企业 AI / Agent / RAG 上线前检查清单:6 层合规审计、工具越权与 FAQ
企业 AI 应用上线后,最容易被低估的风险,不是模型偶尔回答错误,而是模型接入知识库、外部检索、工单系统、邮件工具之后,在真实业务链路中被不可信输入带偏,并进一步触发错误输出或错误动作。
如果你的 AI 应用已经具备以下能力,就不应该只做“模型效果测试”,而应该同步做 AI 合规审计:
- 接入内部知识库或外部网页检索;
- 读取客户资料、工单、邮件、合同、配置等业务数据;
- 能调用工具、插件、API 或自动化流程;
- 输出内容会被客服、销售、运营、研发或管理层直接采用;
- 影响客户沟通、权限、隐私、资金、合规边界或业务决策。
本文给出一套更偏工程落地的 AI 合规审计方法,适合用于上线前检查、上线后巡检和周度复盘。
核心结论:
AI 合规审计不是补材料,而是确认 AI 系统在真实运行链路中是否可信、可控、可追溯。
1. 先明确:AI 合规审计到底审什么
很多团队会把 AI 审计理解成“看模型是否安全”或“看制度是否写完”。这两件事都重要,但不够。
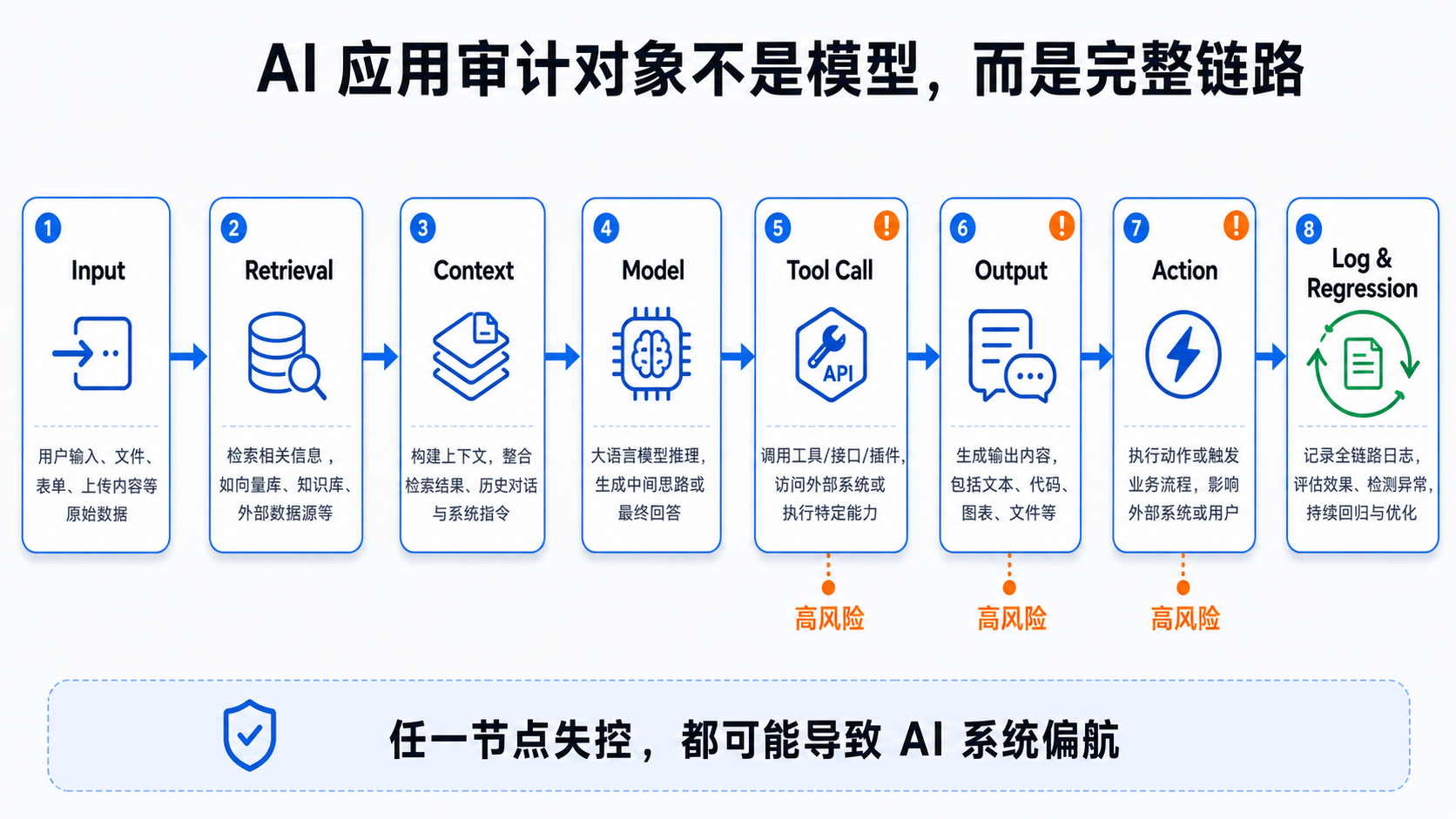
企业 AI 应用真正的风险通常出现在链路中:
用户输入 / 外部内容
↓
检索 / 知识库 / 工具返回
↓
模型上下文
↓
模型输出
↓
系统执行 / 人工采用
↓
日志 / 复盘 / 回归
因此,审计对象不是单个模型,而是模型、数据、工具、权限、输出、人工确认和日志回放组成的完整系统。
从工程实践上,可以拆成 6 层:
| 层级 | 审计对象 | 核心问题 |
|---|---|---|
| 输入层 | 用户输入、外部网页、邮件、知识库、上传文件 | 输入来源是否可信,是否与系统指令隔离 |
| 工具层 | 插件、API、工单、邮件、CRM、配置系统 | 工具权限是否最小化,是否存在越权调用 |
| 输出层 | 自由文本、结构化结果、自动执行内容 | 哪些输出可执行,哪些只能作为建议 |
| 留痕层 | 检索日志、tool call、模型输出、人工确认 | 出问题后是否可回放、可定位 |
| 复核层 | reviewer、人工确认、双重验证 | 高风险动作是否有人兜底 |
| 回归层 | 攻击样本、异常样本、规则库、周度抽检 | 上线后是否持续检查风险漂移 |
这 6 层缺任何一层,AI 系统都可能出现“上线时看起来没问题,运行一段时间后无法解释”的情况。
2. 第一步:做系统盘点
审计之前,先把系统盘点清楚。建议至少建立一张表:
| 字段 | 示例 | 说明 |
|---|---|---|
| 系统名称 | 客服 AI 助手 | 哪个 AI 应用 |
| 业务场景 | 客户问题总结、回复建议 | 服务什么流程 |
| 负责人 | 客服产品负责人 / 技术负责人 | 谁负责上线和复盘 |
| 数据源 | 知识库、工单、客户沟通记录 | 模型能读什么 |
| 工具权限 | 查询工单、生成回复、读取客户标签 | 模型能调用什么 |
| 输出去向 | 客服确认后发送给客户 | 输出会被谁使用 |
| 风险等级 | L2 / L3 | 是否影响客户、权限、隐私或合规 |
| 日志状态 | 已记录 / 未记录 / 不完整 | 是否可追溯 |
注意!:如果企业内部已经有多个团队在试用 AI,这一步非常重要。很多风险不是来自单个系统,而是来自“谁都接了一点,没人知道全貌”。
如果你正在整理上线评审表,可以先收藏这张系统盘点表。需要完整可复用版本,可以在评论区留言 「AI审计清单」,获取《企业 AI 合规审计 Checklist》。
3. 第二步:检查输入层,区分可信与不可信内容
Prompt Injection 风险的核心,不是用户输入了一句“请忽略之前指令”这么简单。更常见的情况是间接注入:恶意指令藏在网页、邮件、知识库片段、文档或工具返回值里,被模型当作任务上下文读取。
输入层建议检查以下问题:
| 检查项 | 推荐处理 |
|---|---|
| 外部网页是否默认可信 | 默认不可信,进入上下文前标记来源 |
| 用户上传文件是否默认可信 | 默认不可信,必要时做内容扫描和隔离 |
| 知识库内容是否区分来源 | 区分内部认证内容、人工维护内容、外部同步内容 |
| 工具返回值是否可能包含指令 | 工具返回只作为数据,不作为系统指令 |
| 系统指令和外部内容是否混在一起 | 必须分层处理,避免被外部内容覆盖 |
一个基本原则:
外部内容只能作为被处理的数据,不能变成新的系统指令。
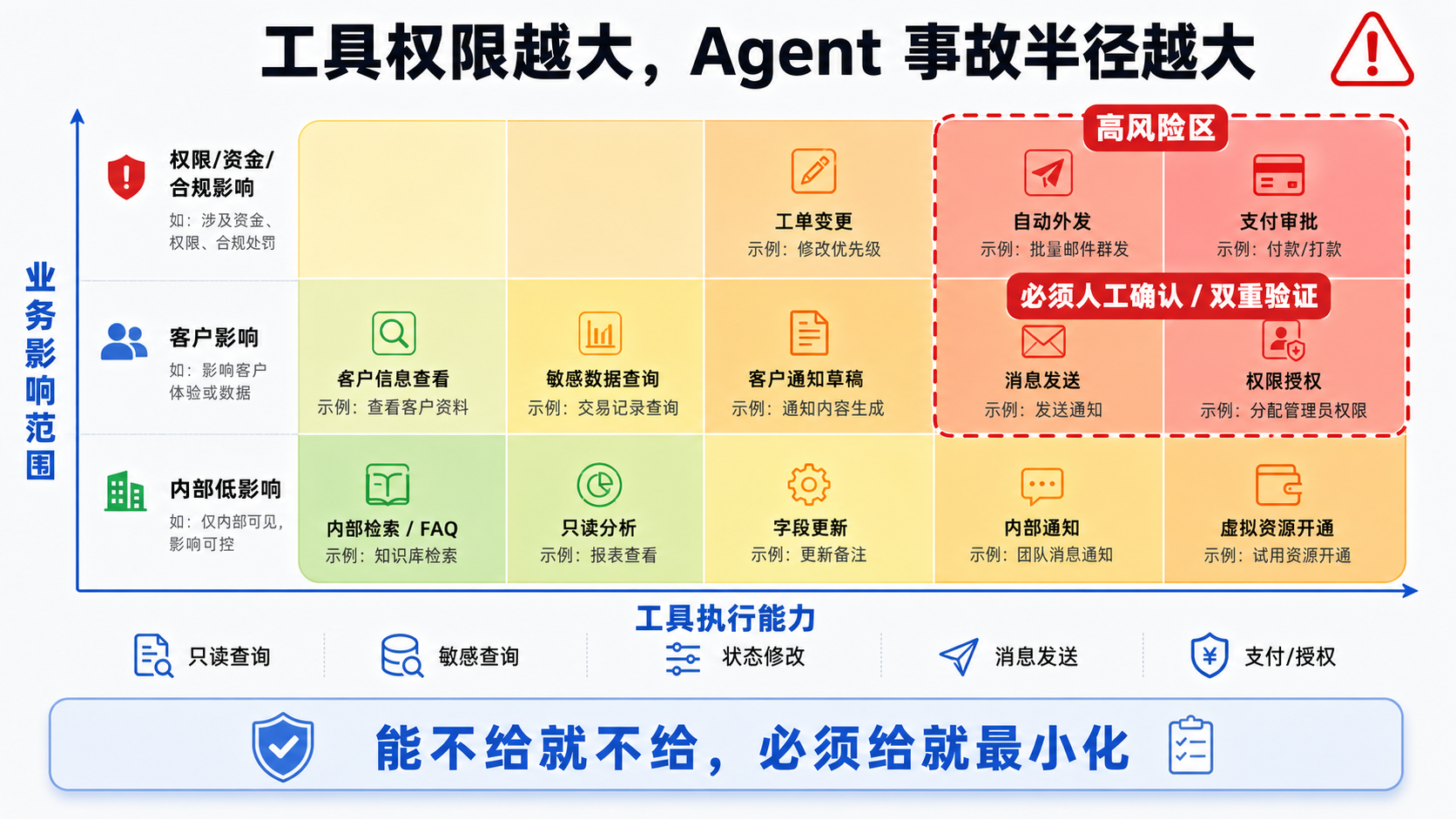
4. 第三步:检查工具权限,避免“过度代理”
当模型可以调用工具时,风险会明显放大。
尤其是这些能力:
- 查询客户信息;
- 修改工单状态;
- 发送邮件或消息;
- 修改系统配置;
- 访问敏感数据;
- 触发审批、退款、授权等流程。
工具层审计的重点不是“模型能不能完成任务”,而是“为什么必须给它这个权限”。
建议按最小权限原则设计:
| 工具类型 | 风险 | 建议 |
|---|---|---|
| 只读查询工具 | 中低 | 允许使用,但记录查询日志 |
| 客户数据查询 | 中高 | 限定字段,屏蔽敏感信息 |
| 消息发送工具 | 高 | 必须人工确认后发送 |
| 配置修改工具 | 高 | 默认禁止自动执行 |
| 支付、退款、权限变更 | 高 | 不允许模型单独闭环,必须双重验证 |
如果一个 AI Agent 同时具备“能查、能改、能发”的能力,就必须重点审计。因为一旦模型被带偏,影响范围会比普通问答系统大很多。
5. 第四步:检查输出层,切断错误自动执行链路
企业 AI 应用里,最危险的输出不是“回答错了”,而是“回答错了以后被系统执行了”。
输出层建议做三件事:
- 能结构化的输出尽量结构化;
- 高风险输出必须降级为建议;
- 自动执行前必须有人或规则兜底。
示例输出结构:
{
"suggestion": "建议客服回复客户说明当前问题已进入排查流程",
"risk_level": "L2",
"requires_human_review": true,
"source_refs": ["ticket_1024", "kb_88"],
"blocked_actions": ["send_email", "close_ticket"]
}这种结构的好处是:
- 可以强制标记风险等级;
- 可以明确是否需要人工确认;
- 可以保留来源引用;
- 可以把高风险动作从输出中隔离出来。
不要让模型直接输出“可执行命令”,再由下游系统无条件执行。这是很多 AI 应用风险扩大的关键原因。
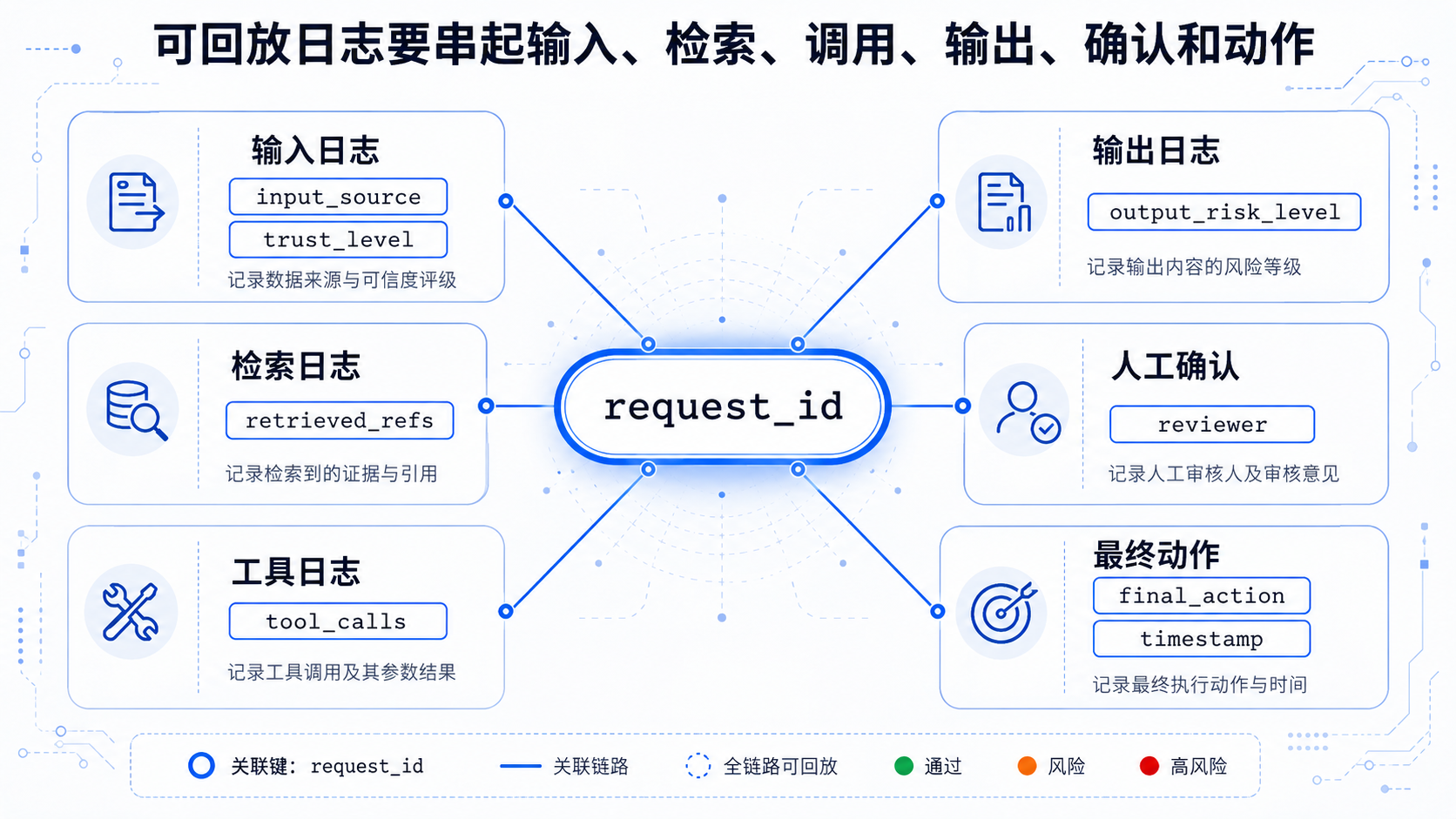
6. 第五步:检查留痕层,保证可回放
没有日志,就没有审计。
AI 系统至少要记录以下内容:
| 日志类型 | 必要字段 |
|---|---|
| 请求日志 | request_id、user_id、system_id、timestamp |
| 输入日志 | 输入来源、可信等级、是否命中风险规则 |
| 检索日志 | query、召回内容、来源、排序结果 |
| 工具调用日志 | tool_name、参数、返回结果、调用人 / 调用系统 |
| 输出日志 | 模型输出、风险等级、是否需要人工确认 |
| 人工确认日志 | reviewer、确认结果、修改记录、时间 |
一个简化日志结构可以这样设计:
{
"request_id": "ai_audit_20260609_001",
"system_id": "customer_success_agent",
"user_id": "u_1001",
"input_source": "external_email",
"input_trust_level": "untrusted",
"retrieved_refs": ["kb_23", "ticket_889"],
"tool_calls": [
{
"tool": "ticket_query",
"permission": "read_only",
"result_logged": true
}
],
"output_risk_level": "L2",
"requires_human_review": true,
"reviewer": "cs_manager_01",
"final_action": "edited_and_sent",
"timestamp": "2026-06-09T10:30:00+08:00"
}日志的目标不是“存下来”,而是出问题后能回答三个问题:
- 问题从哪个输入引入?
- 哪个工具调用扩大了影响?
- 哪个人或规则在最后一步做了确认?
7. 第六步:建立复核和回归机制
AI 审计不能只做上线前一次。
因为上线后会持续发生变化:
- 知识库内容会更新;
- 工具权限会调整;
- 用户输入方式会变化;
- 业务流程会变化;
- 风险样本会增加。
建议建立周度回归机制:
| 周度检查项 | 要回答的问题 |
|---|---|
| 新增 AI 场景 | 本周是否新增系统、Agent、插件 |
| 新增数据源 | 是否接入外部网页、邮件、用户上传文件 |
| 新增工具权限 | 是否新增可查询、可修改、可发送的工具 |
| 异常输出 | 是否出现不符合预期的输出 |
| 高风险动作 | 是否绕过人工确认 |
| 日志回放 | 是否能回放关键请求链路 |
| 样本回归 | 是否把新风险样本写入测试集 |
这一步的关键是持续性。一次审计只能证明上线当时的状态,持续回归才能证明系统上线后仍然可控。
8. 风险分级建议
可以直接把 AI 使用场景分成三档:
| 风险等级 | 场景 | 处理方式 |
|---|---|---|
| L1 低风险 | 摘要、会议纪要、头脑风暴、内部知识整理 | 可高频使用 AI,重点关注效率和复用 |
| L2 中风险 | 需求分析、技术方案初稿、外发内容草稿、测试样例 | 必须有 reviewer 和验证环节 |
| L3 高风险 | 权限策略、客户沟通定稿、隐私与合规数据处理、生产代码核心逻辑 | 不允许 AI 生成后直接采用,必须人工主写或双重验证 |
这个分级可以直接用于上线评审表、需求评审表和内部 AI 使用规范。
9. 整改动作表
| 风险 | 典型问题 | 整改动作 |
|---|---|---|
| 外部内容与系统指令混在一起 | 模型把网页或邮件里的恶意指令当成任务要求 | 外部内容默认标记为不可信,与系统指令分层处理 |
| 工具权限过大 | 模型既能查客户信息,又能发消息、改工单 | 权限最小化,高风险工具默认关闭 |
| 输出可直接自动执行 | 错误输出被下游系统直接执行 | 高风险输出只能作为建议,执行前必须人工确认 |
| 日志不完整 | 出问题后无法定位输入、检索、调用、输出链路 | 为检索、tool call、输出和人工确认建立日志 |
| 只上线前审计一次 | 上线后风险随数据源和权限变化而漂移 | 建立每周抽检和红队样本回归 |

10. 总结
企业 AI 合规审计的重点,不是证明“模型没有问题”,而是证明整条 AI 业务链路可控。
如果要落地,可以按这个顺序执行:
- 盘点所有 AI 系统和工具链;
- 区分可信输入和不可信输入;
- 收敛工具权限;
- 约束输出边界;
- 建立可回放日志;
- 增加人工复核;
- 做周度回归。
真正能让 AI 放心上线的,不是制度写得厚,而是系统能持续证明自己可信、可控、可追溯。
如果你正在做企业 AI 应用、RAG、Agent 或内部 AI 工具上线,可以收藏这篇文章,并在评论区留言 「AI审计清单」,获取《企业 AI 合规审计 Checklist》。
这份 Checklist 会覆盖系统盘点、输入分层、工具权限、输出边界、日志字段、人工复核和周度回归,适合直接放进上线评审、技术方案评审或安全复盘流程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)