从工具到平台:私有化大模型翻译平台的建设思路
建设大模型翻译平台,最容易被低估的一件事是:翻译能力本身只是起点。
如果只是做一个内部小工具,功能可以很简单。用户输入文本,选择语言,点击翻译,拿到译文,任务就结束了。
但如果目标是建设一个可以商业化交付、支持私有化部署、面向企业客户长期使用的平台,问题就会复杂很多。客户真正需要的不是一个“翻译按钮”,而是一套可以放进企业内容生产、知识管理、文档流转和业务系统中的翻译能力底座。
它要能处理不同类型的内容,适配不同模型,管理术语资产,记录任务过程,控制权限和成本,并且能在客户私有化环境中稳定运行。
因此,大模型翻译平台的建设目标不应该是“做一个翻译工具”,而应该是建设一个企业级翻译能力平台。
一、建设目标:从模型调用走向平台能力
大模型翻译平台至少要解决三类问题。
第一类是翻译效率问题。平台要让用户能够快速完成文本、文档、批量内容的翻译,并支持结果预览、下载和复用。
第二类是翻译质量问题。企业翻译不是简单追求“看起来通顺”,还要保证术语一致、格式稳定、数字准确、语气符合场景,并且能对关键内容进行人工审校。
第三类是商业交付问题。平台要能被部署、被配置、被管理、被审计、被升级。对于私有化交付来说,这部分能力甚至和翻译效果同样重要。
从这个角度看,平台建设需要同时考虑业务架构、技术架构和能力边界。哪些能力应该自研,哪些能力可以外采,哪些能力应该放在标准基线里,哪些能力应该留给项目交付适配,都需要在一开始想清楚。
二、业务架构:围绕内容、任务、资产和治理设计
业务架构不应只围绕“翻译动作”设计,而应围绕企业内容翻译的完整生命周期设计。
可以把业务架构拆成五层:用户角色层、翻译场景层、任务流程层、翻译资产层和运营治理层。
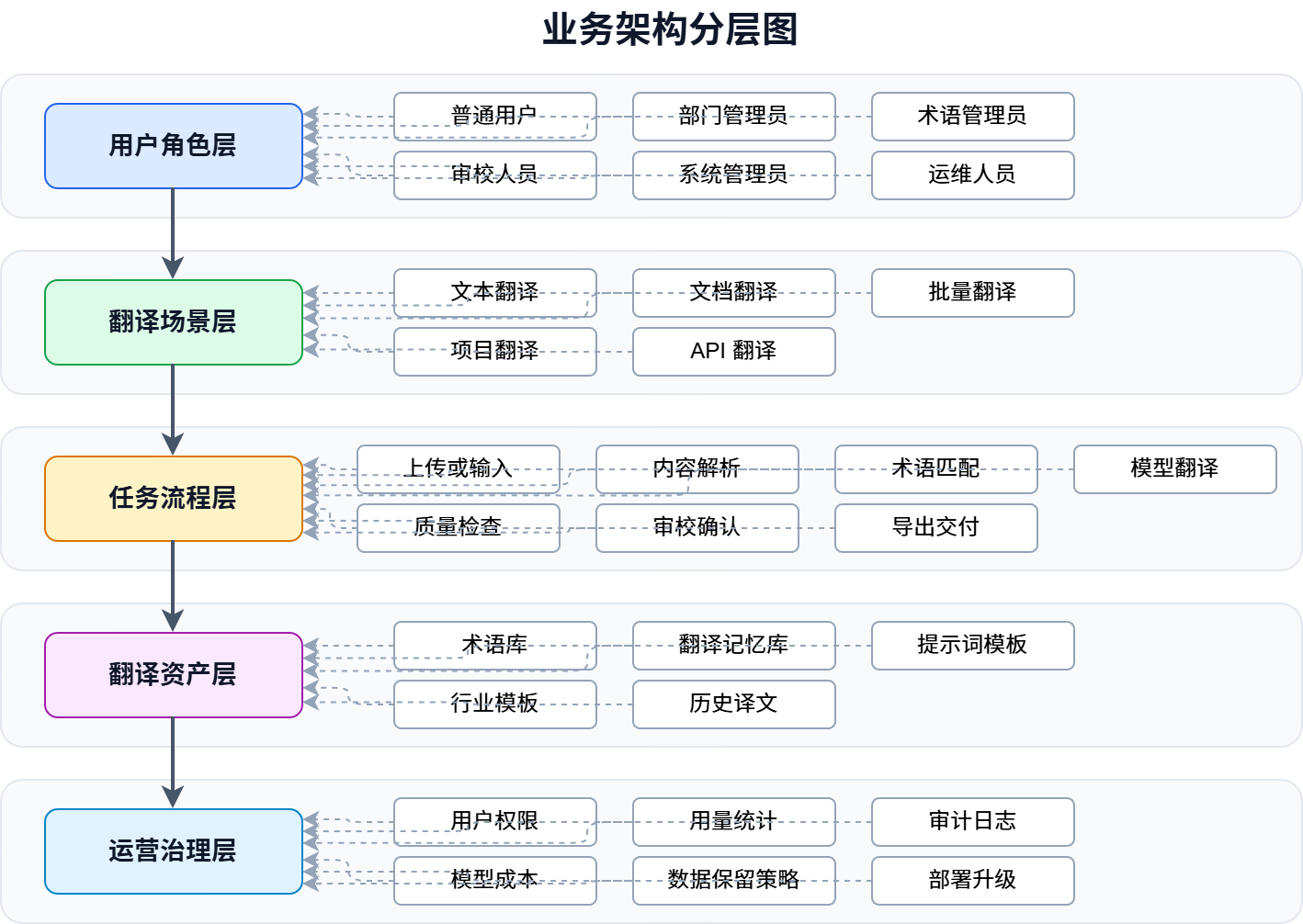
1. 用户角色层
平台中的用户不只有普通翻译用户。一个商业化平台至少会涉及普通用户、部门管理员、术语管理员、审校人员、系统管理员和运维人员。
普通用户关注翻译效率,术语管理员关注术语一致性,审校人员关注译文质量,系统管理员关注权限和配置,运维人员关注模型状态、任务队列和系统稳定性。
角色清楚,权限边界才清楚。后续做任务流转、审计、统计和客户交付时,也更容易扩展。
2. 翻译场景层
企业场景通常包括文本翻译、文档翻译、批量翻译、项目翻译、术语约束翻译、审校翻译和 API 翻译。
第一期不一定要全部做完,但架构上要能容纳这些场景。尤其是文档翻译,通常是企业客户的高频需求。真实客户很少只翻译一句话,更多是翻译合同、报告、制度、产品说明书、技术文档、会议材料和知识库内容。
3. 任务流程层
一个完整的翻译任务不是简单调用模型。它通常包括上传内容、解析文档、识别语言、匹配术语、拆分片段、调用模型、结果后处理、质量检查、人工审校、导出文件和记录日志。
如果平台没有任务流程设计,后续很难支持长文档、批量处理、失败重试、任务追踪和人工协同。
4. 翻译资产层
术语库、翻译记忆库、行业模板、提示词模板、质量规则和历史译文,都是平台越用越有价值的资产。
这也是大模型翻译平台和普通翻译工具的重要区别。普通工具只完成一次翻译,平台要让每一次翻译都反哺后续任务。
5. 运营治理层
私有化商业平台必须具备治理能力,包括用户权限、用量统计、模型成本、审计日志、数据保留策略、敏感内容处理、任务失败重试、授权 License、部署升级等。
这些能力看起来不如翻译效果显眼,但它们决定平台能否在企业环境中真正落地。
三、核心功能模块:先建设企业平台型基线
第一期不建议只做轻量工具型版本。轻量版本交付快,但通常只能证明技术可行性,难以支撑商业化交付。
更合适的方向是建设企业平台型基线。这个基线不必一开始就覆盖完整翻译生产流程,但要具备企业软件的基础能力。
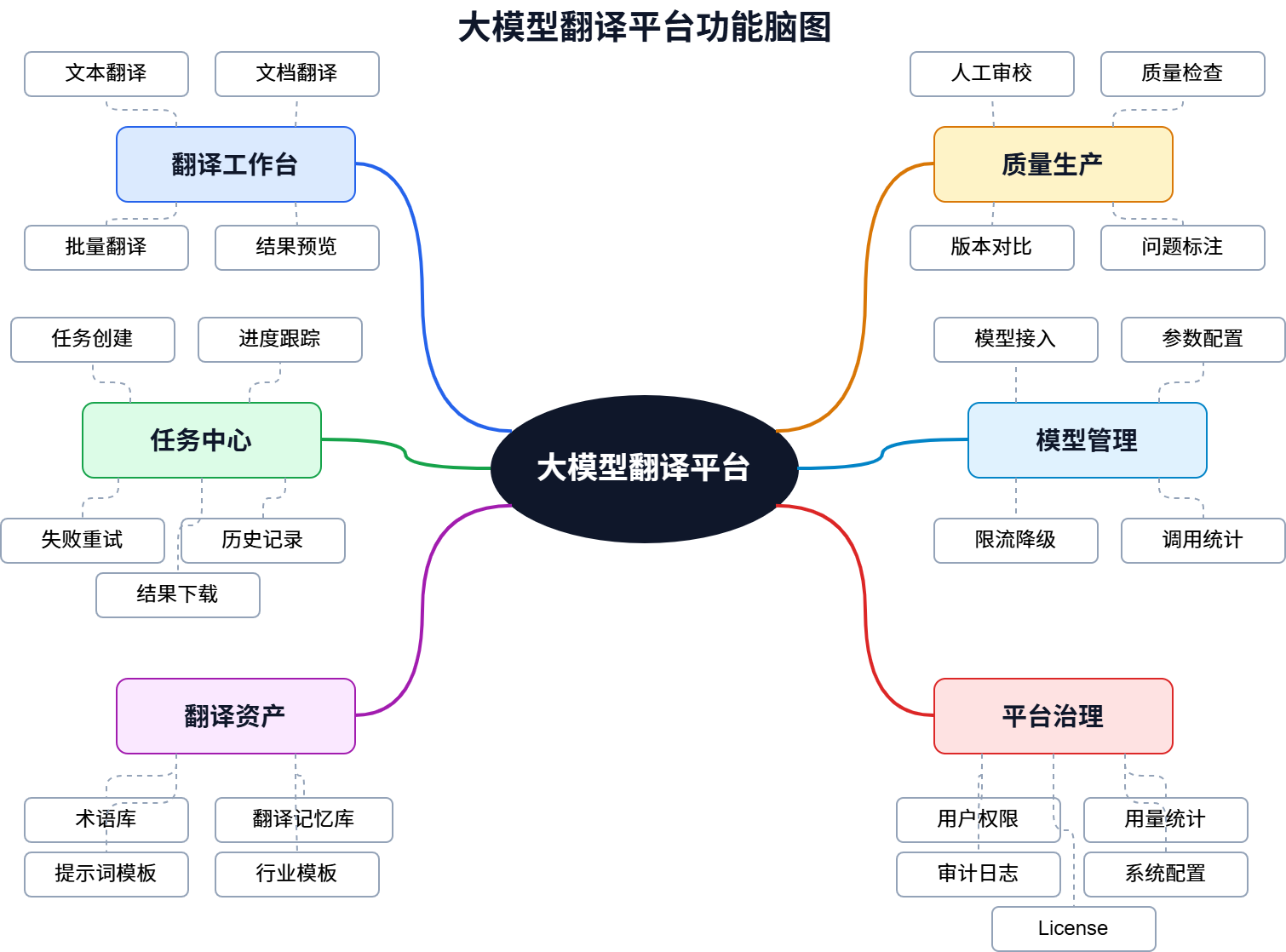
建议第一期优先建设以下模块:
| 模块 | 主要能力 | 一期建议 |
|---|---|---|
| 翻译工作台 | 文本翻译、文档翻译、语言选择、领域选择、结果预览 | 必做 |
| 任务中心 | 任务创建、进度跟踪、失败重试、历史记录、结果下载 | 必做 |
| 文档处理 | 格式解析、内容抽取、分段、版式还原、文件导出 | 必做 |
| 术语库 | 企业术语、行业术语、项目术语、禁译词、强制译法 | 必做 |
| 模型管理 | 模型接入、参数配置、限流、调用统计、启停状态 | 必做 |
| 用户权限 | 用户、角色、组织、菜单权限、数据权限 | 必做 |
| 统计报表 | 字符数、文档数、任务量、用户用量、模型成本 | 必做 |
| 审计日志 | 登录、上传、下载、翻译、配置变更、异常记录 | 必做 |
| 翻译记忆 | 历史译文复用、相似片段召回、一致性增强 | 二期增强 |
| 审校工作台 | 原文译文对照、人工修改、批注、版本对比 | 二期增强 |
| 质量检查 | 漏译、数字错误、术语不一致、格式异常、敏感词检查 | 二期增强 |
| API 开放 | 接口调用、应用鉴权、回调通知、调用额度 | 二期或三期 |
第一期的目标不是“大而全”,而是让平台具备可交付、可管理、可运行的产品基线。
四、业务流程:一项翻译任务如何流转
从业务视角看,一个文档翻译任务可以抽象为以下流程。
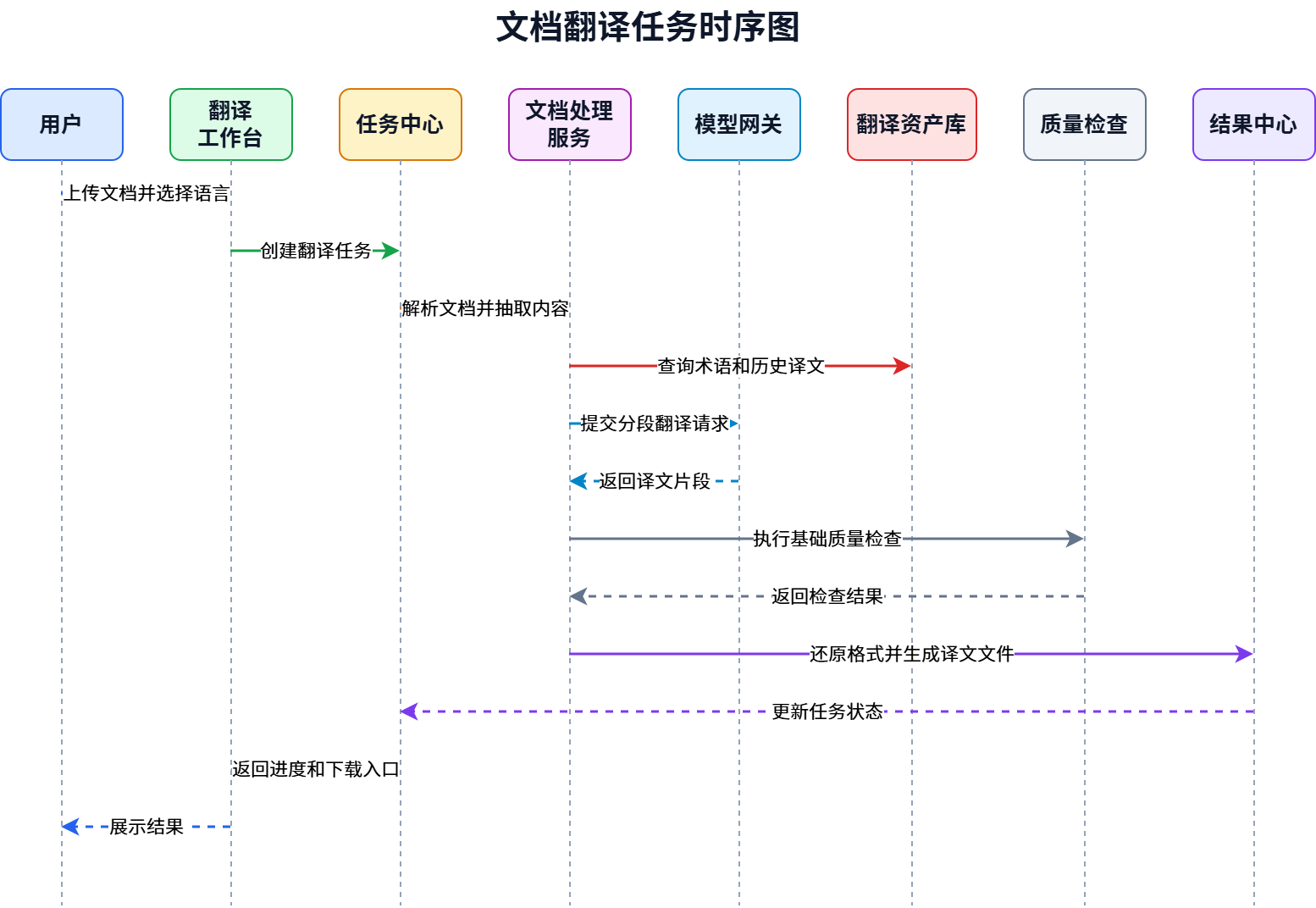
这个流程说明了一个关键点:模型只是链路中的一环。文档解析、术语召回、任务编排、质量检查、格式还原和结果管理同样重要。
尤其在企业文档翻译中,用户往往无法接受“文字翻译了,但格式乱了”“专业名词前后不一致”“数字单位出错”“任务失败后不知道原因”。这些问题都需要通过平台能力解决。
五、技术架构:业务、文档和模型要解耦
技术架构上,建议采用分层设计。核心原则是:业务系统不要直接绑定某一个模型,文档处理不要散落在业务代码里,耗时任务不要阻塞用户操作。
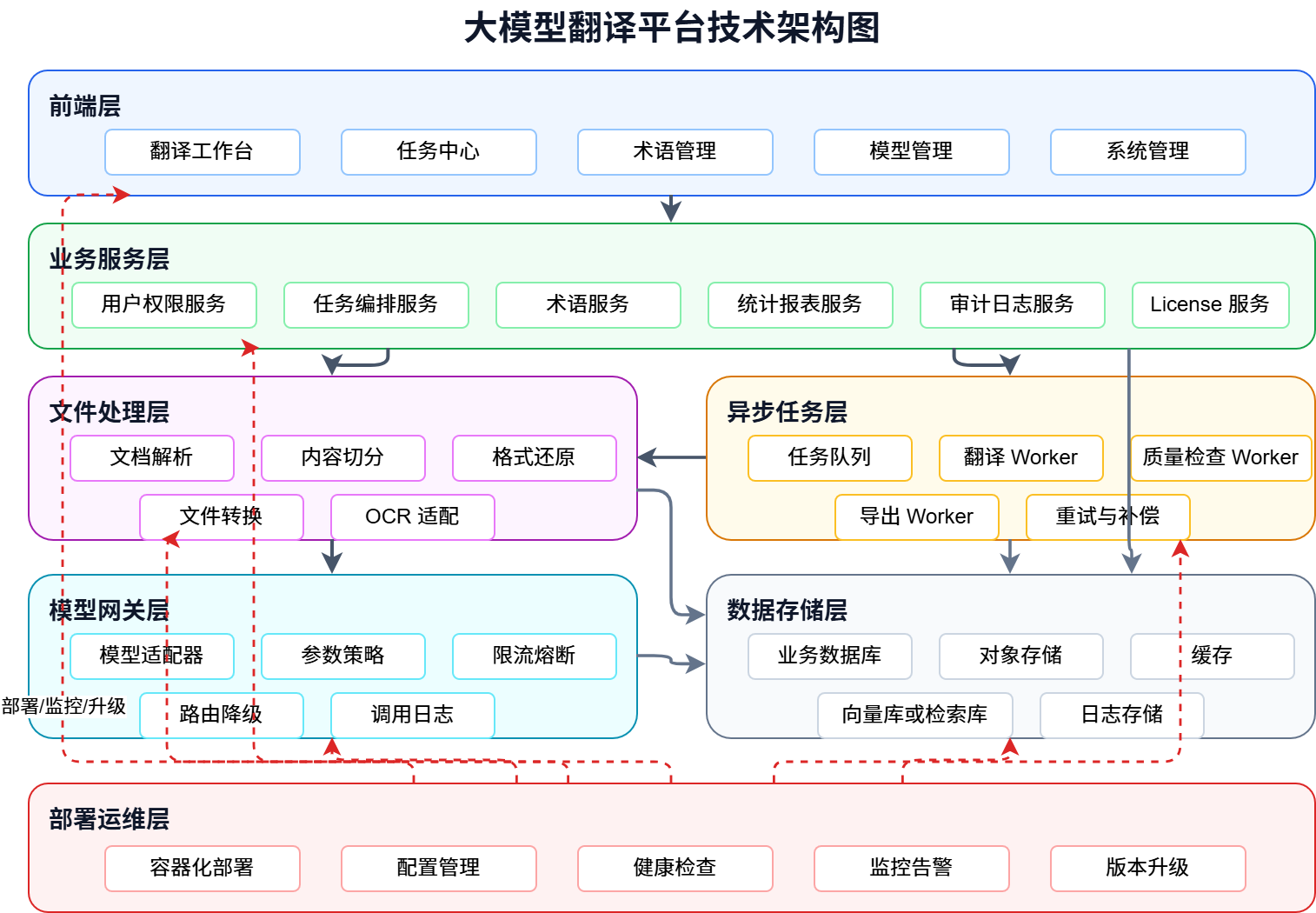
1. 前端层
前端层面向不同用户角色提供操作入口,包括翻译工作台、任务中心、术语管理、模型管理、统计报表和系统管理。
界面设计不宜做成纯聊天式。企业翻译场景需要任务、文件、状态、进度、历史记录和下载结果,因此更适合采用工作台式设计。
2. 业务服务层
业务服务层负责平台主干能力,包括用户权限、任务编排、术语管理、统计报表、审计日志和 License 控制。
这一层是平台自研的核心。它决定平台是否具备商业化交付能力,也决定后续能否支持不同客户的配置和扩展。
3. 文件处理层
文件处理层负责文档解析、内容切分、格式还原、文件转换和 OCR 适配。
文档翻译质量很大程度取决于这一层。模型翻译得再好,如果文档结构丢失、表格错位、标题层级混乱,用户体验仍然不可接受。
4. 异步任务层
长文档、批量翻译、质量检查和文件导出都应该走异步任务。这样可以避免用户长时间等待,也便于做任务进度、失败重试、断点续跑和补偿处理。
5. 模型网关层
模型网关层负责统一接入不同大模型或机器翻译引擎。
业务服务不应该直接调用某一个模型。更合理的方式是通过模型网关完成模型适配、参数配置、限流、熔断、重试、路由、降级和调用日志记录。
这样可以支持客户内网模型、平台内置模型、第三方模型服务和传统机器翻译引擎共存。
6. 数据存储层
数据存储层通常包括业务数据库、对象存储、缓存、向量库或检索库、日志存储。
业务数据库存用户、权限、任务、术语和配置。对象存储存原文文件、译文文件和中间产物。向量库或检索库可以用于术语召回、翻译记忆和上下文检索。
7. 部署运维层
私有化部署需要考虑容器化、配置管理、健康检查、监控告警、日志排查、版本升级、授权 License 和离线环境支持。
这部分不是附属能力,而是商业化交付能力的一部分。
六、自研还是外采:核心平台自研,基础能力集成
大模型翻译平台不应该什么都自研,也不应该什么都外采。判断标准是:是否构成平台主干,是否决定客户体验,是否影响长期可控性。
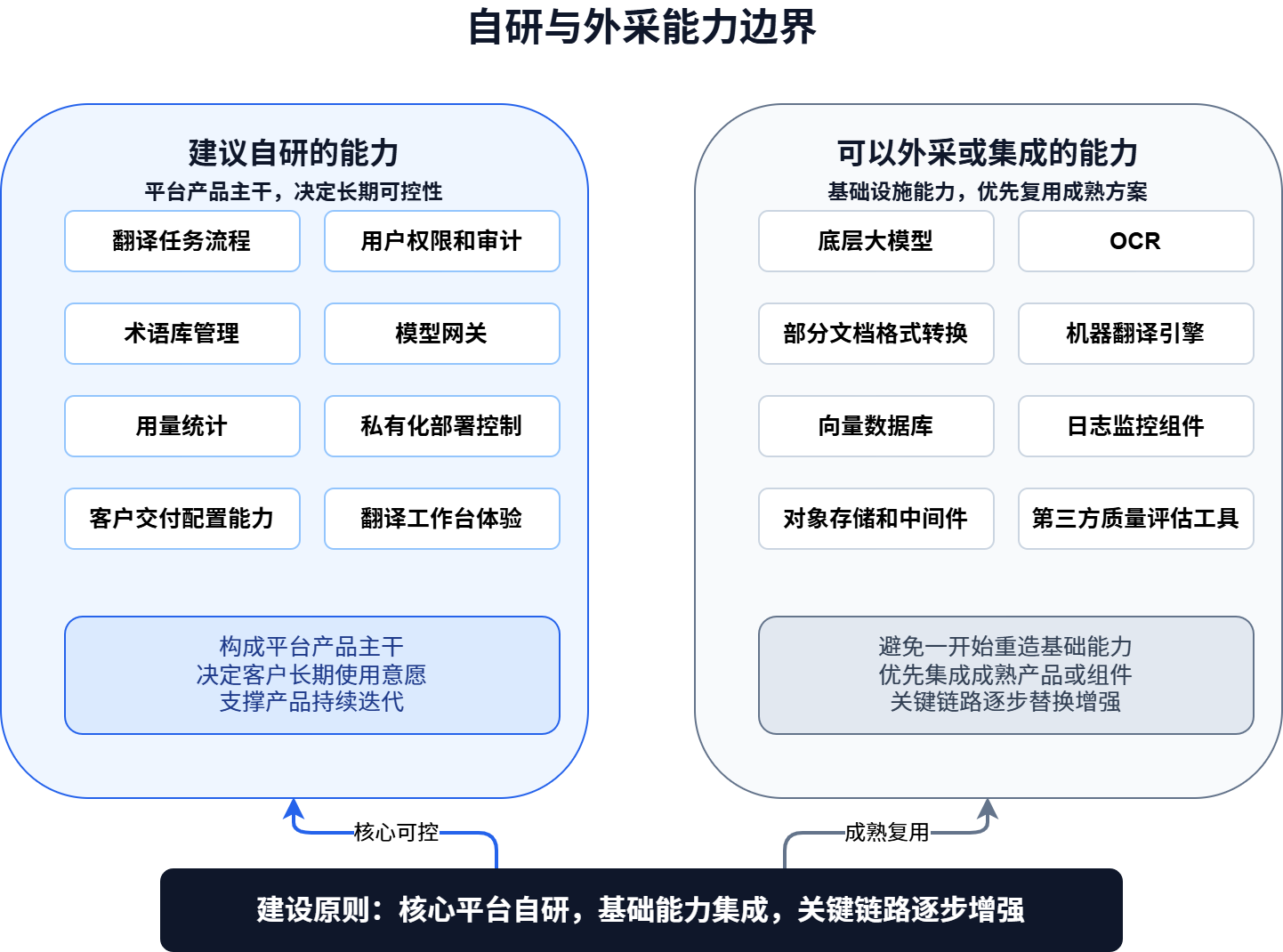
建议自研的能力:
- 翻译任务流程
- 用户权限和审计
- 术语库管理
- 模型网关
- 用量统计
- 私有化部署控制
- 客户交付配置能力
- 翻译工作台体验
这些能力构成平台的产品主干。它们决定客户是否愿意长期使用,也决定平台能否持续迭代。
可以外采或集成的能力:
- 底层大模型
- OCR
- 部分文档格式转换
- 机器翻译引擎
- 向量数据库
- 日志监控组件
- 对象存储和中间件
- 第三方质量评估工具
不建议一开始就自研大模型,也不建议把全部文档解析能力从零开始做完。更务实的方式是:核心平台自研,基础能力集成,关键链路逐步替换和增强。
七、建设节奏:先基线,再生产,再生态
平台建设可以分为三个阶段。
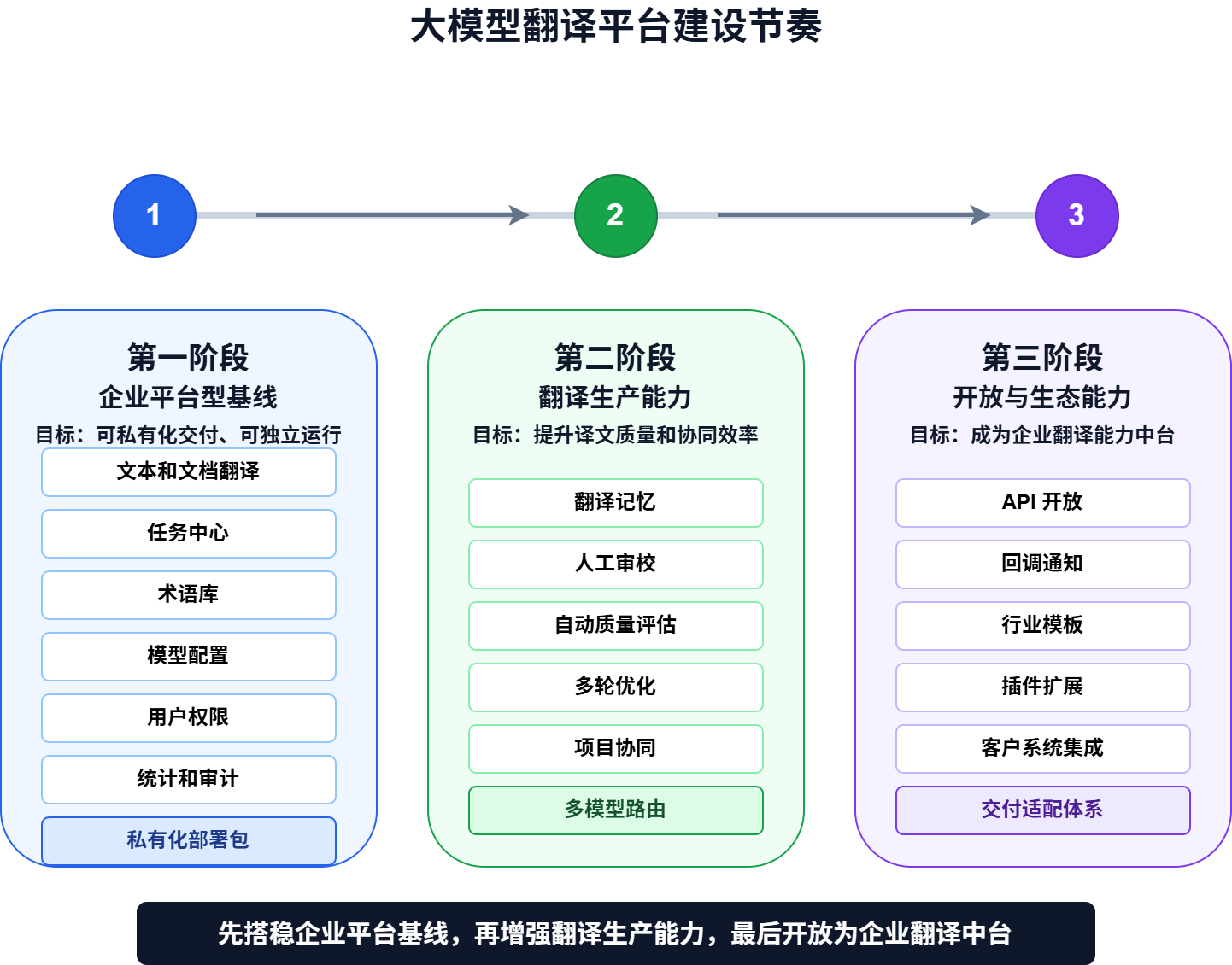
第一阶段:企业平台型基线
目标是让平台能在客户私有化环境中独立运行,完成文本和文档翻译,支持模型配置、术语管理、任务记录、用户权限、统计和审计。
这一阶段要解决“能不能作为商业平台交付”的问题。
第二阶段:翻译生产能力
在基线稳定后,加入翻译记忆、人工审校、自动质量评估、多轮优化和项目协同。
这一阶段要解决“能不能生产高质量译文”的问题。
第三阶段:开放与生态能力
在平台能力成熟后,再开放 API、回调、插件、行业模板和客户系统集成能力。
这一阶段要解决“能不能成为企业翻译中台”的问题。
不同客户需要的登录集成、组织同步、页面嵌入、业务系统对接等能力,也更适合放在这一阶段或交付适配层中处理,而不是一开始就写死在产品基线里。
八、结语
大模型翻译平台的建设,真正要打开的是平台视角。
它不是一个页面,也不是一个模型调用接口,而是一套企业内容翻译的基础设施。业务上要围绕内容、任务、资产和治理来组织;技术上要围绕文档处理、模型网关、异步任务和私有化部署来设计;建设策略上要区分自研主干和外采能力。
一句话概括:
核心平台要自研,底层能力可集成;业务基线要稳定,客户适配要灵活;先把平台骨架搭对,再逐步提升翻译质量和交付深度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)