R语言变量选择
变量选择的核心问题
在多个候选自变量中,选择一部分真正有解释力或预测力的变量,使模型既不过于复杂,也不过于简单。
一、变量选择的基本模型
多元线性回归完整模型为:
其中,表示候选自变量个数。
如果我们只选择其中一部分变量,记选中的变量集合为,那么候选模型可以写成:
其中,表示被选入模型的变量集合。
如果 ,就表示模型只保留
。
二、变量选择为什么不能只看 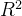
决定系数为:
其中:
但是,在多元回归中,只要不断加入变量,SSE 通常会下降, 通常会增加。也就是说:
所以,如果只看 ,模型会倾向于保留更多变量,容易出现过拟合。
因此,变量选择需要同时考虑:
拟合优度+模型复杂度惩罚
三、调整后的
为了解决普通 偏向复杂模型的问题,可以使用调整后的
。
其中, 是样本量,
是模型参数个数,包括截距项。
如果选入变量个数为,那么:
调整后的 会对变量数量进行惩罚。如果加入的新变量不能明显降低
,调整后的
反而可能下降。变量选择时,可以选择调整后
最大的模型:
四、AIC 准则
AIC 全称是 Akaike Information Criterion,即赤池信息准则。它的一般形式为:
其中,是模型似然函数,
是参数个数。在线性回归正态误差假设下,AIC 常写成:
AIC 的选择规则是:
AIC 越小,说明模型在拟合效果和复杂度之间的平衡越好。
一般来说,AIC 的惩罚相对较弱,因此它更倾向于选择变量稍多、预测能力较强的模型。
五、BIC 准则
BIC 全称是 Bayesian Information Criterion,即贝叶斯信息准则。它的一般形式为:
在线性回归中,BIC 常写成:
BIC 的选择规则是:
与 AIC 相比,BIC 的惩罚项是 ,通常比 AIC 的
更大。也就是说,BIC 更偏向选择简洁模型。AIC 和 BIC 的核心区别可以写成:
当 较大时,通常有:
所以 BIC 对模型复杂度的惩罚更强。
六、Mallows  准则
准则
也是经典变量选择准则,用于衡量模型偏差和方差之间的平衡。其公式为:
其中, 表示当前候选模型的残差平方和,
通常由完整模型估计得到。
完整模型的误差方差估计为:
一般来说,如果一个模型比较合理,则:
其中 是当前模型的参数个数,包括截距项。
七、嵌套模型的 F 检验
变量选择也可以基于假设检验进行。比如比较一个完整模型和一个简化模型。
简化模型的残差平方和记为:
完整模型的残差平方和记为:
其中,R表示 reduced model,F表示 full model。
嵌套模型 F 检验统计量为:
其中, 是完整模型参数个数,
是简化模型参数个数。
原假设通常为:
被删除变量的回归系数均为0
备择假设为:
至少有一个被删除变量的回归系数不为0
如果 F 检验显著,说明被删除的变量整体上有贡献,不应该删除。
八、向前选择
向前选择的思想是:
从空模型开始,每次加入一个最能改善模型的变量。空模型为:
每一步尝试加入一个候选变量,选择使准则最优的变量。例如使用 BIC,则选择:
如果加入变量后准则下降,则保留该变量:
否则停止选择。
向前选择适合候选变量较多、但希望逐步构建模型的情况。
九、向后剔除
向后剔除的思想是:从完整模型开始,每次删除一个最不重要的变量。
完整模型为:
如果删除变量后 BIC 下降,则删除该变量:
否则停止。
向后剔除适合样本量足够,并且一开始可以拟合完整模型的情况。
十、逐步回归
逐步回归结合了向前选择和向后剔除。它的思想是:每一步既允许加入变量,也允许删除变量。
当前变量集合为,则每一步同时比较:
加入变量:
删除变量:
然后选择使准则下降最多的操作:
其中,可以是 AIC、BIC、调整后的
或其他准则。
十一、全子集选择
全子集选择是最直接的方法。如果有个候选变量,则所有可能模型数量为:
例如,则模型数量为:
全子集选择会遍历所有变量组合,然后选择准则最优的模型:
如果使用 AIC,则为:
全子集选择的优点是可以找到全局最优模型;缺点是当很大时计算量会非常大。
总结
变量选择的本质是:在多个候选模型中,通过 AIC、BIC、调整后 、
或 F 检验等准则,选择一个既能较好解释数据、又不过度复杂的模型。
变量选择可以概括为:
候选变量→构建候选模型→计算评价准则→比较模型→确定最终变量集合

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)