【车辆】基于DDPG强化学习的小车倒立摆控制附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。
🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:做科研,博学之、审问之、慎思之、明辨之、笃行之,是为:博学慎思,明辨笃行。
🔥 内容介绍
一、引言
小车倒立摆系统是控制领域中的经典问题,它具有非线性、多变量和强耦合的特点,对其实现稳定控制极具挑战性。深度确定性策略梯度(DDPG)作为一种基于模型无关的强化学习算法,为小车倒立摆控制提供了创新的解决方案。通过与环境的不断交互学习,DDPG 能够有效应对系统的复杂动态,实现小车倒立摆的稳定平衡与精确控制。
二、小车倒立摆系统概述
- 系统结构
:小车倒立摆系统由一个可在水平轨道上移动的小车和一个通过铰链连接在小车上的倒立摆组成。小车可在外部作用力下沿轨道左右移动,而倒立摆则会因小车的移动以及自身重力和惯性的作用产生摆动。
- 动力学模型
:描述小车倒立摆系统通常使用牛顿 - 欧拉方程。假设小车质量为 m1,倒立摆质量为 m2,倒立摆长度为 l,作用在小车上的力为 u,倒立摆与垂直方向的夹角为 θ。系统的动力学方程可表示为一系列关于位置、速度、加速度以及角度、角速度、角加速度的微分方程。例如,水平方向上小车的加速度与作用力 u、倒立摆的摆动角度等因素相关;而倒立摆的角加速度则与小车的加速度、重力以及摆长等有关。这些方程准确刻画了系统各变量之间的动态关系,但由于其非线性特性,传统控制方法难以精确求解。
三、DDPG 强化学习算法

四、基于 DDPG 的小车倒立摆控制实现
- 状态定义
:为了让 DDPG 算法能够有效学习小车倒立摆系统的控制策略,需要合理定义系统的状态。状态通常包括小车的位置 x、速度 x˙,倒立摆的角度 θ、角速度 θ˙ 等信息。这些状态信息全面反映了系统在每个时刻的运行状况,作为 DDPG 算法中神经网络的输入,帮助智能体做出合适的动作决策。
- 动作定义
:在小车倒立摆系统中,动作定义为作用在小车上的力 u。由于力是连续变量,适合使用 DDPG 这种针对连续动作空间的强化学习算法。演员网络输出的动作值直接对应作用在小车上的力的大小和方向,通过调整力来控制小车的运动,进而维持倒立摆的平衡。
- 奖励函数设计
:奖励函数的设计直接影响 DDPG 算法的学习效果,目的是引导智能体采取能够使倒立摆保持平衡的动作。例如,当倒立摆的角度接近垂直方向且小车位置在允许范围内时,给予较高的正奖励;若倒立摆角度过大或小车超出规定位置,则给予负奖励。奖励函数 R 可以定义为:R=α1(1−∣θ∣)+α2(1−∣x∣)−β其中,α1 和 α2 是权重系数,用于调整角度和位置在奖励中的相对重要性,β 是一个常数,用于在系统状态不佳时给予惩罚。这样的奖励函数能够激励智能体尽量保持倒立摆的垂直平衡和小车位置的稳定。
- 训练与优化
:在训练过程中,智能体(DDPG 算法)根据当前系统状态,通过演员网络生成动作(即作用在小车上的力),作用于小车倒立摆系统。系统根据该动作转移到新的状态,并返回奖励值。智能体将这些经验数据 (s,a,r,s′) 存储到经验回放缓冲区中。然后,从缓冲区中随机采样一批数据,用于更新演员网络和评论家网络。评论家网络根据采样数据计算时间差分误差,并通过反向传播算法更新自身参数,以更好地估计动作价值。演员网络则根据评论家网络给出的 Q 值估计,通过策略梯度算法更新自身参数,以生成更优的动作策略。经过多次迭代训练,智能体逐渐学习到使倒立摆保持平衡的最优控制策略。
⛳️ 运行结果
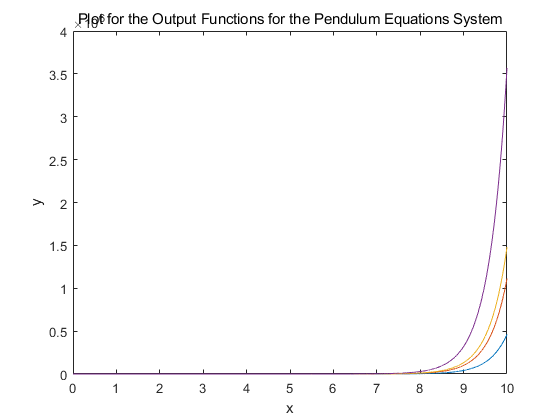
📣 部分代码
% Cart parametersm = 1; % pendulum massM = 5; %cart massL = 2; %pendulum lengthg = -9.81; % Gravityd = 1; % dampping term opposing the force input % slows the pendulum down, the higher this is the faster the pendulum slows down s = 1; % pendulum up (s=1)A = [0 1 0 0; %x 0 -d/M -m*g/M 0; %x_dot 0 0 0 1; % theta 0 -s*d/(M*L) -s*(m+M)*g/(M*L) 0]; % theta_dot %state space representation of the dependent forcesB = [0; 1/M; 0; s*1/(M*L)]; %state space representation of the linear forceseig(A) %% give the eigen values of A, where the poles are. C = eye(4); % sets an identity matrix. sys = ss(A,B,C,0*B); % converts a dynamic system, to space state representation%%tspan = 0:.001:10;if(s==-1) y0 = [0; 0; 0; 1.5]; %initial is used to plot the output of the system of equations. %yL is the output response, t is the time vector for the simulation, %and xL is the state trajectories. Uses sys to make this. [yL,t,xL] = initial(sys,y0,tspan); % solves the ode for the given syste, time and initial conditions. % returns the time frame, and the output vector. [t,yNL] = ode45(@(t,y)cartpend(y,m,M,L,g,d,0),tspan,y0);elseif(s==1) y0 = [0; 0; pi+.0001; 0]; [yL,t,xL] = initial(sys,y0-[0; 0; pi; 0],tspan); [t,yNL] = ode45(@(t,y)cartpend(y,m,M,L,g,d,0),tspan,y0);else endfigure (10); %plot(t,yL);plot(t,yL+ones(10001,1)*[0; 0; pi; 0]'); % as far as I can see they are the same.xlabel("x"); ylabel("y"); title("Plot for the Output Functions for the Pendulum Equations System");hold on; %%hold off; pause;
🔗 参考文献
🍅更多免费数学建模和仿真教程关注领取

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)