数算岛开源AI训练推理平台 V2.0 —— 多租户GPU池化、分布式训练、全生命周期管理、多框架兼容、边缘端适配、云边协同、企业级私有化部署
·
数算岛开源AI训练推理平台 V2.0 —— 多租户GPU池化、分布式训练、全生命周期管理、多框架兼容、边缘端适配、云边协同、企业级私有化部署
如果对您有帮助,您可以点右上角 “Star” ❤ 支持一下谢谢!
📖 项目介绍
数算岛开源AI训练推理平台是一款面向企业级的开源AI全生命周期管理解决方案,基于GPU池化技术打造,代码全开源无加密,可免费商用,适合企业AI中台、科研院所、算法研发团队快速搭建统一的AI研发与算力管理体系。平台针对行业普遍存在的GPU资源利用率低、环境配置繁琐、多租户管控难、开发协作低效、资产复用困难等痛点,覆盖数据管理、算法开发、模型训练、模型管理、部署推理全研发链路,支持TensorFlow、PyTorch等主流AI框架,兼容多品牌异构算力硬件,可私有化部署,全方位提升AI研发效率与算力资源价值。
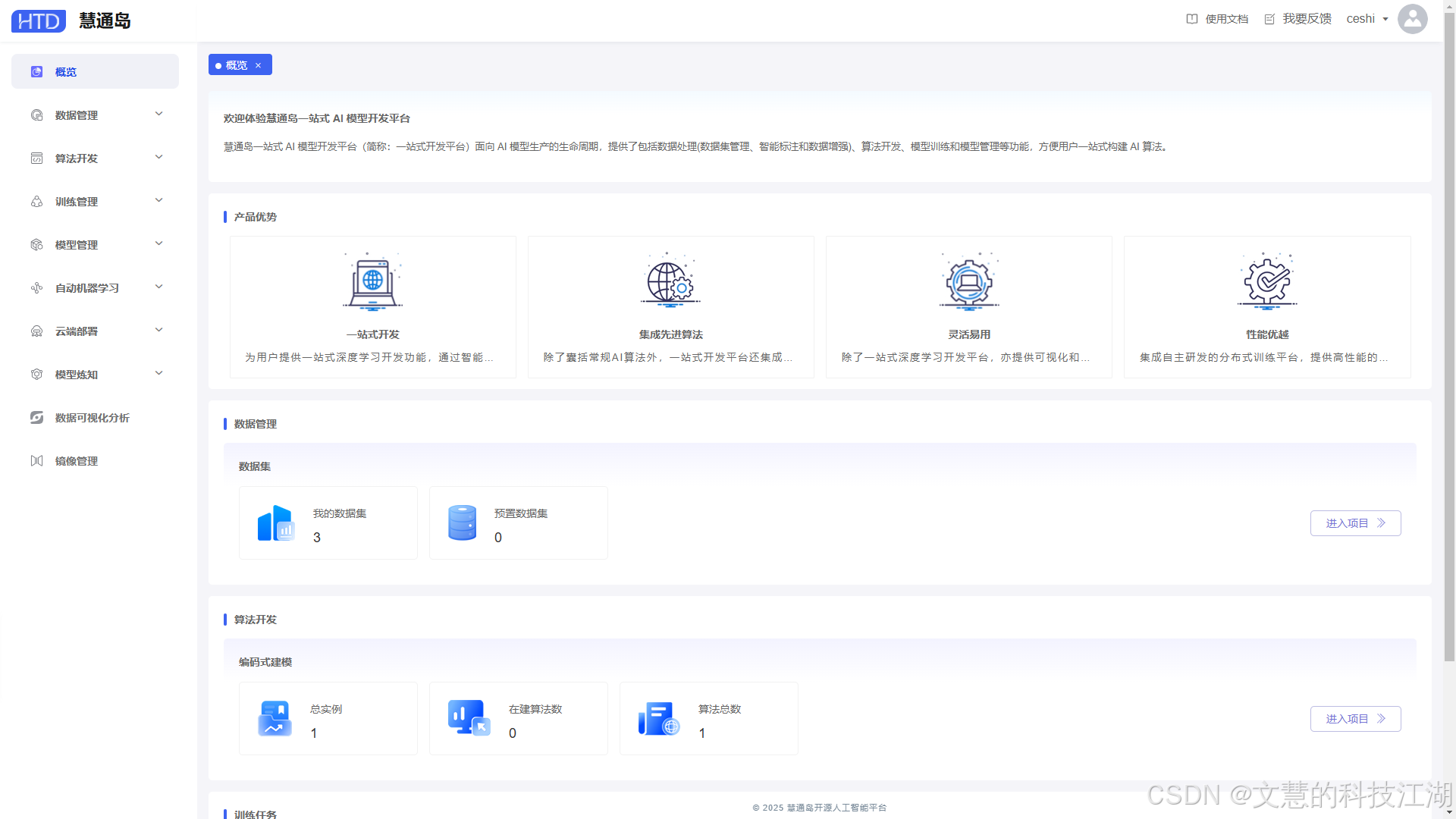
技术架构
平台采用云原生微服务架构,前后端分离设计,基于容器化技术构建统一算力调度底座,自下而上分为硬件兼容层、资源调度层、框架适配层、业务能力层与终端接入层。底层兼容NVIDIA、AMD、华为昇腾等多品牌异构算力,中层通过智能调度引擎实现GPU池化与资源弹性分配,上层覆盖AI研发全流程业务模块,同时支持云边协同架构,实现云端训练、边缘部署的一体化能力。平台接口规范清晰,代码结构分层明确,二次开发便捷,可快速对接第三方业务系统。
核心功能
平台围绕AI研发全流程与算力管理设计核心能力,覆盖资源层、开发层、训练层、部署层全链路:
- 全链路AI研发生命周期管理
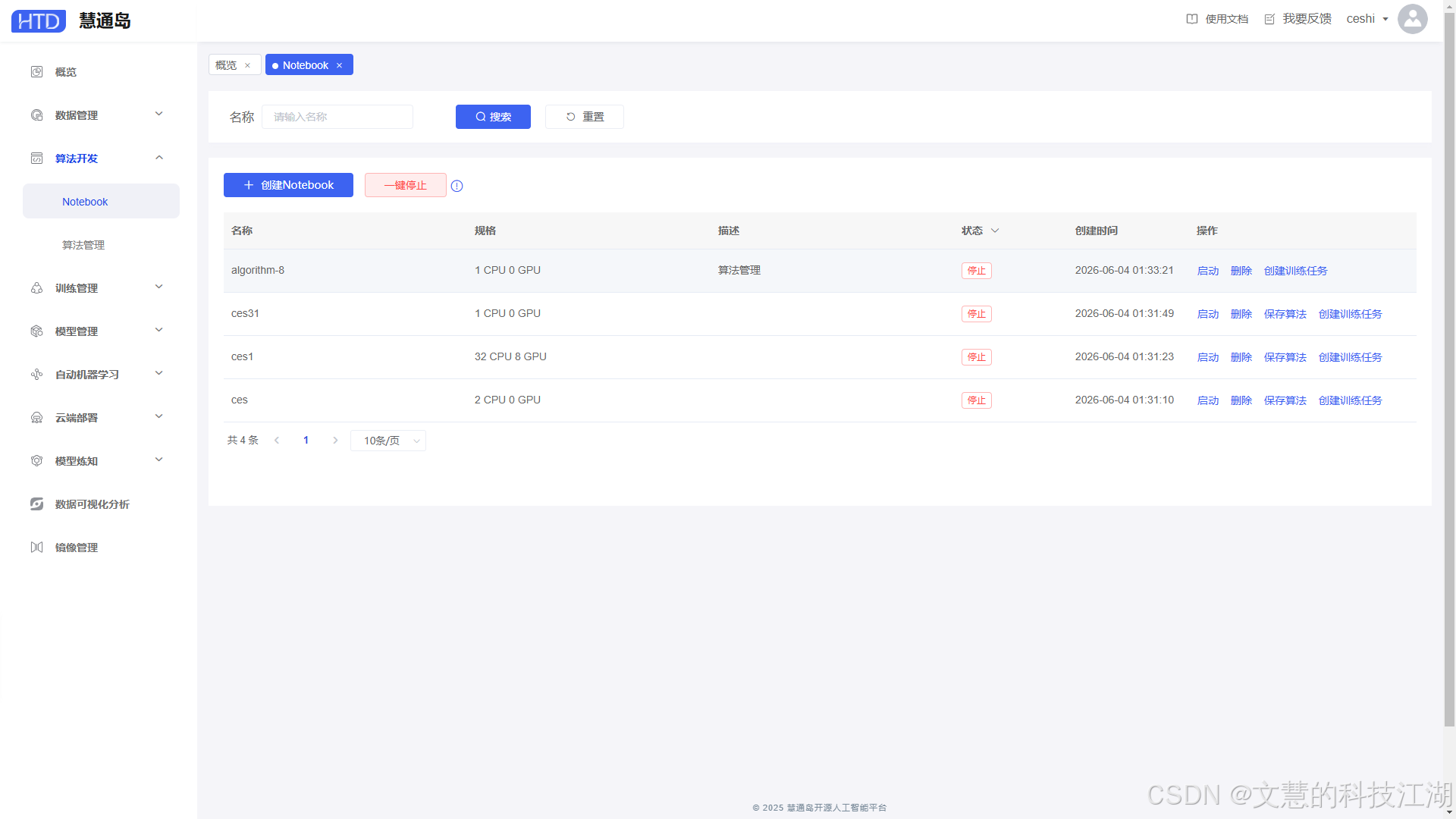
覆盖数据标注处理、算法开发、模型训练优化、推理部署全流程,支持TensorFlow、PyTorch、MXNet等主流深度学习框架的异构计算调度,内置自动机器学习、模型炼知、数据可视化等工具组件,一站式满足AI研发全环节需求。 - 智能GPU池化调度引擎
采用动态GPU池化技术,支持多型号GPU混合调度与统一管理;内置智能排队系统,支持抢占式任务调度与资源自动回收;基于cgroups实现硬件资源隔离与QoS保障,有效提升算力资源整体利用率。 - 高性能分布式训练与推理
优化AllReduce算法,分布式训练线性加速比达0.95+,支持断点续训、模型自动保存与TensorBoard可视化集成;提供模型量化压缩、格式转换、在线推理、端侧推理优化能力,配套服务网格化部署与模型热更新功能。 - 全资产版本化管控体系
实现数据集、算法代码、模型文件、运行镜像全资产的版本化管理,完整记录实验过程中的超参数、指标、日志等信息,保障实验可追溯、成果可复用,支持团队内资产共享与协作。 - 多形态在线开发环境
支持JupyterLab、VSCode Remote、SSH、Web终端等多种接入方式,预置20+深度学习基础镜像,秒级启动运行环境;配套资源配额管理,可灵活管控CPU、GPU、内存、磁盘等资源使用上限。 - 云边协同与边缘部署能力
支持模型自动转换为TensorRT等边缘适配格式,配套云边协同传输协议,实现云端训练模型一键下发边缘端,支持在线模型热更新,满足边缘计算场景的部署需求。
系统优势
- 算力利用率显著提升
通过GPU池化、智能调度与资源自动回收机制,可将算力资源闲置率从40%+大幅降低,实际落地案例中千卡集群利用率提升至82%,模型训练周期缩短40%,充分释放硬件资产价值。 - 企业级多租户隔离
具备细粒度权限控制与资源隔离机制,支持多层级组织架构管理,配套用量监控与成本分析体系,符合企业级安全合规要求,支持数据加密传输与存储,满足GDPR、HIPAA等合规标准。 - 全栈软硬件兼容
向下兼容NVIDIA、AMD、华为昇腾、寒武纪等多品牌异构算力硬件,向上适配主流AI框架与开源生态,同时支持阿里云、腾讯云、AWS等公有云与私有云、物理服务器多种部署环境。 - 研发效率大幅提升
预置开箱即用的开发环境与工具链,免去环境配置、依赖适配等重复工作,可节省30%以上的开发准备时间;配套实验全记录与资产复用机制,加速模型迭代与团队协作效率。 - 高可用稳定架构
支持硬件故障自动迁移与任务容错机制,配套50+项实时监控指标,全方位监控算力运行状态;架构弹性可扩展,可随业务规模平滑扩容算力资源与服务节点。 - 开源可控灵活定制
全量代码开源无加密,支持免费商用与私有化部署,代码结构清晰、文档完善,二次开发便捷,可根据业务需求定制功能模块,满足个性化场景需求。
💻 技术特点
运行环境及框架
- 前端访问:Web全栈界面,兼容主流浏览器,支持多种开发环境在线接入
- 后台服务:基于Spring Cloud微服务架构构建,云原生容器化部署
- 算力适配层:兼容NVIDIA/AMD/华为昇腾等多品牌GPU,支持vGPU与分布式算力调度
- AI框架层:支持TensorFlow、PyTorch、MXNet等主流深度学习框架
- 部署环境:支持Linux服务器部署,适配公有云、私有云、自有IDC等多种基础设施
- 运行条件:Docker环境、Kubernetes集群、MySQL 5.7+、Redis 5+、对应GPU驱动环境
核心技术栈清单
1. 容器编排:Docker + Kubernetes
2. 微服务框架:Spring Boot + Spring Cloud
3. 前端框架:Vue + ElementUI
4. 数据存储:MySQL + Redis + 兼容S3/HDFS分布式存储
5. 算力调度:GPU池化引擎 + 分布式训练调度器
6. AI框架兼容:TensorFlow / PyTorch / MXNet
7. 开发环境:JupyterLab + VSCode Remote + Web Terminal
8. 监控体系:Prometheus + Grafana 多维度资源监控
9. 模型管理:支持ONNX/PMML通用模型格式
10. 边缘协同:云边传输协议 + 边缘推理引擎
项目代码包介绍
1. ssd-platform 后端主工程 微服务底座与核心业务逻辑
2. ssd-scheduler 资源调度服务 GPU池化与任务调度核心引擎
3. ssd-datamgr 数据管理服务 数据集处理、标注与版本管控
4. ssd-train 训练服务 分布式训练与实验管理
5. ssd-model 模型管理服务 模型仓库、推理部署管理
6. ssd-image 镜像管理服务 镜像仓库与环境定制
7. ssd-ui WEB程序 PC端管理与研发前端工程
8. ssd-edge 边缘端组件 边缘推理与云边协同模块
9. ssd-doc 文档 部署文档、使用文档、二开文档
10. ssd-deploy 部署脚本 容器化部署与环境配置脚本
系统演示
- 运营管理后台:演示 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.platform.huizhidata.com
账号:admin
密码:admin123456 - 研发平台端:演示 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.platform.huizhidata.com
- API接口文档:演示 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.platform.huizhidata.com
- Github 主仓库(优先更新)
📚 项目资料
资料支持
- 使用文档:文档 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.doc.huizhidata.com
- 接口文档:文档 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.doc.huizhidata.com
- 二开文档:文档 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.doc.huizhidata.com
- 技术社区:文档 - 慧通岛开源人工智能平台简介 | 慧通岛开源人工智能平台 http://huitongdao.doc.huizhidata.com
部署说明
平台支持容器化一键部署,适配公有云、私有云、物理服务器等多种基础设施环境,可根据业务规模选择单节点测试部署与集群化生产部署两种方案。
🎨 核心功能全景图
| 🔴 研发全流程 | 🟠 资源调度 | 🟡 资产管理 | 🟢 部署推理 |
|---|---|---|---|
| 数据标注处理 | GPU动态池化 | 数据集版本管控 | 在线推理服务 |
| 在线算法开发 | 多租户资源隔离 | 模型全生命周期管理 | 模型量化压缩 |
| 分布式模型训练 | 智能任务排队 | 镜像仓库管理 | 边缘端部署 |
| 自动机器学习 | 抢占式调度 | 实验全流程记录 | 模型热更新 |
| 模型炼知工具 | 资源自动回收 | 资产共享复用 | 端侧推理优化 |
| 数据可视化分析 | 故障自动迁移 | 代码版本管理 | 服务网格化部署 |
| 🔵 硬件兼容 | 🟣 企业能力 | 🟤 生态集成 | ⚫ 场景价值 |
|---|---|---|---|
| NVIDIA全系列GPU | 多租户权限管控 | 主流AI框架兼容 | 企业AI中台搭建 |
| AMD算力硬件 | 用量成本统计 | HuggingFace生态 | 科研模型训练 |
| 华为昇腾算力 | 安全加密传输 | 分布式存储对接 | 算法团队协作 |
| 寒武纪硬件 | 合规审计日志 | 公有云平台适配 | 边缘计算落地 |
| 多品牌异构算力 | 组织架构管理 | 第三方系统对接 | 算力利用率提升 |
| 国产化硬件适配 | 多级配额管理 | 开源工具链集成 | 研发效率提效 |
文慧的科技江湖

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)