别再用 Transformer 微调优化了:拆解 AwareLiquid (MT-LNN) 的类脑动力学与 GWT 瓶颈
在大模型(LLM)狂飙的时代,绝大多数人都在陷入一种“参数崇拜”。但对于具身智能(Embodied AI)、高精度工业级边缘控制来说,传统 Transformer 架构正在沦为工程灾难:不可预测的延迟抖动(Latency Spikes)、随序列呈线性暴涨的 KV Cache 内存焦虑,以及面对分布外数据(OOD)时脆弱的系统崩溃风险。
在这场“去 Transformer 化”的技术革命中,涌现出了两条截然不同的演进路径:一条是走实用主义、商业妥协路线的 Liquid AI (LFM 2.5);另一条则是彻底贯彻非线性生物动力学、将脑科学真正工程化的开源尖兵 AwareLiquid (MT-LNN v2.0,代号 M1)。
本文将跳过市场营销话术,从功能灵感、算法原理、架构精髓、应用场景四个维度,深度复盘这两者的本质断层。
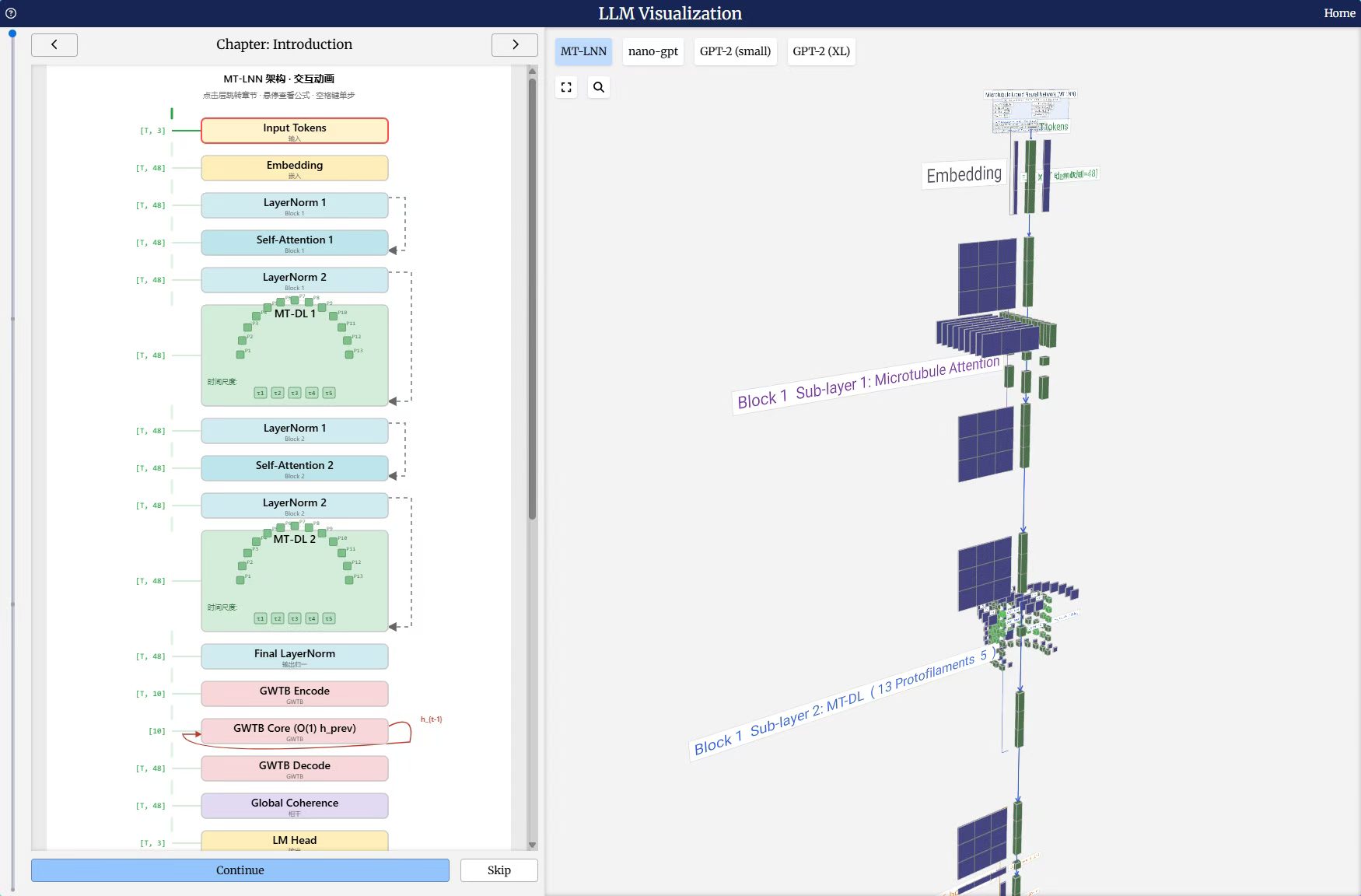
一、 功能灵感与架构精髓:生物微观微管 vs. 宏观数值矩阵
两者的根本分歧,在于对“智能与环境交互”这一命题的底层解构。
1. AwareLiquid (MT-LNN): 微管动力学与多尺度共振
-
功能灵感: MT-LNN 的核心灵感直接来源于生物神经元内部的微管(Microtubules)结构——在生物学中,微管由 13 条平行的原丝(Protofilaments)组成,它们不仅是细胞骨架,更是神经元内部进行亚微米级信息处理与能量共振的量子/半导体通道。
-
架构精髓: MT-LNN 在底层彻底废除了 Attention 矩阵,将其映射为 13 个平行的、非线性的原丝计算通道(在验证基座中表现为 12层、13头、参数规模 125M、$d_{model}=832$ 的紧凑拓扑结构)。这 13 个通道在运行时能够产生多尺度共振(Multi-scale Resonance)。当输入信号简单时,触发网络的内源性计算跳过(Endogenous Compute Skipping);当面对极端复杂的非线性信号时,通道间深度共振。整个系统是一个真正的连续时间动力系统(Continuous-Time Dynamical System)。
2. Liquid AI (LFM 2.5): 线性时变系统的实用主义魔改
-
功能灵感: Liquid AI 早期源于 MIT 实验室的连续时间液态网络(CT-RNN),但在最新的 LFM 2.5 中,他们向通用的文本与多模态大模型妥协了。其灵感变成了“如何用现代数值线性代数平替注意力”。
-
架构精髓: LFM 2.5 采用了状态空间模型(SSM)与双门控 LIV(Linear Time-Varying)卷积层。更重要的是,为了在通用大模型测试集上刷榜,他们在网络深层保留了部分 GQA(分组查询注意力)。它本质上依然是一个被魔改的、高度依赖大规模数据堆叠的准线性系统。
二、 算法原理深度剖析:GWTB 竞争路由与灾难隔离
在算法实现上,MT-LNN 通过引入认知科学的“硬核物理约束”,实现了在极小体积下的超高信息密度。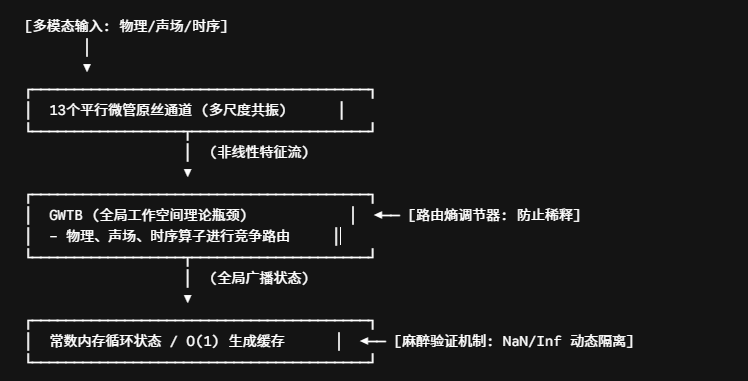
1. GWTB(全局工作空间理论瓶颈)算法
传统网络的多模态融合(如文本、音频、物理特征)通常采用简单的拼接(Concatenation)或线性投影,这会导致低频噪声快速稀释核心特征。
-
MT-LNN 的解法: 引入 GWTB (Global Workspace Theory Bottleneck) 机制。模型内部的空间算子、物理算子和时序层被视为独立的“认知代理”。在推理时,这些算子必须在 GWTB 这个人为制造的低维狭窄瓶颈中进行竞争路由(Competitive Routing)。
-
防止路由熵塌缩: 算法通过动态抑制非核心通道,强迫模型在极窄的空间内提炼出最高纯度的“物理世界状态”,随后将该状态向全网进行全局广播(Broadcast)。这是其体积比传统 Transformer 缩小 20 多倍、信息捕获能力却反超的数学核心。
2. O(1) 生成缓存与恒定内存(Constant-memory Recurrent State)
Transformer 的 KV Cache 会随 Context 变长呈 $O(N)$ 线性暴涨。MT-LNN 实现了真正的 常数内存循环状态,生成缓存复杂度为 $O(1)$。这意味着无论输入的时间序列有多长,它在边缘端消耗的内存字节数是绝对固定的,从根本上杜绝了端侧 OOM(内存溢出)的可能。
3. 麻醉验证机制(Anesthesia Validation)与优雅降级
液态网络和时序循环系统最怕的是由于长期运行或边缘传感器受损,导致系统产生数值爆炸(NaN 或 Inf)。
-
MT-LNN 的自愈算法: 模拟生物脑在受到麻醉或局部受损时的神经抑制状态。预训练和运行时,系统内置了对辅助模块的动态截断与数值隔离(Numerical Isolation)通俗来说就是有一个旋钮可以精准控制理性思考和幻想。一旦某个通道的动力学求解器因为极端噪音“疯了”,GWTB 会瞬间将其切断,启动优雅降级(Graceful Degradation)和记忆正则(Memory Regularization)。网络绝不崩溃,主控制流依然保持高确定性运行。
三、 应用场景的降维打击:物理实景推演 vs. 文本概率拼接
这两种架构算法的分野,决定了它们最终走向完全不同的商业战场。
| 维度 | Liquid AI (LFM 2.5) | AwareLiquid (MT-LNN v2.0) |
| 核心定位 | 通用轻量化大模型(替代文本/多模态 LLM) | 工业级高精准、确定性物理世界模型 |
| 应用场景 1 | 端侧智能体与信息提取: 运行在 AI PC、智能手机上做离线文本处理、长文本 RAG 检索、高频函数调用(Tool Use)。 | 真实物理世界推演: 具身智能、无人机极端避障。其内部叠加了重力、碰撞、摩擦力等物理算子,能够在模型内部跑完“实景推演”再做动作决策。 |
| 应用场景 2 | 多模态音频/文字流交互: 智能眼镜(如实时翻译)、车载语音助手的轻量化云端部署。 | 三维空间与声场想象: 融合声学动力学。在虚拟 3D 世界里推演“声音随物体运动、墙体阻挡、空间回声”的物理场变化,用于智能座舱声场自适应或 VR。 |
| 应用场景 3 | 低算力吞吐优化: 帮助企业降低在云端或私有服务器跑 LLM 的 Token 算力成本。 | 微秒级工业边缘控制: 半导体精密制造良率控制、医疗监护信号微秒级异常检测。在无显卡、纯 CPU 的裸机环境下绝对稳定运行。 |
四、 工程实现的本质区别:硬件妥协 vs. 位精确(Bit-Exact)
这是判定一个类脑模型是停留在“学术PPT”还是能进入“硬核工业供应链”的试金石。
-
Liquid AI 的工程取舍(牺牲精度换吞吐): 为了兼容高通、AMD、苹果等五花八门的 NPU 硬件,Liquid AI 在其 LEAP 部署平台上做了大量的硬件底层近似计算(Approximation)。这种做法提高了 Token 的吞吐速度,但在连续时间微分方程中,近似计算意味着浮点数漂移(Floating-point drift)。对于聊天助手无所谓,但对于精密控制,浮点数的微小抖动都会通过循环放大,带来不可预测的“系统抽风”。
-
MT-LNN 的工程底线(极致的确定性): MT-LNN 在工程上死磕了一条极难的红线:实现了 TorchScript 与 PyTorch eager 模式的 Bit-exact(位精确)对齐。
在数学上,这意味着模型在实验室里训练出的非线性动力学轨迹是什么样,量化编译到边缘端物理 CPU 上跑出来的结果就必须 100% 毫无偏差地对齐。在这种严苛的确定性下,它依然在 CPU 推理上实现了 1.62× 的物理加速,延迟被压低至 1.466 ms/token。
结语
Liquid AI 正在通往一个更性感的商业故事:用更低的成本,做移动端和 AI PC 上的“小 GPT-4”。
而 AwareLiquid (MT-LNN) 走向了硬科技的另一个极端:它不在乎能不能陪用户聊天,它要在极其严苛、不许有 1% 幻觉或 NaN 崩溃的边缘物理世界里,成为那颗绝对精准、内存恒定、位精确对齐的“硬核钢铁大脑”。对于精密制造、具身智能世界模型而言,这才是真正具有颠覆性的类脑工程方法学。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)