TRO 2026|轮椅也能“猜到”用户想往哪走?
哈喽大家好,我是疯狂读论文的戴夫。今天继续啃一篇论文,给快要宕机的脑子升升级。
智能轮椅听起来已经很成熟了:装上雷达、摄像头、避障算法,好像就能帮助行动不便的人更安全地移动。
但真正的人机协作没有这么简单。
轮椅用户在控制轮椅时,可能突然想绕开人群,可能想穿过门,也可能只是靠近门口看一眼。人在导航中的意图本身带有不确定性,尤其是在走廊分叉、门口、拥挤区域这些场景里,仅凭当前摇杆输入很难判断用户接下来到底想去哪里。
这篇 TRO 2026 论文讨论的就是这个问题:
智能轮椅能不能根据用户动作、视线、环境和语义信息,预测用户未来几秒可能走出的多条轨迹?
论文题目是:
Navigating Uncertainty: Diffusion-Based User Intention Estimation for Wheelchair Assistance
DOI:10.1109/TRO.2025.3637101
可以理解为:
基于扩散模型的智能轮椅用户意图估计方法。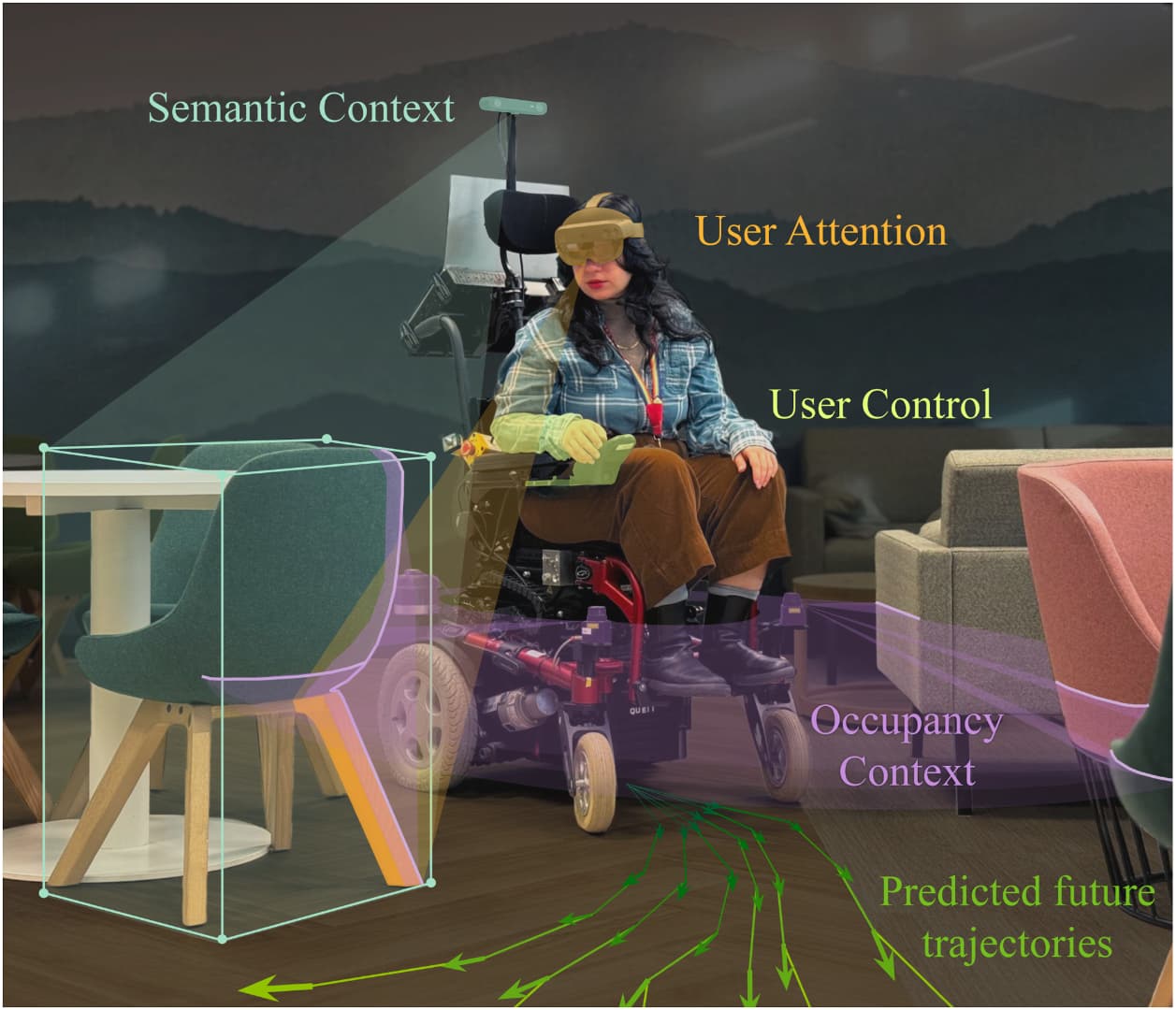
图1 DIWIE 概念图
一、这篇论文讲什么?
这篇论文研究的是智能轮椅中的 user intention estimation,用户意图估计。
在共享控制系统里,轮椅用户仍然是主要操作者,系统负责提供辅助。一个好的辅助系统,需要提前知道用户大概想往哪里走,再决定是否帮他避障、修正方向或提供额外速度控制。
这里的关键问题是:
用户意图不是一个确定答案,而是一组可能的未来轨迹。
比如在一个三岔路口,用户可能直行,也可能左转,也可能右转。在环境线索不足时,预测用户意图本来就存在不确定性。
所以作者没有把问题做成“预测一个唯一目标点”,而是提出了一个扩散模型框架:
DIWIE:Diffusion-based Wheelchair User Intention Estimation
它要做的事情是:输入最近一段时间的轮椅状态、环境障碍物、用户注意力、语义信息和摇杆命令,然后生成未来几秒内多条可能轨迹。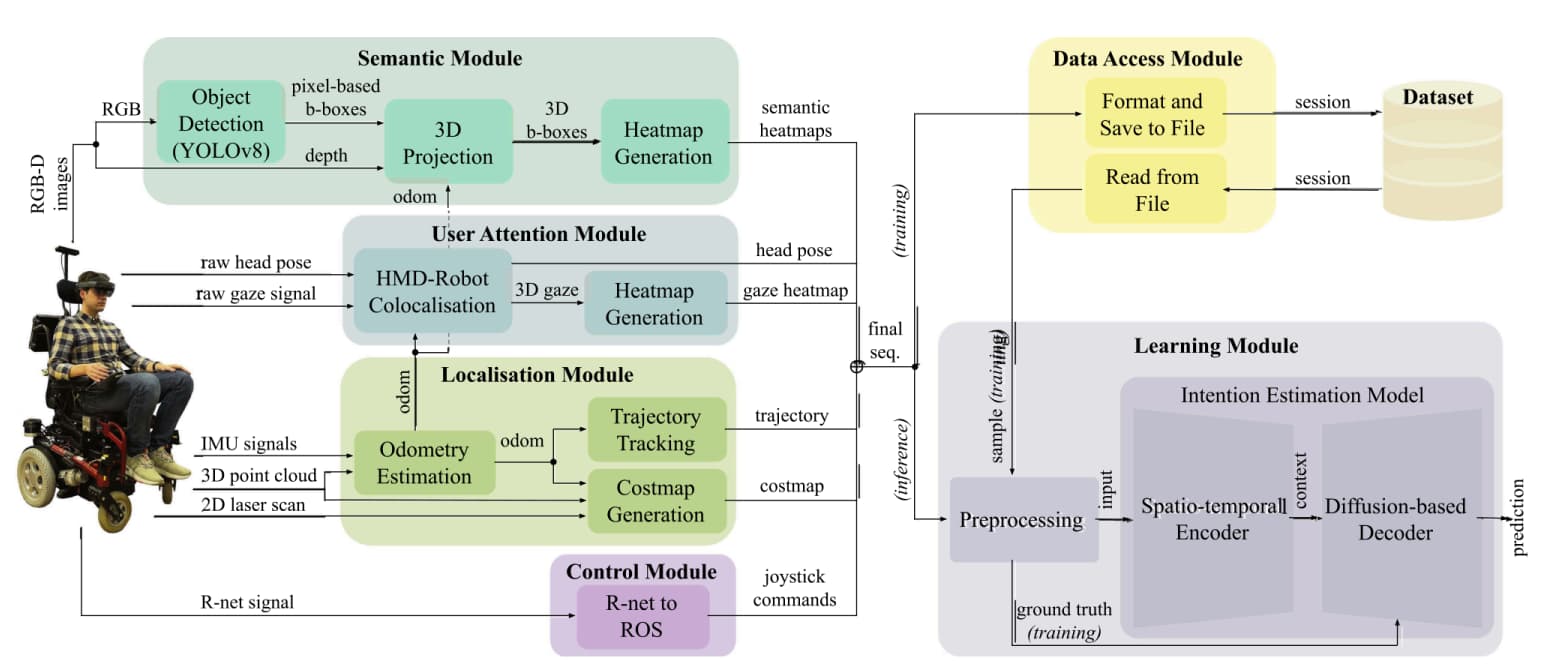
图2 DIWIE 总体框架
二、现有方法卡在哪里?
早期智能轮椅的意图估计,常依赖预定义地图、固定目标点或简单启发式规则。
比如系统先知道环境里有哪些门、走廊、终点,再根据用户当前位置和摇杆输入判断他可能要去哪。
这种方法在结构化环境里可以工作,但现实场景更复杂:
用户目标可能临时变化;
环境里可能有人群和动态障碍物;
用户不一定总是走最短路径;
预先标注所有可能目标并不现实;
只看摇杆输入,很难理解用户更高层的意图。
所以这篇论文的切入点是:
用数据驱动方法建模用户短期未来轨迹,同时显式保留人类行为的不确定性。
扩散模型正好适合做这件事,因为它可以从噪声中生成多种合理轨迹,而不是只输出一条确定路线。
三、作者怎么解决?
DIWIE 的核心思路可以概括为:
把轮椅用户意图估计,建模成条件扩散模型下的短期轨迹生成问题。
它预测的不是长期目标,比如“去办公室”或“去门口”,而是未来几秒的短期轨迹。
论文中使用过去 5 秒的历史信息,预测未来 5 秒的轮椅运动轨迹。
输入信息包括五类:
第一,轮椅过去运动轨迹。
也就是轮椅最近怎么移动、朝向怎么变化。
第二,占据栅格图。
用来表示周围障碍物,比如墙、桌子、人群、门框等。
第三,用户注意力信息。
包括眼动注视点和头部姿态,用来判断用户可能在看哪里。
第四,语义信息。
比如门、桌子、椅子、人、楼梯等环境元素。
第五,摇杆命令。
也就是用户当前给轮椅的控制输入。
DIWIE 把这些信息编码成上下文表示,再通过扩散模型逐步去噪,生成多条可能的未来轨迹。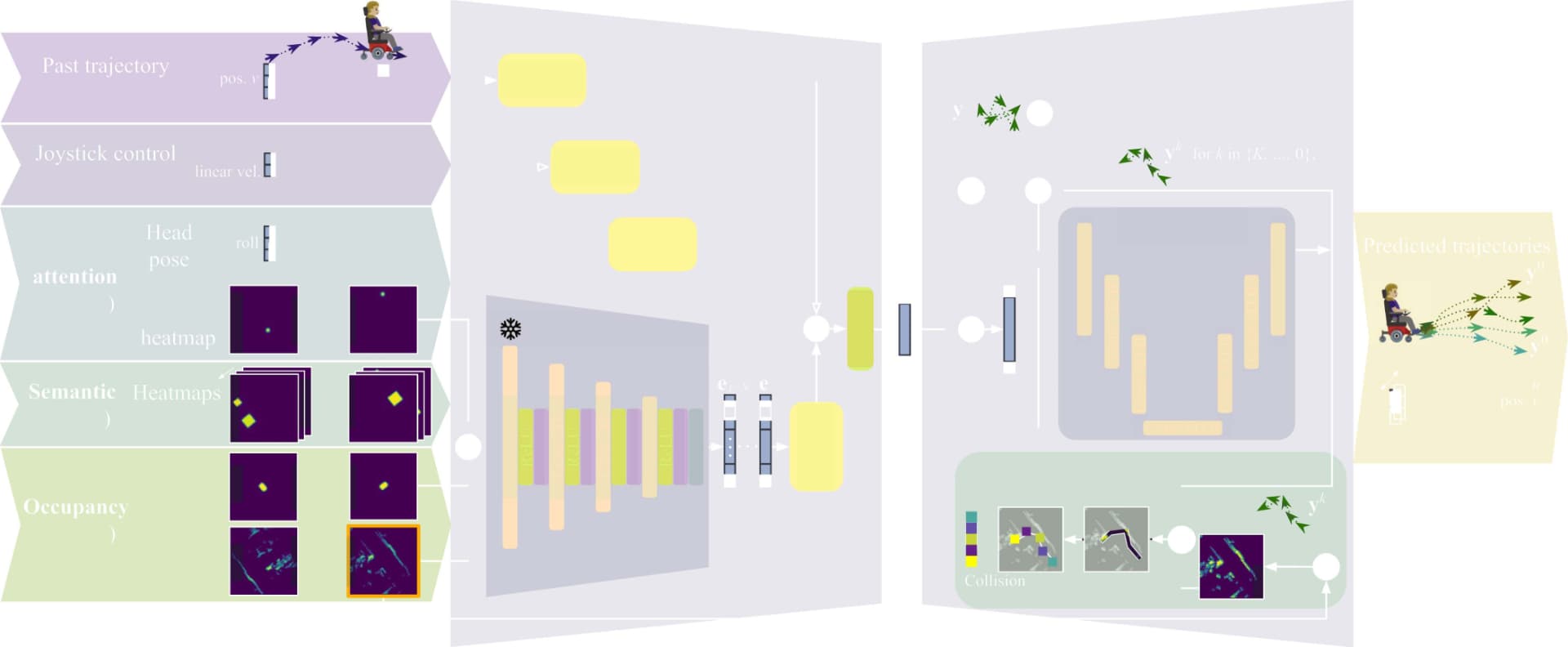
图3 模型结构图
四、关键设计拆解
1. 多模态输入
这篇论文最大的特点之一,是输入信息很丰富。
传统方法常常主要依赖摇杆输入和轮椅运动历史。DIWIE 进一步加入了障碍物、用户注意力和语义环境。
这很符合真实导航逻辑。
用户看向一扇门,可能意味着想穿过去;
用户看向旁边的人,可能意味着准备避让;
前方有桌子、墙或人群,都会影响未来路径选择。
轮椅要理解用户意图,就不能只看摇杆,还要看用户在看哪里、环境里有什么。
2. 条件扩散模型
扩散模型的作用,是从随机噪声中逐步生成未来轨迹。
在训练时,模型学习如何把加噪后的真实轨迹一步步还原回来;在推理时,模型从随机噪声出发,结合当前上下文,生成多条可能轨迹。
这样做的好处是可以表达不确定性。
如果当前场景很明确,多条轨迹会比较集中;如果当前场景有多个可能方向,多条轨迹会更分散。
3. 碰撞引导
作者还加入了 Collision Guidance,碰撞引导模块。
模型在生成轨迹时,会结合占据栅格图判断轨迹是否靠近障碍物,从而减少不合理的碰撞预测。
这让生成结果更接近真实轮椅导航需求,而不是只在数学上拟合轨迹。
4. 真实智能轮椅平台
论文使用的是自建智能轮椅平台,传感器包括 LiDAR、IMU、RGB-D 相机、HoloLens 2 头显等。
HoloLens 用来采集用户头部姿态和眼动注视信息;LiDAR 和相机用于构建障碍物与语义环境。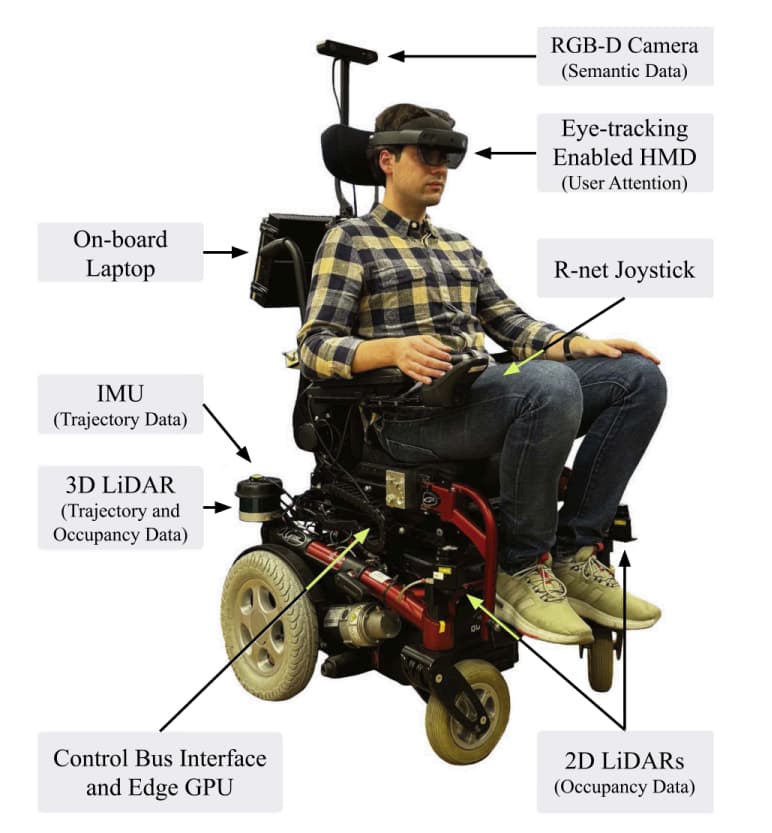
图4 智能轮椅平台
五、实验怎么验证?
作者构建了一个真实导航数据集。
数据来自 13 名驾驶者,在 4 个不同环境中自由驾驶轮椅。场景包括室内走廊、办公室、会议室、咖啡区、室外开放区域和行人较多的空间。
为了让驾驶行为更自然,作者还设计了一个 AR 找宝石小游戏:用户需要驾驶轮椅去寻找并收集虚拟宝石。
这样做的好处是,用户不是机械地按固定路线行驶,而是在更接近自然探索的状态下控制轮椅。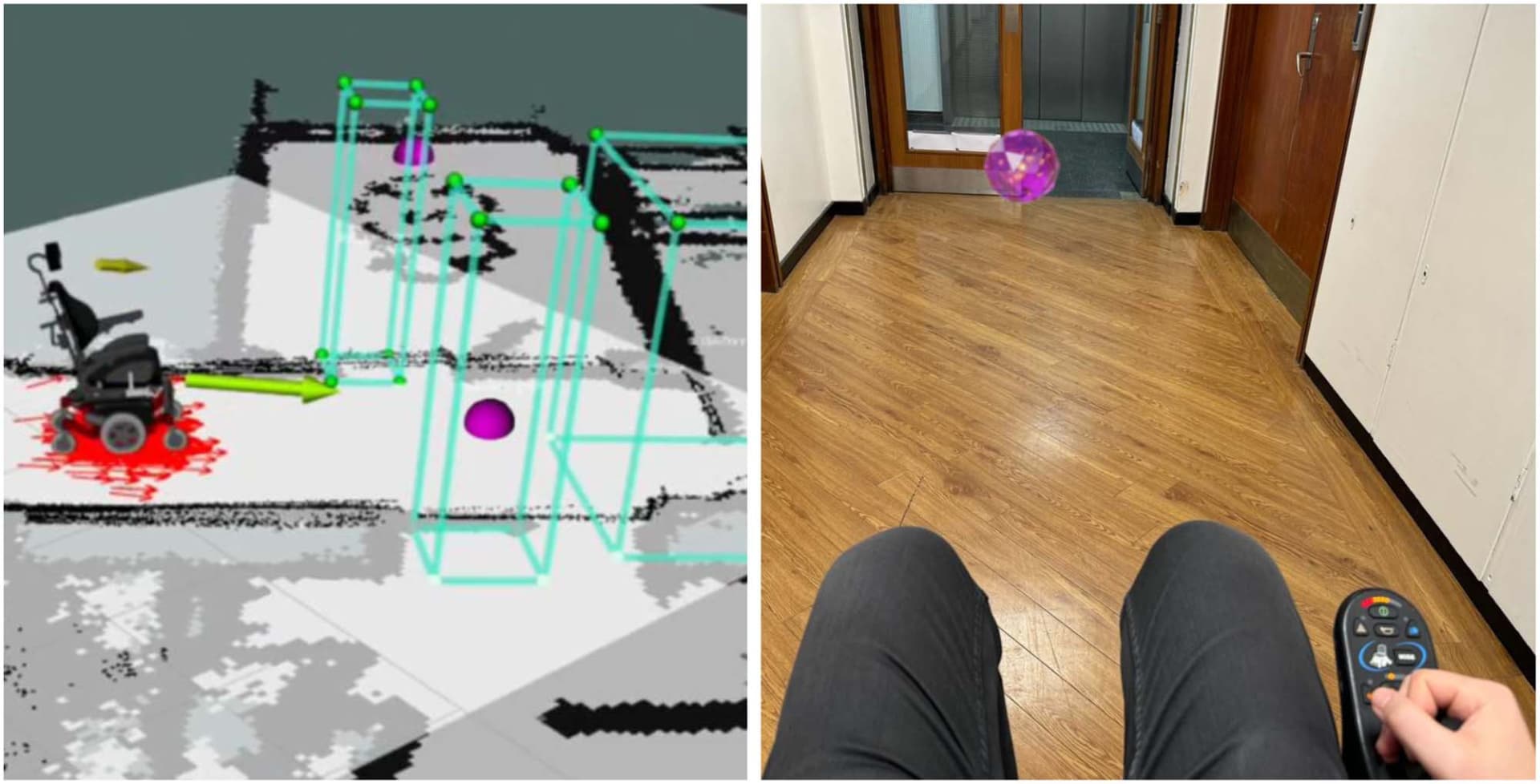
图5 AR 找宝石数据采集游戏
图6 数据采集环境
评价指标主要包括:
minADE:预测轨迹和真实轨迹的平均位置误差;
minFDE:最后一个预测点和真实终点的误差;
minRMSEO:轮椅朝向预测误差;
CR:预测轨迹碰撞率。
作者把 DIWIE 和 ConvLSTM、CVAE,以及没有碰撞引导模块的 DIWIE 变体进行了对比。
六、实验结果说明什么?
实验结果可以概括成三点。
第一,DIWIE 的轨迹预测更准。
从表格结果看,DIWIE 在 minADE、minFDE 和碰撞率上整体优于对比方法。尤其是 minFDE 能做到 1 米以内,这对于 5 秒预测窗口和轮椅自身尺寸来说比较有意义。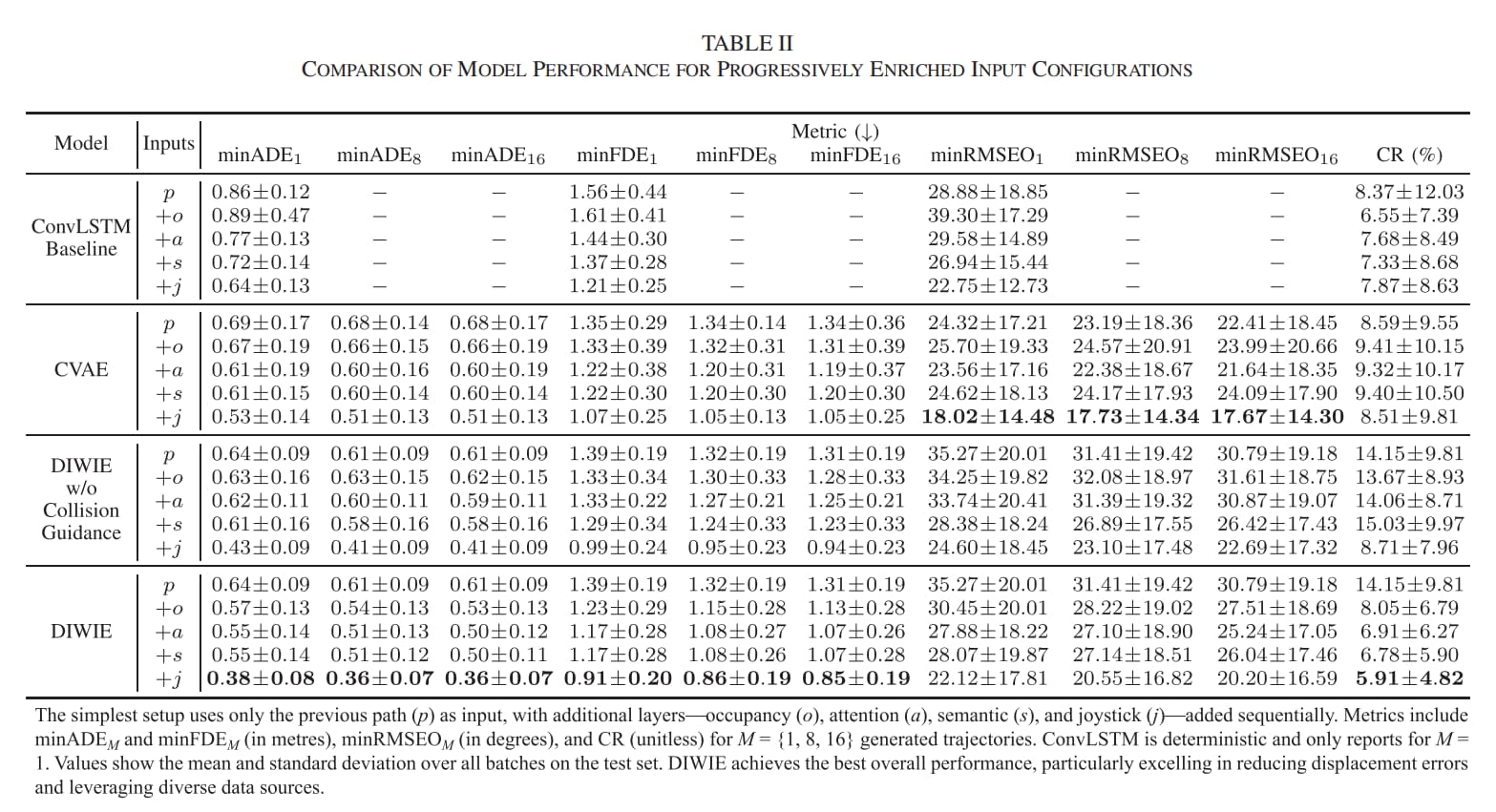
图7 不同模型性能对比
第二,多模态信息确实有帮助。
随着输入信息从单纯历史轨迹,逐步加入障碍物、注意力、语义信息和摇杆命令,模型整体表现变好。说明用户意图估计不能只靠轮椅过去怎么走,还需要结合用户和环境上下文。
第三,DIWIE 能表达不确定性。
论文中展示了不同场景下的定性结果。在三岔路口这类高不确定场景中,DIWIE 会生成多条可能轨迹,并保留多个合理假设。随着上下文信息增加,预测轨迹会逐渐集中,说明模型置信度提高。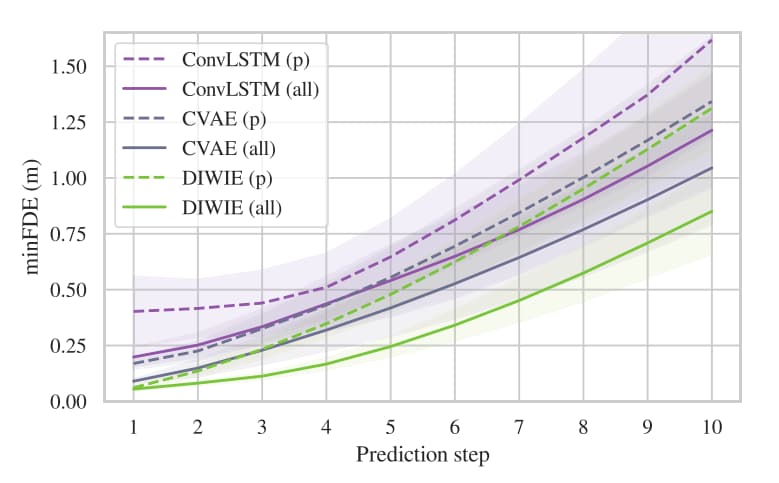
图8 预测误差随时间变化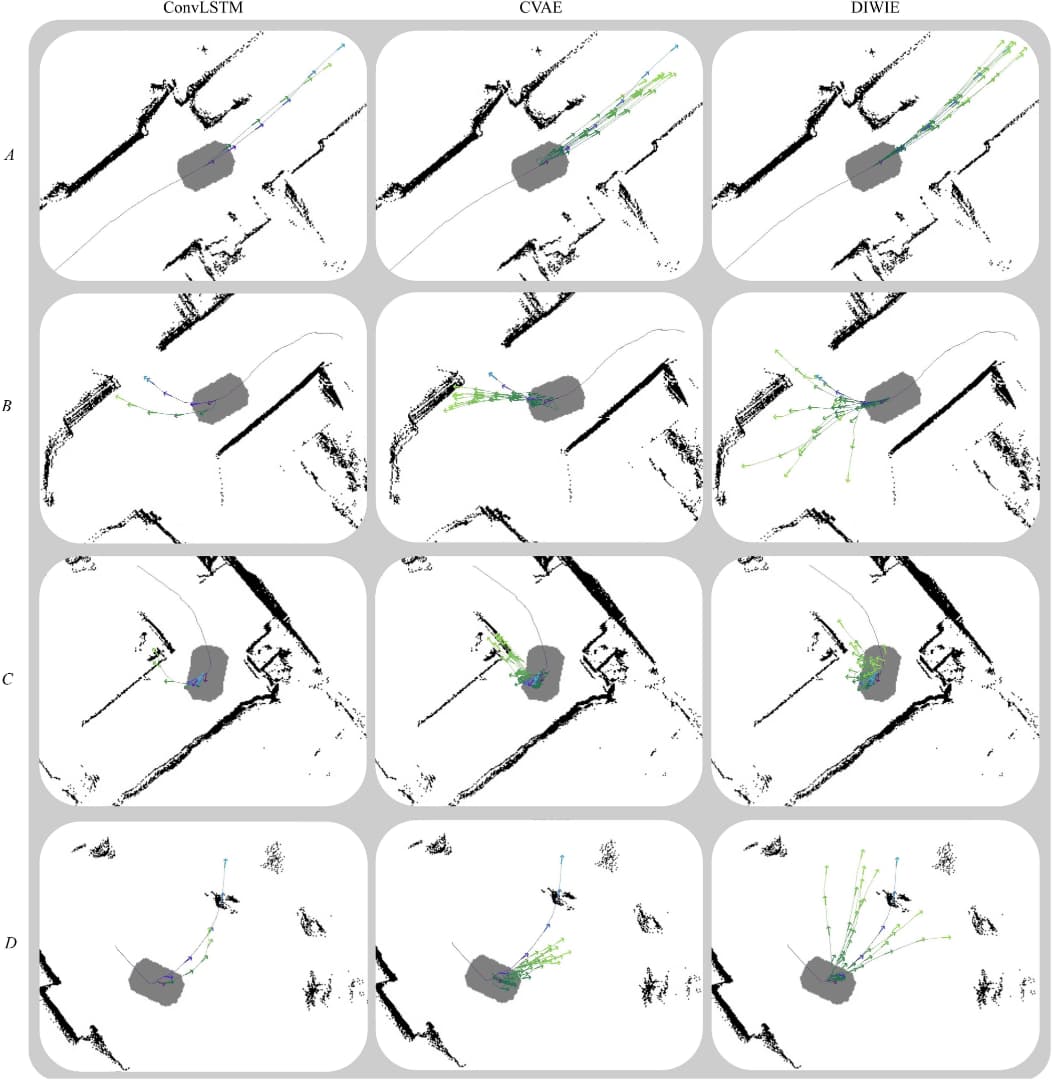
图9 四类场景预测可视化
不过论文也指出一个限制:DIWIE 对动态障碍物的显式建模还不够。例如人群正在移动时,模型未必能准确预测这些人未来会让出空间。
七、论文画像
应用范围: 这篇论文主要面向智能轮椅、辅助移动机器人、共享控制和人机意图预测,应用场景比较聚焦,但实际价值很强。
复现友好度: 复现门槛较高。模型本身可以复现,但完整实验需要智能轮椅、多传感器平台、眼动头显和真实用户数据采集。
方法新颖度: 亮点在于把扩散模型用于轮椅用户短期意图估计,并结合多模态输入和碰撞引导生成多条可行轨迹。
思维借鉴度: 很适合学习如何把辅助机器人问题转化成轨迹预测问题,也适合借鉴多模态数据融合和评价指标设计。
技术完整度: 论文从问题定义、模型设计、机器人平台、数据集采集到多指标实验验证,形成了比较完整的技术链条。
实验充分性: 实验包含真实平台、多个用户、多个环境、多种输入组合和多模型对比,支撑较充分。
最后总结
这篇 TRO 论文的核心价值在于:
它把智能轮椅辅助控制中的“用户想去哪”,转化成了一个多模态条件下的未来轨迹生成问题。
这篇文章最值得学的地方有三个:
第一,问题定义很清楚。
它不强行预测长期目的地,而是预测短期未来轨迹,更适合共享控制。
第二,多模态设计很完整。
轮椅运动、摇杆、障碍物、视线、头部姿态和语义环境都被纳入模型。
第三,实验比较扎实。
真实轮椅平台、真实用户、真实环境和公开指标,让结果更有说服力。
如果只记住一句话:
好的辅助机器人系统,需要在保留用户自主性的前提下,提前理解用户可能想怎么走。
关注我了解更多相关咨询。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)