独立开发者技术栈实战:12款工具构建全链路开发工作流
作为一名独立开发者,我在两年时间内试用了50多款生产力工具,最终沉淀出这套12工具组合。本文从工程实践角度,分享如何低成本搭建覆盖“需求→设计→开发→测试→部署→增长”的技术栈。
一、技术视角:独立开发的核心瓶颈在上下文切换
很多人以为独立开发者的痛点是技术难题,其实不然。真正消耗精力的是在不同角色之间频繁切换:刚写完用户故事的逻辑,转头要调整CSS配色,接着又得配置CI/CD流水线。
认知科学中有一个概念叫「上下文切换成本」。研究显示,开发者在被打断深度工作状态后,平均需要23分钟才能恢复此前的专注度。独立开发者一天之内自我打断十几次是常态,这种认知损耗远比debug一个复杂问题更致命。
另一个工程化层面的问题是产物碎片化:
需求文档 → Notion
设计稿 → Figma
源代码 → GitHub
接口文档 → 某处Markdown
错误日志 → Sentry
各产物之间缺乏自动流转机制,每次迭代都要人工搬运信息。当产品演进至v3版本时,v1的设计决策依据往往已不可追溯。
我们需要的是一条Pipeline:每个Stage的输出自动成为下一个Stage的输入。

二、12款工具技术解析(按DevOps流程分类)
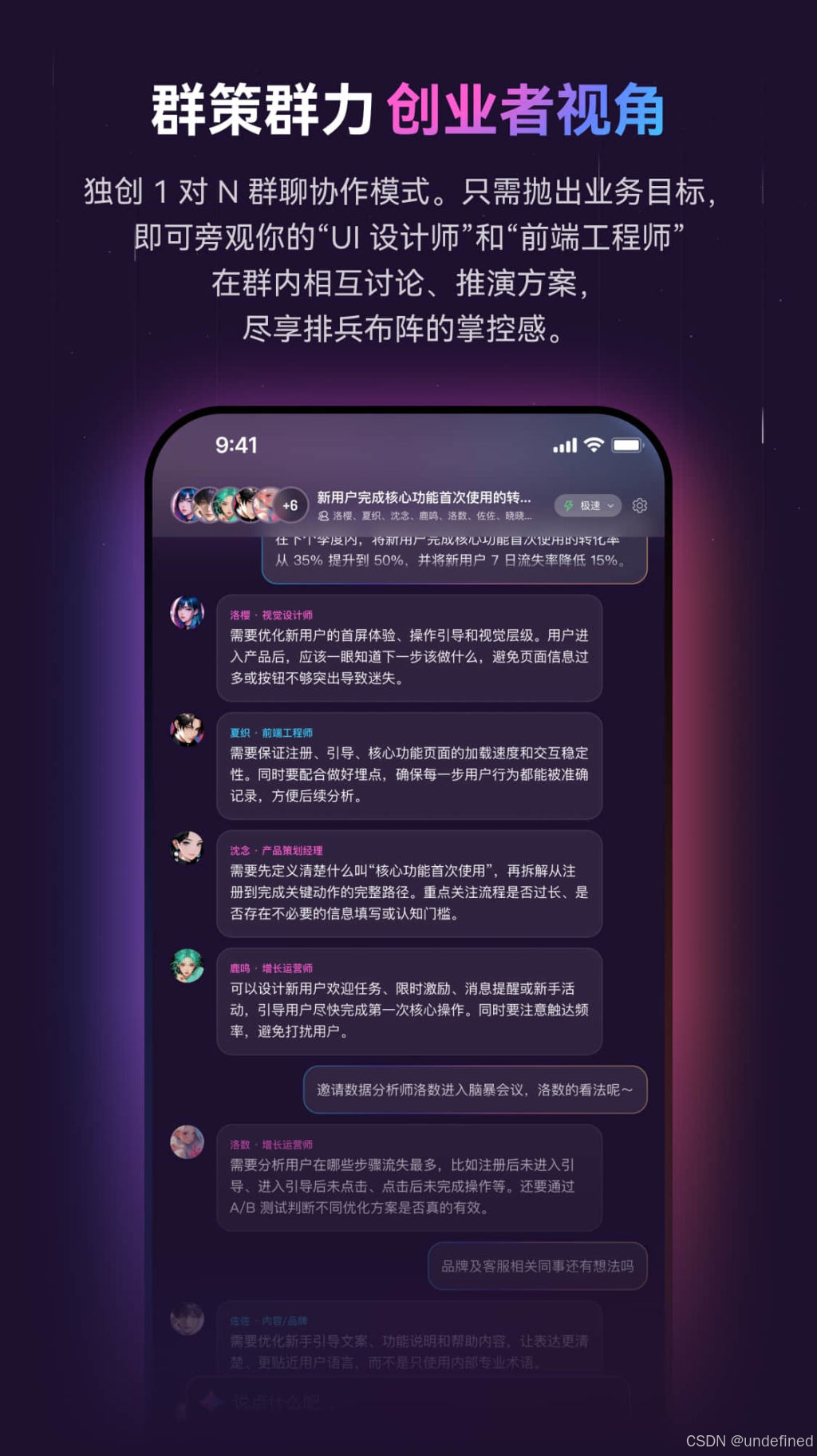
工具1:墨见 — AI驱动的需求工程平台
技术定位:基于多Agent协作的需求拆解系统,集成产品、设计、技术、增长四个维度的AI角色。

工程实践:在墨见中创建项目后,输入初步产品构想。AI系统会从以下维度输出可行性分析报告:
产品维度:核心用户画像、价值主张、功能优先级
设计维度:信息架构、关键页面流程
技术维度:技术栈选型建议、实现复杂度评估
增长维度:获客路径、转化率预估
对我这样的技术背景开发者而言,增长维度的分析特别有价值——它能指出我本能忽视的运营难点。
优势:项目级记忆能力,支持持续对话和追问,无需重复交代项目背景。最终产物为可直接进入UI设计阶段的结构化PRD。
工具2:Notion — 项目知识库
技术定位:文档型数据库,支持关系型数据关联。
工程实践:PRD、竞品分析、用户反馈按项目维度归档。利用Notion的database功能,建立需求追踪表,将用户反馈与功能迭代关联。三个月后回看时,能完整还原决策链路。
工具3:Figma — UI设计与Design System
技术实践:基于Auto Layout和Component Variants构建可复用的设计系统。我的工作流:
从墨见PRD中提取页面结构
在Figma中调用组件库快速搭建
利用墨见生成的React代码框架做参考,确保设计在实现层面可控
关键技巧:为常用组件(Button、Card、Modal)创建Variants,覆盖不同状态和尺寸,保证设计与代码实现的一致性。
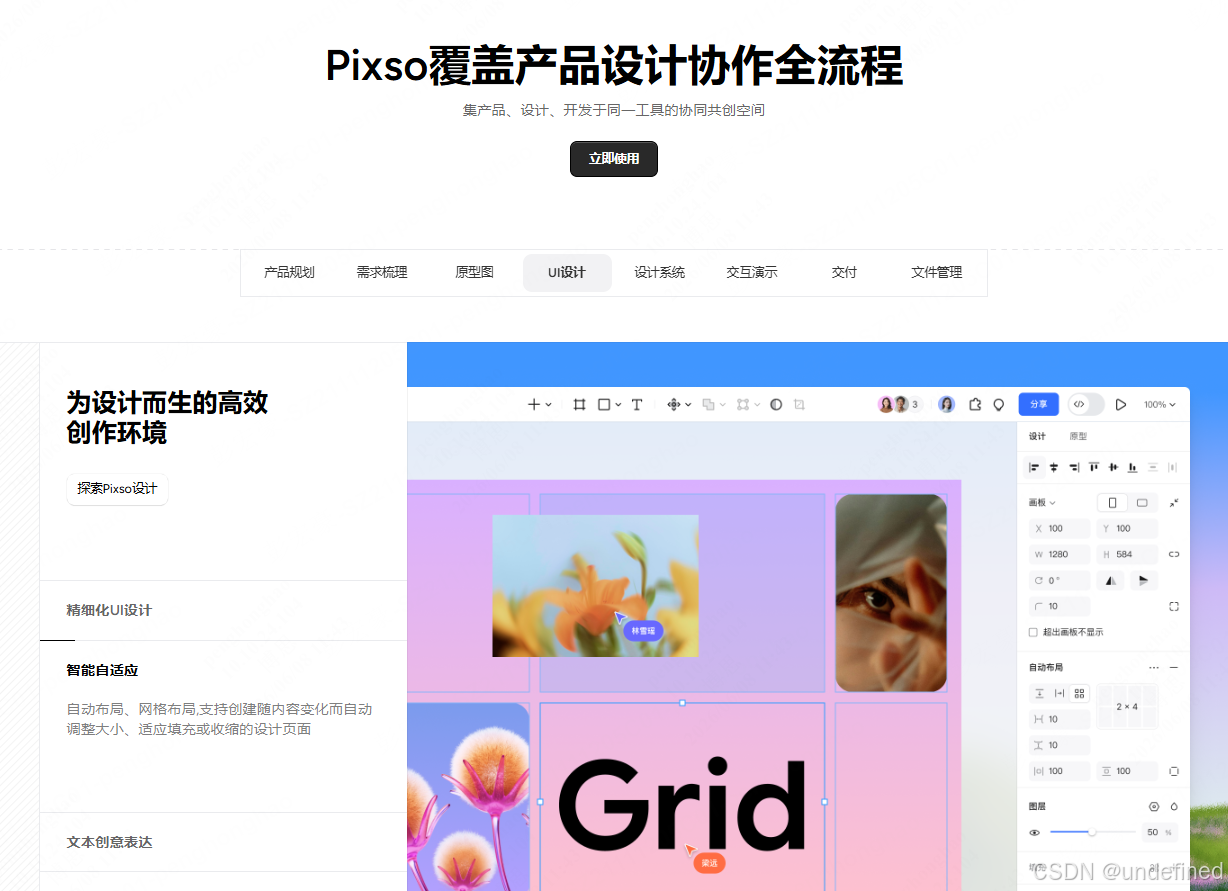
工具4:Pixso — 原型演示与协作
技术实践:当需要向早期用户或合作方演示时,用Pixso制作高保真可交互原型。核心优势:
国内服务器,加载速度优于海外竞品
一键生成分享链接,支持评论和标注
个人版可免费使用,满足独立开发者使用场景
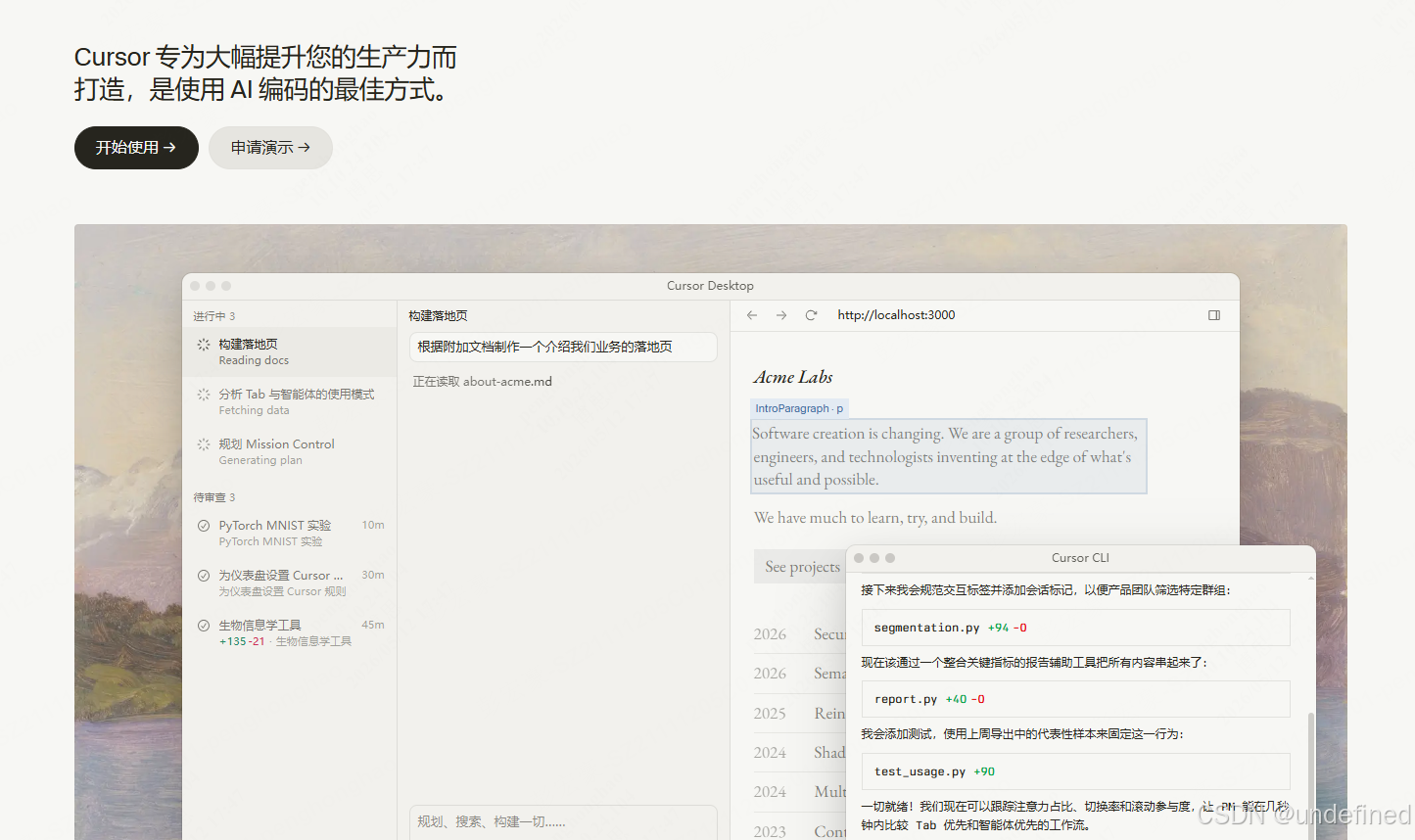
工具5:Cursor — AI原生IDE
技术定位:基于VS Code fork的AI集成开发环境,深度理解项目上下文。
工程实践:这不是简单的代码补全,而是真正的AI Pair Programming。典型工作流:
Cmd+L打开Chat面板,用自然语言描述需求
AI生成代码骨架,包含类型定义、状态管理、API调用
开发者在关键业务逻辑上进行Review和微调
Tab键接受内联建议,处理样板代码
效率数据:接入Cursor后,前端页面开发时间平均缩短60%。从设计稿到可运行的React组件,大半天即可完成。
技术细节:Cursor的上下文理解能力基于整个代码库的Embedding。它会读取相邻文件、配置文件、依赖列表,生成的代码风格与项目已有代码保持一致。
工具6:GitHub — 代码托管与DevOps
技术实践:除了Git版本管理,重点配置GitHub Actions实现CI/CD流水线
每次push自动触发测试和构建,阻断明显的问题进入生产环境。
工具7:Vercel — 前端部署平台
技术实践:与Next.js深度集成,实现零配置部署:
Push代码 → 自动Build → 生成Preview URL
Production分支自动部署到生产域名
Edge Network全球CDN加速
独立开发者无需关心服务器配置、SSL证书、CDN设置,专注业务逻辑开发。
工具8:Postman — API测试自动化
技术实践:为所有后端接口创建Collection,定义请求参数、断言规则、环境变量。
关键实践:
每个接口至少覆盖Happy Path和Error Case
使用Environment Variables管理不同环境的Base URL
导出Collection作为项目文档的一部分
迭代时复用已有测试用例,防止回归
这个习惯帮我避免了至少三次潜在的线上故障。
工具9:Sentry — 可观测性平台
核心价值:错误堆栈追踪、受影响用户统计、Release关联。没有运维团队的独立开发者,Sentry是生产环境的眼睛。
工具10:Product Hunt — 首发流量获取
技术实践:产品正式发布前的必备准备:
提前一周准备英文介绍文案、Maker Comment、演示视频
准备5-10条对潜在评论的回复模板
首发当天保持在线,快速回复评论
引导早期用户在PH页面留言,互动频率直接影响排名
数据参考:数据显示,登上首页的产品平均获得3000-5000次首日访问。
工具11:Google Analytics 4 — 用户行为分析
技术实践:关键事件追踪配置:
page_view:分析用户流转路径
feature_use:核心功能使用频次
conversion:注册/付费转化漏斗
数据驱动的决策逻辑:当数据证明某功能使用率低时,果断停止投入;当某路径转化率高时,集中资源优化。
工具12:Stripe — 支付基础设施
技术实践:API集成要点:
Checkout Session处理一次性付款
Subscription API处理周期性订阅
Webhook处理支付状态变更
Customer Portal让用户自助管理订阅
Stripe的API设计堪称RESTful API的典范,文档清晰,SDK完善,出海产品的标配选择。
三、Pipeline设计:工具间的衔接机制
工具链的价值不在于单点能力,而在于端到端的自动化程度。
Stage 1:Idea → PRD
墨见的项目级记忆让需求分析是连续的。开发者可以随时追问:「上次定的核心用户画像是什么?」「这个功能的技术实现复杂度如何评估?」产出物为结构化PRD,直接作为Figma设计的输入。
Stage 2:PRD → Design → Code Skeleton
墨见基于组件规范生成的是工程化原型,不是静态图片。它可以输出前端代码骨架,开发者在Cursor中补全业务逻辑。这个衔接点压缩了从需求到实现的最大时间黑洞。
Stage 3:Code → Deploy → Monitor
GitHub → Vercel的自动部署 + Sentry的自动监控,形成完整的DevOps闭环。
四、成本分析:技术栈月度开支
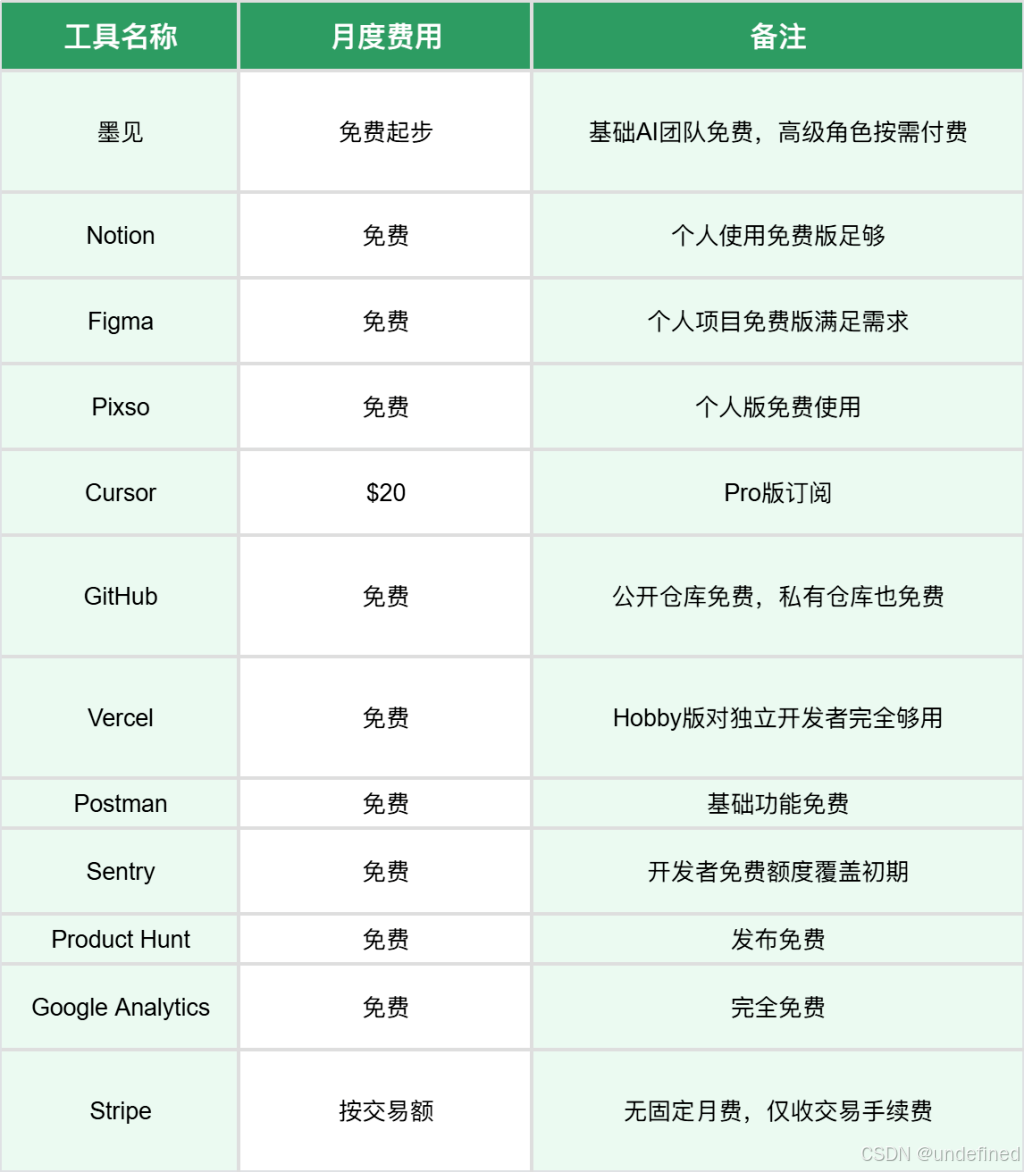
基础配置:月均约145(仅Cursor)
进阶配置:月均300-400(Cursor + 墨见高级AI角色)
对于独立完成全链路开发的场景,这个ROI是非常合理的。
五、分阶段引入路线图
Phase 1 - MVP验证(0-3个月)
核心组合:墨见 + Cursor + Vercel
目标:最短时间产出可验证原型
Phase 2 - 产品验证(3-6个月)
扩展组合:+ Product Hunt + Google Analytics
目标:获取初始用户,数据验证方向
Phase 3 - 规模化(6个月+)
完整组合:+ Stripe + Sentry + Notion系统化
目标:商业化闭环 + 生产环境稳定
六、写在最后
独立开发者的核心竞争力不是工具的数量,而是Pipeline的效率。2026年的AI工具已经能承担大量重复劳动,但架构设计、产品判断、用户理解,仍然需要开发者本人的深度投入。
这套12工具组合帮我实现了一个人活成一支队伍的目标。如果你正在构建自己的技术栈,建议从墨见的AI脑暴开始,先把需求阶段跑通,再逐步扩展到设计和开发环节。
有疑问欢迎在评论区交流,我会持续更新这套工具链的使用心得。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)