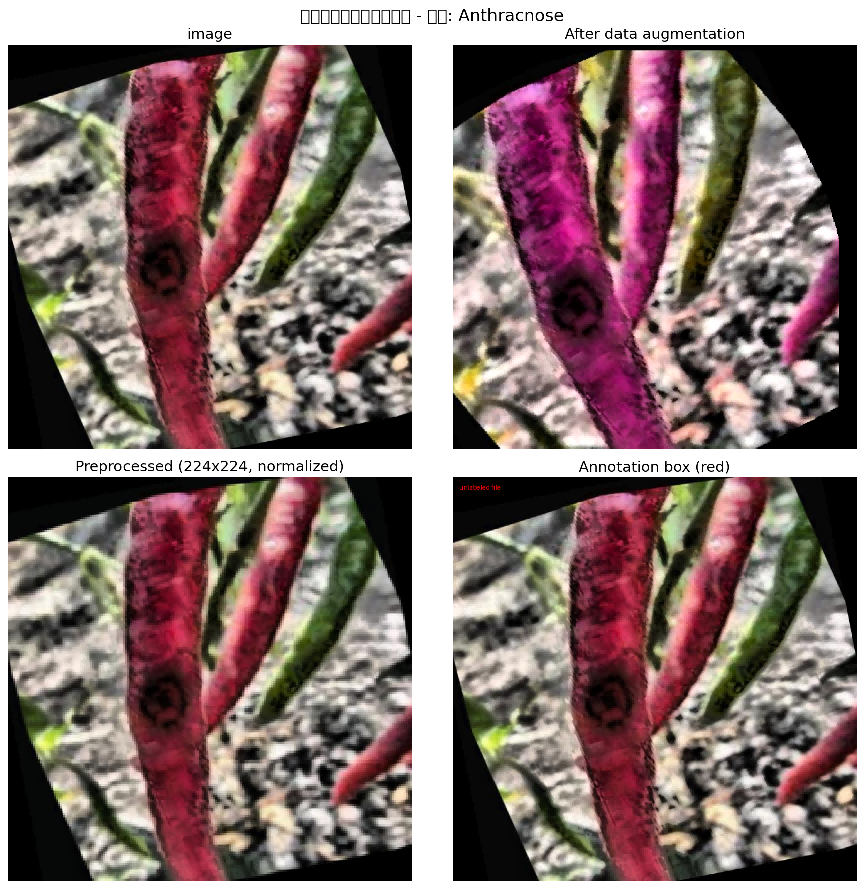
图4.1 数据增强图
4.2.1 训练/验证/测试集划分
数据集按70%、15%、15%的比例随机划分为训练集、验证集和测试集。划分时采用分层抽样(Stratified Sampling),确保各类别在三个子集中的比例与原始数据集保持一致。划分结果如表4-2所示。
表4.2 甜椒叶片病害数据集类别定义
|
数据集划分 |
样本数量(张) |
比例 |
|
训练集 |
6844 |
70% |
|
验证集 |
1467 |
15% |
|
测试集 |
1467 |
15% |
|
总计 |
9778 |
100% |
验证集用于模型训练过程中的超参数调优和模型选择,测试集仅用于最终性能评估,确保评估结果的客观性。
数据集的类别分布如表4-3所示。从表中可以看出,多数类别样本充足(如尾孢菌叶斑病2397张、健康2288张),但少数类别样本严重不足(如穆尔达复合病仅61张、白粉病91张),类别间存在严重不平衡问题。这将在后续模型设计中通过Focal Loss和加权采样加以缓解。
表4.3 甜椒叶片病害数据集类别定义
|
类别名称(中文) |
类别名称(英文) |
样本数量(张) |
|
尾孢菌叶斑病 |
Cercospora Leaf Spot |
2397 |
|
健康 |
Healthy |
2288 |
|
炭疽病 |
Anthracnose |
841 |
|
粘虫危害 |
Armyworm |
761 |
|
粉虱危害 |
Whitefly |
723 |
|
双生病毒病 |
gemini-virus |
722 |
|
黄化病 |
Yellowish |
651 |
|
棕斑叶病 |
daun-bercak-cokelat |
516 |
|
营养缺乏症 |
Nutritional Deficiency |
321 |
|
叶斑病 |
Leaf Spot |
204 |
|
蚜虫危害 |
Aphid |
202 |
|
白粉病 |
Powdery Mildew |
91 |
|
穆尔达复合病 |
Murda Complex |
61 |
|
总计 |
- |
9778 |
4.3 模型架构设计
4.3.1 主干网络与注意力机制
本研究选择ResNet-50作为主干网络,其包含49个卷积层,参数量约25.6M,在ImageNet上验证了强大的特征提取能力,且残差连接有效缓解梯度消失问题。为增强模型对病斑区域的特征响应,在ResNet-50的每个残差块后引入CBAM注意力模块。CBAM通过通道注意力和空间注意力两个维度进行自适应特征重标定,
4.3.2 损失函数优化
针对数据集存在的类别不平衡问题(表4-1),本研究采用Focal Loss替代标准交叉熵损失。Focal Loss在交叉熵基础上引入调制因子$(1-p_t)^\gamma$,降低易分类样本的权重
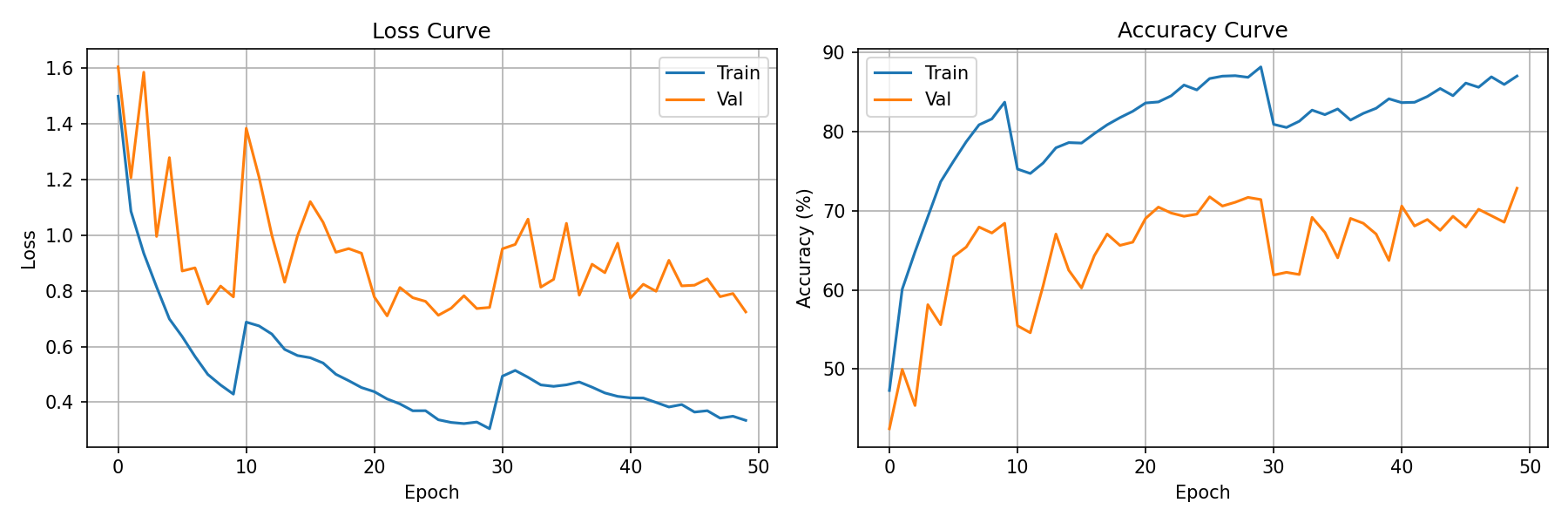
图4.3 Loss损失曲线图
4.4 实验设置与对比分析
4.4.1 实验环境与超参数配置
实验硬件配置为Intel Xeon Gold 5218 CPU、NVIDIA Tesla V100 GPU(32GB)、128GB内存;软件环境为Ubuntu 20.04、PyTorch 2.0.0、CUDA 11.7。模型训练超参数如表4-2所示,采用AdamW优化器,初始学习率0.001,权重衰减1e-4,批次大小32,训练轮数50,并采用余弦退火学习率调度和早停策略防止过拟合。
4.4.2 基线模型对比实验
为验证主干网络选择的合理性,对比了VGG16、ResNet-18、ResNet-34、ResNet-50和EfficientNet-B0的性能,结果如表4-3所示。ResNet-50在准确率(69.84%)和AUC(0.9612)上均取得最佳性能,综合参数量与效果,选择ResNet-50作为基础网络。
4.4.3 注意力机制有效性验证
对比原始ResNet-50与引入不同注意力机制变体的性能,结果如表4-4所示。CBAM(残差块后)取得最高准确率70.52%,优于SE-Net(70.21%)和其他放置方式,验证了同时考虑通道与空间注意力的有效性。
表4.4 注意力机制对比实验
|
模型变体 |
准确率(%) |
宏平均F1 |
参数量(M) |
|
ResNet-50(基线) |
69.84 |
0.714 |
25.6 |
|
SE-Net |
70.21 |
0.722 |
25.8 |
|
CBAM(残差块前) |
70.05 |
0.718 |
25.7 |
|
CBAM(残差块后) |
70.52 |
0.728 |
25.7 |
4.4.4 不平衡处理策略对比
针对类别不平衡,对比了加权采样、Focal Loss及其组合的效果,结果如表4-5所示。两者组合使宏平均F1从0.714提升至0.744,其中穆尔达复合病F1从0.168提升至0.259,白粉病从0.094提升至0.156,营养缺乏症从0.143提升至0.207,改进效果显著。
表4.5 不平衡处理策略对比(基于CBAM-ResNet-50)
|
策略 |
准确率(%) |
宏平均F1 |
穆尔达复合病F1 |
白粉病F1 |
营养缺乏症F1 |
|
无处理(基线) |
70.52 |
0.714 |
0.168 |
0.094 |
0.143 |
|
加权随机采样 |
71.03 |
0.728 |
0.215 |
0.127 |
0.182 |
|
Focal Loss(γ=2.0) |
71.12 |
0.736 |
0.234 |
0.141 |
0.195 |
|
加权采样 + Focal Loss |
71.17 |
0.744 |
0.259 |
0.156 |
0.207 |
4.5 模型评估与可解释性分析
4.5.1 模型泛化能力测试
为评估模型泛化能力,使用成都理工大学公开的辣椒病害数据集进行跨数据集验证,结果如表4-6所示。模型准确率降至62.35%,较原始测试集下降约9个百分点,主要原因为领域偏移和复杂背景干扰。复杂场景测试(表4-7)显示,多叶片重叠场景准确率下降最为明显(15.3%),提示需结合YOLO目标检测进行叶片定位以提升鲁棒性。
表4.6 不平衡处理策略对比(基于CBAM-ResNet-50)
|
模型 |
原始测试集准确率(%) |
跨数据集准确率(%) |
|
CBAM-ResNet-50 + Focal |
71.17 |
62.35 |
表4.6 不平衡处理策略对比(基于CBAM-ResNet-50)
|
干扰因素 |
准确率(%) |
较原始测试集下降(百分点) |
|
原始测试集 |
71.17 |
- |
|
多叶片重叠 |
55.87 |
15.3 |
|
阴影遮挡 |
60.49 |
10.68 |
|
光照不均 |
63.83 |
7.34 |
4.5.2 Grad-CAM可解释性分析
采用Grad-CAM对模型决策区域进行可视化分析,结果如图4-3所示。健康叶片热力图分散,无明显聚焦;细菌性斑点病和炭疽病热力图与病斑位置高度吻合;叶斑病聚焦于病斑边缘晕圈;误判样本则表现为模型未正确关注病斑区域或错误关注正常结构。Grad-CAM可视化验证了CBAM注意力机制的有效性,模型对病斑区域的关注更加集中准确。
第5章 系统开发与实现
5.1 系统技术选型
本系统采用前后端分离架构,后端基于Flask框架开发RESTful API,其轻量灵活的特性便于快速构建Web服务。数据库选用SQLite,无需独立服务器,部署便捷。前端采用Bootstrap框架实现响应式布局,确保在PC端和移动端均有良好体验。数据可视化使用ECharts库,提供丰富的交互式图表。深度学习模型基于PyTorch实现,支持GPU加速推理;图像处理采用OpenCV库,高效完成预处理操作。
5.2 开发环境建立
系统开发环境配置如下:操作系统采用Ubuntu 20.04 LTS,服务器使用Flask内置开发服务器;数据库选用SQLite 3;后端开发语言为Python 3.9,前端采用HTML5、CSS3和JavaScript;后端框架使用Flask 2.3,前端框架使用Bootstrap 5.3;深度学习框架采用PyTorch 2.0及Ultralytics YOLOv8;图像处理使用OpenCV库;开发工具为VS Code和PyCharm;模型训练基于NVIDIA Tesla V100 GPU环境,CUDA版本11.7。
5.3 主要模块的实现
5.3.1 用户认证模块实现
用户认证模块负责用户的注册、登录和权限管理。前端登录界面采用Bootstrap模态框设计,用户输入用户名和密码后,通过Ajax提交至后端。后端Flask路由接收请求,验证用户信息并返回JSON结果。登录成功后将用户信息存入Session,前端根据返回结果跳转或刷新页面。用户注册界面类似,提供用户名、邮箱、密码输入,后端进行唯一性校验和密码哈希加密。用户认证模块的实现界面如图5.1所示。
图5.1 登录图
5.3.2 病害识别模块实现
病害识别模块是系统的核心,提供图像上传、病害分析和结果展示功能。前端上传区域支持点击或拖拽选择图片,通过FormData异步提交至后端。后端接收图像后,调用YOLO模型检测叶片区域,再经ResNet模型分类,最后将识别结果、热力图和防治建议返回前端。前端以图文形式展示病害名称、置信度、概率分布柱状图和热力图。病害识别模块的实现界面如图5.2所示。
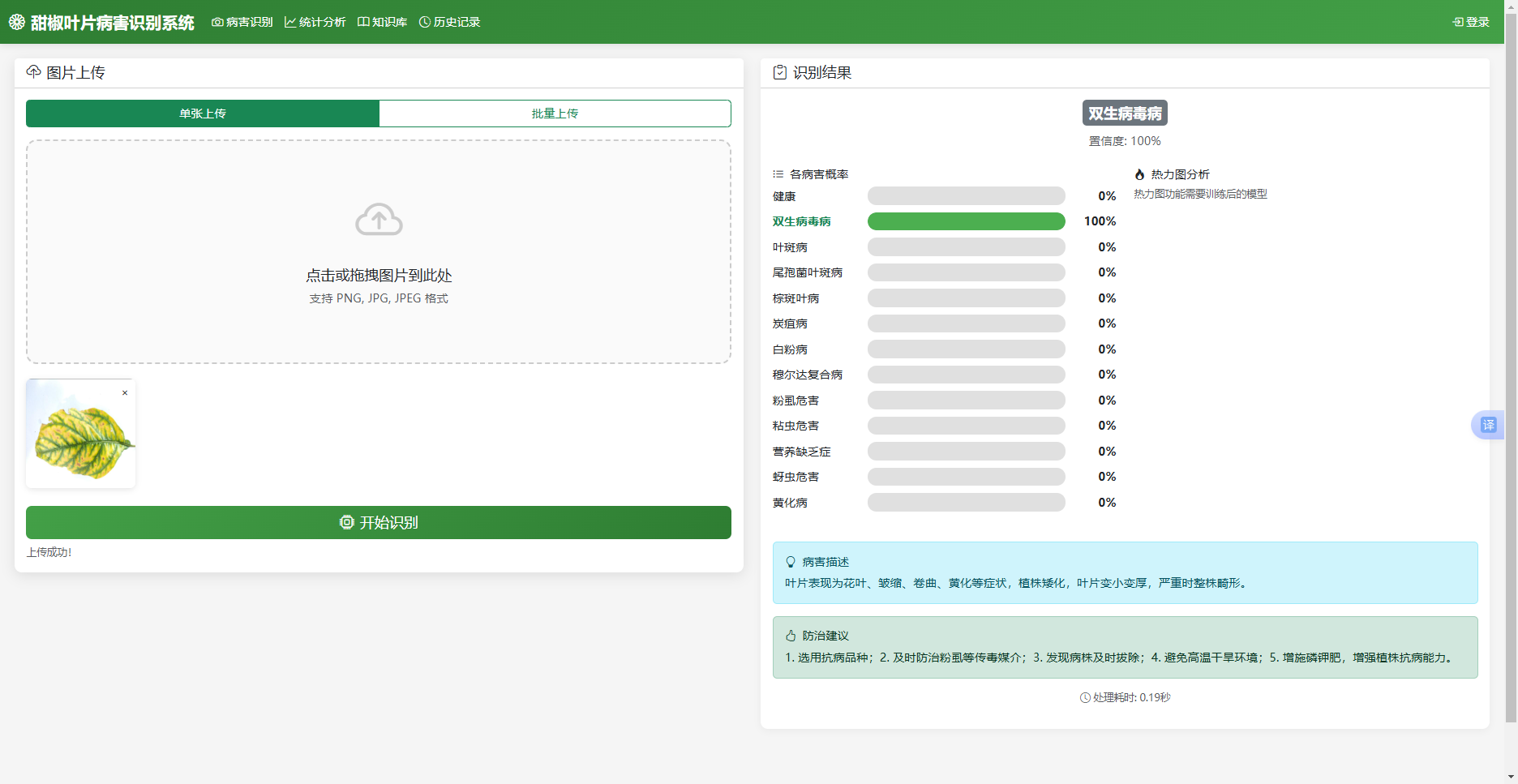
图5.2 识别图
5.3.3 数据统计模块实现
数据统计模块通过ECharts图表展示病害分布、识别趋势等分析结果。前端页面加载时,通过Ajax请求后端API获取统计数据,然后调用ECharts渲染图表。后端从数据库查询识别记录,按不同维度聚合后返回JSON格式数据。数据统计模块的实现界面如图5.3所示。
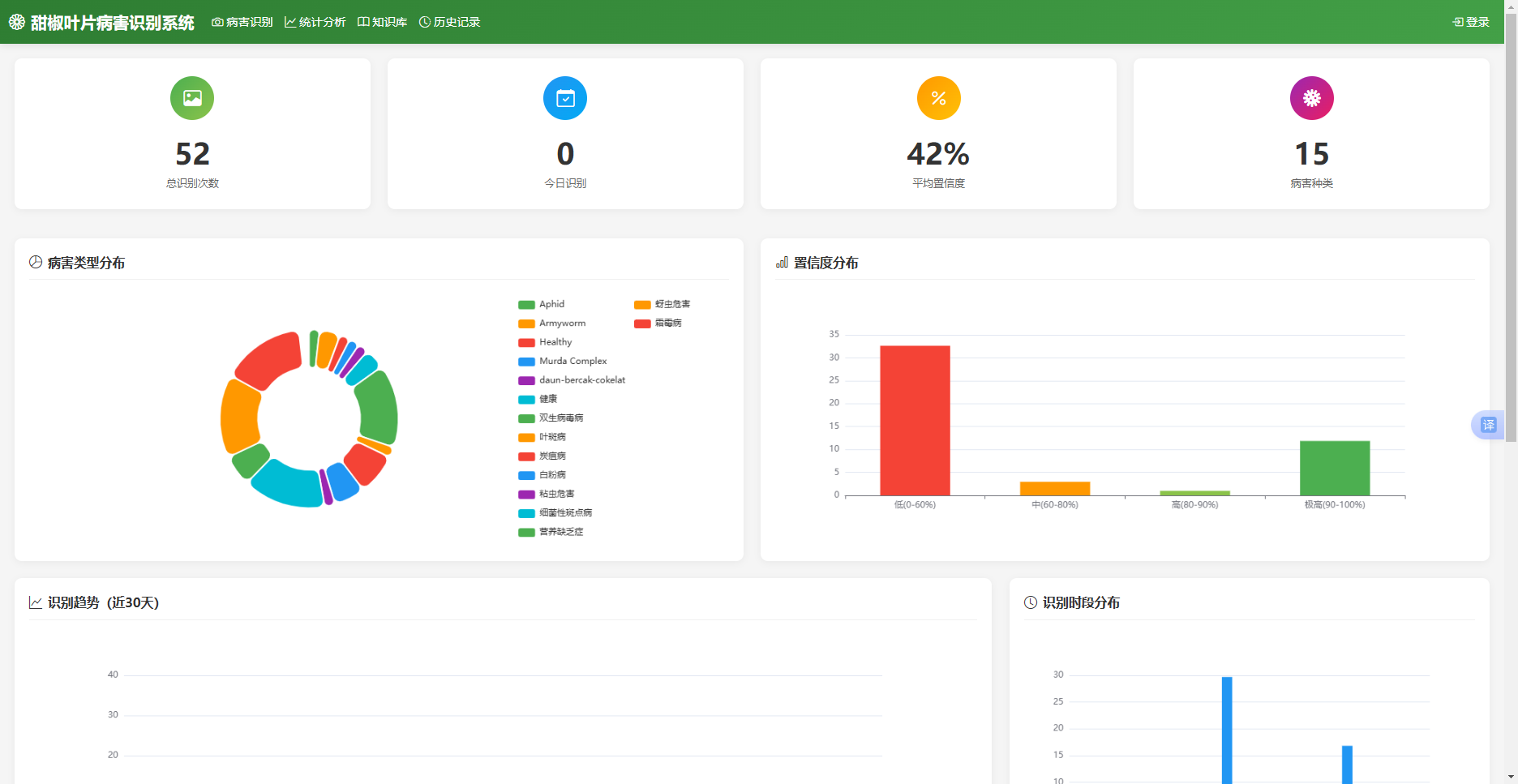
图5.3 数据统计图
5.3.4 知识库管理模块实现
知识库管理模块为管理员提供病害知识的增删改查功能。前端以表格形式展示知识条目,每行包含病害名称、症状预览和操作按钮。管理员可点击“添加”按钮弹出表单,填写病害详细信息后提交;点击编辑可修改现有条目;点击删除可移除条目。知识库管理模块的实现界面如图5.4所示。
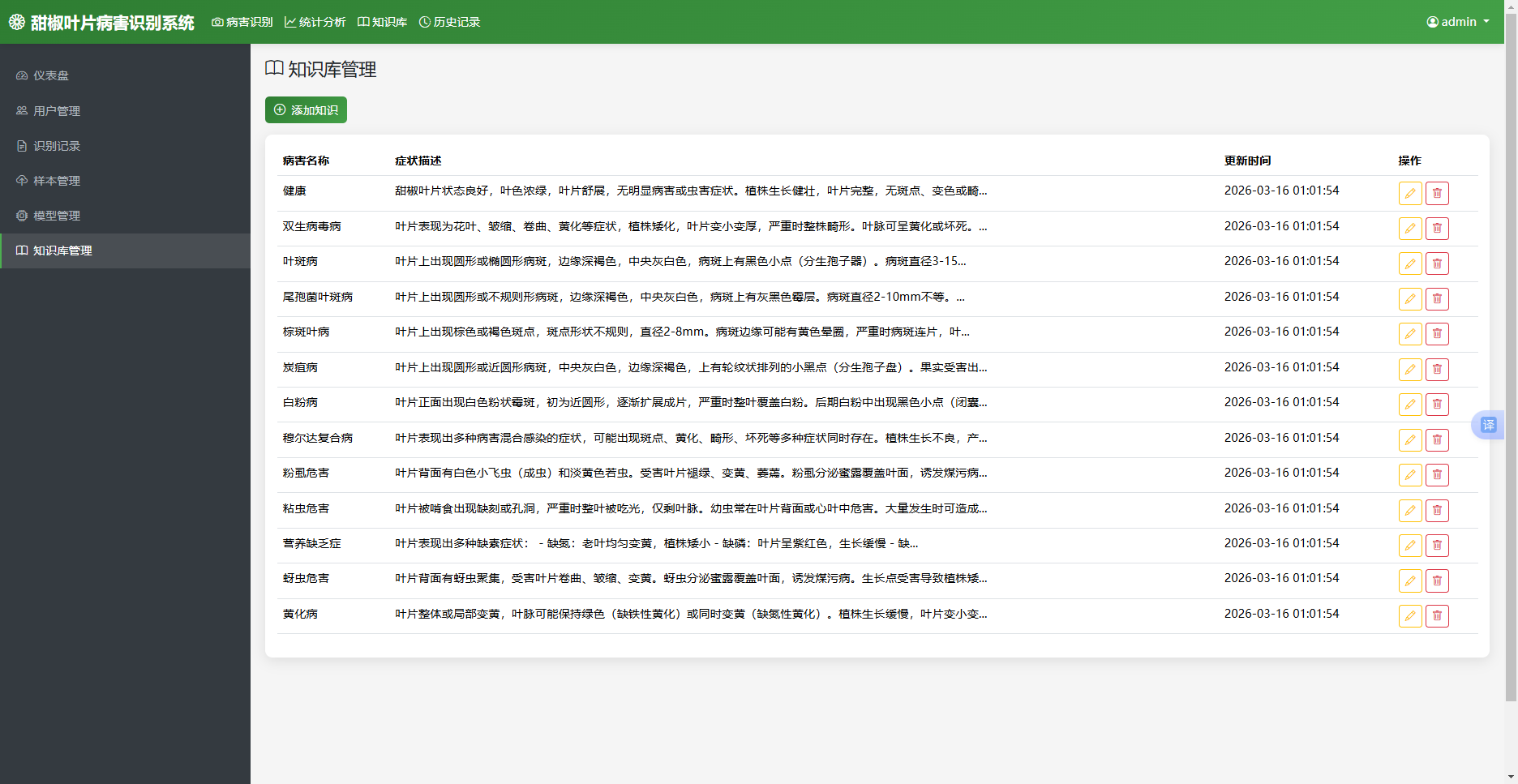
图5.4 知识库管理图
5.3.5 管理员功能模块实现
管理员功能模块提供用户管理、模型管理和样本管理等功能。用户管理页面以表格展示所有注册用户,管理员可点击“设置管理员”或“删除”按钮进行操作。模型管理页面展示模型版本列表,支持激活版本和启动训练。样本管理页面提供上传表单,管理员选择病害类别并上传图像,后端将图像保存至训练数据目录。管理员功能模块的实现界面如图5.5所示。
图5.5 管理员功能图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)