山东大学创新实训9——从 SQLite 到 PostgreSQL
一、现存问题
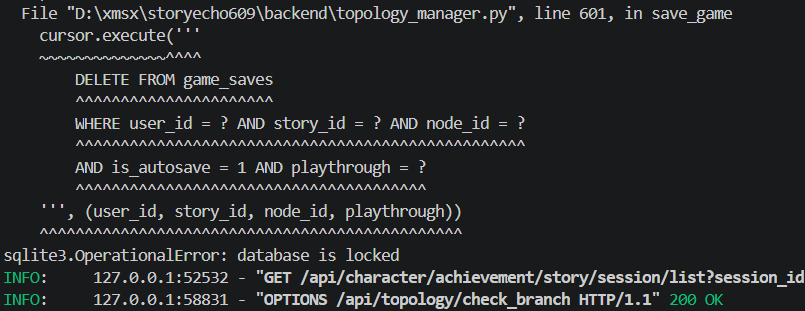
StoryEcho 是一个 AI 驱动的文字冒险游戏后端,最初使用 SQLite 作为数据库。随着请求增长,系统开始频繁出现数据库锁定错误(sqlite3.OperationalError: database is locked)。分析发现,SQLite 在写入时会锁定整个数据库文件,当多个请求同时执行 `update_character_session` 和 `record_item_discovery` 操作时就会产生冲突,而默认等待时间较短,高并发下很容易超时。因此,我们决定将数据库从 SQLite 迁移到 PostgreSQL。
二、技术选型
我和ai进行了交互,看什么数据库更加合适:


选择 PostgreSQL 主要基于三点考虑:PostgreSQL 采用 MVCC(多版本并发控制)机制,读写互不阻塞,能够支持数千并发连接;原生支持 JSONB 类型,可以高效存储游戏中的动态属性数据;同时具备完整的事务隔离级别,确保数据一致性。相比之下,SQLite 的写锁机制在高并发场景下成为明显瓶颈。
三、架构设计
迁移策略采用统一数据库接口层设计。应用层(FastAPI)通过 `get_db_connection()` 函数获取数据库连接,该函数根据环境变量 `USE_POSTGRES` 自动选择使用 PostgreSQL 的 asyncpg 连接池或 SQLite 连接。这样既能在生产环境使用 PostgreSQL 处理高并发,又能保留 SQLite 用于开发测试。
配置管理方面,新增了 `db_config.py` 文件统一管理 PostgreSQL 连接参数,包括主机、端口、数据库名、用户名和密码,所有这些配置都通过环境变量读取,确保敏感信息不入库。
我根据了下面这个博客进行了安装和配置环境:
postgreSQL安装教程及使用方法(保姆级)-CSDN博客
在cmd中创建数据库:
psql -U postgres -h localhost -c "CREATE DATABASE storyecho;"
psql -U postgres -h localhost -c "CREATE USER storyecho_user WITH PASSWORD 'your_password_here';"
psql -U postgres -h localhost -c "GRANT ALL PRIVILEGES ON DATABASE storyecho TO storyecho_user;"在.env文件中进行配置:
# 数据库配置
USE_POSTGRES=true
DB_HOST=localhost
DB_PORT=5432
DB_NAME=storyecho
DB_USER=storyecho_user
DB_PASSWORD=your_password_here
#使用 SQLite:.env 中设置 USE_POSTGRES=false
#使用 PostgreSQL:.env 中设置 USE_POSTGRES=true四、核心代码修改
数据库连接池的初始化是关键改造。在 `database.py` 中,我们实现了异步连接池:`init_db_pool()` 函数创建 asyncpg 连接池,设置最小 5 个、最大 20 个连接,并配置了 60 秒命令超时。
async def init_db_pool():
"""初始化数据库连接池"""
global _pool, _pool_initialized
if _pool_initialized and _pool is not None and not _pool._closed:
return _pool
if USE_POSTGRES:
# 关闭旧连接池
if _pool is not None and not _pool._closed:
await _pool.close()
_pool = await asyncpg.create_pool(
host=POSTGRES_CONFIG['host'],
port=POSTGRES_CONFIG['port'],
database=POSTGRES_CONFIG['database'],
user=POSTGRES_CONFIG['user'],
password=POSTGRES_CONFIG['password'],
min_size=5,
max_size=20,
command_timeout=60,
max_queries=50000,
max_inactive_connection_lifetime=300
)
_pool_initialized = True
print(f"[DB] PostgreSQL 连接池已创建 -> {POSTGRES_CONFIG['database']}")
else:
# SQLite 模式(备用)
print(f"[DB] 使用 SQLite 模式")
_pool_initialized = True
return _pool`get_db_connection()` 返回连接池对象供各处使用,应用关闭时通过 `close_db_pool()` 释放资源。连接池机制有效解决了 SQLite 时代每次请求都打开关闭数据库连接的性能开销。
表结构定义也进行了适配。由于 asyncpg 不支持 `INSERT OR IGNORE` 语法,全部改为标准的 `INSERT ... ON CONFLICT ... DO NOTHING/UPDATE` 模式。JSON 字段从 SQLite 的 TEXT 类型改为 PostgreSQL 原生的 JSONB 类型,支持更高效的查询和索引。我们创建了专门的 `database_pg.py` 来集中管理所有表的 DDL 语句,包括用户表、角色表、会话表、存档表、成就表、拓扑节点表等二十余张表。
# backend/database_pg.py
# -*- coding: utf-8 -*-
import asyncpg
import json
from typing import Dict, List, Optional, Any
from datetime import datetime
from .db_config import POSTGRES_CONFIG, DATABASE_URL
class PostgresDatabase:
def __init__(self):
self.pool = None
async def connect(self):
"""创建连接池"""
self.pool = await asyncpg.create_pool(
host=POSTGRES_CONFIG['host'],
port=POSTGRES_CONFIG['port'],
database=POSTGRES_CONFIG['database'],
user=POSTGRES_CONFIG['user'],
password=POSTGRES_CONFIG['password'],
min_size=5,
max_size=20,
command_timeout=60
)
await self._init_tables()
print(f"[DB] PostgreSQL 连接池已创建 -> {POSTGRES_CONFIG['database']}")
async def _init_tables(self):
"""创建所有表"""
queries = [
# 用户表
"""
CREATE TABLE IF NOT EXISTS users (
user_id TEXT PRIMARY KEY,
email TEXT UNIQUE,
username TEXT UNIQUE,
password TEXT,
verify_code TEXT,
is_verified INTEGER DEFAULT 0,
created_at TIMESTAMP
)
""",
# 故事表
"""
CREATE TABLE IF NOT EXISTS stories (
story_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
icon TEXT,
genre TEXT,
difficulty TEXT,
background TEXT,
description TEXT,
created_at TIMESTAMP
)
""",
# 角色表
"""
CREATE TABLE IF NOT EXISTS characters (
character_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
story_id TEXT NOT NULL,
name TEXT NOT NULL,
gender TEXT,
personality INTEGER DEFAULT 50,
base_attributes JSONB,
initial_inventory_json JSONB,
selected_talent_id TEXT,
selected_background_id TEXT,
ngp_level INTEGER DEFAULT 0,
created_at TIMESTAMP,
updated_at TIMESTAMP
)
""",
# 角色会话表
"""
CREATE TABLE IF NOT EXISTS character_sessions (
session_id TEXT PRIMARY KEY,
character_id TEXT NOT NULL,
user_id TEXT NOT NULL,
story_id TEXT NOT NULL,
current_attributes JSONB,
inventory_json JSONB,
relationships_json JSONB,
task_progress_json JSONB,
session_start_at TIMESTAMP,
last_updated_at TIMESTAMP,
status TEXT DEFAULT 'ongoing'
)
""",
# 存档表
"""
CREATE TABLE IF NOT EXISTS game_saves (
save_id TEXT PRIMARY KEY,
user_id TEXT,
story_id TEXT,
node_id TEXT,
game_state JSONB,
created_at TIMESTAMP,
playthrough INTEGER,
is_autosave BOOLEAN DEFAULT FALSE,
save_name TEXT,
last_loaded TIMESTAMP
)
""",
# 故事成就表 - 添加 category 字段
"""
CREATE TABLE IF NOT EXISTS story_achievements (
story_achievement_id TEXT PRIMARY KEY,
story_id TEXT NOT NULL,
name TEXT NOT NULL,
description TEXT,
icon TEXT,
category TEXT,
condition_json JSONB,
sort_order INTEGER DEFAULT 0
)
""",
# 用户成就表
"""
CREATE TABLE IF NOT EXISTS user_story_achievements (
user_story_achievement_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
story_id TEXT NOT NULL,
story_achievement_id TEXT NOT NULL,
character_id TEXT,
unlocked_at TIMESTAMP
)
""",
# 成就表(通用)
"""
CREATE TABLE IF NOT EXISTS achievements (
achievement_id TEXT PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
category TEXT,
unlock_condition TEXT
)
""",
# 用户成就表(通用)
"""
CREATE TABLE IF NOT EXISTS user_achievements (
user_achievement_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
achievement_id TEXT NOT NULL,
unlocked_at TIMESTAMP
)
""",
# ============ 拓扑相关表 ============
# 拓扑节点表(模板)
"""
CREATE TABLE IF NOT EXISTS topology_nodes (
id TEXT,
story_id TEXT,
name TEXT,
type TEXT,
description TEXT,
x REAL,
y REAL,
conditions JSONB,
connected_to JSONB,
icon TEXT,
PRIMARY KEY (id, story_id)
)
""",
# 用户解锁节点表
"""
CREATE TABLE IF NOT EXISTS user_unlocked_nodes (
id SERIAL PRIMARY KEY,
user_id TEXT NOT NULL,
story_id TEXT NOT NULL,
node_id TEXT NOT NULL,
unlocked_at TIMESTAMP,
playthrough INTEGER,
UNIQUE(user_id, story_id, node_id, playthrough)
)
""",
# 探索路径表
"""
CREATE TABLE IF NOT EXISTS exploration_path (
id SERIAL PRIMARY KEY,
user_id TEXT,
story_id TEXT,
from_node TEXT,
to_node TEXT,
visited_at TIMESTAMP,
playthrough INTEGER,
discovery_type TEXT
)
""",
# 节点发现物表
"""
CREATE TABLE IF NOT EXISTS node_discoveries (
id SERIAL PRIMARY KEY,
user_id TEXT,
story_id TEXT,
node_id TEXT,
playthrough INTEGER,
discovery_type TEXT,
discovery_id TEXT,
discovery_name TEXT,
description TEXT,
icon TEXT,
discovered_at TIMESTAMP
)
""",
# 天赋表
"""
CREATE TABLE IF NOT EXISTS talents (
talent_id TEXT PRIMARY KEY,
story_id TEXT,
name TEXT,
description TEXT,
effects JSONB,
rarity TEXT,
unlock_condition TEXT
)
""",
# 出身表
"""
CREATE TABLE IF NOT EXISTS backgrounds (
background_id TEXT PRIMARY KEY,
story_id TEXT,
name TEXT,
description TEXT,
initial_items JSONB,
attribute_bonus JSONB,
starting_skills JSONB,
unlock_condition TEXT
)
""",
# 角色物品表
"""
CREATE TABLE IF NOT EXISTS character_inventory (
inventory_id TEXT PRIMARY KEY,
character_id TEXT,
story_id TEXT,
item_name TEXT,
quantity INTEGER,
source_event_id TEXT,
reason TEXT,
created_at TIMESTAMP,
updated_at TIMESTAMP
)
""",
# 会话物品表
"""
CREATE TABLE IF NOT EXISTS session_inventory (
session_inventory_id TEXT PRIMARY KEY,
session_id TEXT,
item_id TEXT,
quantity INTEGER,
meta_json JSONB
)
""",
# 故事物品表
"""
CREATE TABLE IF NOT EXISTS story_items (
item_id TEXT PRIMARY KEY,
story_id TEXT,
name TEXT,
category TEXT,
description TEXT,
effects JSONB,
source_type TEXT,
is_allowed INTEGER DEFAULT 1
)
""",
# 商人物品表
"""
CREATE TABLE IF NOT EXISTS vendor_items (
vendor_item_id TEXT PRIMARY KEY,
vendor_id TEXT,
item_id TEXT,
price INTEGER,
stock INTEGER
)
""",
# 角色武器表
"""
CREATE TABLE IF NOT EXISTS character_weapons (
character_weapon_id TEXT PRIMARY KEY,
character_id TEXT,
story_id TEXT,
weapon_id TEXT,
weapon_name TEXT,
acquired_at TIMESTAMP,
is_equipped INTEGER DEFAULT 0
)
""",
# 故事战斗会话表
"""
CREATE TABLE IF NOT EXISTS story_combat_sessions (
story_session_id TEXT PRIMARY KEY,
character_session_id TEXT,
character_id TEXT,
user_id TEXT,
story_id TEXT,
enemy_name TEXT,
combat_difficulty TEXT,
enemy_hp INTEGER,
enemy_hp_max INTEGER,
enemy_attack INTEGER,
combat_triggered INTEGER DEFAULT 0,
combat_outcome TEXT,
encounter_scene TEXT,
metadata_json JSONB,
created_at TIMESTAMP,
updated_at TIMESTAMP
)
""",
# 事件日志表
"""
CREATE TABLE IF NOT EXISTS event_log (
event_id TEXT PRIMARY KEY,
character_id TEXT,
user_id TEXT,
deltas_json JSONB,
reason TEXT,
source TEXT,
created_at TIMESTAMP
)
""",
# NGP记录表
"""
CREATE TABLE IF NOT EXISTS ngp_records (
ngp_id TEXT PRIMARY KEY,
character_id TEXT,
previous_ngp_level INTEGER,
inherited_talents JSONB,
inherited_bonuses JSONB,
created_at TIMESTAMP
)
""",
# 记忆文档表(RAG)
"""
CREATE TABLE IF NOT EXISTS memory_documents (
doc_id TEXT PRIMARY KEY,
collection TEXT,
text TEXT,
metadata_json TEXT,
created_at TEXT
)
""",
# 会话摘要表
"""
CREATE TABLE IF NOT EXISTS session_summaries (
id SERIAL PRIMARY KEY,
session_id TEXT,
turn INTEGER,
summary TEXT,
context_json TEXT,
created_at TEXT
)
""",
# 故事敌人表
"""
CREATE TABLE IF NOT EXISTS story_enemies (
enemy_id TEXT PRIMARY KEY,
story_id TEXT,
name TEXT,
category TEXT,
tier TEXT,
base_hp INTEGER,
base_attack INTEGER,
default_difficulty TEXT,
aliases_json JSONB,
nodes_json JSONB,
min_turn INTEGER,
encounter_text TEXT,
loot_json JSONB,
attr_rewards_json JSONB,
money_min INTEGER,
money_max INTEGER,
is_allowed INTEGER DEFAULT 1
)
""",
]
# 创建索引
index_queries = [
"CREATE INDEX IF NOT EXISTS idx_saves_user_story ON game_saves(user_id, story_id, playthrough)",
"CREATE INDEX IF NOT EXISTS idx_unlocked_nodes ON user_unlocked_nodes(user_id, story_id, playthrough)",
"CREATE INDEX IF NOT EXISTS idx_exploration_path_user ON exploration_path(user_id, story_id, playthrough)",
"CREATE INDEX IF NOT EXISTS idx_node_discoveries_user ON node_discoveries(user_id, story_id, node_id, playthrough)",
"CREATE INDEX IF NOT EXISTS idx_character_inventory_char ON character_inventory(character_id)",
"CREATE INDEX IF NOT EXISTS idx_session_inventory_session ON session_inventory(session_id)",
"CREATE INDEX IF NOT EXISTS idx_character_weapons_char ON character_weapons(character_id, story_id)",
"CREATE INDEX IF NOT EXISTS idx_event_log_user ON event_log(user_id, created_at)",
"CREATE INDEX IF NOT EXISTS idx_memory_documents_collection ON memory_documents(collection)",
"CREATE INDEX IF NOT EXISTS idx_session_summaries_session ON session_summaries(session_id)",
"CREATE INDEX IF NOT EXISTS idx_story_combat_sessions ON story_combat_sessions(story_session_id)",
]
async with self.pool.acquire() as conn:
for query in queries:
try:
await conn.execute(query)
except Exception as e:
print(f"[DB] 创建表失败: {e}")
for idx_query in index_queries:
try:
await conn.execute(idx_query)
except Exception as e:
print(f"[DB] 创建索引失败: {e}")
print("[DB] 所有表创建/检查完成")
async def execute(self, query: str, *args):
"""执行单条语句"""
async with self.pool.acquire() as conn:
return await conn.execute(query, *args)
async def fetch(self, query: str, *args):
"""获取多条记录"""
async with self.pool.acquire() as conn:
return await conn.fetch(query, *args)
async def fetch_one(self, query: str, *args):
"""获取单条记录"""
async with self.pool.acquire() as conn:
return await conn.fetchrow(query, *args)
async def fetch_val(self, query: str, *args):
"""获取单个值"""
async with self.pool.acquire() as conn:
return await conn.fetchval(query, *args)
async def close(self):
if self.pool:
await self.pool.close()数据库维护模块 `db_maintenance.py` 从同步改为异步版本。所有数据库操作函数都添加了 `async/await` 关键字,使用 `async with conn.acquire()` 获取连接,确保连接正确释放。
五、兼容性处理
为了确保迁移平稳过渡,我们采取了双数据库兼容策略。所有数据库操作函数都通过 `USE_POSTGRES` 标志判断当前模式,在 PostgreSQL 模式下使用 asyncpg 的异步 API,在 SQLite 模式下回退到原有的 sqlite3 同步 API。这样开发环境可以继续使用 SQLite 快速迭代,生产环境使用 PostgreSQL 保障性能。
六、迁移过程
迁移分为三步:首先在 PostgreSQL 中创建数据库和用户,然后运行初始化脚本创建所有表结构,最后通过 `run_database_maintenance()` 函数将现有 SQLite 数据导出并导入到 PostgreSQL。采用了逐表导出导入方式,没有使用复杂的迁移工具。
async def run_database_maintenance():
"""运行数据库维护(PostgreSQL 版本)"""
if not USE_POSTGRES:
return
print("[DB] 开始 PostgreSQL 数据库维护...")
try:
chars = await migrate_character_inventory_names()
if chars:
print(f"[db] 已规范化 {chars} 个角色的 character_inventory")
catalog = await migrate_story_items_quantity_suffix()
if catalog:
print(f"[db] 已修正 {catalog} 条 story_items 目录命名")
await cleanup_story_data()
print("[DB] PostgreSQL 数据库维护完成")
except Exception as e:
print(f"[DB] 数据库维护失败: {e}")七、效果与总结
迁移完成后,数据库锁定错误彻底消失,并发写入能力大幅提升。asyncpg 连接池的复用机制减少了连接建立开销,JSONB 类型对游戏属性等动态数据的存取更加高效。这次迁移验证了一个重要经验:数据库选型需要与业务并发模型匹配,SQLite 适合单机低并发场景,而需要处理并发写入的网络服务则应该从一开始就考虑使用 PostgreSQL 这样的专业数据库。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)