OpenAI 要建 5000 亿美元数据中心,而你还在为接入哪个模型发愁?
OpenAI 要建 5000 亿美元数据中心,而你还在为接入哪个模型发愁?
这周 AI 圈出了两件事,连在一起看很有意思。
6 月 10 号,消息说 OpenAI 在谈俄亥俄州一个 10 吉瓦的数据中心园区,建设成本至少 5000 亿美元,英伟达可能出钱,第一阶段 2028 年启动。OpenAI 签 20 年租约,等于把整个设施拿下了。
6 月 15 号,Sam Altman 飞韩国,去三星电子总部谈 AI 芯片和数据中心合作。三星之前已经在给 OpenAI 的「星际之门」项目供高性能内存,SK 海力士供 HBM。
顺便一提,三星这个月刚搞了个「AI 大转型」,研发、采购、制造、营销、服务等八条业务线全部接入 AI,还向员工开放了 ChatGPT Enterprise、Gemini Enterprise 和 Claude。
头部厂商在疯狂堆基建、抢芯片、锁供应链。这个趋势没什么争议。
模型越多,开发者越累
但你要是开发者,感受可能完全不一样。
GPT-4o、Claude 4、Gemini 2.5、DeepSeek、Qwen、Llama 4...2026 年的模型列表比餐厅菜单还长。每个模型都有自己擅长的活儿,也都有各自的 API 文档、计费规则、速率限制。
你想在项目里用 GPT-4o 做对话、Claude 做长文分析、DeepSeek 做代码生成?
那你得:
- 分别注册三个平台
- 分别充值,分别管 API Key
- 分别对接三套 SDK,维护三套错误处理
- 月底对着三张账单算钱
这根本不是开发,这是给模型当保姆。
而且你很难在合适的时机用合适的模型。GPT-4o 今天降价了你知不知道?Claude 昨天出了新版本你切没切?DeepSeek 的费率悄悄调了你看没看?
平台之间的墙越筑越高,你的成本就越来越厚。
一个平台,搞定所有模型
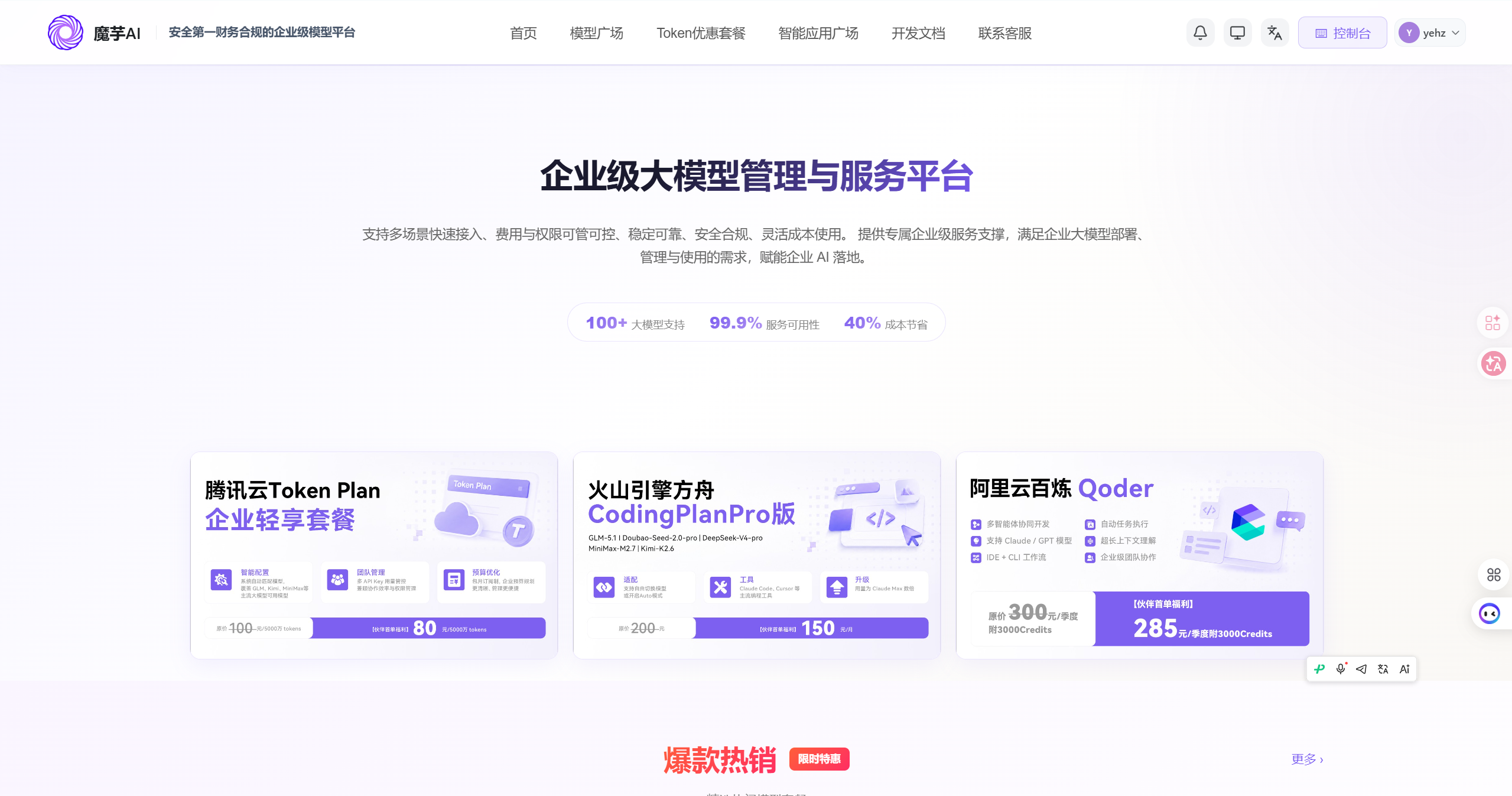
魔芋AI 解决的就是这个问题。
它是一个多源大模型 API 聚合平台,接入了 GPT-4o、Claude、Gemini、DeepSeek、Qwen、Llama 这些主流模型。注册一次,一个 API 里调用所有模型。
切换模型,改一行代码的事。
# 用 GPT-4o
response = moyu.chat(model="gpt-4o", messages=[...])
# 想切 Claude?改个参数就行
response = moyu.chat(model="claude-sonnet-4-20250514", messages=[...])
不用重新接 SDK,不用翻三个后台管 Key,不用月底对着四张账单拼成本。
一个 Key 调所有模型,计费统一,接口统一,管理统一。
为什么现在是用聚合平台的时候
OpenAI 砸 5000 亿美元建数据中心,说明一件事:模型竞争远远没到终局。
未来两三年,模型能力还会继续分化,新的黑马随时可能冒出来。你不可能把所有赌注押在一个模型上,但也不应该为每个模型都维护一套独立的接入方案。
聚合平台的价值很简单:切换成本最低,你永远能用当下最强的模型。
当 OpenAI 在俄亥俄州建数据中心、Altman 在首尔跟三星谈芯片的时候,你只需要关心一件事:哪个模型最适合你现在的业务,然后调它。
试试魔芋AI,一个 Key 接入所有主流模型:https://www.moyu.info/register?aff=40jA

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)