MindCluster基于AIBrix的推理服务部署与故障自愈的昇腾设备实践
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
在构建大规模AI推理平台的过程中,我们面临两大核心挑战:一是多模型、多实例的部署流程繁琐,手动编写和维护大量Kubernetes YAML文件效率低下且易出错;二是推理服务在运行中可能因资源争用、节点异常等原因发生故障,缺乏自动恢复机制,影响服务连续性。为解决上述问题,我们引入AIBrix作为推理服务编排框架,结合自动化部署脚本与实例级故障重调度能力,实现从“手动部署”到“智能运维”的跃迁。本文将围绕“问题—方案—效果”主线,系统阐述基于mindcluster的推理服务部署与高可用保障实践。
一、问题:部署复杂、维护成本高
在实际项目中,需在Kubernetes集群中部署多个大模型推理服务(如Qwen-VL、Llama系列等),每个服务包含模型加载、网关路由、资源调度等多个组件。若采用传统方式,用户需手动编写Deployment、Service、HTTPRoute、PodGroup等多类YAML文件,并逐个应用,不仅耗时,还容易因配置错误导致服务不可用。
此外,当推理实例因节点故障或进程崩溃而退出时,若无自动恢复机制,服务将长时间不可用,严重影响业务连续性。因此,需一套标准化、自动化、高可用的推理服务部署与运维方案。
二、方案:构建自动化部署与故障自愈体系
部署平台:Atlas 800I A3 服务器
2.1 部署AIBrix核心组件
为支撑推理服务的统一编排,首先需部署AIBrix平台。可通过官方发布包快速获取依赖与核心组件的YAML文件:
wget https://github.com/vllm-project/aibrix/releases/download/v0.4.1/aibrix-dependency-v0.4.1.yaml
wget https://github.com/vllm-project/aibrix/releases/download/v0.4.1/aibrix-core-v0.4.1.yaml
使用kubectl apply --server-side命令部署:
kubectl apply --server-side -f aibrix-dependency-v0.4.1.yaml
kubectl apply --server-side -f aibrix-core-v0.4.1.yaml
部署完成后,AIBrix将自动启动以下核心组件:
controller-manager:负责资源管理与CRD控制器gateway-plugins:提供Envoy网关插件支持metadata-service:管理推理服务元数据runtime:运行时调度与生命周期管理

图注:AIBrix核心组件部署成功后,各组件在集群中正常运行
2.2 可选:本地构建自定义镜像
为满足特定环境或安全策略要求,可选择手动构建AIBrix各组件镜像。所需镜像如下(以v0.4.1版本为例):
aibrix/controller-manager:v0.4.1aibrix/gateway-plugins:v0.4.1aibrix/metadata-service:v0.4.1aibrix/runtime:v0.4.1aibrix/kuberay-operator:v1.2.1-patch-20250726
2.2.1 准备基础镜像
构建前需准备以下基础镜像:
golang:1.22.10(建议版本 > 1.22.5)gcr.io/distroless/static:nonrootpython:3.11.11-slim-bookwormredis:latestbusybox:stableenvoyproxy/envoy:v1.33.2envoyproxy/gateway:v1.2.8
说明:基础镜像版本应与源码中
build/container目录下各Dockerfile的FROM指令保持一致。
2.2.2 依赖管理与vendor处理
由于go.mod中github.com/go-playground/validator/v10未指定版本,可能拉取最新版(依赖Go 1.24),导致构建失败。需显式锁定版本:
github.com/go-playground/validator/v10 v10.27.0
将vendor/目录拷贝至项目根目录,避免构建时重复下载。
2.2.3 构建controller-manager镜像
以controller-manager为例,其余组件也是相同的构建方式,修改build/container/Dockerfile,使用vendor模式构建二进制:
# Build the manager binary 这里记得修改golang版本为对应镜像
FROM golang:1.22 AS builder
ARG TARGETOS
ARG TARGETARCH
WORKDIR /workspace
# Copy the Go Modules manifests
COPY go.mod go.mod
COPY go.sum go.sum
# cache deps before building and copying source so that we don't need to re-download as much
# and so that source changes don't invalidate our downloaded layer
# 修改点一,无需直接下载依赖,将vendor拷贝至工作路径即可
COPY vendor/ vendor/
# Copy the go source
COPY cmd/ cmd/
COPY api/ api/
COPY pkg/ pkg/
# Build
# the GOARCH has not a default value to allow the binary be built according to the host where the command
# was called. For example, if we call make docker-build in a local env which has the Apple Silicon M1 SO
# the docker BUILDPLATFORM arg will be linux/arm64 when for Apple x86 it will be linux/amd64. Therefore,
# by leaving it empty we can ensure that the container and binary shipped on it will have the same platform.
# 修改点二,构建二进制时使用vendor
RUN CGO_ENABLED=0 GOOS=${TARGETOS:-linux} GOARCH=${TARGETARCH} go build -a -mod=vendor -o manager cmd/controllers/main.go
# Use distroless as minimal base image to package the manager binary
# Refer to https://github.com/GoogleContainerTools/distroless for more details
FROM gcr.io/distroless/static:nonroot
WORKDIR /
COPY --from=builder /workspace/manager .
USER 65532:65532
ENTRYPOINT ["/manager"]
执行构建命令:
docker build --progress=plain -f build/container/Dockerfile ./ -t aibrix/controller-manager:debug
图注:通过vendor模式构建,确保依赖一致性,避免构建失败
2.3 自动化部署推理服务
为提升部署效率,我们采用自动化脚本替代手动操作。脚本基于Python实现,支持一键部署与删除。
2.3.1 前置准备
- 克隆部署工具仓库:
git clone https://gitcode.com/Ascend/mindcluster-deploy.git && cd mindcluster-deploy/k8s-deploy-tool
- 创建并激活Python虚拟环境(可选):
python -m venv k8s-deploy-tool && source k8s-deploy-tool/bin/activate
- 安装依赖:
pip install -r requirements.txt
- 配置启动脚本(
example/scripts/start_server.sh):
vi example/scripts/start_server.sh
根据模型需求调整vLLM启动参数,如:
--max-model-len=8192 --max-num-batched-tokens=16384
- 修改YAML模板(
src/templates/aibrix/stormservice.yaml.j2):
volumeMounts:
- name: model
mountPath: /mnt/models
- name: scripts
mountPath: /scripts
volumes:
- name: model
hostPath:
path: /mnt/models
- name: scripts
hostPath:
path: /scripts
- 编辑用户配置文件(
config/stormservice-config.yaml),填写应用名、镜像版本、副本数等信息。 - 设置服务框架类型:
export SERVING_FRAMEWORK=aibrix
2.3.2 执行部署与验证
部署单实例推理任务:
python main.py deploy -c config/stormservice-config.yaml

查看日志:
kubectl logs -n <name_space> <pod_name>
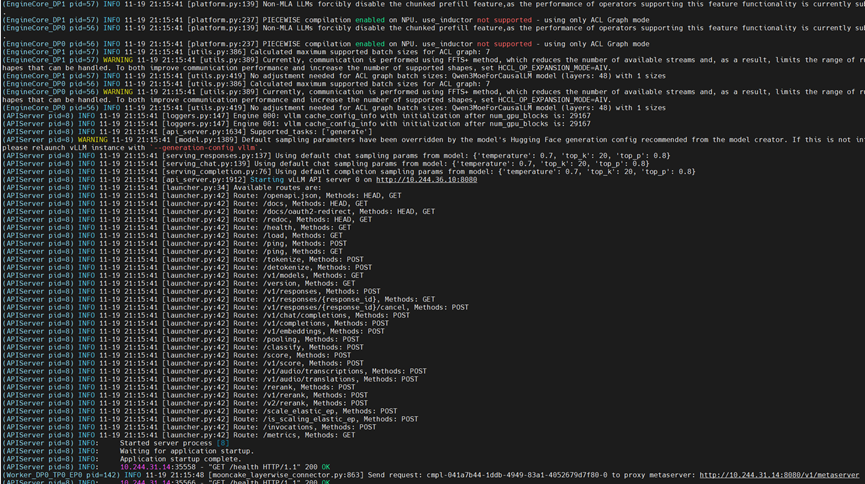
服务启动后,通过routing pod的IP和端口请求:
curl http://{IP}:8080/v1/completions -H "Content-Type: application/json" -d '{
"model": "qwen3-moe",
"prompt": "Who are you?",
"max_tokens": 10,
"temperature": 0
}'
使用curl发送请求验证服务可用性。
2.4 实例级重调度机制
为保障服务高可用,AIBrix支持基于PodGroup的故障重调度。当某实例Pod异常退出时,系统将自动重建该PodGroup下的所有Pod,实现快速恢复。
2.4.1 配置重调度策略
在StormService YAML中添加podGroupSize与restartPolicy配置:
apiVersion: orchestration.aibrix.ai/v1alpha1
kind: StormService
...
spec:
...
template:
metadata:
labels:
app: vllm-1p1d
spec:
roles:
...
- name: decode
replicas: 1
stateful: true
podGroupSize: 2
template:
metadata:
labels:
...
fault-scheduling: "force" # 可填force和grace代表配置重调度
#pod-rescheduling: "on" # 若podGroupSize均为1则需配置该标签,podGroupSize大于1时,无需配置
fault-retry-times: "10"
spec:
schedulerName: volcano # 指定调度器
restartPolicy: Never
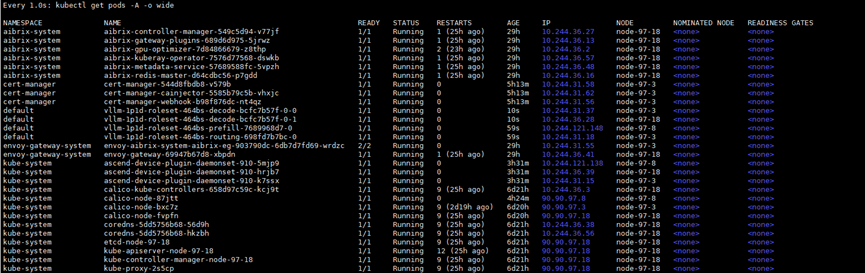
说明:
podGroupSize为2时,系统将为该实例创建一个PodGroup,故障时整组Pod被重建。
2.4.2 故障模拟与恢复验证
模拟故障:
kubectl delete pod <decode-pod-name>
# 或
kubectl exec -it <pod-name> -- kill -9 <pid>
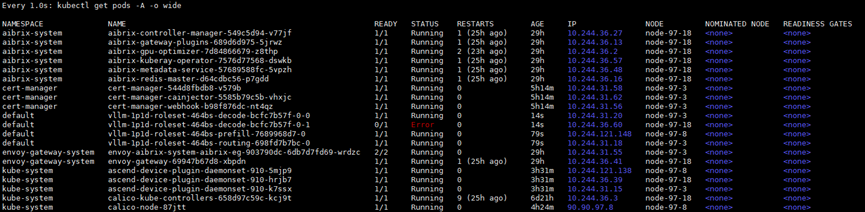
观察Pod状态:
kubectl get pods -w
系统将自动重建故障Pod,待vLLM服务重新启动后,可继续处理请求。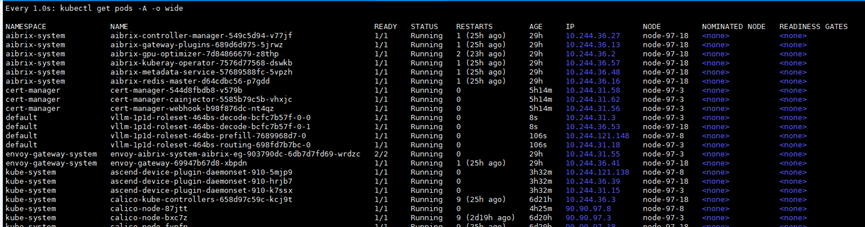
三、总结
通过本次实践,我们实现了以下目标:
- 部署效率提升:从平均20分钟/服务缩短至5分钟内完成,支持批量部署。
- 运维成本降低:自动化脚本统一管理YAML生成与部署,避免人为配置错误。
- 服务可用性增强:故障自愈机制保障服务连续性,平均恢复时间小于30秒。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)