CUDA编程模型入门
目录
1.什么是CUDA编程模型
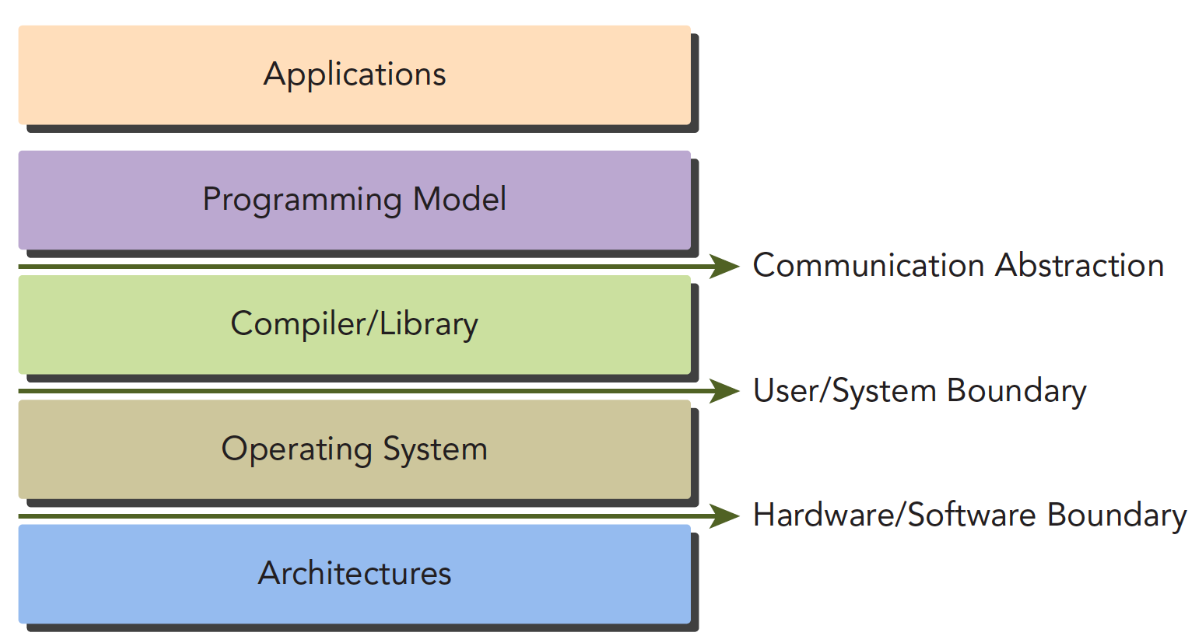
“应用 → 编程模型 → 编译/库 → 系统 → 硬件”
应用层:用户直接使用的程序(如科学计算、机器学习应用)。
编程模型:开发者控制的逻辑部分,定义语法、内存结构、线程结构等,决定GPU等异构设备的工作模式(如并行计算方式)。
编译器/库:将编程模型代码转化为可执行指令,提供API(如CUDA库函数)简化开发。
操作系统:管理硬件资源(包括GPU),协调软件与硬件的交互。
硬件架构:GPU等物理硬件本身。
CUDA编程模型是应用程序和硬件设备之间的“桥梁”
- CUDA C 是编译型语言(需通过编译器编译、链接后,由操作系统执行,操作系统包含GPU等硬件);
各层之间通过“抽象层”分隔,明确职责边界:
- Communication Abstraction:通信抽象
分隔“编程模型”和“编译器/库”,处理编程模型与底层库的交互逻辑。- User/System Boundary:用户/系统边界
分隔“应用”和“操作系统”,用户程序通过系统调用与硬件交互。- Hardware/Software Boundary:硬件/软件边界
分隔“操作系统”和“硬件”,操作系统(软件)控制硬件(GPU)的运行。我们写程序时自己控制的部分,包括语法、内存结构、线程结构等。它就像应用和硬件之间的一座桥。
CUDA 编程模型的关键组成有:
核函数:在 GPU 上并行执行的函数
内存管理:主机和设备内存的分配与拷贝
线程管理:如何组织成千上万的线程
流:控制并发和依赖关系
GPU 编程的两个“组织层次”:
线程的层次结构(网格→块→线程)
内存的层次结构(全局内存、共享内存等)
理解这两个层次,是后面写好 CUDA 程序的基础。
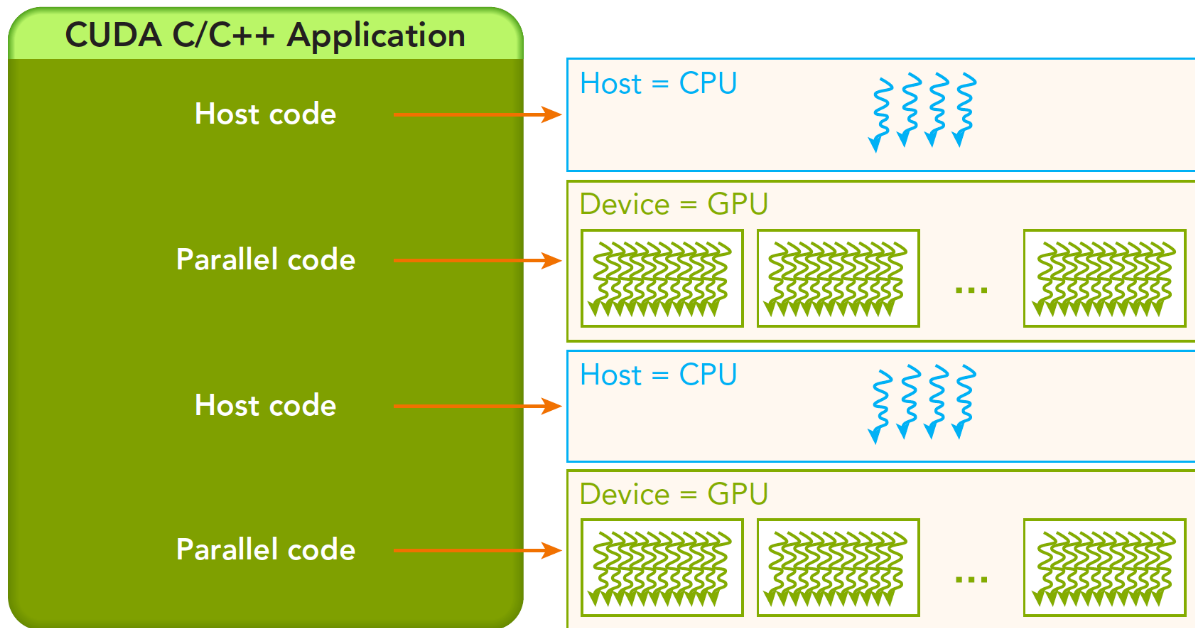
2.CUDA编程结构
一个异构环境,通常有多个CPU多个GPU,他们都通过PCIe总线相互通信,也是通过PCIe总线分隔开的。所以我们要区分一下两种设备的内存:
- 主机:CPU及其内存
- 设备:GPU及其内存
注意这两个内存从硬件到软件都是隔离的(CUDA6.0 以后支持统一寻址),我们目前先不研究统一寻址,我们现在还是用内存来回拷贝的方法来编写调试程序,以巩固大家对两个内存隔离这个事实的理解。
执行第一个核函数的时候,host是不会等待其返回的,一直往下执行,可能第二阶段的host code已经开始执行了,也就是异步的方式
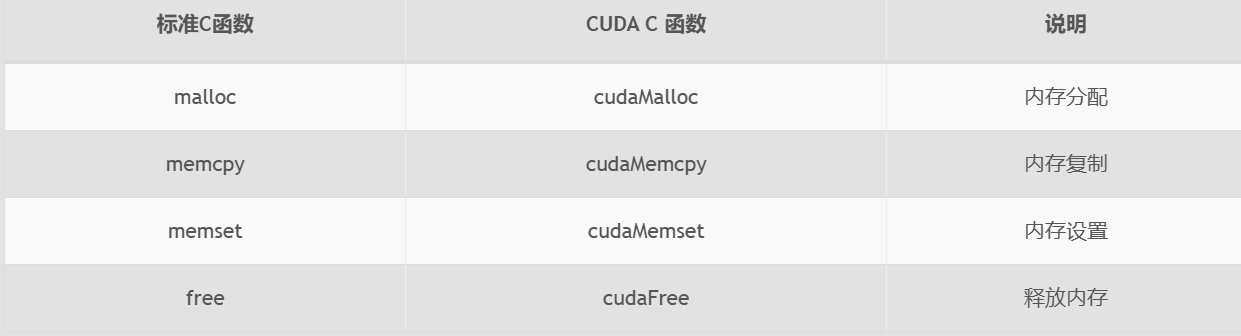
3.内存管理
内存管理在传统串行程序是非常常见的,寄存器空间,栈空间内的内存由机器自己管理,堆空间由用户控制分配和释放
CUDA程序同样,只是CUDA提供的API可以分配管理设备上的内存,当然也可以用CDUA管理主机上的内存,主机上的传统标准库也能完成主机内存管理。
cudaError_t cudaMemcpy (void * dst, const void * src, size_t count, cudaMemcpyKind kind);
cudaError_t(返回值):这是一个错误码,告诉你操作是否成功。
返回
cudaSuccess表示拷贝成功。返回其他值(如
cudaErrorMemoryAllocation)表示出错了。可以用
cudaGetErrorString()函数把错误码翻译成人类能读懂的字符串,方便调试。
void * dst(目的地指针):数据要搬到哪里去。如果是把数据从 CPU 搬给 GPU,这里就填 GPU 显存上的一个地址(如a_d)。
const void * src(数据来源指针):数据从哪里来。不能为空。
size_t count(搬运数量):要搬多少字节的数据。注意单位是字节,不是元素个数。比如你要搬 32 个float类型的数,这里就要填32 * sizeof(float)= 128
cudaMemcpyKind kind(搬运方向):告诉函数数据要往哪个方向走。这是一个枚举类型,有四种可能:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这里就把准备好的输入向量,通过 PCIe 总线,从内存推到了显存里,计算完之后在从显存搬回内存
有个更简单的判断错误的宏函数,CHECK
#define CHECK(call) \ do { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) CHECK(cudaMemcpy(...)) //可以直接判断是否正确
共享内存(shared Memory)和全局内存(global Memory)后面我们会特别详细深入的研究
4.向量加法
向量加法即对应位置对应相加即可
a = [1, 2, 3]
b = [4, 5, 6]
c = a + b = [1+4, 2+5, 3+6] = [5, 7, 9]通过命令nvidia-smi //查看自己的机器下有多少块显卡
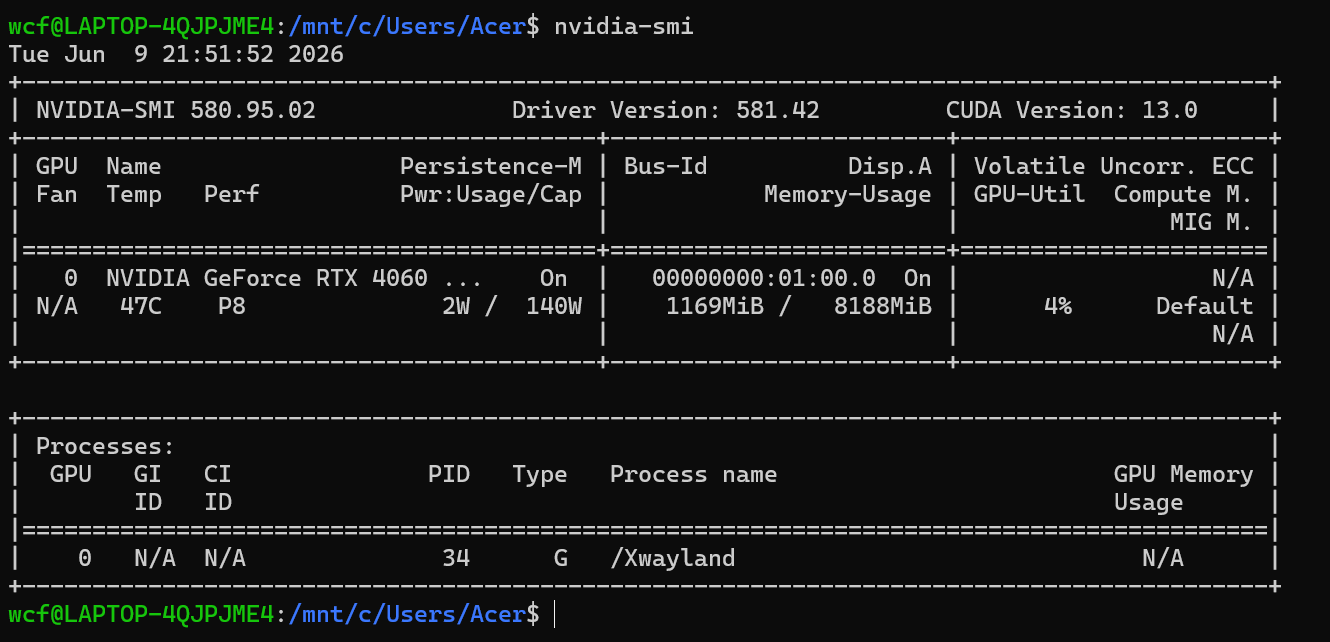
可以看到这台机器只有一张显卡,编号是0;
函数及其作用
CUDA 运行时 API :: CUDA Toolkit 文档
当你不明白一些函数是需要自己的查文档
函数修饰符 函数在哪里执行 可被哪里调用 返回值处理 __host__仅 CPU 仅 CPU 返回给 CPU 调用者,正常。 __global__仅 GPU 仅 CPU(或从另一 GPU 核函数调用) 必须为 void,不能有返回值。__device__仅 GPU 仅 GPU 核函数或其他设备函数 返回给 GPU 调用者。 每个函数开头都有修饰,说明这个函数是能在哪里调用的,返回值如何处理
枚举值 含义 cudaSuccess操作成功,无事发生 cudaErrorMemoryAllocation显存分配失败(GPU 内存不足) cudaErrorInvalidDevice选了一个不存在的 GPU 编号 cudaErrorInvalidValue传入了非法的参数值 cudaErrorLaunchFailure核函数执行异常崩溃 cudaErrorUnknown未知的内部错误 #define CHECK(call){ \ const cudaError_t error = call; \ if (error != cudaSuccess) { \ printf("Error: %s:%d, ", __FILE__, __LINE__); \ printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \ exit(1); \ } \ }返回值cudaError_t是一些枚举类型,这些类型得通过cudaGetErrorString(cudaError_t)来打印错误信息
为了方便,我们封装了一个宏函数CHECK,后面可以一直用来检查返回值
//当前线程后续所有操作都针对编号为 dev 的那块 GPU。 cudaSetDevice(dev);比如你想让两块 GPU 同时跑不同任务,就需要在两个主机线程里,分别调用
cudaSetDevice(0)和cudaSetDevice(1),把任务分配到不同显卡上。它在软件层面为当前 CPU 线程创建(或绑定)一个CUDA 上下文(Context)。这个上下文是程序在特定 GPU 上的“工作空间”,所有后续的内存分配、数据传输、核函数启动都会在这个空间里进行。不同 GPU 的上下文是隔离的,一张卡上分配的内存,另一张卡不能直接访问。
__host____device__cudaError_t cudaMalloc ( void** devPtr, size_t size ) 在设备上分配内存。返回值是专门用来传递错误的
那么我们只能通过传参的形式去接收一些地址,所以这里是void**的形式,要把某个变量的地址传进去,然后内部解引用把显存那边的地址传过来,存到devPtr这个变量当中
__host__cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind ) Copies data between host and device.
返回值
cudaError_t:指示操作是否成功。cudaGetErrorString检查
dst:目的地指针。
src:来源指针。
count:要拷贝的字节数(不是元素个数)。
kind:拷贝方向,决定数据流经的总线。dim3 block(nElem); dim3 grid(nElem / block.x); vectorSumDevice<<<grid, block>>>(a_d, b_d, res_d); printf("Execution configuration<<<%d,%d>>>\n", block.x, grid.x);dim3这个是 CUDA 内置的三维向量类型,专门用来描述线程块和网格的维度。
后续将详细讲解线程管理,先记住
#include <cstdio>
#include <iostream>
#include "../freshman.hpp"
//向量加法
void vectorSumHost(float* a_h,float*b_h,float*res_h,const int size){
for(int i=0;i<size;i+=4){
res_h[i]=a_h[i]+b_h[i];
res_h[i+1]=a_h[i+1]+b_h[i+1];
res_h[i+2]=a_h[i+2]+b_h[i+2];
res_h[i+3]=a_h[i+3]+b_h[i+3];
}
}
__global__ void vectorSumDevice(float* a,float*b,float*res){
int i = threadIdx.x;
res[i] = a[i] + b[i];
}
// 随机初始化
void initialData(float *ip, int size) {
srand((unsigned)time(NULL)); // 设置随机种子
for (int i = 0; i < size; i++) {
ip[i] = (float)(rand() & 0xFF) / 10.0f; //0.0 ~ 25.5 之间的随机数
}
}
bool check(float*res_h, float*res_dtoh, int nElem){
for(int i=0;i<nElem;i++){
if(res_h[i]!=res_dtoh[i])
return false;
else{
std::cout<<"host:"<<res_h[i]<<" "<<"device:"<<res_dtoh[i]<<std::endl;
}
}
return true;
}
int main(){
int dev=0; //这个是表示要使用第几张显卡,通过nvidia-smi可以看到有多少张显卡,并且显卡的配置是啥
cudaSetDevice(dev);
int nElem=32; //32大小的向量
int totalSize=sizeof(float)*nElem;
float* a_h,*b_h,*res_h;
float* res_dtoh;
//开辟内存空间
a_h=(float*)malloc(totalSize);
b_h=(float*)malloc(totalSize);
res_h=(float*)malloc(totalSize);
res_dtoh=(float*)malloc(totalSize);
//初始化
initialData(a_h,nElem);
initialData(b_h,nElem);
//开辟显存空间
float* a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,totalSize));
CHECK(cudaMalloc((float**)&b_d,totalSize));
CHECK(cudaMalloc((float**)&res_d,totalSize));
//把host初始化的数据传送给Device
CHECK(cudaMemcpy(a_d,a_h,totalSize,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,totalSize,cudaMemcpyHostToDevice));
//启动Gpu端计算
dim3 block(nElem);
dim3 grid(nElem / block.x);
vectorSumDevice<<<grid, block>>>(a_d, b_d, res_d);
printf("Execution configuration<<<%d,%d>>>\n", block.x, grid.x);
//拷贝回cpu端
CHECK(cudaMemcpy(res_dtoh,res_d,totalSize,cudaMemcpyDeviceToHost));
//启动cpu端计算
vectorSumHost(a_h,b_h,res_h,nElem);
//验证两个是否一样
std::cout<<check(res_h,res_dtoh,nElem)<<std::endl;
//释放
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_dtoh);
return 0;
}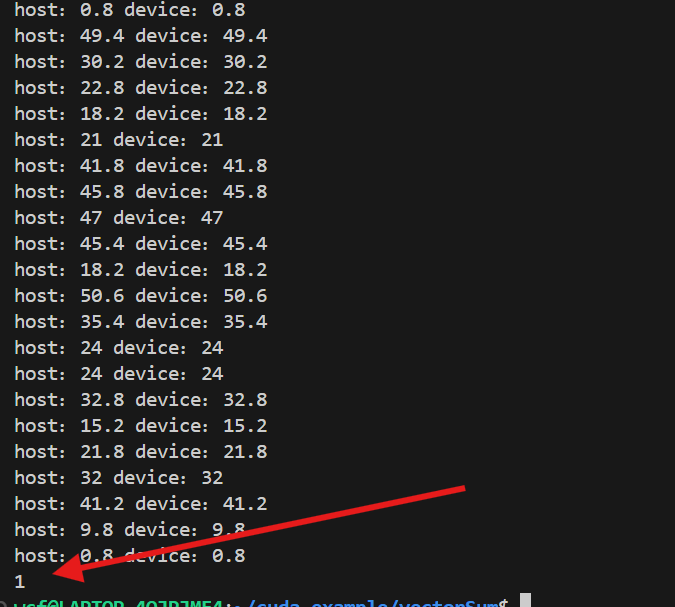
最后的打印结果也是正确的
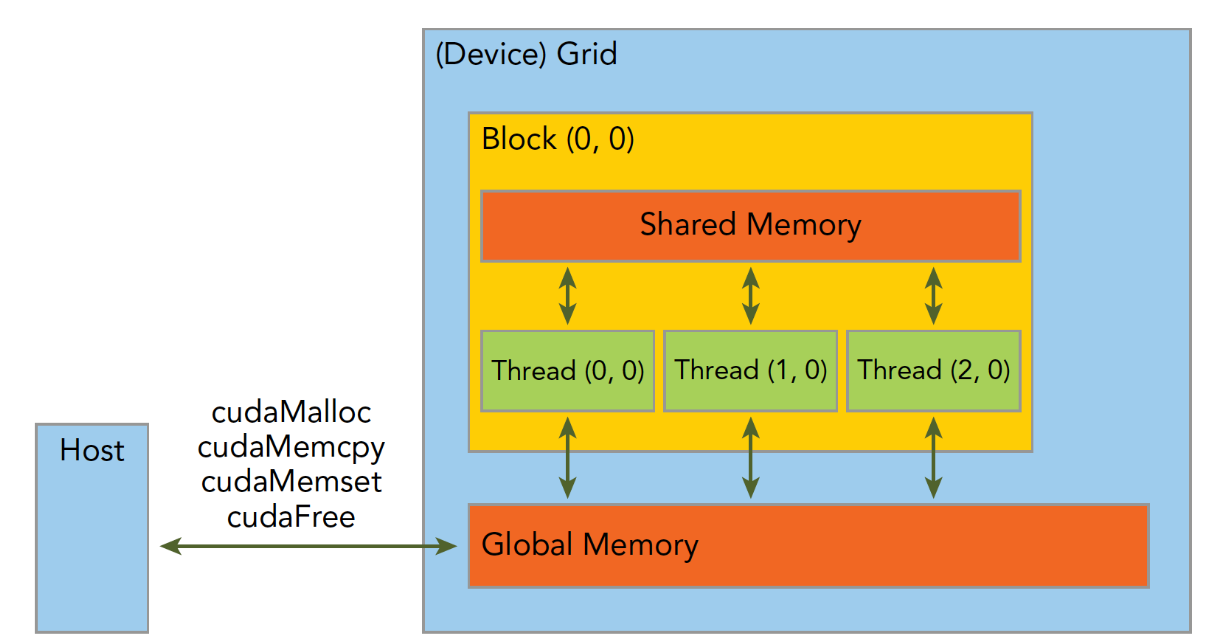
5.线程管理
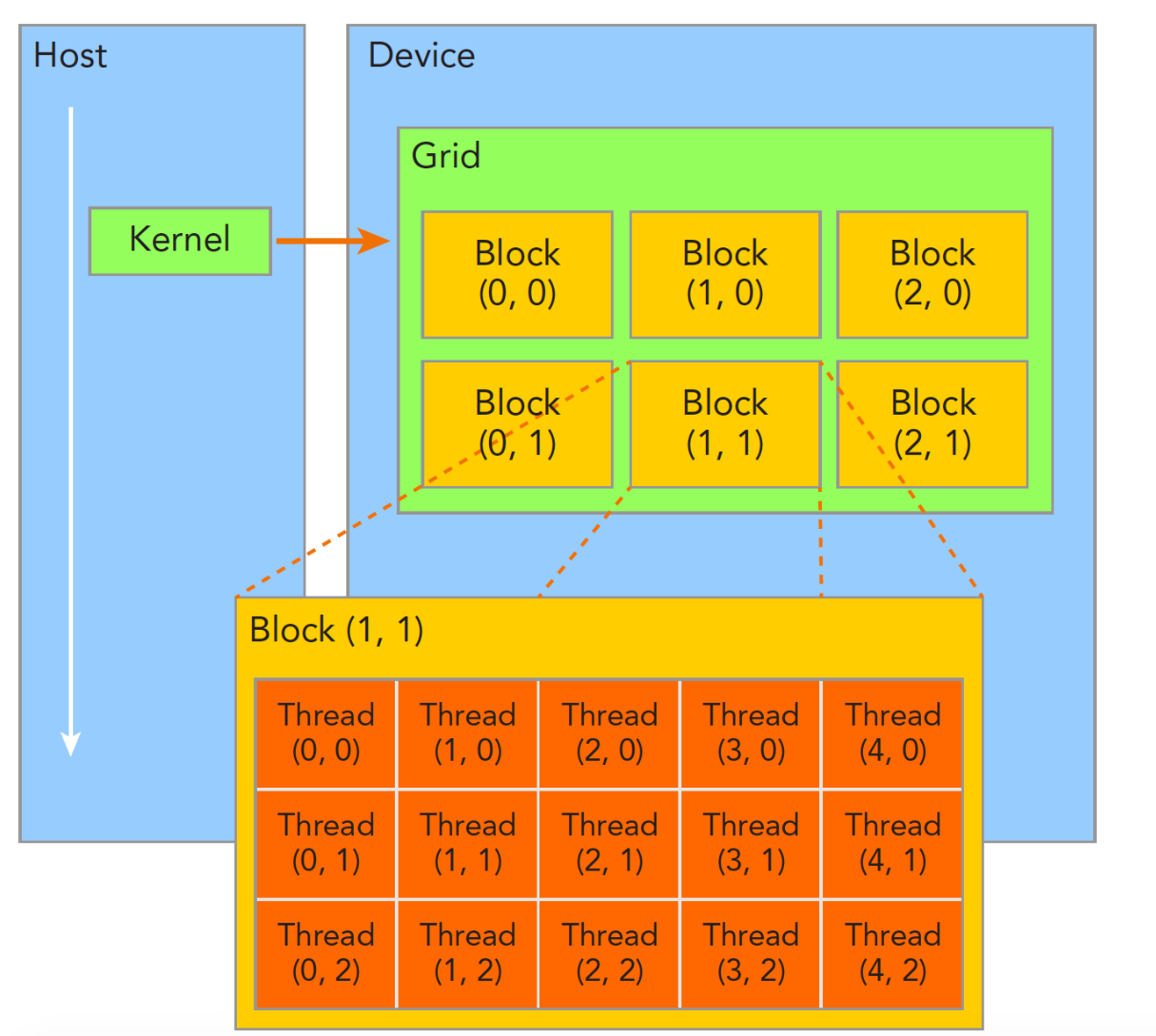
一个核函数只能绑定一个Grid,然后一个Grid里面有很多Block,一个Block里面有很多线程
这些都是可以由于去指定的
在 CUDA 中,一次核函数调用,只能拥有一个 Grid。 这个 Grid 里,你可以放进任意多个线程块,它们按照你指定的维度(一维、二维或三维)排列。
相当于你一个排有多少个班,一个班有多少个士兵都是可以自己安排的
dim3 block(nElem); dim3 grid(nElem / block.x); vectorSumDevice<<<grid, block>>>(a_d, b_d, res_d);这里的dim3是一个类,然后block是一个对象,这里是构造函数
在 CUDA 编程里,
dim3是一个专门用来表示三维尺寸的内置结构体,它有x、y、z三个成员(也就是通过三维来搭建这个块内的线程排列的,这里的处理是x为nElem,y和z默认1)dim3 grid(nElem.block.x)
配置一个网格放多少线程块,这里放了1个
最后传参vectorSumDevice<<<grid,block>>>();
意思就是配置这个网格里面有1个线程块,每个线程块有32个线程
一个线程块block中的线程可以完成下述协作:
- 同步
- 共享内存
不同块内线程不能相互影响!他们是物理隔离的!
针对块内的线程,我们执行了同一段代码,访问的数据不一样,我们需要区分不同的线程,简单来说就是要编号,才能对应到相应线程,使得这些线程也能区分自己的数据。如果线程本身没有任何标记,那么没办法确认其行为。
依靠下面两个内置结构体确定线程标号:
- blockIdx(线程块在线程网格内的位置索引)
- threadIdx(线程在线程块内的位置索引)
类型:
uint3结构体,有.x、.y、.z三个分量。- blockIdx.x
- blockIdx.y
- blockIdx.z
- threadIdx.x
- threadIdx.y
- threadIdx.z
Idx:index
int i = threadIdx.x; res[i] = a[i] + b[i];硬件收到
<<<1, 32>>>的配置后,会启动 32 个线程。每个线程在执行vectorSumDevice函数时,都拿到完全相同的三个指针a_d, b_d, res_d。但每个线程通过自己的threadIdx.x(0~31),去访问这些数组里的不同位置,从而并行完成 32 次独立的加法。
- blockDim
- gridDim
blockDimdim3线程块的尺寸,即每个块在 x, y, z 方向各有多少个线程 gridDimdim3网格的尺寸,即整个网格在 x, y, z 方向各有多少个线程块
dim3是你(程序员)在主机端用来“下命令”的配置类型。uint3是设备端硬件用来“执行命令”的只读数据类型。uint3这个是你触发核函数之后,硬件自动把参数填进去,后续device端那边用就是用这个,并且是只读数据是不能更改的,dim3是host端用来配置的
blockIdx.xthreadIdx.x
blockIdx.x * blockDim.x + threadIdx.x最终拿到的数据编号 i0 0 0 * 32 + 0 = 0 处理第 0 号数据 0 1 0 * 32 + 1 = 1 处理第 1 号数据 ... ... ... ... 0 31 0 * 32 + 31 = 31 处理第 31 号数据 1 0 1 * 32 + 0 = 32 处理第 32 号数据 1 1 1 * 32 + 1 = 33 处理第 33 号数据 ... ... ... ... 1 31 1 * 32 + 31 = 63 处理第 63 号数据 如何定位一个准确的编号,我们得根据block的编号+thread的编号进行定位具体的线程编号,并且我们还要知道一个块里面有多少个线程,那就是通过blockDim进行读取的
网格和块的维度存在几个限制因素,块大小主要与可利用的计算资源有关,如寄存器共享内存。
分成网格和块的方式可以使得我们的CUDA程序可以在任意的设备上执行。
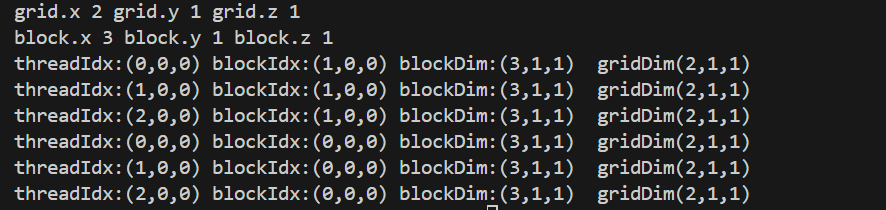
#include <cuda_runtime.h> #include <stdio.h> __global__ void checkIndex(void) { printf("threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim:(%d,%d,%d)\ gridDim(%d,%d,%d)\n",threadIdx.x,threadIdx.y,threadIdx.z, blockIdx.x,blockIdx.y,blockIdx.z,blockDim.x,blockDim.y,blockDim.z, gridDim.x,gridDim.y,gridDim.z); } int main(int argc,char **argv) { int nElem=6; dim3 block(3); dim3 grid((nElem+block.x-1)/block.x); printf("grid.x %d grid.y %d grid.z %d\n",grid.x,grid.y,grid.z); printf("block.x %d block.y %d block.z %d\n",block.x,block.y,block.z); checkIndex<<<grid,block>>>(); cudaDeviceReset(); return 0; }可自己思考一下结果,然后运行试一下
应该没啥疑惑,之前已经解释很清楚了
注意的是blcokDim和gridDim表示的是在这个方向上,有多少个元素,也就是size,而不是index,这里的线程块是一个3D的,也就是它是一个有长宽高的实体,这样也特别好理解,因为你的长是3,那下标就是从012,宽是1,那你的下标就是0,高也是1,下标也是0
那线程下标就是(0,0,0)(1,0,0)(2,0,0)
6.一个核函数应该如何被正确的书写
核函数(Kernel)是 CUDA 编程中最核心的概念,它本质上是在 GPU 上由成千上万个线程并行执行的一段代码。核函数内部:你写串行,硬件跑并行
所以我们写CUDA程序就是写核函数,第一步我们要确保核函数能正确的运行产生正确的结果,第二优化CUDA程序的部分,无论是优化算法,还是调整内存结构,线程结构都是要调整核函数内的代码,来完成这些优化的。
- 核函数
- 启动核函数
- 编写核函数
- 验证核函数
- 错误处理
启动核函数
kernel_name<<<grid, block, shared_memory_size, stream>>>(args...);三对尖括号里的参数是专属于 CUDA 的语法扩展,它不是传给核函数的,而是给 GPU 硬件调度器看的。
grid(必需)—— 网格维度
作用:告诉 GPU,这次任务总共要启动多少个线程块(Block)。
类型:可以是
dim3类型,也可以是一个普通的int。如果只给一个整数,就自动当作dim3的x分量,y和z默认为 1。例子:
dim3 grid(2, 1, 1)或直接写2。
block(必需)—— 线程块维度
作用:告诉 GPU,每个线程块里有多少个线程(Thread)。
类型:同样可以是
dim3或int。每个块的总线程数有限制(通常是 1024)。例子:
dim3 block(32, 1, 1)或直接写32。
shared_memory_size(可选)—— 动态共享内存大小
作用:如果核函数里需要动态分配共享内存,就在此指定要额外分配的字节数。
类型:
size_t,一个无符号整数。默认值:如果省略,就是
0,表示不使用动态共享内存。例子:
1024。
stream(可选)—— 异步流
作用:指定核函数在哪个 CUDA 流中执行,用于实现 CPU 与 GPU、GPU 与 GPU 之间的任务并行。
类型:
cudaStream_t。默认值:如果省略,就是默认流(
0),此时核函数启动是异步的,但和其他默认流操作存在隐式同步。例子:
stream1。kernel_name<<<4,8>>>(argument list);
通过这个例子,核函数是同时复制到多个线程执行的
int i = threadIdx.x; res[i] = a[i] + b[i];所以之前我们编写的那个例子本质就是通过偏移量去访问同一块空间的不同区域
i就是找到偏移量,比如第一个线程的偏移量就是0,那就会去我们传入参数的a里面的第一块
第二个线程的偏移量就是1,那就是去第二块,这样不同的线程就可以访问同一块空间的不同区域
之前提到过,主机端启动了核函数之后,控制权马上回到主机端接着往下执行代码,也就是异构架构,那如果想要主机端停下来等设备端,可以使用以下函数
cudaError_t cudaDeviceSynchronize(void);cudaError_t cudaMemcpy(void* dst,const void * src,size_t count,cudaMemcpyKind kind);这个是必须等待设备端计算完之后才能传数据,所以这里会阻塞等待
调用
cudaMemcpy后,整个流程是这样的:
CPU 端:驱动程序向命令队列依次放入核函数命令、栅栏命令、拷贝命令,然后 CPU 进入阻塞状态(等待一个信号)。
GPU 硬件调度器:从队列中取出核函数命令,把所有线程块分派给 SM,并跟踪完成状态。
硬件栅栏:GPU 执行到栅栏命令时暂停,等待调度器确认所有线程块执行完毕。
栅栏放行:最后一个线程块完成,栅栏放行,GPU 开始执行拷贝命令,DMA 引擎自动把数据从显存搬到内存。
中断通知:DMA 完成后,GPU 发硬件中断给 CPU,唤醒
cudaMemcpy,函数返回。编写核函数
__global__ void kernel_name(argument list);
限定符 执行位置 可被谁调用 返回类型 启动方式 备注 __global__仅 GPU CPU 或 GPU(CC 3.5+) 必须 void<<< >>>语法核函数,CUDA 的核心 __device__仅 GPU 仅 GPU 函数 任意类型 直接调用 设备端工具函数 __host__仅 CPU 仅 CPU 任意类型 直接调用 可省略,默认为 __host____host__ __device__CPU + GPU 各自一份 CPU 和 GPU 都可调 任意类型 直接调用 双栖函数,两份编译 Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
错误处理
#define CHECK(call){ \ const cudaError_t error = call; \ if (error != cudaSuccess) { \ printf("Error: %s:%d, ", __FILE__, __LINE__); \ printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \ exit(1); \ } \ }简单来说就是防御性编程,因为整个架构是异步架构,并发执行,等我们回头看代码的时候压根不知道哪里出错了,所以最好是每一步做一个简单的检查即可
7.编译CUDA程序
nvcc --help //可以看到所有的参数列表+作用
-o <file>指定输出的可执行文件名 nvcc -o myapp hello.cu-c只编译成 .o目标文件,不链接nvcc -c kernel.cu这是性能优化的关键,为你自己的显卡生成最优代码。
参数 含义 示例 -arch=<arch>指定虚拟架构,决定了能使用哪些 PTX 特性 -arch=compute_52(Pascal)-code=<code>指定真实架构,生成具体的 GPU 机器码 (SASS) -code=sm_52-gencode联合指定,可多次使用,为一个文件生成多种架构代码 -gencode=arch=compute_50,code=sm_50控制代码是追求速度,还是方便调试。
参数 含义 说明 -O0,-O1,-O2,-O3主机端代码优化级别 类似于 gcc的-O选项-g生成主机端调试信息 用于 CPU 端代码的调试 -G生成设备端调试信息 关键! 用 cuda-gdb调试核函数必须加此参数-lineinfo生成行号信息 用于 profiler 定位到具体代码行 用于查看幕后细节或加速编译。
参数 含义 --dryrun或-dryrun不执行编译,只打印出 nvcc会执行的所有命令,非常适合理解它的工作流程-v或--verbose输出详细的编译执行信息 -t或--threads <N>使用 N 个线程并行编译,加速大项目

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)