一个开源反馈系统应该如何设计?从 Feedback 到 Roadmap 的闭环拆解
写在前面
很多团队一开始并不会认真设计“用户反馈系统”。早期用户少,反馈从哪里来都可以:微信群、Discord、邮件、客服私聊、GitHub Issue、社媒评论、飞书文档、Notion 表格,甚至开发者自己的备忘录。
这种方式在产品早期是有效的,因为信息量不大,团队成员之间也足够熟悉。谁提了什么问题、哪个用户比较重要、哪个 Bug 需要先修,大家凭记忆也能处理。
但产品进入增长阶段后,问题会迅速变形。反馈不是简单变多,而是开始失去上下文:同一个需求被不同用户反复表达;Bug 和功能建议混在一起;用户提交后不知道有没有被看到;团队明明一直在迭代,用户却感知不到变化。
这时,反馈系统如果仍然只是“留言板”,就很难支撑产品决策。更合理的设计,是把反馈当成一条产品沟通链路:
用户反馈 -> 团队整理 -> 需求合并 -> 路线图展示 -> 更新日志发布 -> 用户感知到变化
本文不写工具使用教程,而是从工程设计角度拆解:一个面向独立开发者、小型 SaaS 团队和开源项目的反馈闭环系统,应该如何设计数据模型、状态流转、语义去重、Roadmap、Changelog、自托管部署和权限边界。
一、为什么“收集反馈”本身不够
反馈系统最容易被低估的地方在于:团队以为自己缺的是收集入口,实际上缺的是反馈处理机制。
如果只是新增一个表单,用户确实更容易提交意见。但表单后面的流程没有变化,问题仍然存在:谁来整理?重复反馈怎么合并?哪些进入计划?哪些明确不做?发布后如何通知曾经关心这件事的用户?
对比一下几种常见做法:
| 方式 | 优点 | 问题 |
|---|---|---|
| 群聊/Discord | 反馈实时、沟通直接 | 信息容易被刷走,难以沉淀 |
| 邮件 | 适合详细描述问题 | 难以公开讨论,重复问题多 |
| GitHub Issue | 对开发者友好 | 普通用户门槛较高,产品反馈和工程问题混杂 |
| Notion/表格 | 灵活、低成本 | 状态、投票、通知都要手动维护 |
| 专门反馈系统 | 能形成闭环 | 需要设计权限、状态和数据关系 |
所以,一个反馈系统真正要解决的不是“让用户发消息”,而是把分散输入变成可整理、可合并、可排序、可公开沟通的产品资产。
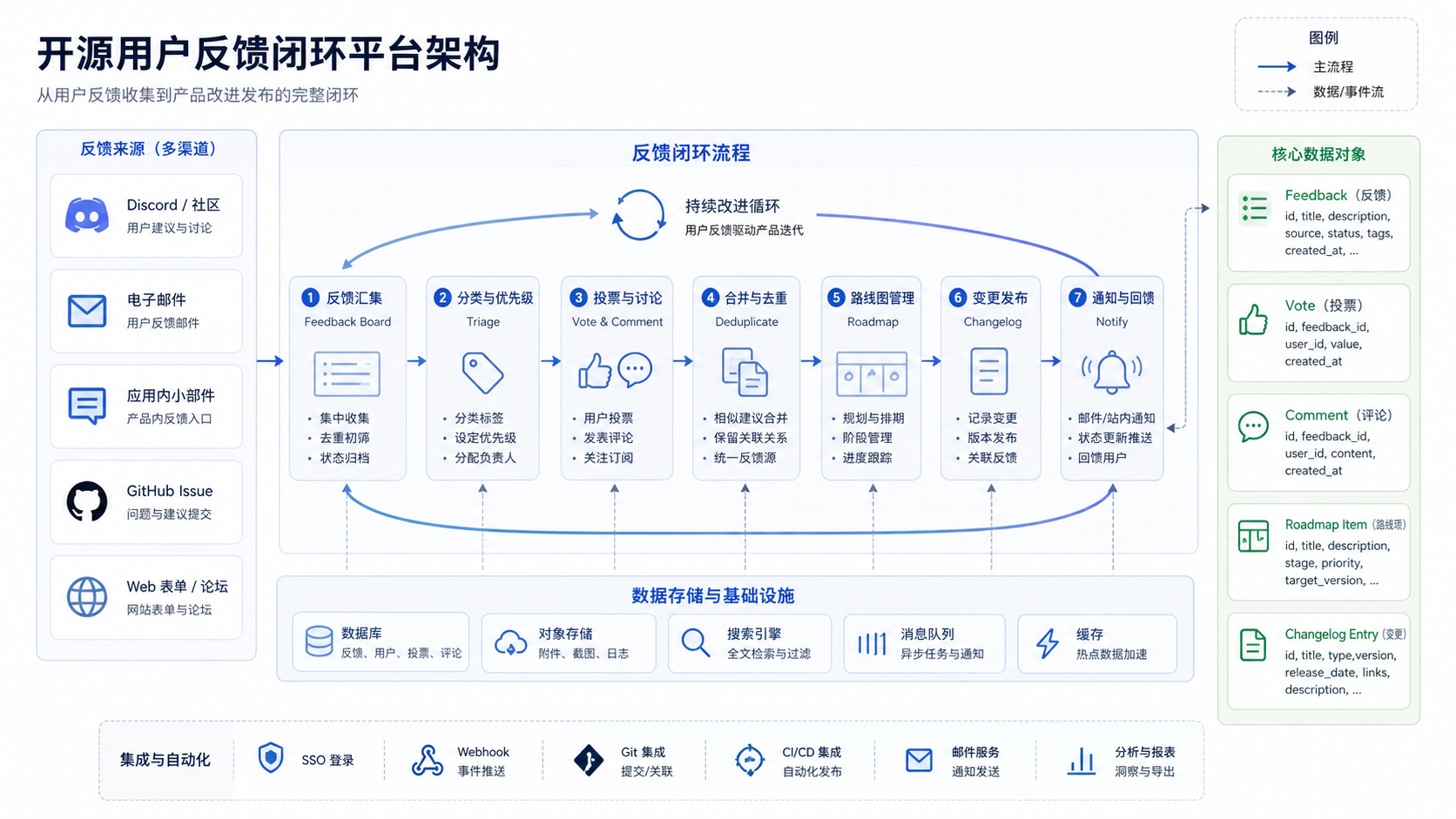
二、把反馈拆成四类对象
从数据建模看,反馈闭环系统至少需要四类核心对象:
| 对象 | 作用 | 典型字段 |
|---|---|---|
| Board | 反馈集合或空间 | name、visibility、slug、owner |
| Feedback | 用户提交的具体反馈 | title、description、status、author、votes |
| Roadmap Item | 团队计划或正在推进的事项 | title、stage、priority、related_feedback |
| Changelog Entry | 已发布的功能或修复记录 | title、type、content、release_date |
这四类对象最好不要混在一起。
Feedback 是用户语言,通常比较碎片化;Roadmap Item 是团队语言,应该更稳定、更抽象;Changelog Entry 是发布语言,要面向用户解释“发生了什么变化”。如果把三者都当成同一种记录,后续会很难处理。
举个例子:
| 用户反馈 | 团队整理后的 Roadmap Item | 发布后的 Changelog |
|---|---|---|
| 希望能用 GitHub 登录 | 增加第三方登录能力 | 新增 GitHub OAuth 登录 |
| 注册太麻烦了 | 增加第三方登录能力 | 新增 GitHub OAuth 登录 |
| 团队成员不想再记一个密码 | 增加第三方登录能力 | 新增 GitHub OAuth 登录 |
三个用户说的是不同话,但背后的产品需求可能是同一个。反馈系统要做的,就是保留这些用户声音,同时允许团队把它们合并到一个更清晰的产品事项上。
三、反馈对象怎么设计
一个反馈对象不应该只有标题和正文。至少需要包含状态、作者、投票、评论、分类、合并关系和时间信息。
可以抽象成下面这样的结构:
{
"id": "feedback_xxx",
"board_id": "board_xxx",
"author_id": "user_xxx",
"title": "希望支持 GitHub 登录",
"description": "当前只能邮箱注册,团队协作不方便",
"category": "feature",
"status": "open",
"vote_count": 12,
"comment_count": 4,
"merged_into": null,
"created_at": "2026-06-10T10:00:00Z",
"updated_at": "2026-06-10T10:00:00Z"
}
这里有几个字段很关键:
| 字段 | 为什么重要 |
|---|---|
| board_id | 区分不同产品、模块或反馈空间 |
| author_id | 支持后续通知和用户分层 |
| status | 让反馈有明确生命周期 |
| vote_count | 表示需求广度 |
| comment_count | 表示讨论深度 |
| merged_into | 支持重复反馈合并 |
| category | 区分 Bug、功能建议、体验问题 |
很多团队后期想做数据分析时,才发现早期反馈只有一段文本,没有状态、没有作者、没有合并关系。这会导致历史数据很难被重新利用。
四、公开 Board 和私有 Board 要分开
反馈系统常见的一个设计问题,是把所有反馈都默认公开。实际上并不是所有内容都适合公开讨论。
公开反馈适合收集产品建议、常规 Bug、体验问题和用户投票。但企业客户需求、安全问题、账单问题、私有部署问题,通常更适合进入私有 Board 或内部处理队列。
| Board 类型 | 适合内容 | 权限边界 |
|---|---|---|
| 公开 Board | 功能建议、体验反馈、普通 Bug | 用户可浏览、投票、评论 |
| 私有 Board | 企业客户需求、安全问题、内部反馈 | 仅团队或特定成员可见 |
| 嵌入式 Board | 产品内反馈入口 | 依赖业务系统传入身份 |
| Triage Board | 待整理反馈池 | 团队内部使用 |
公开与私有的边界要尽早设计。尤其是 API 查询层,不能只依赖前端隐藏。任务列表、详情页、搜索、相似反馈候选,都必须校验用户是否有权限访问对应 Board。
五、状态机:用户反馈需要可解释的生命周期
反馈闭环系统最核心的产品体验之一,是让用户知道“这条反馈现在处于什么状态”。
一个基础状态机可以这样设计:
状态含义可以拆成表格:
| 状态 | 含义 | 用户侧感知 |
|---|---|---|
| open | 新反馈,尚未处理 | 已提交,可投票评论 |
| under_review | 团队正在评估 | 团队已经看到 |
| planned | 已进入计划 | 可能出现在 Roadmap |
| in_progress | 正在开发 | 有明确推进动作 |
| shipped | 已发布 | 可关联 Changelog |
| merged | 合并到已有反馈 | 跳转到主反馈 |
| closed | 暂不处理或已过期 | 应说明关闭原因 |
这里最重要的是“可解释”。比如关闭反馈时,最好给出原因:重复、超出当前方向、暂不支持、已有替代方案、缺少更多信息等。否则用户只会看到反馈被关闭,而不知道为什么。
六、投票和评论不是社交装饰
很多反馈系统会提供投票和评论,但如果后端只是简单存数量,价值会被浪费。
投票代表需求广度,评论代表需求深度。两者都应该进入优先级判断,但不能机械地只看票数。
| 信号 | 表示什么 | 使用方式 |
|---|---|---|
| 投票数 | 有多少用户关注 | 判断需求覆盖面 |
| 评论数 | 是否有复杂场景 | 判断需求深度 |
| 最近活跃 | 问题是否持续 | 判断时效性 |
| 用户类型 | 谁在提这个需求 | 区分免费用户、付费客户、内部团队 |
| 重复反馈数 | 是否大量用户独立提出 | 判断真实痛点 |
一个只有 5 票但来自关键客户、并且评论里包含详细业务场景的反馈,可能比一个 50 票但描述模糊的建议更重要。反馈系统应该提供这些上下文,而不是替团队做单一排序。
七、AI 语义去重:更适合做候选召回,而不是自动裁决
重复反馈是反馈平台里最常见的问题。用户不会用同样的词表达同一个需求。
例如:
| 用户表达 | 背后需求 |
|---|---|
| 希望支持 GitHub 登录 | 第三方登录 |
| 能不能用 GitHub 账号注册 | 第三方登录 |
| 邮箱注册太麻烦 | 第三方登录 |
| 团队成员希望用 OAuth | 第三方登录 |
如果只靠关键词匹配,很容易漏掉语义相近但表达不同的反馈。更合理的方式是为反馈标题和正文生成 embedding,再用向量检索召回相似反馈。
公开 README 中提到,该开源实现使用 PostgreSQL 17+ 与 pgvector 支撑相似反馈检测。这类设计的好处是,核心业务数据和向量索引可以放在同一套数据库体系里,降低额外引入向量数据库的复杂度。
一个语义去重流程可以这样设计:
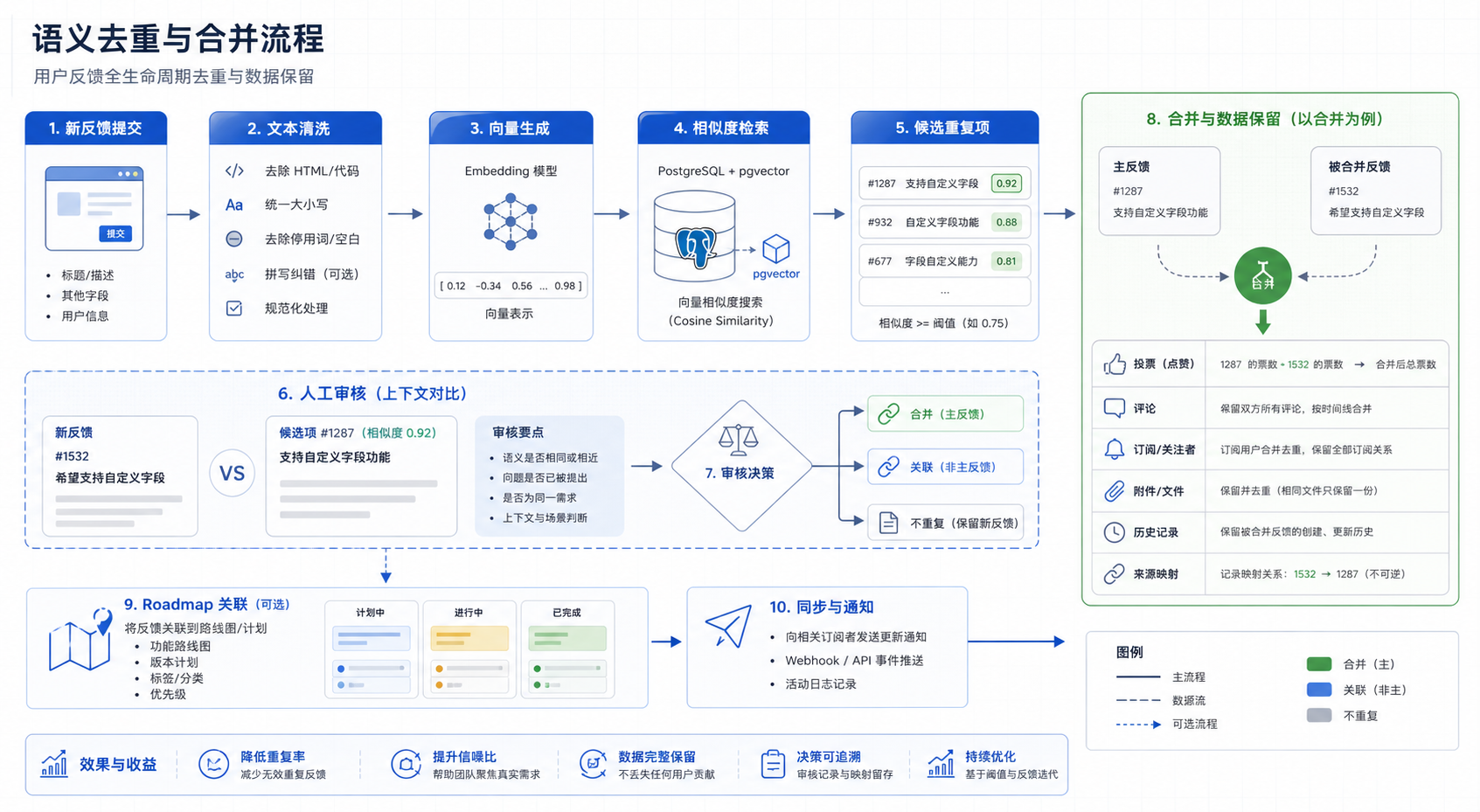
这里有一个重要原则:AI 更适合做候选召回,不适合直接做最终裁决。
原因很简单,语义相似不等于产品需求相同。“支持 GitHub 登录”和“支持企业 SSO”都属于认证能力,但实现成本、目标用户和产品优先级可能完全不同。如果自动合并,反而会污染需求判断。
示例口径:不同去重策略对比
以下为模拟数据,仅用于说明评估口径,不代表任何项目真实指标。
| 去重策略 | 重复召回率 | 误合并风险 | 人工成本 | 建议 |
|---|---|---|---|---|
| 人工浏览 | 低 | 低 | 高 | 适合早期低量反馈 |
| 关键词匹配 | 中 | 中 | 中 | 适合标题规范的场景 |
| 向量召回 + 人工确认 | 高 | 低 | 中低 | 适合增长阶段 |
| 全自动合并 | 高 | 高 | 低 | 不建议直接用于生产 |
对反馈系统来说,误合并通常比漏合并更危险。漏合并只是多几条重复反馈,误合并会把不同需求混在一起,影响产品方向判断。
八、Roadmap:不是承诺清单,而是预期管理
Roadmap 的作用不是把内部计划全部公开,也不是向用户承诺所有需求都会做。它更像是一个预期管理工具:告诉用户团队正在关注什么、计划做什么、哪些已经在推进。
Roadmap Item 通常不是单条反馈,而是多个反馈合并后的产品事项。
| Roadmap 阶段 | 含义 | 用户侧价值 |
|---|---|---|
| considering | 正在评估 | 知道团队已看到 |
| planned | 已进入计划 | 知道方向被采纳 |
| in_progress | 正在开发 | 知道有实际推进 |
| shipped | 已发布 | 可查看更新说明 |
Roadmap 最容易出问题的地方,是公开后长期不维护。一个长期停滞的 Roadmap 会让用户觉得产品没有进展,甚至比没有 Roadmap 更糟。
因此,Roadmap 应该从数据层和状态机联动,而不是靠人工维护静态页面。反馈状态进入 planned 或 in_progress 后,可以同步进入 Roadmap;功能上线后,再进入 Changelog。
九、Changelog:把“我们做了什么”翻译成“用户得到了什么”
很多团队持续发布功能,但用户没有感知。原因不是团队没有更新,而是更新没有被结构化表达。
Changelog 的价值在于把产品变化变成可订阅、可回溯、可传播的信息。它不应该只是内部提交记录,而应该回答用户关心的问题:这次更新解决了什么?谁会受益?是否和我之前提过的问题有关?
一个 Changelog 条目可以包含:
| 字段 | 说明 |
|---|---|
| title | 发布标题 |
| type | feature / improvement / bugfix |
| summary | 面向用户的摘要 |
| related_feedback_ids | 关联反馈 |
| release_date | 发布时间 |
| author | 发布人 |
| visibility | 公开或内部 |
| notification_status | 是否已通知相关用户 |
如果 Changelog 能关联反馈,就可以形成真正的闭环:用户投票或评论过某个反馈,功能上线后,系统可以通知这些用户。这比单纯发一篇更新日志更有效,因为它回应的是用户曾经表达过的具体诉求。
AI-assisted changelog drafting 适合在这里发挥作用:基于已完成事项、关联反馈和变更摘要生成草稿。但最终发布内容仍应人工确认,避免把内部描述、未确认承诺或过度营销语句直接发布出去。
十、从数据关系看反馈闭环
如果把系统抽象成数据关系,反馈闭环大致是这样:
这里有几条关系特别重要:
- Feedback 与 Vote/Comment 的关系,决定用户参与度。
- Feedback 与 Merge Relation 的关系,决定重复反馈是否能收敛。
- Feedback 与 Roadmap Item 的关系,决定用户声音是否进入计划。
- Roadmap Item 与 Changelog Entry 的关系,决定产品变化是否能回溯。
- Changelog Entry 与 Notification 的关系,决定用户是否感知到团队行动。
这也是为什么反馈系统不能只建一张 feedback 表。没有这些关系,就无法形成闭环。
十一、开源自托管:反馈数据为什么值得自己掌握
反馈数据包含大量产品方向、用户诉求、客户分层和潜在商业信息。对于独立开发者、小型 SaaS 团队和开源项目来说,是否把这些数据完全托管在第三方平台,需要谨慎评估。
开源自托管的价值主要体现在:
| 维度 | 自托管价值 |
|---|---|
| 数据主权 | 反馈、投票、评论和用户关系在自己的数据库中 |
| 可迁移性 | 不被闭源平台的数据结构锁死 |
| 可扩展性 | 可以按团队流程调整字段、权限和集成 |
| 成本可控 | 用户增长后不一定按席位或反馈量线性付费 |
| 私有化需求 | 可以部署在 VPS、NAS、内网或企业环境 |
当然,自托管并不意味着没有成本。团队需要负责部署、升级、备份、安全配置和监控。因此,一个好的开源反馈系统应该尽量降低部署门槛,同时保留足够的可配置能力。
十二、技术栈拆解:为什么选 Nuxt + PostgreSQL + pgvector
以 feedlog ai 的公开 README 和仓库配置为例,该项目采用 Nuxt 4、TypeScript、Drizzle ORM、PostgreSQL 17+ with pgvector、Tailwind CSS v4、shadcn-vue、better-auth 等技术栈,并支持 Cloudflare Workers、Vercel 和 Docker 部署。
从架构角度看,这套技术栈的组合比较清晰:
| 层级 | 技术选择 | 作用 |
|---|---|---|
| 应用框架 | Nuxt 4 / Vue 3 / Nitro | 页面、API、服务端渲染 |
| 类型系统 | TypeScript | 降低字段变更风险 |
| 数据库 | PostgreSQL 17+ | 存储核心业务数据 |
| 向量能力 | pgvector | 支持相似反馈检测 |
| ORM | Drizzle ORM | 管理 schema 和类型安全查询 |
| 认证 | better-auth | 邮箱、OAuth、管理员角色 |
| UI | Tailwind CSS / shadcn-vue | 管理后台和公开页面 |
| 对象存储 | R2 / Vercel Blob / S3-compatible | 附件和静态资源存储 |
| AI 接口 | OpenAI-compatible API | embedding、相似检测、发布说明草稿 |
这套架构有一个特点:AI 是增强能力,不是系统唯一核心。即使关闭 AI,相似检测和 changelog 草稿不可用,反馈收集、Roadmap、Changelog 仍然可以作为基础功能运转。
这点很重要。产品系统不应该把核心链路完全建立在 AI 可用性之上。AI 更适合作为提效层,而不是单点依赖。
从工程细节看,这类项目还有几个值得关注的设计:
| 细节 | 工程含义 |
|---|---|
| Drizzle migration | 数据库 schema 变更可版本化,便于自托管升级 |
| Nuxt layer 配置 | 让应用既可独立运行,也有机会作为 Nuxt layer 被复用 |
| S3-compatible blob module | Docker / Node 环境可在运行时接入 AWS S3、R2、MinIO、OSS 等存储 |
| Cloudflare setup module | 首次部署时可辅助完成数据库初始化流程 |
| OAuth 可选配置 | Google / GitHub 登录按需启用,不强制依赖第三方登录 |
| AI 可选配置 | 未配置 OpenAI-compatible API 时,AI 功能可关闭,核心功能仍可运行 |
十三、部署方式:Cloudflare Workers、Vercel、Docker 的取舍
不同团队对部署的诉求不同。有人希望快速上线,有人希望完全控制,有人希望部署到自己的服务器或内网。
| 部署方式 | 优点 | 代价 | 适合场景 |
|---|---|---|---|
| Cloudflare Workers | 边缘部署,适合搭配 R2 | 需要理解 Workers、Hyperdrive 等平台概念 | 熟悉 Cloudflare 生态 |
| Vercel | 上线快,前端团队熟悉 | 数据库和存储通常依赖外部服务 | 快速验证和小团队 |
| Docker | 控制权高,可私有部署 | 运维责任更重 | VPS、NAS、内网、私有化 |
无论选择哪种方式,底层都需要支持 pgvector 的 PostgreSQL 17+。如果团队计划使用相似反馈检测,数据库扩展和索引策略就会影响实际体验。
从仓库的 Docker Compose 配置看,私有化部署的基础形态可以概括为“两件套”:应用容器 + pgvector-enabled PostgreSQL。应用侧需要配置数据库连接、认证密钥和管理员邮箱;如果不配置 S3 兼容存储,上传内容可以先落到本地文件系统,但生产环境通常需要挂载持久化卷或接入对象存储。
| 配置项 | 作用 | 备注 |
|---|---|---|
| DATABASE_URL | PostgreSQL 连接字符串 | 数据库需启用 vector 扩展 |
| BETTER_AUTH_SECRET | Session / Cookie 加密密钥 | 应使用随机强密钥 |
| SYSTEM_ADMIN_EMAILS | 首批管理员邮箱 | 必须在首次注册前配置 |
| S3_* | 对象存储配置 | Docker / Node 部署时按需启用 |
| OPENAI_* | AI 能力配置 | 未配置时 AI 功能可关闭 |
| RESEND_API_KEY | 事务邮件配置 | 用于密码重置、通知等邮件场景 |
十四、权限、安全和数据边界
反馈平台虽然偏产品侧,但安全设计不能忽略。它涉及用户账号、内部计划、客户反馈、附件和潜在敏感内容。
至少需要关注这些边界:
| 安全点 | 设计建议 |
|---|---|
| 管理员初始化 | 首个管理员通过环境变量或安装流程指定 |
| OAuth 回调 | 生产环境配置稳定公开 URL |
| 私有 Board | 查询接口必须校验成员权限 |
| 附件访问 | 避免永久公开 URL,必要时签名访问 |
| 日志脱敏 | 避免记录完整敏感反馈 |
| AI 输入 | 发送到外部模型前明确数据边界 |
| 数据导出 | 支持团队迁移和备份 |
特别是 AI 相关能力。相似反馈检测和发布说明草稿可能需要把反馈文本发送到模型接口。对于敏感行业或企业客户,应允许团队关闭 AI,或者只对指定 Board 启用 AI。
十五、上线后应该看哪些指标
反馈平台的价值应该可衡量,否则很容易变成“大家感觉更重视用户了”。
可以关注这些指标:
| 指标 | 含义 |
|---|---|
| new_feedback_count | 新增反馈数量 |
| duplicate_candidate_count | 相似候选数量 |
| merge_rate | 合并率 |
| time_to_first_response | 首次响应时间 |
| time_to_triage | 进入评估平均时间 |
| roadmap_conversion_rate | 反馈进入 Roadmap 比例 |
| changelog_link_rate | 发布记录关联反馈比例 |
| notification_success_rate | 通知成功率 |
以下为模拟数据,仅用于说明统计方式,不代表任何项目真实表现。
| 指标 | 只用表格整理 | 使用闭环系统 |
|---|---|---|
| 重复反馈识别率 | 45% | 82% |
| 平均首次响应时间 | 72 小时 | 18 小时 |
| 反馈进入 Roadmap 可追踪比例 | 20% | 68% |
| 发布后通知相关用户比例 | 5% | 76% |
| 用户重复追问比例 | 31% | 12% |
这里的重点不是证明某个工具一定更好,而是说明反馈系统应有可衡量目标。没有指标,团队很难判断“反馈闭环”是否真的发生了。
十六、从旧系统迁移:不要试图一次性搬完
很多团队已经有历史反馈:Notion、表格、GitHub Issue、邮件、客服记录。迁移时不要试图一次性搬完所有内容。
更稳妥的迁移方式是分阶段:
| 阶段 | 目标 | 操作 |
|---|---|---|
| 第一阶段 | 建立新入口 | 新反馈统一进入系统 |
| 第二阶段 | 迁移高价值历史反馈 | 只导入仍有决策价值的内容 |
| 第三阶段 | 合并重复项 | 用相似检测辅助人工整理 |
| 第四阶段 | 建立 Roadmap | 把已确认方向公开展示 |
| 第五阶段 | 补 Changelog | 从最近几个版本开始整理 |
历史数据不必全部迁移。很多旧反馈已经过期,强行导入只会增加噪声。迁移的目标不是复原所有聊天记录,而是建立未来稳定的反馈闭环。
十七、常见反模式
17.1 把反馈系统当成客服工单
客服工单关注单个用户的问题解决,反馈系统关注多个用户诉求背后的产品方向。二者可以关联,但不应该混为一谈。
17.2 Roadmap 公开后长期不维护
Roadmap 一旦公开,就会成为用户预期的一部分。长期不更新会让用户觉得产品停滞。
17.3 只按票数排序
票数是重要信号,但不是唯一信号。用户类型、业务价值、实现成本、产品方向都要参与判断。
17.4 AI 自动合并所有相似反馈
AI 召回候选很有价值,但最终合并最好保留人工确认。误合并会污染产品判断。
17.5 Changelog 写成内部开发日志
用户关心的是变化对自己有什么影响,而不是内部代码重构了多少。更新日志应该面向用户价值,而不是只记录开发动作。
结语
一个反馈系统是否有价值,不取决于它能不能让用户提交内容,而取决于它能不能帮助团队完成闭环:听见用户、整理需求、公开进展、发布变化、再把结果反馈给用户。
从工程角度看,这类系统的关键不是单个页面,而是数据关系和状态流转。Feedback、Roadmap、Changelog、Vote、Comment、Merge Relation、Notification 这些对象连接起来,才构成真正的用户反馈闭环。
如果团队希望在保留数据控制权的前提下建设这类系统,可以参考 feedlog 这类开源实现的思路:用现代 Web 技术栈承载产品体验,用 PostgreSQL 和 pgvector 支撑结构化数据与语义检索,用 Roadmap 和 Changelog 把用户反馈接入产品迭代过程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)