多元线性回归与Logistic回归
目录
一、多元线性回归
1.1 什么是多元线性回归?
多元线性回归是机器学习中最基础、也是最经典的回归算法之一。当你有多个影响因素,想预测一个具体的连续数字(房价、气温、身高等)时,它就是在数据里找一张「最合适的超平面」,让预测值尽可能接近真实值。
一句话,多元线性回归(Multiple Linear Regression)用来预测连续数值。
1.2 为什么需要多元线性回归?
我们都知道:一元线性回归是什么
公式就一条直线:
意思是:只看一个影响因素 xx,估一个连续的数字 。但是它能干什么?
比如预测房价,你暂时只关心面积,别的因素先不管:
面积 100㎡ → 预 200万;面积120㎡ → 预测 240万。
面积越大,价越高——在「只看面积」的前提下,一元线性回归完全说得通。
但是换到另一个场景:就不行了,在现实中买房,你不可能只看面积。两套都是 100㎡:
A 房:3 个房间、房龄 5 年 → 卖 280 万
B 房:2 个房间、房龄 20 年 → 卖 220 万
面积一样,价格却差 60 万。 一元回归只有「面积」这一个输入,只能给一个预测(比如都估 230 万),没法解释「为什么同面积不同价」,也没法回答:「房间数、房龄差不多时,面积每多 1㎡,大概涨多少?」
一句话: 一元回归 = 只允许 1 个原因,但现实往往是好几个原因一起起作用。
所以有了多元线性回归把多个因素一起放进模型:
对应到房价:
多元线性回归补上的,就是「多个因素联合估一个连续数字」——还是预测「多少万」,但不再只能看一个面积了。
1.3 多元线性回归的预测函数
预测函数(标准形式):
其中
或
为截距
矩阵形式(n个样本):
输出: 任意实数(连续值)
训练目标: 最小化均方误差
一句话总结就是:多个特征的线性组合 → 拟合一个连续数字
1.4 如何使用多元线性回归函数
我们有了预测函数——输入 square、rooms、age,输出。
但这些数据从哪来?不能凭空捏造,要靠历史数据,并且先定义:什么叫「拟合得好」?
先想一个问题:怎样算「猜得准」?
还是房价的例子。假设三套房的真实价和预测价如下:
|
真实price |
预测 |
误差 |
|
|---|---|---|---|
|
1 |
280 万 |
275 万 |
5 万 |
|
2 |
220 万 |
230 万 |
-10 万 |
|
3 |
350 万 |
340 万 |
10 万 |
每一行都有一个残差(真实 − 预测):5、-10、10。我们的目标很朴素:让这些误差整体尽量小。
难点在于:误差有正有负,不能直接相加——否则猜高10万和猜低10万会互相抵消,看起来「没误差」。
所以多元线性回归的经典做法是:先平方,再对所有样本加起来。下面把这个想法写成公式。
:第 i套房的真实 price
:模型预测的 price
:样本总数
这个式子就是在说:每一套房都算一遍「预测偏差有多大」,平方后求平均——平均平方误差越小,整体拟合越好。
为什么要平方,而不是直接取绝对值?三点原因:
1.正负误差不会互相抵消——猜高10万和猜低10万都算错,平方后都是100。
2.大错罚得更重——差20万的惩罚是差10万的4倍,模型会更努力避免离谱预测。
3.数学上好求导,方便后面用公式或梯度下降找到最优 。
用一句话概括:让每一套房的「预测价 − 真实价」尽量接近 0,所有样本的平方误差之和越小越好。
那么有了损失,训练在干什么?
MSE只是「打分规则」,训练就是在这个规则下找最好的参数:
在所有可能的权重里,选那一组让 MSE 最小的——那就是模型从数据里「学」到的和
。
最后退回一个特征,直觉更清楚
如果暂时只看square一个因素,,上式就是在散点图上找一条直线,让各点到直线的竖直距离平方和最小——中学里也叫「最小二乘拟合」。
特征变成多个时,不过是把「一条线」推广成「一个超平面」,损失函数的形式不变,道理一样。
特征多的时候,还有一条公式路
若设计矩阵可逆,
甚至有解析解,不必迭代:
这叫正规方程。实际项目里特征一多、样本一大,更常用数值优化或直接调sklearn,不必手算逆矩阵——但知道「MSE 最小化有闭式解」有助于理解它在做什么。
同时这条损失不是随便选的
若进一步假设:真实 price 与预测值之间的误差服从高斯(正态)分布,那么「最大化似然(MLE)」和「最小化 MSE」是一回事。也就是说,MSE 不只是一个好用的打分方式,背后还有概率依据。
1.5 实际案例
前面四节把公式和损失都讲清了——这一节做一件事:用真实数据跑一遍,看模型学出来的长什么样、预测靠不靠谱、图该怎么读。
第一步:获取数据
我现在有这么一组200个数据
|
样本ID |
面积 |
房间数 |
房龄 |
房价 |
|
1 |
0.130741 |
-1.43014 |
-0.44004 |
-69.2609 |
|
2 |
1.502357 |
-0.26941 |
0.717542 |
155.2535 |
|
3 |
0.647689 |
0.496714 |
-0.13826 |
68.82556 |
|
4 |
0.341756 |
-0.75913 |
0.150394 |
15.69516 |
|
... |
... |
... |
... |
... |
|
196 |
-1.32819 |
0.208864 |
-1.95967 |
-235.426 |
|
197 |
1.366874 |
-2.30192 |
-1.51519 |
-64.496 |
|
198 |
-0.42065 |
-0.23459 |
-1.41537 |
-172.703 |
|
199 |
-0.83095 |
-0.86399 |
0.048522 |
-74.34 |
|
200 |
0.963376 |
1.158596 |
-0.82068 |
26.49008 |
数值是标准化后的模拟数据,不是真实「多少㎡、多少万」,但结构和1.2的房价故事一致——三个特征 → 一个连续 price。
第二步:划分数据,让模型「学」
和实际项目一样,把 200 条分成:
训练集(75%):用来最小化MSE,学和
测试集(25%):训练时不给模型看,专门用来检验「对新样本泛化好不好」
第三步:分析跑出来的结果
学习到的系数 w: [72.181 22.34 72.171]
截距 b: -0.531
测试集 MSE: 285.46
测试集 R2: 0.9709
的符号和大小:在训练集上学到的「每个因素对 price 的方向和力度」——具体业务里还要结合特征是否标准化来解读。
MSE = 285.46:测试集上平均平方误差,越小越好;要和 price 的量级一起看。
R2 ≈ 0.97:模型能解释测试集上约 97% 的价格波动——说明拟合相当不错(模拟数据噪声较小,所以 R2 偏高是正常的)。
第四步:代入一条新样本,手算直觉
拿第 2 条样本:square = 1.50,rooms = -0.27,age = 0.72,真实 price = 155.3。
用学到的权重代入公式:
和真实 155.3 很接近——这就是「训练完以后,对新输入做预测」的完整流程。
第五步:看图——两张图各回答一个问题
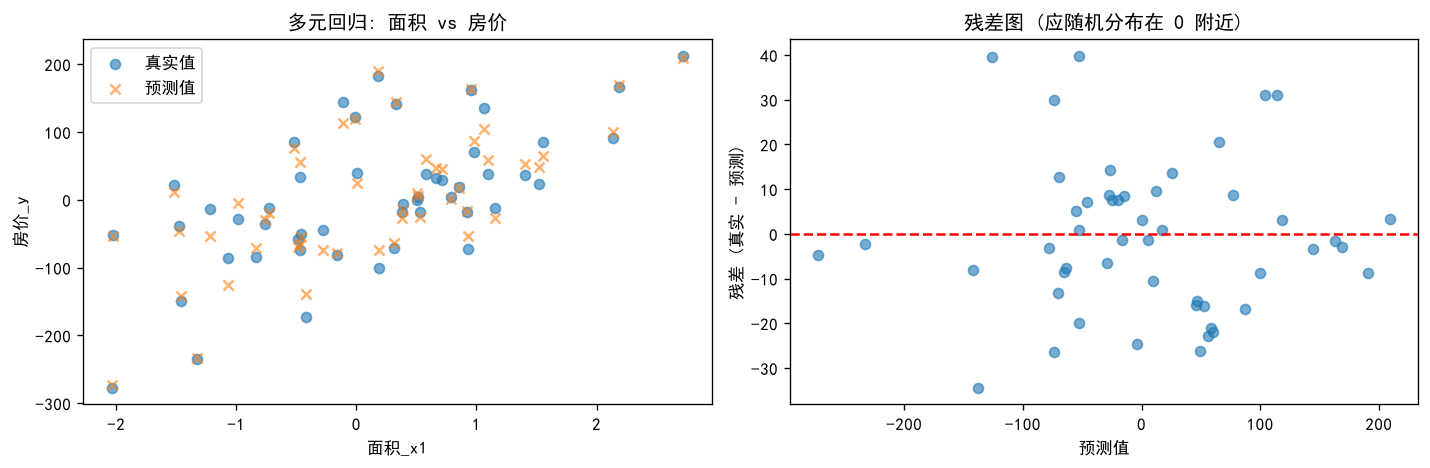
左图回答了预测整体有没有跟着真实走?右图回答了有没有「系统性偏高/偏低」?
一个一个分析:
左图蓝色圆点是测试集真实 price,橙色叉号是预测 price。叉号与圆点几乎重合,且都沿同一上升趋势分布——说明模型抓住了「面积越大、价越高」的主规律。
右图红色虚线是 残差 = 0;蓝点 = 真实 − 预测。点随机散落在 0 上下,没有「预测越大残差越大」的漏斗形,也没有明显的 U 形弯带——说明线性假设基本合理,没有漏掉「该用曲线却用了直线」的大问题。个别点偏离稍远(最大约 ±40)属于正常噪声,不是模型系统性失败。
1.6 多元线性回归在现实中的应用
我们在模拟房价数据上走完了全流程。回到现实,多元线性回归的用法不变——多个因素一起,估一个连续数字;变的只是行业和特征名。
以下有三个经典场景分类适用于多元线性回归
场景一:房价定价
输入:square、rooms、age、location 等
输出:price(多少万)
问法:「这套房大概值多少?」
和1.2的故事一一对应——也是本文贯穿的例子。
场景二:销量预测
输入:广告投入、促销力度、季节指数
输出:sales(件数或金额)
问法:「下周大概能卖多少?」
逻辑一样:不是单看「广告花多少」,而是多因素联合估一个数。
场景三:用电负荷
输入:温度、湿度、是否节假日
输出:load(kWh)
问法:「明天电网负荷大概多少?」
调度部门要的是可量化的连续预测,方便做储备和排班。
三个场景的共同点
|
共同点 |
说明 |
|---|---|
|
标签是连续值 |
可以比大小、算差值 |
|
问的是「是多少」 |
不是「是不是」「哪一种」 |
|
需要多因素 |
单一因素往往不够,要用多元模型 |
如果你遇到的任务符合上表,多元线性回归通常是第一个该试的基线模型。
若标签变成 0/1(是否、有没有),就要换工具——那就是第二篇逻辑回归要解决的问题。
二、Logistic回归(逻辑回归)
2.1 什么是Logistic回归(又称逻辑回归)?
逻辑回归是机器学习中最基础、也最经典的分类算法之一。当你有多个影响因素,想判断一个二选一的结果(邮件是否 spam、是否患病、贷款是否通过)并想知道有多大把握时,它先对特征做线性组合,再通过 Sigmoid 把得分映射成 0~1 之间的概率,从而给出「是 / 否」的结论。名字里虽带「回归」,但它做的是分类 + 概率估计。
一句话就是,逻辑回归(Logistic Regression)用来二分类——问的是「是不是?」
2.2 为什么需要逻辑回归?
我们上面才学习完:多元线性回归是什么
意思是:把多个影响因素一起算,输出是一个具体的数字——可以是 26.3,可以是 328.5,可大可小。
但是它能干什么?
比如预测明天气温:
模型输出 26.3°C——你要的就是「明天多少度」,多元回归正合适。
预测房价、销量、身高……凡是问「是多少」,多元线性回归都是好工具。
但是换到另一个场景:就不行了
现在任务变了:不是问「多少」,而是问「是不是」。
比如判断邮件是不是垃圾邮件——只有两种答案:spam(1)或正常(0)。
如果还硬用多元回归:
算出来可能是:
邮件 A:
邮件 B:
你没法跟老板说「这封邮件spam概率 144%」,也没法说「负 32% 是垃圾邮件」。
硬用 0.5 当阈值虽然能勉强分对错,但输出不是合法概率——银行要的「违约概率 23%」也给不出来。
所以多元回归擅长「估一个连续数字」;分类问的是「属于哪一类、有多大把握」——问法换了,工具就不匹配。
2.3 逻辑回归的预测函数
预测函数(标准形式):
其中为Sigmoid函数
输出: (0,1)(0,1) 概率
训练目标: 最小化二分类交叉熵
一句话总结就是, 线性组合 + Sigmoid → 判断两类、给出概率
2.4 如何使用逻辑回归函数
上一节我们有了预测函数——输入特征,输出(属于正类的概率)。
但 和
从哪来?和多元回归一样,要靠历史数据;而要用数据,得先定义:什么叫「分得好」?
先想一个问题:分类里怎样算「猜得准」?
回归可以直接比「差多少万」;分类不行——标签只有 0 或 1。
还是用邮件的例子。假设 4 封邮件,真实标签和模型预测如下:
| 真实 |
预测 |
感觉 | |
|---|---|---|---|
| 1 | 1(spam) | 0.92 | 很准 |
| 2 | 0(正常) | 0.08 | 很准 |
| 3 | 1(spam) | 0.35 | 偏保守,错了 |
| 4 | 0(正常) | 0.78 | 偏激进,错了 |
规律很清楚:真实是 1 时,希望 靠近 1;真实是 0 时,希望
靠近 0。
而且错得越离谱,应该罚得越重——把正常邮件判成 99% spam,显然比判成 51% 更糟。
接下来要找一个损失函数,把上面这套「直觉」变成可以优化的数字。
二分类交叉熵:把直觉写成公式
∈{0,1}:第 ii 个样本的真实标签
:模型预测「属于正类(1)」的概率
:样本总数
对照前面的表格看:
当 (真是 spam):式子里只剩
。
越接近 1,损失越小;若
接近 0(像第 3 封那样给了 0.35),
会明显变大——就是在惩罚「该说是,却不敢说是」。
当真是正常):式子里只剩
。
越接近 0 越好;若
接近 1(像第 4 封那样给了 0.78),损失同样会很大。
一句话:让模型对「该是的样本」果断说是(),对「该不是的样本」果断说否(
)。 交叉熵就是在度量「预测概率离这个理想状态有多远」。
为什么不用「数错了几个」,也不用 MSE?
你可能会问:直接数错了几封邮件(0/1 损失)不行吗?或者用多元回归那套 MSE,把 0/1 标签当连续数去拟合?
| 方式 | 问题 |
|---|---|
| 只数错了几个(0/1 损失) | 猜错 51% 和猜错 99% 惩罚一样,模型不知道往哪改,梯度几乎学不动 |
| 硬用 MSE 拟合 0/1 | 输出可以跑出 0~1 之外,且对「概率是否校准」不敏感 |
| 交叉熵 | 错得越离谱罚越重,处处可导,天然适配 0~1 概率输出 |
所以逻辑回归选交叉熵,不是随便挑的——它正好接在上节的 Sigmoid 后面,形成「概率输出 + 概率损失」一整套。
有了损失,训练在干什么?
和多元回归一样,有了打分规则,训练就是找让分数最低(这里是最小化损失)的参数:
在所有可能的权重里,选那一组让交叉熵最小的——模型就「学会」了怎么给合法、可信的概率。
这条损失同样有据可查
若假设标签 服从伯努利分布
∼Bernoulli(
)y∼Bernoulli(
),那么「最大化似然(MLE)」和「最小化交叉熵」是一回事。
和第一篇 MSE 对应高斯假设一样,这里的交叉熵也不是拍脑袋——它来自「标签是 0/1 随机事件」这一概率模型。
2.5 实际案例
前面四节把公式和损失都讲清了——这一节做一件事:用真实数据跑一遍,看模型学出来的长什么样、预测靠不靠谱、图该怎么读。
第一步:获取数据
我现在有这么一组300个数据
| 样本ID | 指标1 |
指标2 |
是否正类 |
| 1 | 0.733246 | -1.43101 | 0 |
| 2 | 0.656043 | 0.842841 | 1 |
| 3 | 0.537983 | -2.05655 | 0 |
| 4 | 1.289308 | -0.07902 | 1 |
| ... | ... | ... | ... |
| 299 | 0.122447 | 0.74248 | 1 |
| 300 | 1.715959 | 1.168337 | 1 |
和多元回归不同:这里的只有 0 或 1,没有「中间值」——正好对应2.2说的「是不是」类问题。
第二步:训练——最小化交叉熵
流程和多元线性回归类似:75% 训练、25% 测试
第三步:看概率——不止「对/错」
权重 w: [0.736 3.12 ]
截距 b: -0.467
测试集准确率: 0.9333
分类报告:
precision recall f1-score support
类 0 0.97 0.89 0.93 38
类 1 0.90 0.97 0.94 37
accuracy 0.93 75
macro avg 0.94 0.93 0.93 75
weighted avg 0.94 0.93 0.93 75
测试集 75 条里错 5 条(75 − 70 = 5,准确率 93.3%)。更细地看分类报告:
| 类 | 精确率 | 召回率 | 解读 |
|---|---|---|---|
| 0(负类) | 0.97 | 0.89 | 判为 0 的很准;但有 4 个真 0 被漏判成 1 |
| 1(正类) | 0.90 | 0.97 | 真 1 大多抓住了,漏检少 |
结论:93% 准确率 + 两类 F1 都在 0.93 左右,说明模型有效分开了两类。
逻辑回归的价值在于。拿第 2 条样本(真实
=1):
特征:= 0.66,
= 0.84
模型给出:P(=1)≈0.93
按2.3规则: → 判为 1,和真实标签一致
若这是信贷场景,就可以跟业务说「违约概率约 93%」——这就是2.2强调的逻辑回归相比硬用多元回归多出来的能力。
第四步:看图——决策边界在说什么?
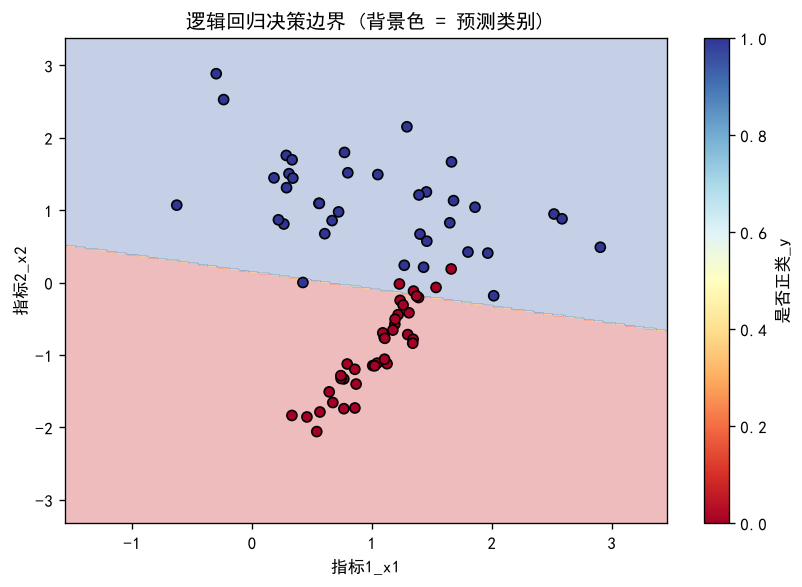
绝大多数点落在「与自己颜色一致」的背景区;仅约 5 个点跨到了对面——和 93.3% 准确率一致。这些错分点多半靠近分界线,属于「概率在 0.5 附近、模型本身就不太确定」的样本,可接受。
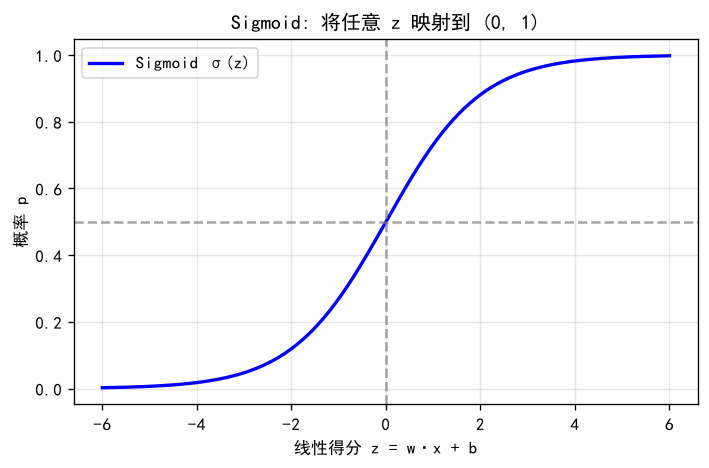
那么为什么要用Sigmoid函数?如下图:
第五步:数值对照
硬用线性回归为什么「数看起来还行、用起来却不行」
同一数据集上若硬用多元线性回归则会出现
线性回归输出范围: [-0.532, 1.443] ← 出现负值和 >1,不是合法概率
强行 0.5 阈值准确率: 0.9233
逻辑回归概率范围: [0.000, 1.000] ← 合法
逻辑回归准确率: 0.9300准确率差不多(92% vs 93%),但线性回归的 1.443、-0.532 无法当概率向业务解释——这就是2.2说的「工具不匹配」。分类任务应看逻辑回归,不能只看准确率数字接近就偷用回归。
2.6 逻辑回归在现实中的应用
我们在二维特征上看到了「分界线 + 概率」。现实中特征可以很多,但问法不变:是不是、会不会、要不要——且往往既要判类,也要概率。
以下有三个经典场景分类适用于逻辑回归
场景一:信贷风控
输入:收入、负债比、逾期记录
输出:是否违约(0/1)+ 违约概率
问法:「这笔贷款会不会违约?概率多大?」
风控不只要「拒/批」,还要算预期损失——直接进业务公式,所以必须用逻辑回归这类输出合法概率的模型。
场景二:垃圾邮件过滤
输入:词频、链接数、发件人信誉等
输出:是否 spam
问法:「这封邮件是不是垃圾?」
可以设≥0.9才进垃圾箱,减少误杀——阈值灵活,依赖的正是概率输出。
场景三:疾病筛查
输入:血压、血糖、BMI
输出:是否高风险
问法:「要不要进一步检查?」
医学场景常更怕漏诊(假阴性),会故意降低阈值——同样基于调,而不是只能「对/错」一个点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)