延世大学与英伟达联手:视频AI的物理幻觉是被“过度加工“害的
这项由韩国延世大学人工智能系与计算机科学系,联合英伟达台湾团队共同完成的研究,发表于2026年第43届国际机器学习大会(ICML 2026),论文编号为arXiv:2606.06361,有兴趣深入了解的读者可通过该编号查询完整原文。
你有没有遇到过这样的情形:用AI生成一段视频,里面的球不是按照重力往下落,而是莫名其妙地飘起来,或者一个物体突然凭空消失,又或者液体往上倒流?这类现象在AI视频生成领域有个专业名字,叫做"物理幻觉"。简单说就是,AI画出来的东西虽然漂亮,但违反了真实世界的物理规律。这项研究就是专门为了解决这个问题而生的。
研究团队提出了一个令人意想不到的核心发现:当你让AI只走两步就生成视频时,得到的画面虽然模糊粗糙,但里面物体的运动轨迹往往比走完整整五十步生成的高清视频更符合物理规律。这就好比一个画家,快速勾勒的草稿反而比精心修改几十遍的成品更准确地捕捉到了物体的动态。基于这个发现,研究团队开发了一套名为"PhaseLock"的方法,能在不额外训练AI、不引入外部物理引擎的情况下,让AI生成的视频在视觉质量几乎不打折的前提下,物理一致性平均提升6.2分。
---
一、一个反直觉的发现:越精细越不物理
要理解这项研究的核心,先得明白AI是怎样生成视频的。现代的视频生成AI,核心机制叫做"扩散模型"。你可以把它想象成一个倒放的沙漏过程——一开始,AI拿到的是一团纯粹的随机噪声,就像电视机没有信号时的雪花屏,然后一步一步地去掉噪声,逐渐"显影"出一段有意义的视频。每走一步,画面就清晰一点,细节就多一点。通常,AI走完五十步才算完成一段高质量视频。
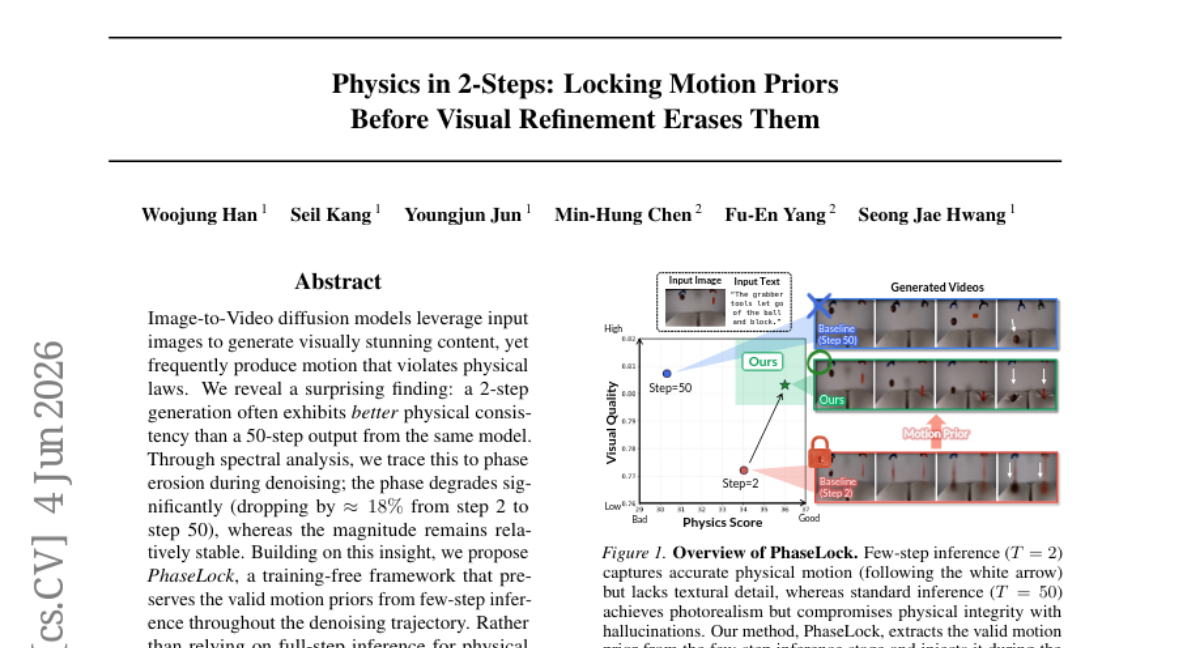
研究团队做了一个有趣的对比实验:让同一个AI用同样的起点,一次只走两步就停下来,另一次走完全部五十步。两段视频拿来比较,走两步的画面模糊、缺乏细节,就像一张焦距没对准的照片;走五十步的则清晰精美,色彩丰富。但当研究人员用一套专门评估物理合理性的标准(叫做Physics-IQ,这是一个通过比较生成视频与真实物理实验视频的运动轨迹来打分的测试)来衡量时,震惊的结果出现了:两步版本的物理评分是34.02分,五十步版本却只有30.82分。走得越多,越不物理。
为了直观理解这个差异,研究团队使用了一种叫做"时空切片"的可视化技术。具体做法是,在视频帧上画一条横线,然后把每一帧这条线上的像素竖着拼起来,就得到一张能同时看到空间位置和时间变化的图。一个球在重力下落时,在这张图上会呈现出一条平滑的向下倾斜曲线。结果发现,两步版本的曲线和真实拍摄的视频几乎一模一样;而五十步版本的曲线则出现了奇怪的折返,球竟然在中途往反方向运动。
---
二、幕后真凶:频率世界里的"相位侵蚀"
发现了这个现象之后,研究团队开始追问:为什么会这样?答案藏在信号处理的世界里。
任何一个图像或视频,都可以被分解成两种信息。用傅里叶变换这把"数学解剖刀"把一段视频切开,你会得到"幅度"和"相位"两个部分。幅度描述的是每种颜色、每种亮度出现的多少,就像一首歌里各种音调的音量大小,决定了画面看起来是亮还是暗、是鲜艳还是灰暗,本质上是外观信息。相位描述的则是这些信息的位置关系和结构,就像乐谱里每个音符出现的时间顺序,决定了物体在哪里、在向哪里运动,是结构和运动信息。
研究团队分析了AI在逐步去噪过程中,幅度和相位各自发生了什么变化。他们用"相位一致性"(测量生成视频的相位与真实视频的相位有多吻合)和"幅度相关性"(同理测量幅度的吻合程度)来量化。结果非常清晰:从第二步到第五十步,幅度相关性几乎没有变化,只降低了约2到3%;但相位一致性却暴跌了大约18%。也就是说,随着AI不断精修视频,外观越来越好看,但描述物体运动轨迹的结构信息却大量流失了。
为了排除一个可能的质疑——两步版本的图像很模糊,会不会是模糊本身导致相位看起来更"纯净"——研究团队做了一个精巧的验证实验。他们对所有视频都施加不同程度的高斯模糊(一种让图像变模糊的技术),强行消除了清晰度的差异,然后再比较相位的时间变化规律。即便在施加了最强程度的模糊之后,两步版本的相位时序规律与真实视频的相关性仍然是五十步版本的3.6倍。这说明,两步版本之所以相位更准确,不是因为它模糊,而是因为它确实保留了更真实的运动结构。
研究团队还做了另一组更直接的因果实验:取一段真实拍摄的视频,分别对其相位和幅度单独注入50%的随机噪声,然后用光流估计工具(一种测量画面中物体实际移动了多少像素的技术)来衡量运动轨迹的破坏程度。破坏相位之后,运动轨迹的平均误差是9.74像素;而破坏幅度之后,误差只有1.14像素。两者相差了8.5倍。这个实验明确证明,相位是运动信息的真正载体,幅度则主要影响外观。
至于为什么AI在精修过程中相位会优先降解,研究团队给出了一个理论解释。大多数视频AI在训练时使用的是均方误差这类损失函数——通俗说就是"预测值和真实值哪里不一样,就罚哪里"。然而,从频率的角度来看,相位误差对最终损失的贡献取决于该频率上的幅度大小。在那些幅度本来就很小的高频区域,哪怕相位差得离谱,对总损失的影响也微乎其微,AI在训练时就几乎学不到如何修正这里的相位。而物体的运动轨迹恰恰常常体现在这些不起眼的、幅度微小的区域里。长此以往,AI就形成了一个内在的不对称性:对幅度非常敏感,对相位相对迟钝。
---
三、PhaseLock:用两步草稿指挥五十步精修
理解了问题所在,研究团队的解决思路就很自然了:既然两步就能得到准确的运动先验,那就把这个先验保留下来,然后在后续的精修过程中,让AI的精修方向不要偏离这个物理轨迹。这就是PhaseLock的核心逻辑。
PhaseLock分两个阶段工作。第一阶段叫做"运动先验提取"。研究团队让AI先用同一个随机起点、同一张输入图片、同一段文字描述,只走两步,得到一段粗糙但物理准确的视频潜在表示(一种AI内部的压缩表示形式,可以理解为视频的"草图数据")。然后,研究团队不直接提取这段草图的相位信息,而是计算每一对相邻帧之间的差值,得到一个"帧间差分"张量,并把它命名为运动先验。这个帧间差分,从理论上说,在帧与帧幅度相近的条件下,其大小近似正比于帧间相位之差——这正是之前证明的"相位才是运动信息载体"的数学体现。研究团队在附录中给出了完整的数学推导:通过傅里叶分析,相邻帧的差值的傅里叶变换幅度,等于共享幅度乘以两倍的帧间相位差的正弦值,在相位差很小(对应平滑运动)时,进一步近似为幅度乘以相位差本身。
第二阶段叫做"潜变量差分引导"。在正式走完五十步精修的过程中,每走一步,研究团队都计算一下当前精修到一半的视频里的帧间差分,与第一阶段提取的运动先验相比,哪里不一样了,就把这个差异作为一个修正信号,轻轻地"推"当前的视频状态,让帧间差分尽量靠近运动先验。这个推力通过一个系数来控制强度,并且随着精修步数的推进,推力会线性地从最大值衰减到零——在精修的前半段,推力较强,保证物理轨迹不偏离;在精修的后半段,推力接近消失,让AI自由地去添加纹理细节和高频信息。
值得注意的是,研究团队明确放弃了一个看似更直接的方案:直接把两步版本的相位信息复制粘贴到五十步版本里。他们做了一系列对比实验,结果发现,直接进行频率域手术(例如低频相位注入、全相位替换、幅度保持相位混合等方案)不仅没有改善,反而让物理评分大幅下降,有时甚至比啥都不做的基线还要差得多,最差的情况只有1.42分。这是因为AI的内部编码空间(VAE编码器生成的潜在空间)并不是一个可以简单地按频率拆解的空间,强行替换其中某些频率成分,就像把一台精密机器的零件换成另一台机器的零件,结果往往是整体失效。而帧间差分引导在空间域操作,不触碰频率域,通过帕塞瓦尔定理,空间域的均方误差约束等价于对所有频率上的谱差异做一个加权求和约束,既达到了相位对齐的目的,又不破坏潜在空间的内在结构。
---
四、实验成果:在三个不同维度验证效果
研究团队在多个模型、多个评估标准上对PhaseLock进行了全面测试。
在物理一致性评估方面,研究团队使用了Physics-IQ基准测试,这个测试包含396段真实物理实验视频,覆盖固体力学、流体动力学、光学、热力学、磁学等66个场景,通过比较生成视频和真实视频中物体位置、速度的偏差来计算分数。将PhaseLock接入CogVideoX-5B(一个50亿参数的视频生成模型)后,物理评分从30.82提升到36.0,提升了5.2分;接入LTX-Video(20亿参数)后,从26.4提升到32.0,提升了5.6分;接入Wan 2.1(140亿参数)后,从20.9提升到28.7,提升了7.8分。这个提升幅度非常可观——要知道,即便把标准推理步数从50步翻倍到100步,物理评分也只提升约1分,而且计算时间翻倍。PhaseLock用仅仅多跑一次两步推理的代价(总时间增加约6%,内存增加约2%),实现了远超步数翻倍的物理一致性提升。
研究团队还在PhyGenBench这个另一个物理常识评估基准上进行了测试,这个基准包含160个精心设计的文字描述,覆盖力学、光学、热力学、材料学四个领域的27条物理规律,使用大语言模型来评估生成视频是否符合物理逻辑。结果同样令人满意:在CogVideoX上平均提升23.9%,在Wan 2.1上平均提升21.4%。其中光学类提升最为显著,力学、热力学和材料学也均有改善。
在视觉质量方面,研究团队使用VBench(一个从主体一致性、背景一致性、运动平滑度、时序稳定性、图像质量、美学质量六个维度评估视频质量的工具)来确认PhaseLock不会破坏视频的外观。结果显示,这六个维度的评分在施加PhaseLock前后几乎没有变化,有些指标(如背景一致性、图像质量)甚至略有提升,美学质量有小幅下降但幅度很小,整体视觉体验基本保持不变。
研究团队还进行了人类偏好实验,邀请15名标注人员对396段视频进行两两对比,分别从物理合理性、视觉质量、文字对应程度三个维度判断哪段视频更好。结果显示,在对比CogVideoX基线时,人类评估者在物理合理性方面有78.3%的胜率选择了PhaseLock的输出;在对比Wan 2.1时,这个胜率更高达83.3%。视觉质量的胜率甚至更高,分别是78.9%和88.2%,说明PhaseLock不仅物理更准确,整体看起来也更令人满意。
---
五、适用范围、局限性与未来方向
研究团队还仔细分析了PhaseLock在哪些场景下效果最好,哪些场景下会失效。
从66个Physics-IQ测试场景来看,PhaseLock改善了74%(Wan 2.1)到67%(CogVideoX)的场景,在另外一些场景下出现了轻微的性能下降。进一步分析发现,流体动力学类场景的改善率最高(Wan 2.1高达93%),平均提升也最大;光学类场景在CogVideoX上改善率达到88%。在刚体运动与非刚体运动的对比上,非刚体场景(包括流体、可变形固体、热力学)的改善幅度平均为41.8%,而刚体场景为23.4%。这是符合逻辑的——非刚体运动往往是连续、有方向性的速度主导运动,相位保护对这类运动最为关键。
PhaseLock也在步数蒸馏版本的模型上进行了测试,例如一个只需4步就能生成视频的轻量版Wan 2.1。在这个模型上,PhaseLock带来了1.7分的提升。提升幅度相对较小,与理论预期完全吻合——这个模型本身就只走4步,相位侵蚀的机会远小于走50步的普通模型,所以可供修复的空间也就更小了。
研究团队也坦承了若干局限。最核心的局限是:PhaseLock转移的是两步推理中生成的运动先验,如果这个两步先验本身就是错误的(例如输入图片模糊、文字描述自相矛盾,或者AI本身对某个物理场景有根本性的认知偏差),那么PhaseLock会把错误的运动先验放大,而不是纠正它。研究团队通过展示失败案例明确指出了这一点:当输入文字要求光线照射在杯子上但图片本身不够典型时,两步先验生成了错误的光影,最终输出同样失败。另一个局限是,PhaseLock依赖迭代去噪循环,对于那些不用扩散模型、而是逐帧自回归生成视频的AI(例如某些大型自回归模型),这套方法无法直接应用。
在未来方向上,研究团队提出了几个有趣的设想。既然相位侵蚀部分源于训练目标的数学结构,那么能否设计一种"相位感知的训练损失函数",让AI在训练阶段就更好地保护相位信息,而不只是在推理阶段打补丁?另外,能否开发出"相位保护的采样器",让去噪路径本身更加相位友好?研究团队还想到,这个现象可能并不只限于视频生成——在音频生成领域,相位决定声音发生的时间和音高,如果类似的侵蚀也在发生,那么一套音频版的PhaseLock或许能让AI生成的音乐节拍更准确;在3D生成领域,相位可能对应几何结构的空间准确性,保护相位可能意味着生成更合理的三维形状。
---
说到底,这项研究讲了一个很简单但细想起来很深刻的道理:更多的加工不总是更好的结果。AI视频生成中那些令人抓狂的物理幻觉,不是因为AI不"懂"物理,而是因为AI在追求高清美观的过程中把自己原本知道的物理知识给"磨掉了"。在精修的五十步旅途里,对美观的追求悄悄侵蚀了对结构准确性的把握,就像一个厨师在反复调味、精心摆盘的过程中,不小心把食材本来的鲜味煮没了。
PhaseLock的做法并不是给AI塞入更多外部知识,而是阻止它丢失自己本来就有的知识。用两步的草稿锁住物理轨迹,然后在精修的全程一直轻轻地提醒AI"别偏",这个思路既经济又有效。它提醒了研究者:有时候,问题的关键不是"怎么加入更多",而是"怎么别让好东西溜走"。
这对普通用户来说,意味着将来用AI制作教学视频、科学可视化、产品演示甚至游戏动画时,物体的运动行为会更加可信,不需要再为AI凭空创造一个"反重力球"而头疼。而对于更远的未来——让AI成为能模拟真实世界的"虚拟物理实验室"——这项研究也铺下了一块坚实的砖。
有兴趣深入探究相位侵蚀机制或PhaseLock实现细节的读者,可通过arXiv:2606.06361查阅完整论文及技术附录。
---
Q&A
Q1:PhaseLock方法是否需要重新训练视频生成模型才能使用?
A:不需要。PhaseLock是完全免训练的推理阶段方法,直接插入现有扩散模型的推理流程中,不改动模型权重。它只需要额外运行一次两步的快速推理来提取运动先验,额外时间开销约6%,内存增加约2%,可以直接接入CogVideoX、Wan 2.1、LTX-Video等现有模型。
Q2:为什么两步推理能比五十步推理更好地保留物理运动规律?
A:扩散模型在最初几步就已经确定了物体运动的粗略轨迹(低频结构),这些轨迹主要由相位信息编码。但在后续的精修步骤中,由于训练时使用的均方误差损失对相位误差不敏感(相位梯度被幅度加权,在幅度小的区域几乎为零),AI倾向于优化外观而忽略相位,导致运动结构被逐渐侵蚀约18%,而幅度(外观信息)只下降2到3%。
Q3:PhaseLock在所有物理场景下都能改善效果吗?
A:不是所有场景都能改善。在Wan 2.1上,PhaseLock改善了74%的Physics-IQ测试场景,在CogVideoX上是67%,其余场景存在轻微下降。流体动力学和热力学类场景改善最显著,非刚体运动平均提升41.8%,刚体运动提升23.4%。主要失效情形是两步先验本身不准确——例如输入图片含义模糊或文字描述与物理常识冲突时,错误先验会被放大而非纠正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献348条内容
已为社区贡献348条内容

所有评论(0)