2026 上下文护城河:八大资产体系与企业 AI 壁垒构建指南
今天,任何企业都能调用同一批顶级模型。
能力本身已经不稀缺了。那竞争的焦点去哪了?
去了模型之外的地方:上下文。
模型是引擎,上下文是燃料。引擎人人可以租,燃料只能自己炼。这是特赞在与数百家全球品牌深度合作的过程中,被反复被验证的一个判断。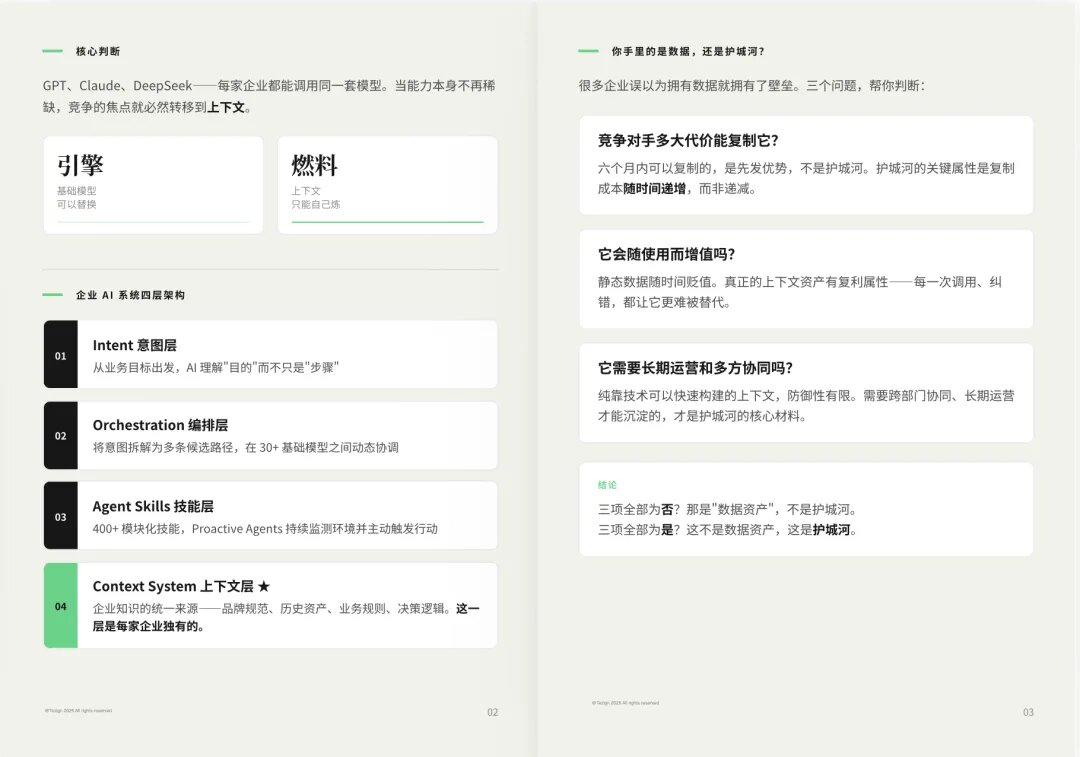
但是,不是所有的数据资产,都是壁垒
很多企业以为有数据就有了护城河。但实际并非如此。数据要成为真正的壁垒,需要通过三个追问:
① 复制成本会随时间增加吗? 六个月内能被对手追平的,叫先发优势,不叫护城河。护城河的关键不是"现在难复制",而是"越晚复制越贵"。
② 它会随使用而增值吗? 静态数据只会贬值。真正的上下文资产有复利属性——每一次调用、每一次纠错,都让它更精准,更难被替代。
③ 它需要多方协同、长期经营吗? 靠技术一个月能搭出来的上下文,防御性有限。必须跨部门、跨周期才能沉淀出来的,才是真正难以复制的材料。
如果三问全部为否,那只是数据资产,还不是护城河。
不是所有的上下文,都一样重要
并非所有上下文都一样珍贵。与数百家企业合作的过程中,我们总结出企业中最核心的上下文类别。从最容易获取到最难复制,大致可以分成四个层级:
第一层:品牌 & 商品信息 视觉语言、文字风格、产品规格。这些是显性知识,竞争对手看一眼就能仿制。防御性最弱,但它是所有内容生成的"调性锚点"——没有它,模型输出就会失去品牌辨识度。
第二层:素材 & 项目过程 企业历史生产的内容库,以及每一次campaign从立项到收尾的完整记录。这里开始有时间成本。十年积累的素材深度,不是新进入者一年能追平的。更关键的是,项目记录留下的是"怎么做决策的",而不只是"最终做了什么"。
第三层:话术 & 用户认知 哪种表达,在哪个渠道,对哪类人群更有效——这需要大量真实交互才能积累。用户画像不是静态标签,是从行为里持续学习的动态认知。你的用户越多、观察越久,这一层就越厚。
第四层:网络 & 历史决策 这是单一企业看不到、平台型企业才能经营的维度。当特赞汇聚180+品牌的数据,就能回答"同品类在抖音的平均内容效果是多少"——谁设定了行业基准,谁就占据了生态位。而历史决策的完整脉络——成功的原因、失败的教训——是隐性知识的最终形态,也是最难从外部获取的东西。

多层级的上下文才能带来商业的复利
单一层级的防御是有限的。真正难以追赶的,是在多个层级上同时积累的企业。
以特赞服务的一家快消品牌为例:三年下来,它在平台上沉淀的不只是素材库,而是素材与素材之间的语义关联、上百次campaign的决策过程、从数万次投放中提炼出来的渠道偏好。
这些东西加在一起:复制成本按年计算,且每过一天,差距就更大一点。而每一次使用,又让这个上下文更精准——用得越多,越准;越准,越离不开。
这个正反馈循环,就是护城河与数据资产的本质区别。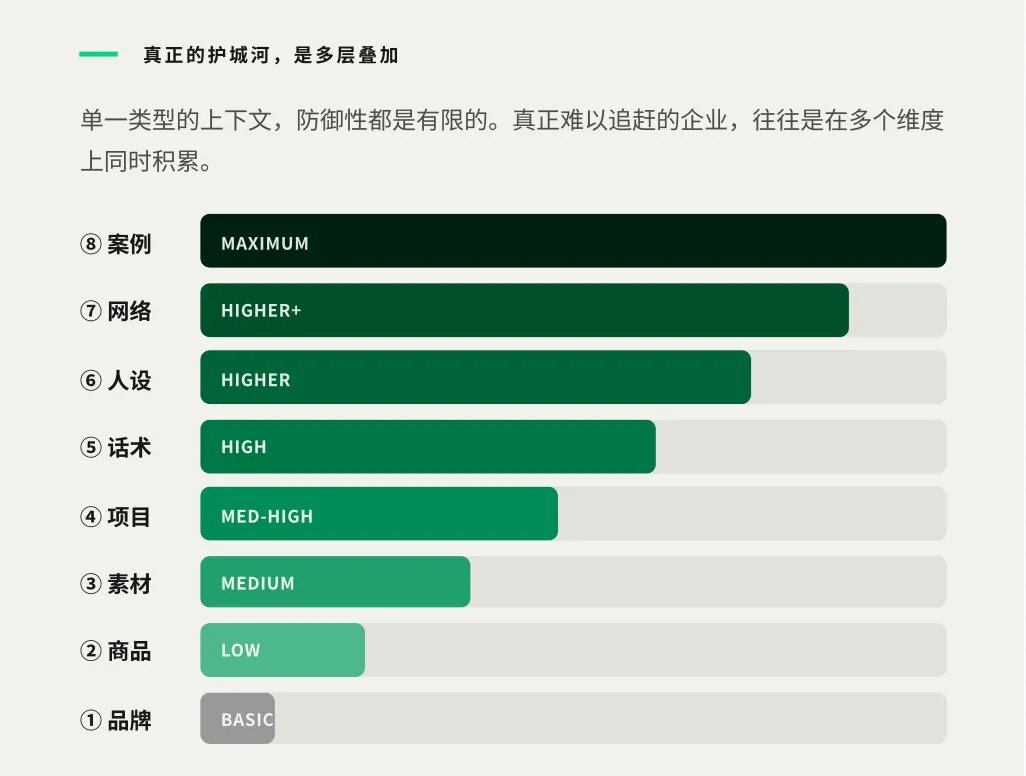
上下文护城河,长在真实业务现场
它不需要单独立项。它本来就应该发生在每一次正常的业务运转里——前提是,你的工作流被设计成能把过程留下来,而不是只留结果。
这一个前提,改变了企业理解AI的整个思路:从"我要部署什么技术",变成"我要把什么经验系统化留存"。
模型会更新,架构会迭代。唯有上下文,是在真实业务里一点一点磨出来的。它是AI时代竞争力的最后一公里——也是最难被复制的那一公里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)