用音频处理项目串联介绍:大模型技术演进路线
大型语言模型(LLM)的发展并非一蹴而就,而是伴随着旧有技术的瓶颈和新应用场景的刚需,逐步演进出了一套庞大的技术生态。本文将结合真实的音频处理项目实战,按技术演进的时间线,详细剖析 Prompt、Context Window、Function Calling、MCP、RAG 与 Agent 等核心概念。
阶段一:纯文本交互时代的局限
在大模型发展的初期,模型被设计为纯粹的“文本到文本(Text-to-Text)”生成引擎。
1. Prompt(提示词)
概念:驱动大模型执行任务的自然语言指令,通常分为系统提示词和用户提示词。
- 系统提示词:在用户交互前,由系统底层注入的全局指令。它用于设定模型的“人设”、输出规范、专业领域边界。它就像是给大模型带上了一个特定的“面具”。
- 用户提示词:用户在具体会话中输入的实际需求和指令。
音频场景应用:
假设我们要处理一个名为 test_noise.wav 的测试音频。在早期的纯文本交互中,我们只能让它做一些基于库的基础特征计算。
系统提示词设置:
“你是一位专业的音频处理算法工程师。在编写音频处理代码时,必须使用 Python 的
librosa库。代码必须包含完整的注释,且在计算梅尔频谱时,默认使用sr=22050,n_mels=128,n_fft=2048,并使用matplotlib将频谱图保存为图片。”
用户提示词输入:
“请帮我写一段代码,读取当前目录下的
test_noise.wav,打印它的精确时长(秒),并绘制它的梅尔频谱图,保存为mel_spectrogram.png。”
模型基于上述双重 Prompt,会输出如下高质量的、可直接运行的代码示例:
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
def process_audio(file_path):
# 1. 加载音频,统一采样率 22050
print(f"正在加载音频文件: {file_path}")
y, sr = librosa.load(file_path, sr=22050)
# 2. 计算并打印音频时长
duration = librosa.get_duration(y=y, sr=sr)
print(f"音频时长: {duration:.2f} 秒")
# 3. 提取梅尔频谱 (Mel Spectrogram)
# 使用系统提示词中要求的标准参数: n_fft=2048, n_mels=128
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=512, n_mels=128)
# 将功率谱转换为分贝 (dB) 单位
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
# 4. 绘制并保存频谱图
plt.figure(figsize=(10, 4))
librosa.display.specshow(mel_spec_db, sr=sr, hop_length=512, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram')
plt.tight_layout()
save_path = 'mel_spectrogram.png'
plt.savefig(save_path)
print(f"梅尔频谱图已保存至: {save_path}")
plt.close()
if __name__ == "__main__":
process_audio("test_noise.wav")
运行结果输出:
正在加载音频文件: test_noise.wav
音频时长: 10.00 秒
梅尔频谱图已保存至: mel_spectrogram.png
生成的梅尔频谱图: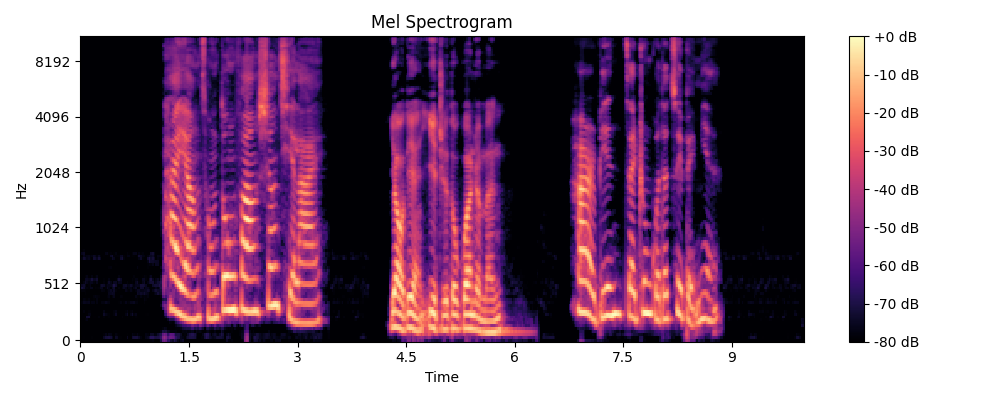
2. Hallucination(幻觉)
产生原因:大模型本质上是一个基于概率的自回归引擎(预测下一个词)。然而,更准确地说,这里的幻觉本质是缺少 Grounding(事实锚定/物理感知)导致的过度生成。当模型在无可靠外部证据的情况下,被强行要求进行事实性判断时,它倾向于为了“补全对话逻辑”而捏造合理但虚假的事实。
音频场景痛点:
如果你直接问一个纯文本模型:“请帮我听一下本地文件 test_noise.wav,里面有背景噪音吗?噪音大不大?”
此时模型处于完全的“黑盒”状态——它没有耳朵,也没有接口去读取本地文件系统。但为了满足用户的提问,它极大概率会“幻觉”出一个听起来很合理的答案:“是的,我检测到该音频在后台有明显的风扇白噪声和低频隆隆声,建议进行降噪处理。”——这完全是毫无根据的捏造。
正确解法:
产生这种幻觉的核心原因不是模型“笨”,而是我们没有给它提供证据却逼它去“猜”。解决该痛点的核心思路是为模型建立可信的感知路径。
由于大模型本身无法直接“听”出复杂的声学结构,最主流的解法是引入专业的外部算法库(工具增强):大模型可以去调用像 ClearVoice-ASR 这样的专业离线降噪模型,先把人声和噪声在物理信号层面上分离出来,然后让工具计算出真实的信噪比(SNR)或噪声能量值并回传。大模型拿到这些真实的“物理证据”后,才能据此进行可靠的二次分析和决策(比如判断是否需要重录、或者继续提取文字)。
(注:其他辅助方案还包括使用原生支持音频输入的多模态大模型,或通过检索增强查询该音频的已知特征报告。)
3. Context Window(上下文窗口)与长文本技术
产生原因:由于 Transformer 架构的注意力机制计算复杂度是序列长度的平方级别(O(N2)O(N^2)O(N2)),大模型在单次对话中能处理的 Token 数量存在物理上限(早期的 Context Window 往往只有 4K 或 8K Tokens)。当对话内容超出该额度时,模型就会被迫截断或遗忘最早的信息。
痛点一:数值文本化导致的 Token 膨胀与推理失效(数据层面)
在语音识别(ASR)场景中,开发者为了让模型“看”到音频特征,常尝试把提取出的梅尔频谱 (128, 431) 矩阵转化为文本字符串喂给模型。
虽然底层瓶颈是 O(N2)O(N^2)O(N2),但在实际工程中,真正瞬间打爆窗口的是数值文本化后的 Token 膨胀。这 55,168 个浮点数(例如 -42.1583)经过 Tokenizer 处理时,小数点、负号、数字序列往往会被拆分成若干个 Token。实际 Token 数量会暴增至元素个数的几倍甚至十几倍,十几万 Token 的开销会瞬间吃光预算。
此外,连续浮点数文本对 Transformer 的“数值稳定性/软对齐”极不友好,模型并不擅长像数值程序那样精确比较浮点数大小。因此,直接逼迫模型阅读生肉矩阵来推理特征,是极其低效和不准确的。
痛点二:多轮复杂对话中的“灾难性遗忘”(工程层面)
如果你想从零开发一个既能降噪、又能语音识别的完整工程项目(如 ClearVoice-ASR),整个开发周期是非常漫长的。如果你一直停留在同一个单独的对话窗口里与模型结对编程,很快就会耗尽上下文额度,导致模型忘记前置设定。
场景例子:第 1 轮对话时,你跟模型约定好了工程的架构:降噪底层核心类叫 OfflineNS,语音识别底层核心类叫 OfflineASR。随着开发的深入,你在这个窗口里不断粘贴环境配置报错、依赖冲突日志以及各模块的调试代码。到了第 20 轮对话时,几十页的调试日志已经把你们最早约定的“工程架构”给挤出了 Context Window。
此时,你让它写一个顶层的串联处理函数,它因为已经“失忆”,可能会凭空捏造出一个叫 NoiseReducer 的变量,甚至用自己瞎编的第三方音频库来写代码,导致新写出来的代码与前面的核心类完全脱节,工程逻辑彻底断裂。
对抗遗忘的解法:长文本模型与上下文压缩
为了解决上述痛点,业界发展出了两条截然不同的技术路线:
解法一:硬抗物理上限(长上下文技术 Long Context)
支持百万级 Token 的模型(如 Gemini 1.5 Pro 的 2M Context)主要得益于两项底层突破:
- RoPE(旋转位置编码):改变了传统绝对位置编码的局限,让模型能够更平滑地“外推”到训练时未见过的超长序列。
- FlashAttention:通过重组注意力机制的计算顺序和利用 GPU SRAM 的高速缓存,大幅降低了计算超长序列时的显存峰值占用。
长文本技术的突破,使得开发者现在可以直接把几十万行的ClearVoice-ASR项目全量源码一次性塞给模型,让它进行全局视角的代码重构。
解法二:精打细算(上下文压缩与外部代理)
即便模型支持长文本,每次对话带着海量 Token 也会导致响应极慢且成本高昂(按 Token 计费)。因此工程上更推荐“瘦身”路线:
- Prompt 提炼与压缩:在发送给模型前,通过脚本过滤掉无用的调试日志,或使用专门的轻量级模型对历史对话进行摘要提炼。
- 让模型去“读”而不是“背”:不要把几万行代码硬塞进窗口,而是提供一个类似
search_codebase的本地 Tool,让模型在需要时自己去检索对应文件的片段。 - 将逻辑下沉为 Skills:将反复使用的固定套路(如降噪的初始化步骤)封装成本地的 Python 脚本或 JSON 配置,这正是后面阶段二我们将要讲到的 Tools 与 Skills 技术的底层驱动力之一。
阶段二:系统级交互与执行能力的扩展
为了让大模型突破“只能说不能做”的限制,模型开始具备输出结构化指令、触发外部环境执行动作的能力。
4. Function Calling、Tools 与 Skills(执行能力的三层递进)
执行边界与安全警告:
在深入概念前,必须澄清一个核心误区:“大模型能写代码” 绝不等于 “大模型能在你的环境里跑代码”。大模型本身是一个纯粹的文本推理引擎,它没有手脚。
真实的执行链路具有严格的物理隔离与安全边界:
大模型基于上下文生成调用意图(符合 Tool schema 的 JSON) → 宿主系统拦截并进行参数校验 → 在受限权限的沙盒(Sandbox)中实际执行代码 → 记录可审计日志 → 将执行结果(Observation)作为普通文本回传给大模型。
虽然行业内常将这三个词混用,但在工程落地时,它们代表了从底层到高层的三个不同维度:
4.1 Function Calling(底层通信协议)
概念:大模型 API(如 OpenAI 接口)提供的一种底层结构化输出能力。它强迫模型不再输出发散的自然语言,而是输出严格符合预定义数据结构(JSON Schema)的参数。
音频场景例子:当大模型判断需要获取时长时,它不执行任何操作,仅仅是生成并输出如下纯文本流:{"function_name": "get_audio_duration", "arguments": {"file_path": "polqa_ref.wav"}}
4.2 Tools(原子化的工具)
概念:开发者在本地或后端系统中实际编写的、执行具体单一任务的代码函数(Function)或脚本。它是响应 Function Calling 的“物理执行者”。
音频场景例子:在 ClearVoice-ASR 项目中,底层封装了极度复杂的 PyTorch 神经网络(如 AudioEnhancer),但暴露给大模型调用的工具(Tool)仅仅是一个高度抽象的包装器。大模型发出 Function Calling 请求后,本地计算机验证权限并运行 Tool,然后将真实结果回传。
代码示例(真实的底层算法封装与单例模式):
为了保证大模型频繁调用工具时不会重复加载庞大的模型权重,真实的 Tool 底层(如 asr_api.py)通常会采用单例模式常驻内存:
import wenet
import os
class OfflineASR:
"""基于 Wenet Paraformer 的离线语音识别接口封装"""
_instance = None
def __new__(cls, model_name: str = 'paraformer'):
if cls._instance is None:
cls._instance = super(OfflineASR, cls).__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self, model_name: str = 'paraformer'):
if self._initialized: return
print(f"正在加载语音识别模型: {model_name}...")
self.model = wenet.load_model(model_name)
self._initialized = True
def transcribe_file(self, audio_path: str) -> str:
if not os.path.exists(audio_path):
return f"Error: 文件不存在 -> {audio_path}"
result = self.model.transcribe(audio_path)
return result.text if hasattr(result, 'text') else str(result)
大模型通过 JSON 指令发出请求后,本地系统拦截指令,瞬间调用已初始化的 OfflineASR 实例处理音频,并将 result.text 文本反馈给模型作为 Observation。
4.3 Skills(面向业务的场景化技能)
概念:通常存在于更高级的 AI Agent 或平台架构中,是一个封装了“专属系统提示词 + 多个底层 Tools 编排 + 特定业务逻辑”的能力包。它比原子的 Tool 更宏观,直接对齐用户的业务意图。
音频场景例子:在 ClearVoice-ASR 项目中,我们配置了一个名为 AudioAssistant 的 Skill。
这并不是一段执行降噪的 Python 代码,而是一份定义了专家级 SOP(标准作业程序)的 JSON 配置文件:
{
"skill_name": "AudioAssistant",
"description": "智能语音处理专家,负责协调降噪与语音识别工作流",
"triggers": ["处理音频", "降噪", "语音识别", "提取文字"],
"system_prompt": "你是一个专业的音频处理助手。当用户要求处理音频时,你需要:\n1. 如果用户要求降噪,调用 `run_noise_suppression` 工具。\n2. 如果用户要求识别文字,调用 `run_speech_recognition` 工具。\n3. 核心SOP:如果同时要求降噪和识别,必须严格遵循【先降噪,后识别】的工作流:先调用降噪工具获取返回的 clean_path,再将该纯净音频路径作为输入传递给识别工具。",
"required_mcp_servers": [
"SmartAudioAssistant"
]
}
当用户在对话框输入“帮我处理音频提取文字”时:
- 意图路由:系统检测到命中
triggers关键字,立刻唤醒该 Skill。 - 挂载能力:Skill 自动为大模型注入
system_prompt中设定的“专业音频助手”人设,并自动连接到SmartAudioAssistantMCP 服务器。 - 闭环编排:大模型无需用户手动指挥,就会自主遵循 SOP,先调用降噪 Tool 生成干净音频,再自动把新路径传给识别 Tool。
对于用户来说,他只需要下达一个模糊的业务指令,背后“模型推理+多工具流转”的复杂业务闭环就被 Skill 彻底隐藏并自动化了。
5. MCP (Model Context Protocol)
产生原因:虽然 Function Calling 解决了执行问题,但每个开发者都需要为大模型手动编写上述的工具定义(Schema)、路由代码和执行环境,导致不同的应用(IDE、DAW、数据库)之间生态割裂。
概念:MCP 是一个标准化的开源协议。它统一了大模型与外部数据源/工具的通信规范。
音频场景应用:
在上述 AudioAssistant Skill 的配置中,我们看到了 "required_mcp_servers": ["SmartAudioAssistant"]。读者可能会好奇,这个 MCP Server 到底在底层做了什么?
实际上,开发者只需利用 mcp 框架编写极少量的代码,就能将复杂的本地算法库暴露为标准的 MCP 服务。以下是 ClearVoice-ASR 项目中 mcp_server.py 的真实源码:
from mcp.server.fastmcp import FastMCP
import os, soundfile as sf
from ns_api import OfflineNS
from asr_api import OfflineASR
# 1. 初始化 MCP Server (充当大模型跨环境执行的“手”)
mcp = FastMCP("SmartAudioAssistant")
@mcp.tool()
def run_noise_suppression(audio_path: str) -> str:
"""【工具】对指定路径的音频进行降噪处理,返回新路径"""
try:
ns_api = OfflineNS('audio_enhancer.pth')
voice_signal, _, sr = ns_api.process_file(audio_path)
clean_path = audio_path.replace(".wav", "_clean.wav")
sf.write(clean_path, voice_signal, sr)
return f"降噪成功!纯净语音已保存至: {clean_path}"
except Exception as e:
return f"降噪失败: {str(e)}"
@mcp.tool()
def run_speech_recognition(audio_path: str) -> str:
"""【工具】对音频进行文字识别,返回识别文本"""
try:
asr_api = OfflineASR('paraformer')
return f"识别结果: {asr_api.transcribe_file(audio_path)}"
except Exception as e:
return f"识别失败: {str(e)}"
if __name__ == "__main__":
mcp.run() # 启动服务,通过标准输入输出流(stdio)监听客户端连接
这个服务器对外暴露了两个具体的 Tool:run_noise_suppression 和 run_speech_recognition。它通过 MCP 协议的 tools/list 端点,让任何支持 MCP 的客户端(如 Trae IDE 或 Claude Desktop)自动“发现”这些工具。
当 Skill 激活并连接该 Server 时,大模型就能像调用系统自带功能一样,直接跨环境调用这两个工具。用户只需在 IDE 里说一句:“帮我对录音降噪并提取文字”,大模型就会通过 MCP 协议指挥本地服务器运行你的 ns_api.py 和 asr_api.py,全程无需你手动编写任何“粘合剂(Glue)”代码。
开源生态扩展:
除了自定义开发,目前开源社区已经有大量开箱即用的 MCP Servers,极大扩展了模型的能力边界:
mcp-server-sqlite:让模型直接连接并查询本地数据库(例如查询你的音频资产数据库)。mcp-server-github:让模型直接读取 Github 仓库的 Issue 和代码,帮你分析音频库的 Bug。mcp-server-fetch:让模型具备读取任意网页内容的能力。
阶段三:垂直领域知识的深度定制
大模型拥有了手脚(工具),但其内部的参数权重(预训练知识)仍停留在通用领域,对于极度垂直的私有音频库依然无能为力。
6. RAG(检索增强生成)与 Embedding(向量化)
产生原因:重训练或微调(Fine-tuning)模型的成本极高(需要昂贵的算力和数据清洗),且无法实时更新知识。比如你今天刚在本地录制了十个新的背景噪音测试文件,模型是不可能马上通过微调知道它们存在的。
概念:
- Embedding:将文本、图像或音频数据映射到高维稠密向量空间。语义相似的数据在向量空间中距离相近。
- RAG:在生成回答前,先通过向量相似度检索出相关的知识片段,将其注入到 Context Window 中,再由大模型进行总结。
音频场景应用(测试语料检索与问答):
为了方便管理 ClearVoice-ASR 产生的大量测试数据,我们构建了一个基于 RAG 的智能查询系统:
- 构建向量库:当每次有新的带噪音频(如
test_noise.wav)和对应的测试报告产生时,系统会将“音频的环境描述(如:室内、风扇噪音、信噪比5dB)”使用 Embedding 模型转化为向量,存入本地数据库。 - 检索(Retrieval):当你在终端提问:“找一个之前测试过的室内风扇噪音的音频来验证一下新的降噪算法。”系统将这段文本同样转为向量,在数据库中找到最匹配的记录。
- 增强生成(Augmented Generation):系统召回了该音频的元数据,并把它交给大模型。大模型回复:“为您推荐
test_noise.wav,这是一段录制于室内且包含明显风扇底噪的测试音频,非常适合您当前的验证。”
阶段四:从被动调用到自主闭环
7. Agent(智能体)与 Harness(运行时框架)
产生原因:传统的 Prompt 交互范式是“指令-响应”式的(单工模式)。面对复杂的复合任务,用户需要不断充当“调度员”的角色。
概念:
- Agent 是一个以大语言模型为“大脑”,具备环境感知、记忆、规划、工具调用和多轮反思(Reflection)能力的自治系统。
- Harness(框架/脚手架) 则是承载 Agent 运行的底层基础设施(如 LangChain、AutoGen 等)。大模型只负责“想”,而 Harness 负责“管”:它负责解析大模型的输出、捕获工具执行的异常、限制死循环次数、并把执行结果重新拼接成上下文喂给大模型。
音频场景应用(全自动智能语音助手):
用户下达宏观目标:“请帮我处理 ClearVoice-ASR/ 目录下的测试音频 test.wav,我要纯净的人声和文字记录。”
Harness 驱动下的 Agent 自主执行链路(ReAct 与 CoT 架构):
为了实现上述链路,Harness 内部实际上封装了 CoT(Chain-of-Thought 思维链) 的逻辑模板。它强制大模型在做出 Action 之前,必须先输出 Thought(我是怎么推理的)。这种将复杂任务拆解为多步显示的推理链条,极大地提升了模型的逻辑严密性和可解释性:
- Thought(大模型通过 CoT 推理):我需要先找到音频文件,然后对其进行降噪,最后提取文字。
- Action(大模型决定动作):输出 JSON 要求调用工具
list_directory(path="ClearVoice-ASR/")。
(此时 Harness 拦截输出,执行本地 Python 代码) - Observation(Harness 回传观察):找到了
test.wav。 - Thought(大模型通过 CoT 推理):环境中有我要的文件。接下来我需要调用降噪工具来提升音频信噪比,否则识别准确率会很低。
- Action(大模型决定动作):要求调用
run_noise_suppression(file_path="test.wav")。
(Harness 执行降噪,若发生 CUDA 内存溢出等异常,Harness 会将报错栈作为 Observation 回传,CoT 会引导模型反思并输出:降噪工具返回了显存不足的错误,我需要调用音频切片工具分段处理。) - Observation(Harness 回传观察):降噪成功,生成了
test_clean.wav。 - Thought(大模型通过 CoT 推理):现在噪音已去除,我可以对纯净音频
test_clean.wav进行文字提取了。 - Action(大模型决定动作):要求调用
run_speech_recognition(file_path="test_clean.wav")。 - Observation(Harness 回传观察):识别出了文字:“仓库的后面是一间小屋…”。
- 最终反馈:Harness 判定任务结束,向用户输出结构化报告:“已为您处理完毕。降噪音频已保存为
test_clean.wav,识别出的文字为:‘仓库的后面是一间小屋…’。”
8. Multimodal(多模态)
产生原因:即便有了 Tools 和 MCP,让大模型处理音频依然是“间接”的(它只能看提取出来的文字或数值参数),信息在转换过程中不可避免会丢失(例如语气、情感、背景环境音的层次感)。
概念:多模态大模型打破了单一文本的限制,其底层的神经网络在训练时同时接入了文本、音频、图像等多种编码器(Encoder)。模型不再是“看文字猜声音”,而是真正能够“听懂”音频流。
音频场景应用:
如果用户上传了一段 user_feedback.wav(包含用户的叹气声和急促的语速),对于早期的架构:
- 传统 ASR 工具:只能转录出冰冷的文本:“这个软件太难用了。”
- 多模态大模型(如 GPT-4o):可以直接输入原始音频波形。模型不仅能转录文字,还能直接分析出声学特征,给出结论:“用户表达了强烈的挫败感,语速比正常快了 1.5 倍,且背景有键盘敲击的噪音,推测用户正在焦躁地进行操作测试。”
阶段五:总结与展望
回顾大模型技术演进的四个阶段,我们看到了 AI 处理复杂现实世界任务(如音频处理)的能力是如何一步步被解放的:
- 纯文本阶段:模型只能像一台聪明的打字机,受限于没有感知(引发幻觉)和短小的 Context Window,只能做最基础的特征运算代码生成。
- 工具化阶段:Function Calling 和 MCP 赋予了模型跨系统调用专业库(如
ClearVoice-ASR)的“手脚”,让复杂的降噪与识别在底层物理执行。 - 自治化阶段:Agent 与 Harness 让模型拥有了自主闭环规划的能力,用户只需给出一个宏大目标,系统即可自动拆解并循环执行。
- 多模态阶段:模型终于长出了“耳朵”,能够直接听懂声音中的情感与层次。
未来展望:
未来的智能应用开发,将不再是让大模型一行行写枯燥的 Python 脚本,而是向着编排与协同的方向发展。开发者会专注于封装更强大的专业级 Tool,编写更严谨的 Skill 业务配置包(SOP),构建更健壮的 Harness 运行环境,最终由原生多模态的大模型来充当超级大脑,完成对物理世界数据的深度洞察与自动化处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)