让AI懂科研:MedPeer如何用“真实数据”治愈大模型幻觉?
随着 AI 深度融入科研场景,越来越多科研工作者摆脱了工具零散的困扰,迈入智能协作新阶段。但大语言模型普遍存在的 “幻觉问题”,成为AI落地生物医学等严谨领域的最大阻碍。依托百万级用户沉淀,MedPeer 不止是整合各类功能的工具平台,更逐步成长为行业通用的科研协作基础设施,而其探索出的 “数据驱动 AI” 模式,也为垂直领域破解模型幻觉提供了可行路径。

一、痛点凸显:通用大模型为何难适配严谨科研?
传统科研本就受限于工具割裂、数据孤岛等问题,当通用大模型入局后,新的短板随之暴露。对于讲求严谨、实证、有据可查的学术研究而言,通用 LLM 存在三大硬伤:
首先是知识更新滞后,模型训练数据存在时间壁垒,无法同步全球最新期刊成果与前沿研究;其次是事实性幻觉,模型依靠概率生成内容,时常编造虚假文献、作者信息、实验数据与 DOI 编号;最后是内容缺乏学术规范,输出观点难以溯源,研究人员人工核查的成本居高不下。
学术领域,准确性永远优先于表达流畅度。想要解决这一行业难题,单纯堆砌模型参数并无意义,搭建 “权威外部知识库 + 动态检索联动” 的技术架构,才是破局关键。
二、核心解法:搭建权威知识库,让 AI “言之有据”
MedPeer 的核心思路十分明确:拒绝 AI 自由生成内容,所有输出均建立在真实、可溯源的科研数据之上。平台通过搭建体量庞大、经过严格清洗的权威文献库,为 AI 筑牢知识底座。

平台整合超 3 亿篇全球中英文科技文献,对接国际主流医学数据库与国内核心期刊,覆盖细分研究领域,科研人员无需跨站检索,一站式获取全面研究资料,从源头打破信息孤岛。
在此基础上,平台对海量文献做结构化处理,将非结构化文档转化为机器可识别的知识体系。系统能够理解专业术语的关联逻辑,实现语义级精准匹配;同时支持按发表年份、期刊等级、研究类型等多维度筛选,进一步提升内容匹配精度。
依托这套体系,AI 写作助手还可结合行文逻辑,智能推荐、插入参考文献,自动规范引文格式,省去人工复制、排版的繁琐操作,在提升效率的同时,大幅降低人为失误概率。
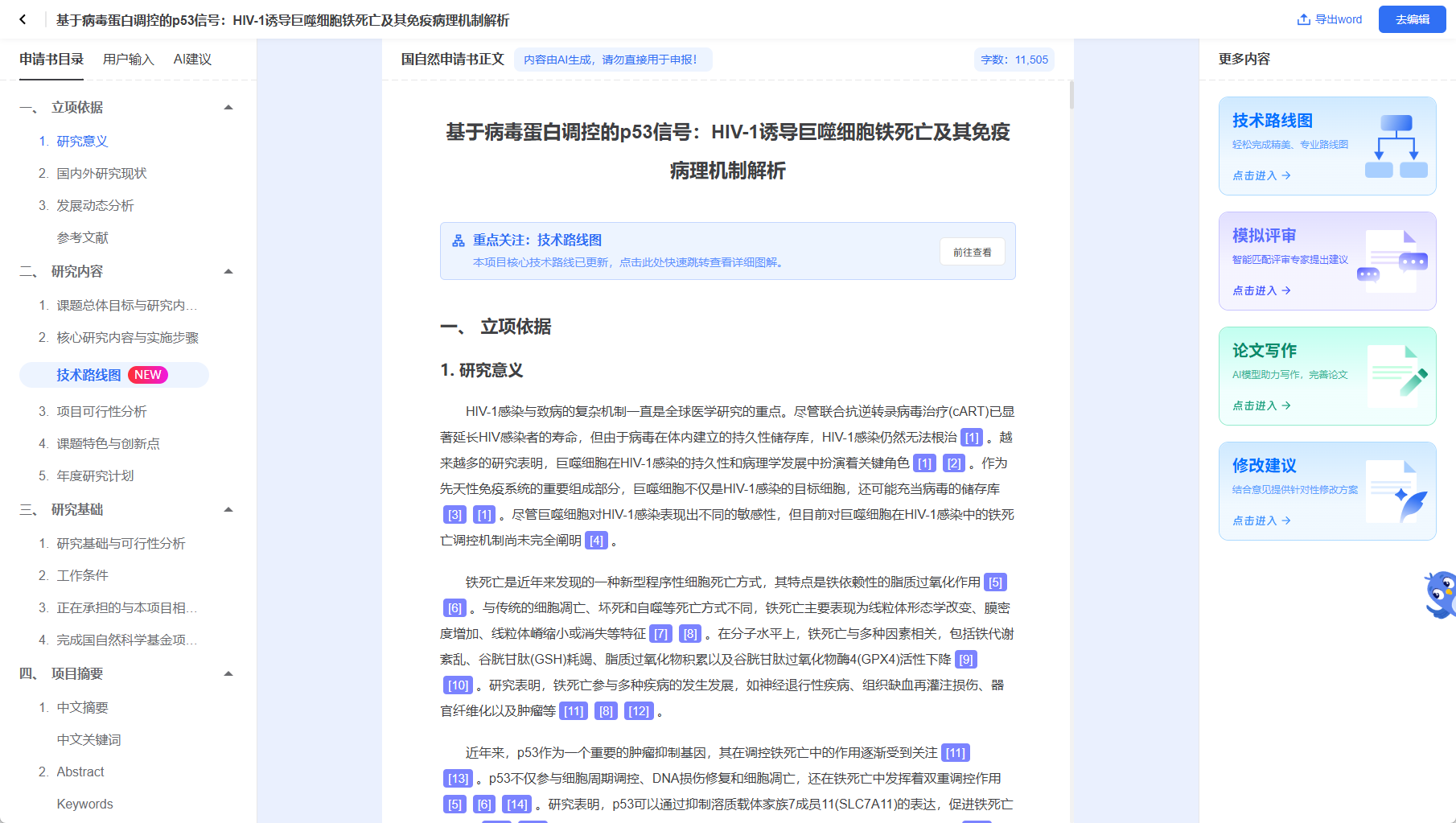
三、体验升级:全链路可溯源,构建信任体系
解决幻觉问题,不仅要在底层数据发力,更要在产品交互上做到 “全程可验证”,让科研人员放心使用。
平台打造了全链路溯源机制:AI 生成内容中的每一处论点、数据,均标注对应引用来源。用户点击引用标记,即可快速查看原始文献段落、摘要及全文链接,实现内容一键核验,真正做到 “所见即可查”。

同时系统设置严格的生成约束:AI 仅基于检索到的权威资料进行总结改写,不脱离原始素材自由创作;若现有文献不足以支撑观点,平台会主动提示补充资料,而非强行拼凑模糊内容,从机制上杜绝 “编造内容” 的情况。
四、价值落地:效率与合规双向提升
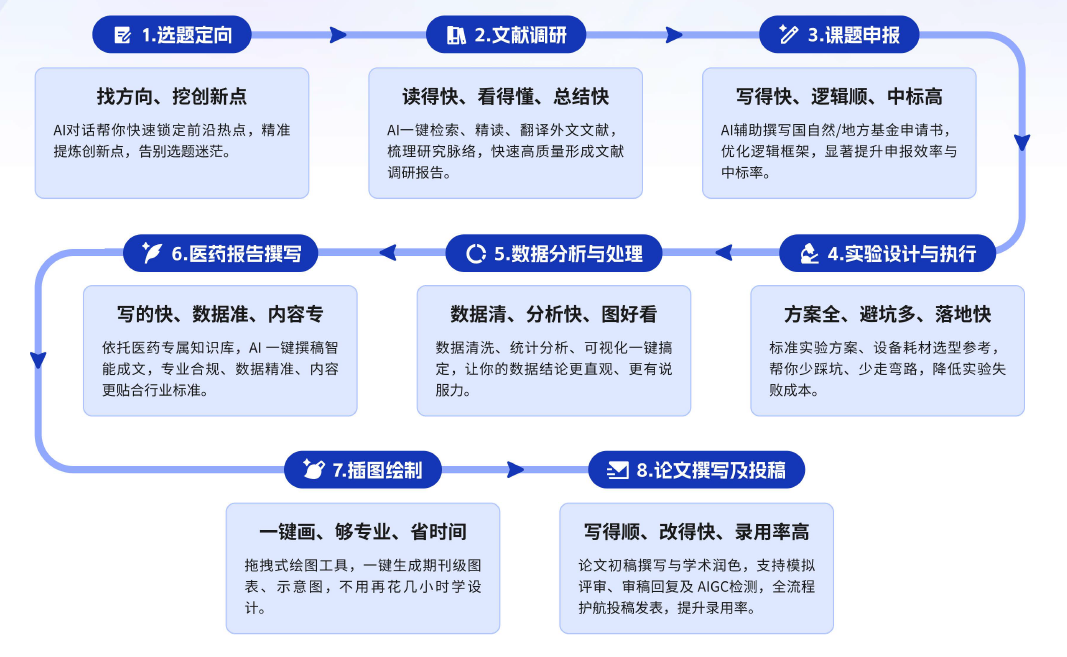
真实应用场景中,这套 “数据 + AI” 的组合模式,实现了科研质量与工作效率的双重提升。目前平台引文准确率接近 100%,远高于通用大模型 65% 左右的内容可用率,彻底规避虚假引用带来的学术风险;从选题、文献梳理到初稿完成,整体写作周期缩短 40%,帮助科研人员把精力聚焦在实验探索与原始创新上。
在安全合规层面,平台拥有网络安全等级保护三级认证,数据全程在加密环境中流转处理,充分满足高校、三甲医院、生物医药企业对数据隐私、知识产权保护的严苛要求。

如今百万用户的选择,印证了科研行业正从零散工具模式,全面转向一体化智能基础设施。MedPeer 的实践也证明:垂直领域的 AI 竞争力,从来不在于模型规模大小,而在于能否对接权威数据、输出可信服务。
面向未来,平台将持续深化 “数据 + AI” 双轮驱动,打破语言、资源与效率的多重瓶颈,让 AI 真正服务于严谨的科研探索,助力行业创新稳步前行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)