LabVIEW亚毫秒级定时深度解析
在工程测控与数据采集应用中,经常需要在Windows操作系统下实现小于1毫秒的定时精度。然而,Windows并非实时操作系统,其默认的系统时钟中断频率仅为64Hz(约15.6ms),导致常规的Wait(ms)函数无法满足亚毫秒级定时的需求。本文从Windows系统底层定时机制出发,深入剖析LabVIEW中多种定时函数的实现原理——包括Wait(ms)、Wait Until Next ms Multiple、High Resolution Relative Seconds和High Resolution Polling Wait,对比各自的精度、适用场景与局限性,并结合实际工程经验给出最佳实践建议。
一、项目背景:为什么需要亚毫秒级定时?
在现代工业自动化与测试测量领域,LabVIEW被广泛应用于高速数据采集、实时信号分析、精密运动控制等场景。这些应用对定时精度提出了越来越高的要求:
- 高速数据采集系统中,采样间隔需要精确到微秒级,以确保波形重建的准确性;
- 数字通信协议模拟(如SPI、I2C)中,时钟信号的占空比和时序需要严格可控;
- 精密运动控制中,脉冲输出间隔决定了步进电机的运行平稳性;
- 实时信号处理链路中,各处理阶段的同步定时直接影响系统整体性能。
然而,Windows通用操作系统的设计目标是多任务公平调度和系统响应性,而非精确定时。这就带来了一个核心矛盾:工程师惯于在Windows + LabVIEW环境下快速开发原型和部署系统,但默认的定时机制无法满足高精度需求。理解这一矛盾的根源,并掌握正确的解决路径,是每个进阶LabVIEW开发者必须攻克的课题。
二、Windows定时机制全景
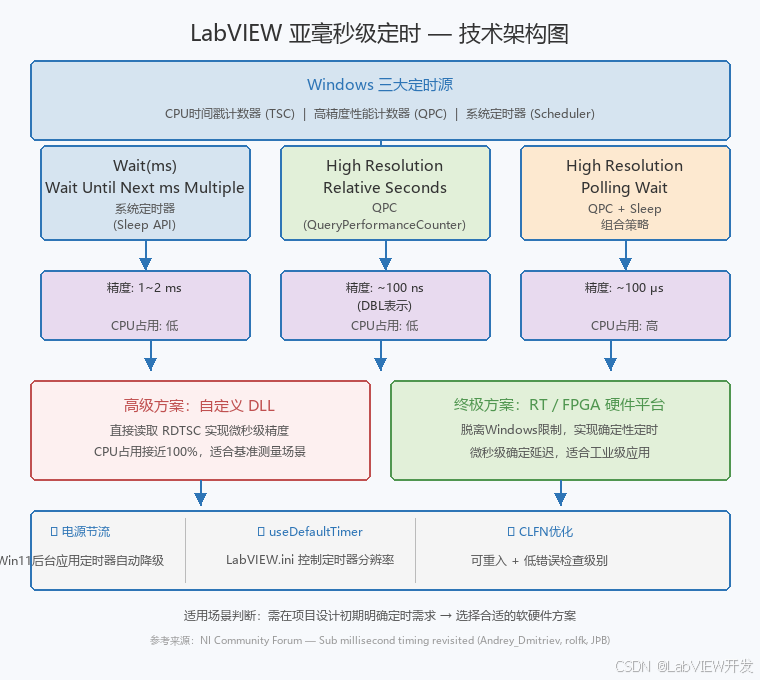
图1 LabVIEW亚毫秒级定时技术架构图
2.1 三大定时源
|
定时源 |
典型精度 |
LabVIEW对应VI |
原理说明 |
|
CPU时间戳计数器 |
~0.3 ns |
无直接对应 |
CPU内置计数器,以恒定频率递增。 |
|
高精度性能计数器 |
~100 ns |
High Resolution |
Windows抽象层,内部由TSC经 |
|
系统定时器 |
1~15.625 ms |
Wait(ms) |
由Sleep() API实现。默认64Hz, |
2.2 系统定时器的工作原理
深入理解系统定时器的工作机制,是掌握LabVIEW定时行为的关键。当LabVIEW中调用Wait(ms)或Sleep() API时,操作系统会将当前线程从“运行”状态切换为“等待”状态,线程的上下文(寄存器、指令指针等)被保存到内核维护的线程对象中,同时一个定时器对象被插入内核的定时器队列。在等待期间,线程不消耗任何CPU时间,处于完全的“静止”状态。
定时器到期后,内核将线程状态切换为“就绪”。注意:线程并不会立即恢复执行!调度器需要根据线程优先级、CPU核心可用性和系统负载等因素,选择合适的时机将线程调度到CPU上运行。这意味着:Sleep(n)保证的是最短等待时间,而非精确的n毫秒——线程可能因为调度延迟而更晚醒来。这正是Windows非实时性的根本原因。
一个关键细节:首次调用Sleep(1)时,实际延迟可能在1~16ms之间波动,因为线程与系统定时器滴答之间的相位关系是随机的。而后续调用会因为与定时器滴答同步,稳定在约15ms的延迟。这也是很多初学者在LabVIEW中测量Wait(1)时发现结果远大于1ms的原因。
2.3 高精度性能计数器(QPC)的工作原理
QueryPerformanceCounter()是Windows提供的高精度计数器,在现代系统上典型频率约为10 MHz(即100 ns分辨率)。其内部实现基于CPU的TSC计数器,但经过操作系统层面的校准因子进行了归一化处理。具体而言,QPC读取TSC值后,经过128位乘法运算(使用预计算倒数)将其转换为标准频率。校准因子并非固定不变,系统重启后可能会有微小变化(例如269.3761与269.3762之间的差异),这是由于CPU基础频率和总线时钟可能存在细微波动。
在LabVIEW中,High Resolution Relative Seconds.vi和High Resolution Polling Wait.vi正是基于QPC实现的。前者返回当前值与起始值的差值,以双精度浮点数(DBL)格式表示为秒数——需要注意的是,即便结果为DBL类型,底层分辨率仍受限于QPC的100 ns粒度。后者则在前者的基础上,结合了一个轮询(Polling)循环来实现精确等待。
三、核心功能实现与对比
3.1 Wait(ms) 与 Wait Until Next ms Multiple
这两个VI是LabVIEW中最常用的定时函数,它们底层均映射到Windows的Sleep() API。LabVIEW运行引擎中的调用链为:RealWait() → ThSleep() → Sleep()。
NI在LabVIEW启动时,通过调用timeBeginPeriod()将系统定时器分辨率从默认的64 Hz(15.625 ms)提升至1 kHz(1 ms)。这意味着Wait(1)实际延迟通常在1~2 ms之间(偶尔因系统负载略高)。可以通过powercfg -energy命令生成能耗分析报告来验证这一行为,报告中会明确显示LabVIEW.exe请求了10,000个100 ns单位(即1 ms)的定时器分辨率。
Wait Until Next ms Multiple在原理上与Wait(ms)一致,只是额外增加了读取当前Tick Count(通过GetTickCount())的步骤,并动态调整睡眠时长以对齐到下一个毫秒边界,底层机制并无本质区别。
3.2 High Resolution Polling Wait
这是LabVIEW在Windows平台上实现亚毫秒级定时的核心VI。其实现思路是组合策略:大部分延迟时间使用Sleep()实现(省CPU),最后约2 ms使用基于QPC的轮询循环实现(保精度)。轮询循环的核心是一个不断调用QueryPerformanceCounter()并比较当前值与目标值的while循环。
需要注意的是,这个轮询循环并非“轻量级”操作。经过分析,LabVIEW中每次循环迭代大约执行384条CPU指令,涉及约15次内部函数调用——大部分开销来自于LabVIEW DLL调用封装层(ExtFuncWrapper)。这也解释了为什么该VI在循环中频繁调用时CPU占用率较高。
实际测试表明,High Resolution Polling Wait在1~2 ms的延迟范围内表现良好,但在极短延迟(如50 μs)场景下,轮询循环本身的执行时间已经占据了请求延迟的相当比例,导致精度显著下降。这是其固有局限性。
3.3 TSC直接定时的极端方案
对于真正需要微秒甚至纳秒级精度的场景,可以通过编写DLL直接读取CPU时间戳计数器来实现。使用RDTSC指令读取TSC值,并在一个紧凑的循环中轮询等待。在3.1 GHz CPU上,50 μs相当于约155,000个TSC周期,轮询循环仅需6条CPU指令(包括RDTSC、减法、比较和条件跳转),远低于LabVIEW中通过CLFN调用QPC的开销。
但该方案的工程实用性有限:首先,Windows作为非实时OS,高优先级中断和线程调度仍然可能打断轮询循环;其次,轮询循环期间CPU占用率为100%,不适合需要同时处理其他任务的系统。此外,在多核心系统上TSC可能因线程在不同核心间迁移而引入额外误差。该方案更适合在专用测试场景中作为基准测量工具,而非产品代码的直接组成部分。
四、使用场合、特点与注意事项
4.1 使用场合建议
|
定时需求 |
推荐方案 |
预期精度 |
备注 |
|
常规循环(>10 ms) |
Wait(ms) |
±1~2 ms |
最低CPU占用,满足大部分 |
|
中等精度(1~10 ms) |
Wait Until Next |
±1~2 ms |
适合固定采样率场景, |
|
高精度短时延迟 |
High Resolution |
±50~200 μs |
轮询模式会增加CPU负载, |
|
极高精度测量 |
自定义DLL |
±1~10 μs |
需要编写底层DLL, |
|
实时确定性要求 |
NI RT/FPGA |
微秒级确定 |
脱离Windows, |
4.2 Windows 11 电源节流的影响
Windows 11引入了更积极的电源管理策略:当应用程序窗口最小化或处于后台时,系统会自动将定时器分辨率降低回默认的~15.6 ms。这是导致LabVIEW程序在后台运行时定时精度突然恶化的根本原因。可以通过以下方式禁用针对特定进程的节流:
powercfg /powerthrottling disable /path "C:\Program Files\National Instruments\LabVIEW 2026\LabVIEW.exe"
也可以通过WinAPI函数SetProcessInformation()在程序内部编程禁用电源节流。验证设置是否生效:powercfg /powerthrottling LIST。如需恢复,使用powercfg /powerthrottling reset。
4.3 useDefaultTimer 配置项
在LabVIEW.ini中添加useDefaultTimer=true后,LabVIEW将不再主动将系统定时器分辨率提升至1 ms。这意味着Wait(ms)的延迟将回到1~16 ms的“原生”范围。该选项在某些对系统功耗敏感的场景(如电池供电的便携测试设备)中有实际意义,但在需要精确定时的场合应谨慎使用。
4.4 CLFN调用优化的关键
如果在LabVIEW中通过Call Library Function Node调用DLL实现高性能定时,以下两个优化点至关重要:
- 线程安全设置:将CLFN设置为“可在任意线程中运行”(Reentrant)避免在UI线程中执行,减少线程切换开销和与界面刷新的竞争。
- 错误检查级别:在“错误检查”选项卡中选择最低级别关闭异常捕获和内存边界检查(Trampoline),避免额外的性能损耗。
实测表明,正确的线程设置可将长时间运行的CLFN调用性能提升百倍以上,而错误检查级别的影响同样显著,尤其在微秒级定时场景中不可忽视。
五、与RT/FPGA平台的对比
理解Windows定时的局限性后,有必要与NI的实时(RT)和FPGA目标平台进行对比。在RT平台上(如cRIO、PXI RT控制器),Wait(ms)的行为本质上没有区别——操作系统仍然根据系统负载调度线程,只是RTOS的调度延迟更短、更可预测。真正能够提供确定性亚毫秒级定时的是FPGA目标,其逻辑以硬件时钟速率运行。例如,在40 MHz FPGA上实现50 μs延迟,只需计数2,000个时钟周期即可——这是从根本上解决了定时不确定性问题。
因此,对于需要严格亚毫秒级定时的工业应用,建议的架构选择顺序为:FPGA目标 > RT目标 > Windows + QPC/TSC方案 > 纯Windows Wait(ms)。在项目设计初期就明确定时需求,并选择合适的硬件平台,可以避免后期因定时精度不足而大规模重构的困境。
六、实际应用案例
案例一:高速数据采集系统中的采样定时
某振动监测系统需要在Windows平台下以2 kHz采样率(即500 μs间隔)同步采集4通道加速度传感器数据。初始方案使用Wait Until Next ms Multiple(1)循环触发采集,实测发现采样间隔在1~3 ms之间大幅波动,频谱分析中出现了严重的频率混叠。
改进方案:将定时机制改用High Resolution Polling Wait,设置延迟为450 μs(留出~50 μs的代码执行余量),并在每次采集前通过High Resolution Relative Seconds精确记录实际时间戳。改进后采样间隔抖动降低到±50 μs以内,通过软件重采样进一步消除了剩余抖动的频谱影响,满足了后续FFT分析的精度要求。
案例二:步进电机精确脉冲输出
某桌面型点胶设备使用LabVIEW通过并口控制步进电机驱动器。电机需要以20 kHz的脉冲频率运行(即50 μs脉冲周期),以实现平稳的微步进运动。直接使用Wait(ms)显然无法达到所需频率。
初始尝试:使用High Resolution Polling Wait(0.05),发现轮询循环的开销已经超过请求的延迟时间,输出脉冲频率远低于预期且极不稳定。
最终方案:编写了一个C语言DLL,内部基于RDTSC指令实现50 μs精确定时,每次调用输出一个脉冲。CLFN设置为可重入并关闭错误检查,同时使用单独的LabVIEW执行系统(在VI属性中设置)避免与UI线程竞争。系统最终实现了稳定的20 kHz脉冲输出,脉冲宽度抖动<5 μs,满足了设备的工艺要求。但需要注意的是,此方案将CPU占用率推高至接近100%,不适合需要同时执行其他任务的场景。
七、案例总结
Windows环境下LabVIEW的亚毫秒级定时是一个需要深刻理解操作系统底层机制才能妥善解决的技术难题。本文从Windows三大定时源的原理出发,系统梳理了LabVIEW中各定时VI的实现机制、性能特征和适用场景,并给出了清晰的技术选型建议。
核心要点总结如下:
- Wait(ms)和Wait Until Next ms Multiple基于Sleep() API,精度受限于系统定时器分辨率(经LabVIEW提升后为1 ms),适合毫秒级以上的常规延迟。
- High Resolution Polling Wait基于QPC+轮询,可实现~100 μs级精度,但CPU占用较高,适合短时间高精度等待。
- 通过自定义DLL直接操作TSC可获得微秒甚至亚微秒级精度,但工程复杂度高,且Windows的非实时性本质无法因此改变。
- 对于真正需要确定性定时的场景,应选择NI RT或FPGA硬件平台。
- 注意Windows 11电源节流和LabVIEW.ini配置项对定时精度的影响。
最后需要强调的是:在Windows上追求精确定时,本质上是在通用操作系统的非实时约束下寻找最优近似解。理解“最短延迟保证”与“精确延迟保证”之间的根本区别,比记住任何具体API的用法更为重要。希望本文能帮助广大LabVIEW开发者在面对定时相关问题时,拥有更清晰的分析框架和更可靠的技术决策依据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)