LangChain 系列之Tools:让大模型真正连接业务系统

前面几章,我们把 RAG 的底层链路讲完了:文档进来,切分,向量化,入库,检索,重排,最后把上下文交给模型。
但这还不够。
RAG 让模型会“查资料”。Tools 让模型能“办事情”。
没有 Tools,大模型只是一个会聊天的脑子。它能分析,能总结,能解释。但它不能查订单,不能改数据库,不能调行情接口,也不能创建工单。
有了 Tools,模型才真正接上业务系统。
一、Tool 到底是什么?
Tool,翻译过来是“工具”。但在 LangChain 里,它不是普通工具类。它是模型和真实业务系统之间的一层安全接口。
模型不能直接碰数据库。模型也不应该直接执行转账、退款、删除、下单这类动作。
正确做法是:你把确定性的业务能力封装成 Tool,模型只负责判断“该不该调用、调用哪个、传什么参数”。真正执行动作的,是你写的代码。
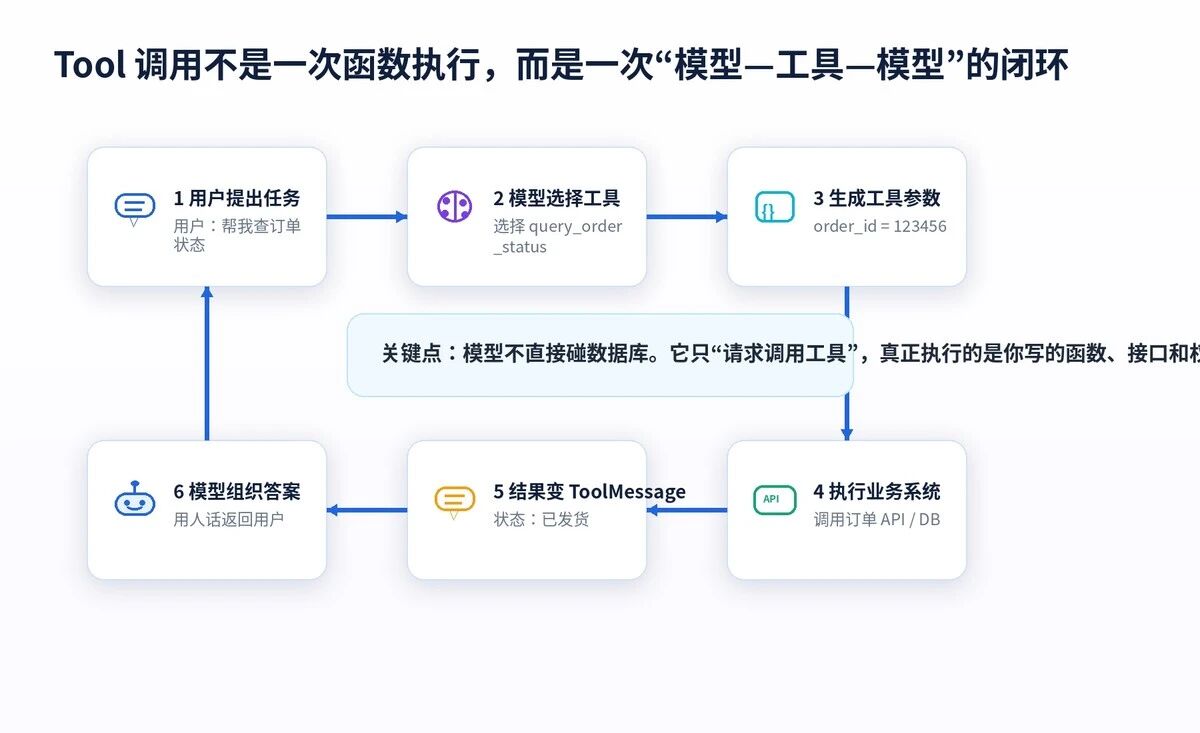
所以,Tool 的本质可以压成一句话:
Tool = 有名字、有说明、有参数结构、有执行函数的业务能力。
二、为什么 Agent 离不开 Tools?
Agent 不是“更会聊天的模型”。Agent 的核心,是模型可以反复决定下一步。
官方文档里对 Agent 的描述很直接:Agent 是模型在循环中调用工具,直到任务完成。它的外壳包括模型、Prompt、Tools 和 Middleware。
这句话非常关键。
因为没有 Tools,Agent 的循环只能在文本里打转;有了 Tools,它才能从文本世界走进业务世界。
三、一个 Tool 长什么样?
从外面看,一个 Tool 很简单。
from langchain.tools import tool
@tool
def query_order_status(order_id: str) -> str:
"""查询订单状态。"""
return order_service.query(order_id)
但从源码看,这个函数会被包装成一个 Tool 对象。
它最重要的不是函数体,而是这几件事:
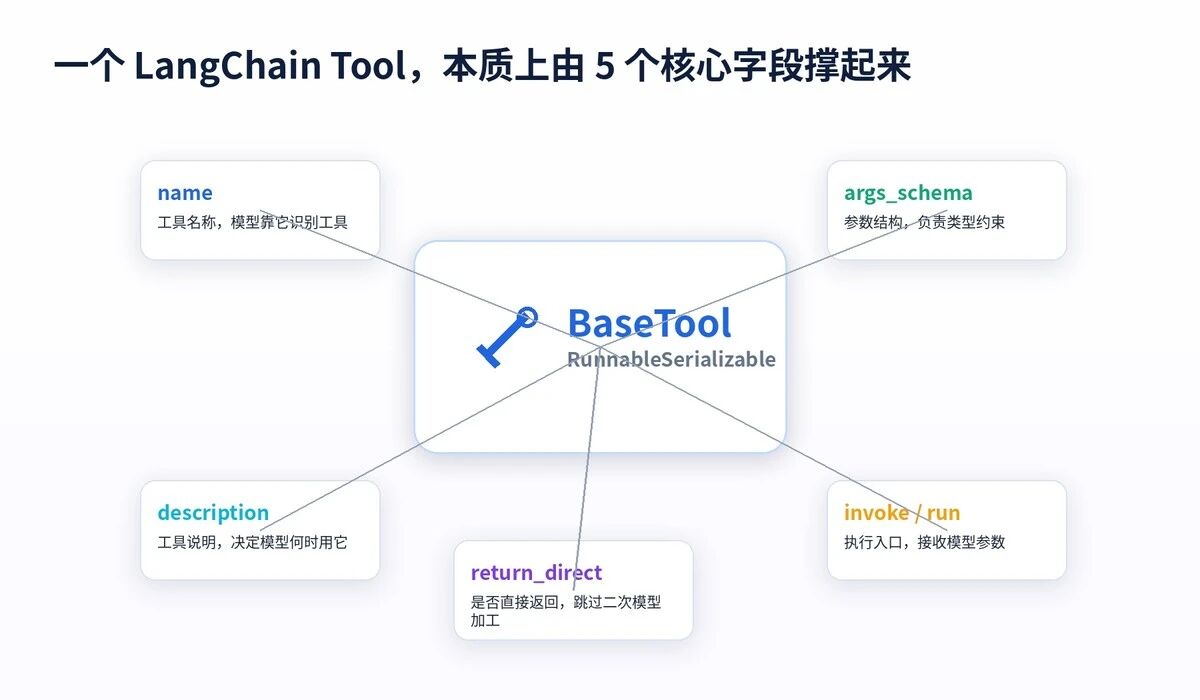
name 告诉模型“我是谁”。description 告诉模型“什么时候该用我”。args_schema 告诉模型“参数怎么传”。invoke/run 是执行入口。return_direct 决定工具结果是否直接返回用户。
这几个字段决定了 Tool 能不能被模型正确选择、正确调用、正确解释。
四、Tool 的源码入口:BaseTool
源码里,Tool 的根基是 BaseTool。
BaseTool 继承 RunnableSerializable。也就是说,Tool 不是孤立对象,它也是 LangChain Runnable 体系的一员。
这就是为什么 Tool 可以被 invoke,可以被回调追踪,可以被放进 Agent,也可以被 LangGraph 的 ToolNode 执行。
class BaseTool(RunnableSerializable[str | dict[str, Any] | ToolCall, Any]):
name: str
description: str
args_schema: ArgsSchema | None = None
return_direct: bool = False
def invoke(self, input, config=None, **kwargs):
tool_input, kwargs = _prep_run_args(input, config, **kwargs)
return self.run(tool_input, **kwargs)
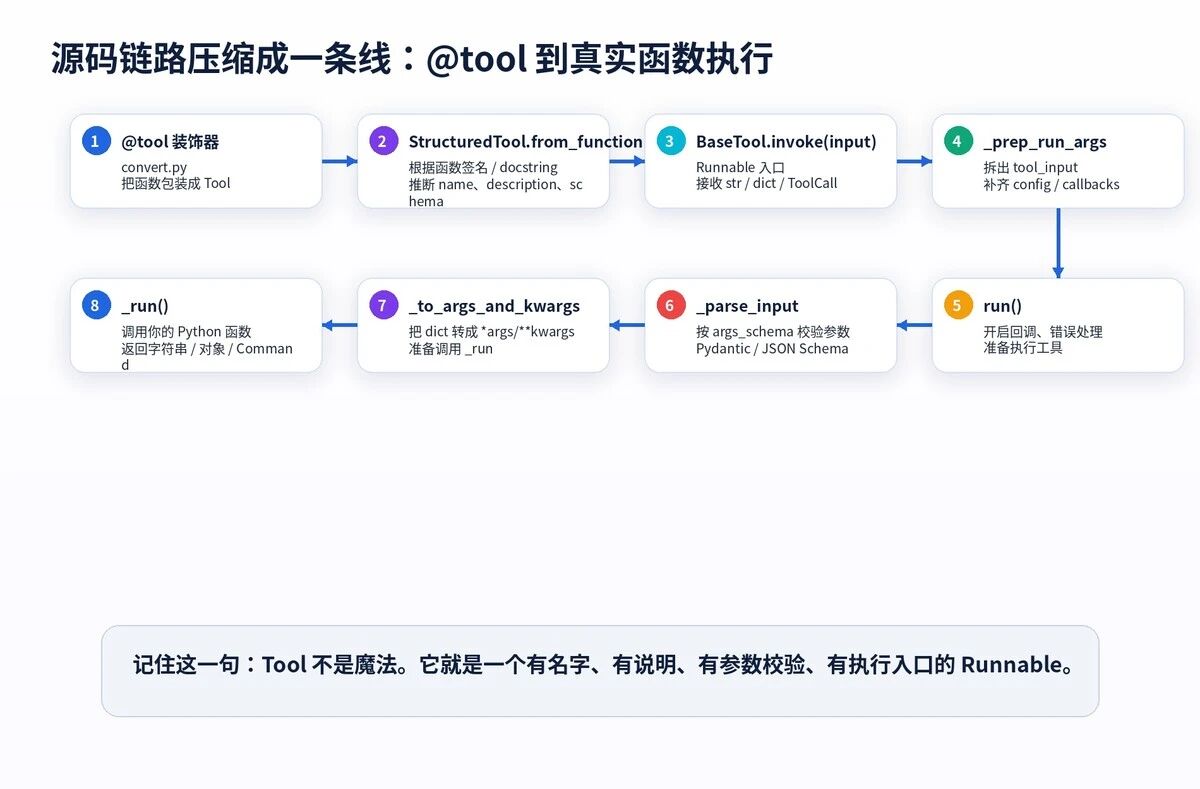
这段源码链路说明了三个事实。
第一,Tool 可以接收字符串、字典,也可以接收模型生成的 ToolCall。
第二,invoke 不直接执行你的函数,它先调用 _prep_run_args,把输入、配置、回调等信息整理好。
第三,真正执行会进入 run,再进入 _parse_input、_to_args_and_kwargs、_run。
五、@tool 装饰器做了什么?
@tool 看起来只是一个装饰器。
但它背后做了很多事。
它会读取函数名,作为默认工具名。它会读取 docstring,作为工具描述。它会读取函数签名和类型注解,推断参数结构。如果传了 args_schema,它会使用你显式定义的参数模型。
也就是说:
@tool 的工作,就是把一个普通 Python 函数变成模型能看懂、Agent 能调用、系统能校验的 Tool。
@tool("web_search")
def search(query: str) -> str:
"""Search the web for information."""
return search_api(query)
函数名可以改。描述可以改。参数结构可以自定义。
但生产环境里,最重要的是 description 和 args_schema。
description 写得模糊,模型就会乱选工具。args_schema 写得松,模型就会乱传参数。
六、Tool 和 StructuredTool 的区别
早期很多人会把 Tool 理解成“一个字符串输入,一个字符串输出”。这个理解太窄了。
真实业务里,一个接口往往有多个参数:订单号、用户 ID、时间范围、分页参数、过滤条件。
这时就需要 StructuredTool。

普通 Tool 更适合简单函数。StructuredTool 更适合多参数业务接口。BaseTool 子类适合企业级深度封装。HeadlessTool 适合 schema 在服务端注册、执行在外部系统的场景。Retriever Tool 则把知识库检索包装成 Agent 可以调用的工具。
七、Tool 的参数为什么必须严格?
模型传参不是天然可靠。
它可能把 order_id 传成“帮我查一下 123456”。也可能漏掉必填字段。还可能把日期范围写错。
所以 Tool 的参数必须结构化。
from pydantic import BaseModel, Field
class OrderInput(BaseModel):
order_id: str = Field(description="订单号")
include_logistics: bool = Field(default=True, description="是否返回物流信息")
@tool(args_schema=OrderInput)
def query_order_status(order_id: str, include_logistics: bool = True) -> dict:
"""查询订单状态和物流信息。"""
return order_api.query(order_id, include_logistics)
这不是为了写得漂亮。
这是为了让模型知道参数含义,也是为了让系统能在执行前做校验。
源码里,BaseTool._parse_input 会根据 args_schema 解析和校验输入。校验失败,不应该继续执行工具。
企业项目里,这一步非常关键。因为 Tool 一旦执行,后面连的可能就是订单库、资金系统、客服系统、股票行情系统。
八、Tool 的返回值怎么选?
Tool 的返回值不是随便 return。返回什么,决定模型后面怎么处理。
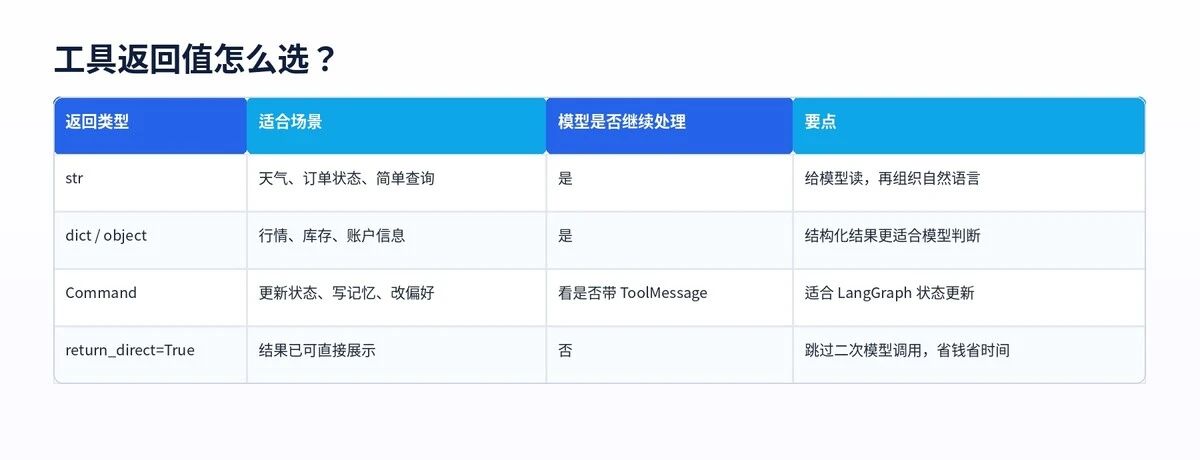
如果结果要继续让模型总结,就返回字符串或对象。
如果结果已经是最终答案,就用 return_direct=True。
如果工具需要修改 Agent 状态,例如保存用户偏好、更新上下文、写长期记忆,可以返回 Command。
官方文档也明确区分了几类返回值:字符串、对象、Command,以及 return_direct。
九、ToolRuntime:工具如何拿到状态、上下文和存储?
早期写工具,很多人只会传业务参数。
但生产环境里,工具经常还需要知道:当前用户是谁、当前会话是什么、线程 ID 是什么、有没有上下文、有没有长期记忆。
这就需要 ToolRuntime。
from langchain.tools import tool, ToolRuntime
@tool
def get_account_info(runtime: ToolRuntime) -> str:
"""获取当前用户的账户信息。"""
user_id = runtime.context.user_id
return account_service.get(user_id)
ToolRuntime 可以访问 state、context、store、stream_writer、execution_info 等运行时信息。
更重要的是,runtime 这类参数是注入参数,通常不会暴露给模型。
这就把“模型可见的参数”和“系统内部运行参数”分开了。
这点对权限控制非常重要。用户 ID、租户 ID、权限范围,不应该让模型自己猜,也不应该让用户从 Prompt 里传。
十、Tool 不是越多越好
很多人做 Agent 的第一个错误,就是一次性塞几十个工具。
模型看到太多工具,会混乱。工具描述太像,会误选。工具参数太复杂,会乱传。
所以 Tool 设计有三个原则。
第一,少而准。一个工具只做一件事。
第二,名字清楚。不要叫 tool1、query、search_all。
第三,描述明确。告诉模型什么时候用,什么时候不用。
比如订单系统,不要只写“查询订单”。
应该写:当用户提供订单号并询问物流、支付、退款、发货状态时使用。
十一、企业级 Tool 必须过安全网
Tool 连着真实业务。
所以它不能像 Demo 一样裸跑。

权限要在工具执行前判断。参数要在工具执行前校验。高危动作要人工确认。执行过程要有超时、重试、审计、脱敏。
大模型不是权限系统。Prompt 也不是权限系统。
能不能执行工具,不能由模型说了算,必须由业务系统说了算。
十二、Tool 错误应该怎么处理?
工具一定会失败。
接口超时。数据库异常。参数错误。权限不足。第三方限流。
如果直接把异常堆栈扔给模型,模型可能会胡乱解释。
正确做法是把异常转成 ToolMessage,让模型知道工具失败了,但不要暴露敏感细节。
@wrap_tool_call
def handle_tool_errors(request, handler):
try:
return handler(request)
except Exception:
return ToolMessage(
content="工具调用失败,请检查参数或稍后重试。",
tool_call_id=request.tool_call["id"],
)
生产环境里,错误处理建议分三层。
第一层,参数错误,直接提示模型换参数。
第二层,临时失败,自动重试。
第三层,高危或不可恢复错误,转人工或返回兜底答案。
十三、在 Java + Python 架构里,Tools 应该放在哪里?
对于 Java 后端项目,不建议把所有 AI 能力都塞进 Spring Boot。
更稳的方式是:Java 主服务管业务、权限、审计、数据;Python AI 服务管 LangChain、Agent、Tools、RAG。
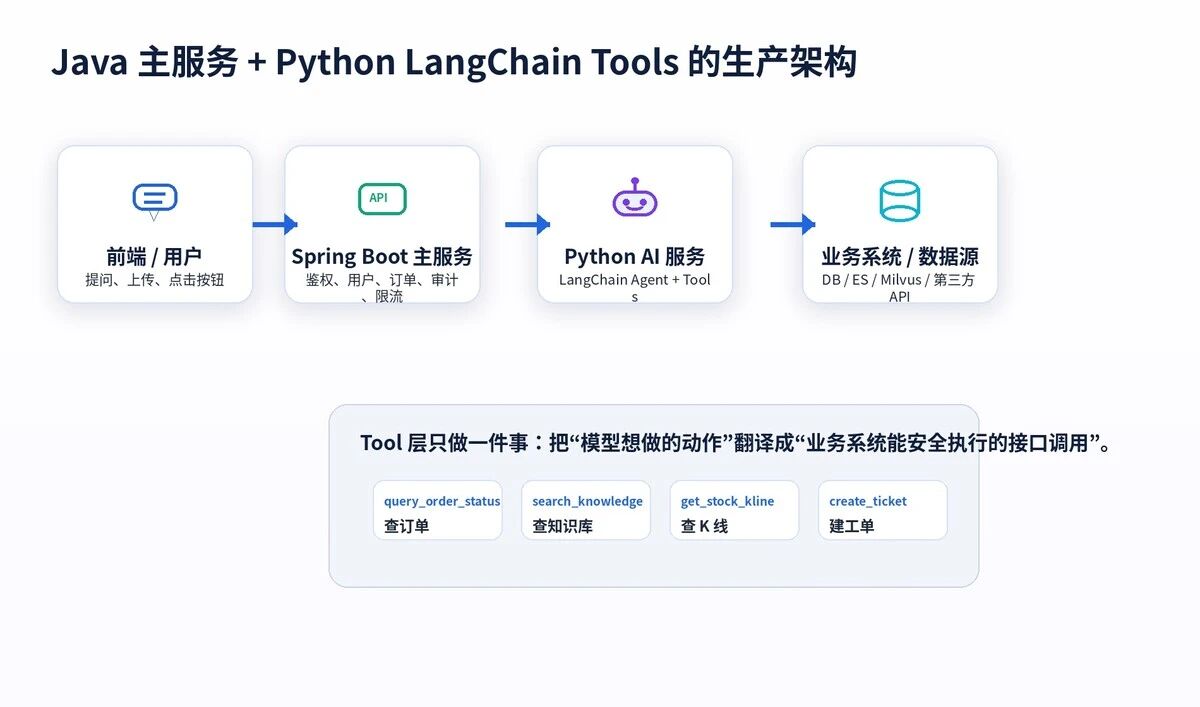
Tools 不应该绕过 Java 主服务直接打数据库。
最稳的链路是:模型请求 Tool,Python Tool 调 Java 内部接口,Java 再做鉴权、限流、审计、业务校验,最后返回结果。
这样做的好处很明显。
AI 服务可以快速迭代。业务规则仍然掌握在 Java 服务里。权限和审计不会失控。
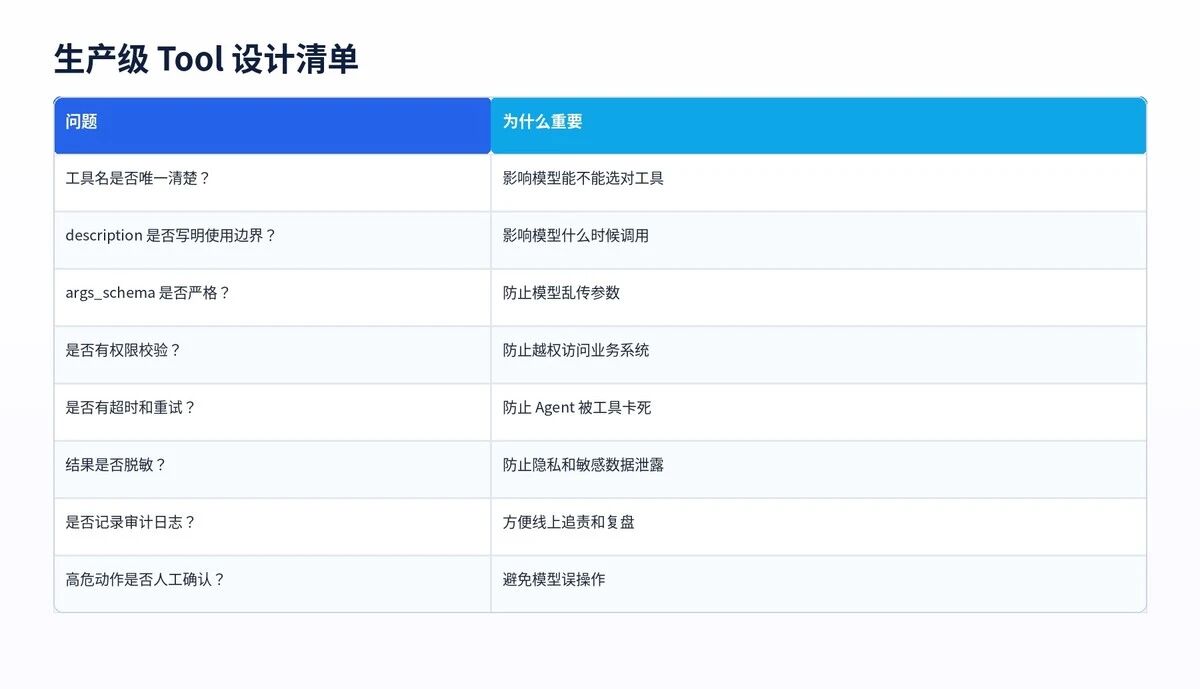
十四、生产环境的 Tool 设计清单
写 Tool 之前,先问这 10 个问题。
十六、总结
RAG 解决“模型不知道”的问题。Tools 解决“模型不能做”的问题。
Tool 不是一段随便暴露给模型的函数。
它是模型和业务系统之间的协议层、安全层、执行层。
源码上,Tool 继承 RunnableSerializable,通过 invoke 进入 run,再经过参数解析、类型校验、真实函数执行,最后把结果返回给模型。
工程上,Tool 必须有权限、校验、审计、超时、重试、脱敏和人工确认。
真正成熟的 Agent,不是模型更强,而是工具设计得更稳。
一句话收尾:Tools 是 Agent 的手脚,但这双手脚必须戴上工程化的安全手套。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献232条内容
已为社区贡献232条内容

所有评论(0)