从0到1快速了解一个中间件---RabbitMQ消息队列
一,什么是RabbitMQ?
RabbitMQ就是一个开源的消息中间件(基于AMQP协议,用Erlang语言写的,所以它的并发性能极强)。可以把它想象成一个可靠的快递站。
(1)没有RabbitMQ时,系统A直接把数据扔给系统B;如果B忙不过来,或者挂了,A就卡死了,或者数据丢了。
(2)有了RabbitMQ后:系统A把数据扔给RabbitMQ后就不用管了,RabbitMQ会负责把数据暂存起来,然后按照系统B的消息处理能力,稳定的输送给B。
二,基本架构
学习RabbitMQ的架构的话,可以把他想象成我们生活中的快递/物流系统来理解。
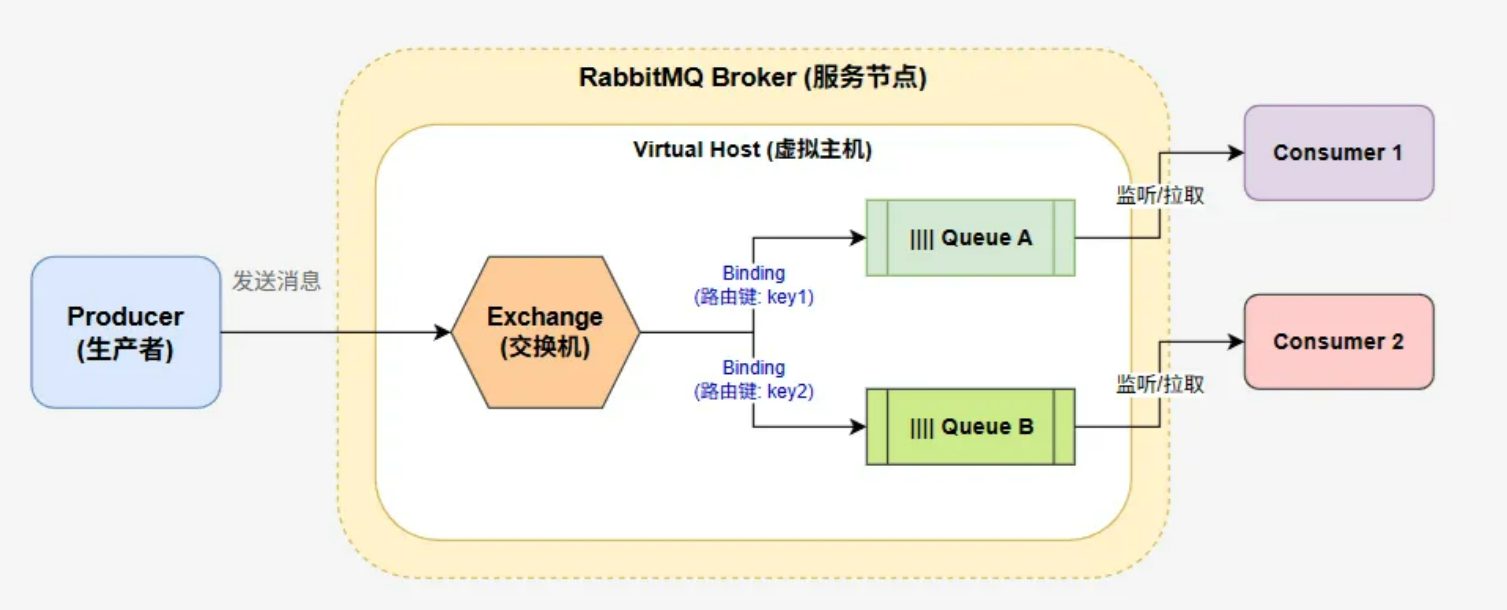
它的核心架构由以下6个关键组件组成:
- Producer(生产者):就是发件人。负责产生消息并发送给RabbitMQ。
- Exchange(交换机):类似于快递分拣中心。这是RabbitMQ最核心的设计,生产者发的包裹不是直接投进队列,而是先发送给交换机。交换机根据包裹上的“地址”(routing key)决定把它扔进哪个队列。
- Queue(队列):类似于快递仓库。消息最终存放的地方,等待被取走。一个消息可以被拷贝到多个队列,但一个队列里的消息只能被消费一次。
- Binding(绑定):类似于分拣规则表。负责告诉交换机哪条消息应该发送到哪个队列。
- Consumer(消费者):收件人。从队列里去消息并处理。
- Virtual Host(虚拟主机):就是独立租户。好比一台服务器上跑了多给MySQL数据库(DB1,DB2...)。VHost之间是完全隔离的,互不影响,通常用于区分不同的业务线(订单、用户...)
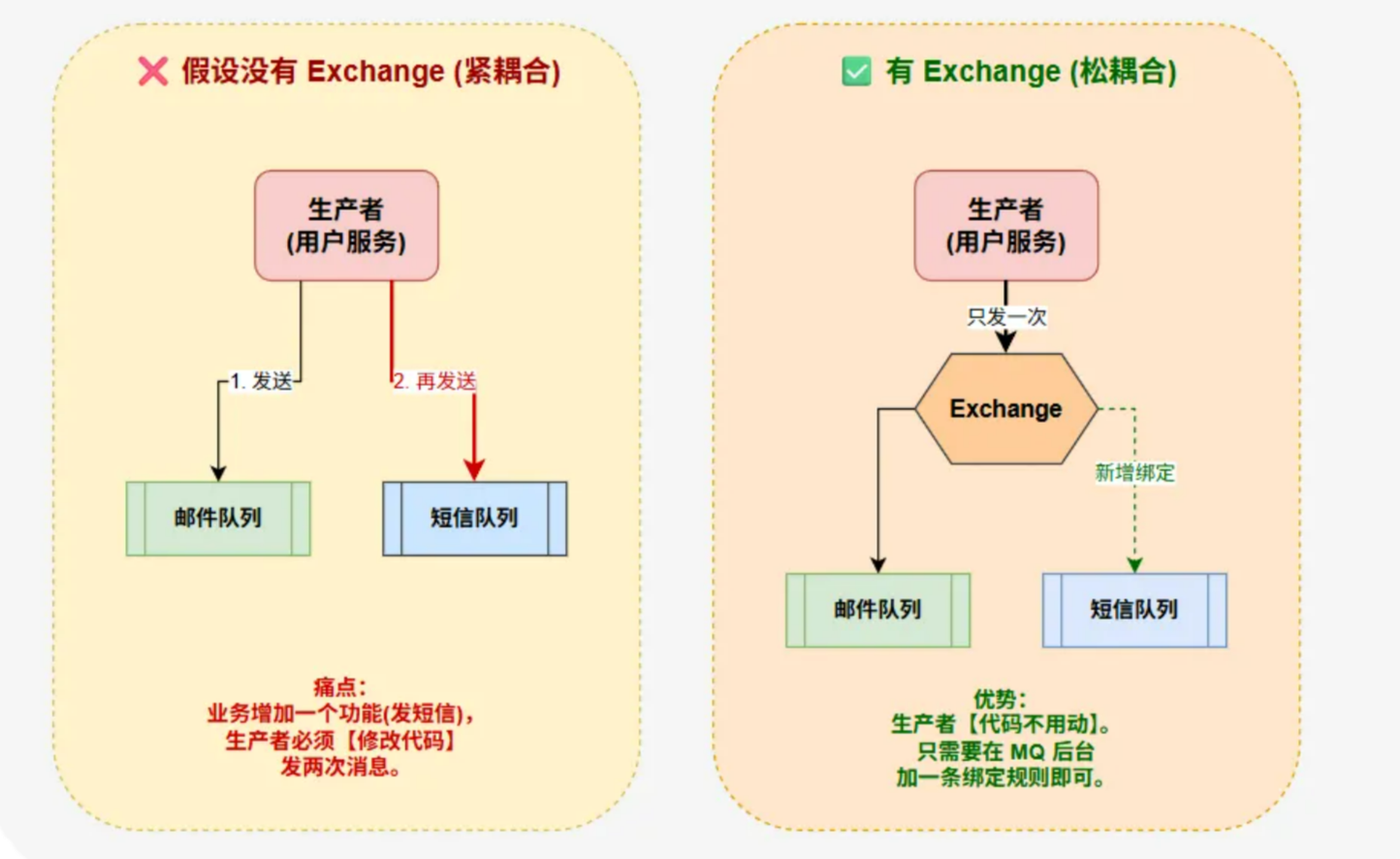
>为什么要有Exchange,消息直接发给MQ不行吗?
答:RabbitMQ的设计最核心的就是解耦。生产者不需要知道“消息发给谁”,只需要知道消息的类型。没有交换机的话,如果业务增加了,原本用户成功后只用发一个邮件通知,现在还需要发送短信通知,那就得改代码让生产者发送两份分别给Qa和Qb。有交换机的话,生产者代码一行不改,只需要在后台配置一下,把Exchange绑定到新的Queue B上就行了。---->灵活路由。
>为什么不直接用TCP连接,而要搞一个Channel?
答:多路复用。建立一个TCP长连接很耗资源(三次握手)。Channel是在TCP连接里虚拟出来的通道。在多线程环境下,我们不需要为每个线程都建立一个TCP连接,而是多个线程共享一个TCP连接,每个线程占用一个Channel。
三,应用场景
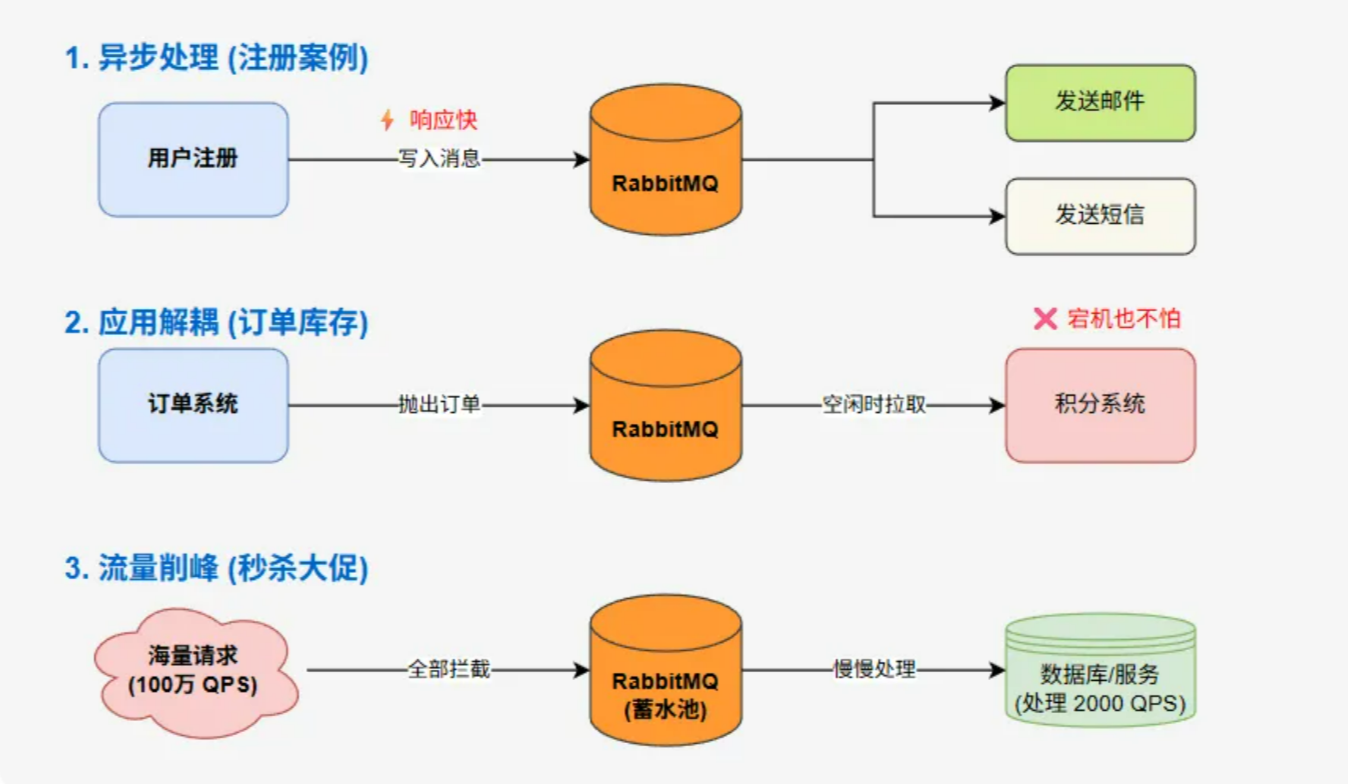
- 异步处理(提升响应速度):比如用户注册功能,以前注册完可能要同步发送邮件或短信,用户得等2秒才能看到“注册成功”。现在注册信息写入数据库后,直接把“发邮件、发短信”的任务交给MQ,能立刻给用户返回成功。
- 应用解耦(降低系统依赖):比如在用户下单场景要加积分。如果订单系统直接调用积分接口,积分系统挂了。订单也下不来了。如果在中间加一个MQ,订单系统只需把}我要下单“的消息发给MQ,积分系统什么时候恢复什么时候取消息加积分,这样非核心业务出问题也不会影响核心流程。
- 流量削峰(保护数据库):比如双十一秒杀。几百万请求瞬间涌进来,数据库直接就崩了。如果先把请求直接扔进MQ排队,后台系统按照自己的能力(比如每秒处理2000个消息)慢慢从MQ里拉去请求处理。
>引入MQ也会带来副作用
这点应该很容易想到,试想,本来是A和两个人通话,现在加了一个C在两个人之间传话,因此,难免会出现信息丢失或者信息错乱等情况。所以凡是中间件都应该会有这方面的影响。具体而言包括以下两点:
1,系统可用性降低:如果MQ挂掉了,整个链路全断。所以MQ必须做高可用集群。
2,数据一致性问题:A发送成功了,结果B处理失败了,或者消息在MQ里丢了,导致两边数据对不上。这就需要引入消息确认机制(ACK)、死信队列或者本地消息表来保证数据最终一致性。
四,与Kafka的区别,两者怎么选择?
RabbitMQ的强项在于路由(Routing)能力强和时效性高。它有非常灵活的交换机规则,可以把消息精确的分到不同的队列。而且它的延迟非常低(微秒级)。适合处理复杂的业务逻辑(比如企业级系统、订单流转)。
而Kafka的强项在于吞吐量极大。它主要用来处理大数据日志,用户行为埋点等,对实时性和复杂路由要求没那么高,但要求一天能吞几亿条数据。
一句话总结:业务系统解耦用RabbitMQ,大数据日志分析用Kafka。
五,在RabbitMQ中,如何确保消息不会丢失?
--->要保证消息不会丢失肯定要从消息产生到消费的整个链路的三个关键节点考虑,也就是发布、确认端和中间端。
1,发布确认:开启发布确认模式。这种模式下,生产者会等待服务器的确认响应,确保消息已经成功存储。
channel.confirm_delivery()
try:
channel.basic_publish(exchange='',
routing_key='task_queue',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent 'Hello World!'")
except pika.exceptions.UnroutableError:
print(" [x] Message could not be confirmed")
2,消息持久化:确保队列和消息都是持久的,即使RabbitMQ服务器重启也不会丢失消息。创建队列的时候设置durable为true,发布消息时设置delivery_mode为2。
channel.queue_declare(queue='task_queue', durable=True)channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
3,消费者确认:使用明确的消费者确认机制(ACK)。消费者在处理完消息后,会向RabbitMQ发送确认,RabbitMQ在收到确认后才会将消息从队列中删除。
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# Processing
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='task_queue',
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
如果消费者在处理完消息后没有确认(ack),消息会重新返回队列并分派给其他消费者。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)