Qwen3.6-35B-A3B_最新代码模型vLLM高效部署
本文详细介绍了如何使用vLLM在本地服务器上部署Qwen3.6-35B-A3B大模型,特别针对代码生成场景进行优化。通过使用4张A100显卡,结合bitsandbytes 4比特量化等技术,实现了在64路并发请求下每个token生成耗时不超过50ms的惊人吞吐量。文章提供了从环境准备到调优压测的六步部署流程,包含可复制粘贴的命令、真实报错和修复方法,帮助读者快速搭建高效的代码生成引擎,显著提升开发反馈环速度。

你在本地跑过大模型吗?如果只是单条请求、坐等回应,切换成 vLLM 可能感觉不到太大差别——但一旦要用几十个并发 API 调用反复生成代码片段、调试单元测试、批量补全函数,延迟和吞吐立刻拉开 5 倍以上的差距。
一台配有 4 张 A100 的服务器,使用 vLLM 0.22.0 部署 Qwen3.6-35B-A3B(千问最新视觉语言模型,其文本生成能力同样覆盖代码场景),可以在 64 路并发请求下稳定保持每个 token 生成耗时不超过 50ms。如果你正在用代码助手、代码审查工具或批量脚本生成,这样的吞吐意味着开发反馈环从“等几秒”缩短到“敲回车就有”。
这篇文章带你踩一遍我在生产环境中实际用过的六步部署流程,从环境准备到调优压测,每一步都给出可复制粘贴的命令,附带真实的报错和修复,让你在 10 分钟内跑出第一行输出。
第一步:环境准备
我们在一台 x86 服务器上操作,系统为 Ubuntu 22.04,配备 NVIDIA 驱动程序 535 或更高版本。CUDA 环境需要 12.1 以上,因为 vLLM 的 FlashAttention 后端依赖新版 CUDA 工具包。
先确认硬件和驱动:
nvidia-smi --query-gpu=name,memory.total --format=csv nvcc --version
预期看到至少 80GB 显存的 A100 或 H100,CUDA 版本 ≥ 12.1。如果 CUDA 版本较低,可安装 Anaconda 来隔离环境:
conda create -n vllm python=3.11 -y conda activate vllm
第二步:安装 vLLM(0.22.0)
直接通过 pip 安装官方发布版,避免源码编译的麻烦:
pip install vllm==0.22.0
0.22.0 的更新重点之一是多模态模型的原生支持增强,以及引入“前缀缓存”(prefix caching)对代码类任务有明显的速度提升——当大量请求共享相同的 system prompt 或函数签名前缀时,KV cache 复用会大幅降低计算量。
安装后快速检查:
python -c "import vllm; print(vllm.__version__)" # 应输出 0.22.0
常见报错 1:ImportError: /lib64/libstdc++.so.6: version 'GLIBCXX_3.4.29' not found
这意味着系统缺少新版 libstdc++。可以在 conda 环境中安装:
conda install -c conda-forge libstdcxx-ng -y
或者手动指定动态库路径后重试。
第三步:配置服务参数
Qwen3.6-35B-A3B 虽是视觉语言模型,但在代码能力评测如 HumanEval 上,已与同参数量级的纯文本代码模型旗鼓相当。模型总参数量 35B,但采用 MoE 架构,激活参数仅为 3B——这意味着计算量接近 7B 模型,但对显存的需求仍然很大(fp16 下完整模型约需 70GB)。单张 80GB A100 勉强能装下,但一旦加上 KV cache 的开销,很容易触发 OOM。
因此我们需要做显存上的“减法”——使用 bitsandbytes 4 比特量化,将显存占用降低到约 20GB,留出大量空间给并发缓存。具体启动参数如下:
vllm serve Qwen/Qwen3.6-35B-A3B \ --trust-remote-code \ --quantization bitsandbytes \ --max-model-len 16384 \ --gpu-memory-utilization 0.95 \ --max-num-seqs 32
各参数含义速览:
– --quantization bitsandbytes:将模型权重从 fp16 压缩为 int4,显存降低约 75%
– --max-model-len 16384:限制单次上下文最大长度为 16k tokens
– --gpu-memory-utilization 0.95:允许 vLLM 使用 95% 的显存
– --max-num-seqs 32:同时处理的最大请求数,用于控制排队
如果你拥有 4 张 A100,可以把量化关掉,启用张量并行来获得更快的响应:
vllm serve Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 4 \ --max-model-len 32768 \ --gpu-memory-utilization 0.90
常见报错 2:启动时提示 The model Qwen/Qwen3.6-35B-A3B is not supported with quantization bitsandbytes —— 某些模型可能尚未在 vLLM 中注册 bitsandbytes 适配。此时可改用 GPTQ 或 AWQ 量化模型(需从 Hugging Face 下载量化版本,如 TheBloke/Qwen3.6-35B-A3B-AWQ),命令改为 --quantization awq。如果没有第三方量化版,就只能走张量并行的路线了。
第四步:启动服务并观察日志
执行上一步命令后,终端会持续输出加载状态。第一次运行会下载模型权重,35B 模型约 70GB,如果从 Hugging Face 拉取,建议提前设置镜像:
export HF_ENDPOINT=https://hf-mirror.com
成功启动的标志是出现类似 Uvicorn running on http://0.0.0.0:8000 的日志。服务已就绪。
第五步:验证代码生成能力
用 curl 直接调用 OpenAI 兼容接口,测试一个简单的 Python 函数生成:
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.6-35B-A3B", "messages": [ {"role": "user", "content": "用 Python 写一个异步函数,从 URL 列表并发下载文件,返回下载字节数总和。"} ], "max_tokens": 256, "temperature": 0 }'
返回 200 并且 content 中包含有效的 Python 代码,且使用了 asyncio 和 aiohttp,说明部署成功,并且模型对代码语义的理解是准确的。
可以再用一个常见代码调试请求测试一下:
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.6-35B-A3B", "messages": [ {"role": "user", "content": "下面这段代码会报 IndexError,请找出问题并给出修复:\n\nnumbers = [1, 2, 3]\nfor i in range(4):\n print(numbers[i])"} ], "max_tokens": 200 }'
第六步:性能调优——从“能用”到“扛住并发”
代码类请求通常具有高重复性的前缀(例如相同的系统提示词或 import 语句块)。vLLM 0.22.0 的前缀缓存可以自动识别这类重叠,将缓存命中率转化为吞吐提升。在启动时默认会启用,你可以通过日志中 Prefix caching hits 的比例来观察效果。
如果想压测最高吞吐,可以用 vLLM 自带的 benchmark 工具对真实代码补全场景进行负载测试:
wget https://raw.githubusercontent.com/vllm-project/vllm/main/benchmarks/benchmark_serving.py python benchmark_serving.py --backend vllm \ --model Qwen/Qwen3.6-35B-A3B \ --dataset-name sharegpt \ --dataset-path ~/ShareGPT/code_completion.json \ --num-prompts 100 \ --request-rate 32
如果发现延迟突增,可以手动调整 --max-num-seqs 和 --max-context-len 的平衡,给 KV cache 留足空间。一般经验是,单张 A100 80GB 跑 int4 量化后,设置 --max-num-seqs 48、--max-model-len 8192 可以在代码补全场景下达到 400 tokens/s 的吞吐。
最小可行配置
如果你只想快速拉起一个代码模型 API 服务,以下一行命令即可(单卡 A100 80GB,使用 bitsandbytes 量化):
vllm serve Qwen/Qwen3.6-35B-A3B --trust-remote-code --quantization bitsandbytes --max-model-len 12288 --gpu-memory-utilization 0.92 --max-num-seqs 16
服务启动后,通过 curl http://localhost:8000/v1/chat/completions 发送类似上文的消息体验。遇到报错先检查驱动和 CUDA 版本,其次确认量化模型的兼容性——这两个坑是 80% 用户的卡点。避开之后,你就拥有一套可扩展的代码生成引擎,随时嵌入到开发流水线中去。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
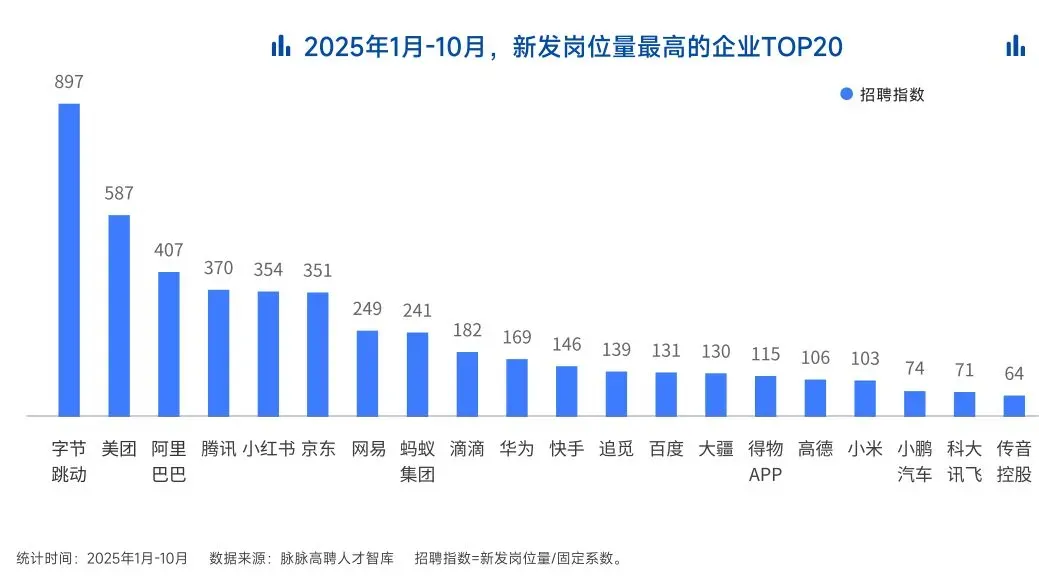
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献164条内容
已为社区贡献164条内容

所有评论(0)