告别Token焦虑!2026年AI Agent元年的10个参数,助你选对模型,效率起飞!
随着2026年被视为AI agent元年,选择合适的AI模型变得尤为重要。本文作者结合自身经验,分享了选择AI模型的10个关键参数,帮助读者从词元焦虑中解脱,实现效率起飞。文章主要涵盖模型智商(推理能力、响应速度、思考深度)、智能切换机制、成本与Token消耗、本地文件读写能力、网络搜索能力、自动化执行能力、记忆与进化机制以及隐私保护等维度,为普通人选择AI提供了实用、可操作的框架。同时,强调了模型选择的重要性,并提醒读者没有完美的模型,只有适合的模型,判断力才是核心。
2026年被认为是AI agent元年,你是否感到Token 焦虑?从词元焦虑到效率起飞,我总结了 AI 模型选择 10个参数,也许对你有用。
另外,你是否有云端模型 vs 本地模型的困惑?普通人选AI,不妨看本文8个维度。

我不是程序员,但对AI特别感兴趣。过去几年,我折腾过几十款AI工具。最早跟ChatGPT闲聊,2023年学习comfyUI,部署本地模型文生视频,到今年用OpenClaw、Hermes这类Agent工具自动化处理工作流,踩过不少坑。
一是盲目崇拜全球顶流: 包括Claude Opus4.X、GPT5.X、Gemini 3.X,都用过,贵,要花真金白银,还要有复杂的上网技巧,劝退普通人;
二是迷信本地模型迷信: 后来想节省token,尝试在本地跑各种模型。结果,本地小模型又傻又犟,完不成任务却擅长给自己找借口。并且本地模型容错能力差,很容易跑偏。唯一的亮点:本地的gemma4:e4b模型,作心理咨询相当出色,效果超过很多网络大模型,这一点以后讲。
三是Agent 崩溃: 使用一些Agent 工具,比如openclaw等,由于软件最初的不完善,模型指令遵循能力不足,Agent很容易陷入死循环,一天之内可以烧掉了价值几千万 Token,费用高却没解决问题。
折腾这么久,最大的感悟,就是选模型这件事,其实也是个技术活。 模型选错了,轻则花冤枉钱,重则把重要任务搞砸。
网上有大量专业测评——MMLU、HumanEval、MATH这些 benchmark 跑分,听着就很技术宅。我们普通人没精力去研究这些,但我们需要一个简单、实用、可操作的选模型框架。
这篇文章,就是我花了大半年时间、烧了不知道多少token之后,沉淀下来的普通人选AI的8个维度。
一、模型智商:推理能力、响应速度、思考深度
这是最核心的能力,三者缺一不可。
推理能力决定模型能不能"想清楚",响应速度决定你愿不愿意等,思考深度决定输出质量的上限。
评分标准如下表:
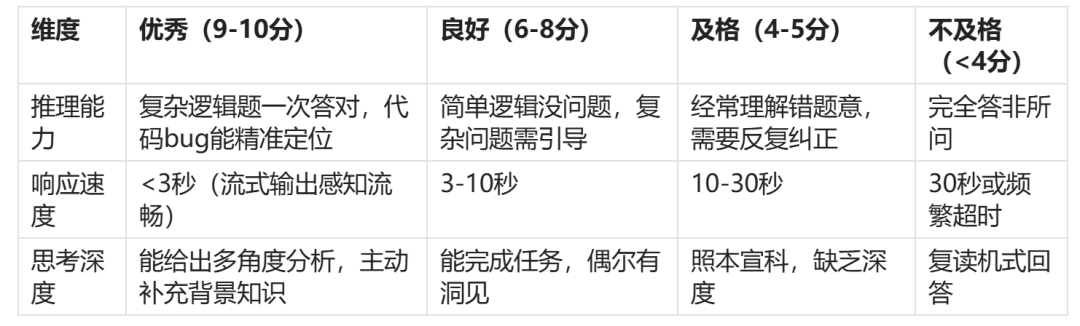
实测方法
简单推理能力测试:
1、老师让同学们阅读一本名著,小A每天读60页,比老师规定的时间提前一天读完;小B每天读40页,比老师规定的时间晚了2天。请问,这本名著有多少页?
2、有四个字数,取其每三个而相加,则其和分别为28、 24、 27 和 20。求这四个数各是多少?
3、用上一题的答案,4个数字,做一个游戏:让这四个数字通过四则运算组成24,你怎么做?
4、5个小偷分100个金币,假设每个人都非常自私,追求利益最大化。分配规则是:5个人抓阄,按顺序分配,其中1号最先提出分配方案,只有达到一半的人同意方案,就通过并实施;否则,一号一无所有,然后由2号分配,如果类推,直到最终方案通过。每个人可以同意自己的方案。请问:1号如何分配可以实现自己的利益最大化?为什么?(注:分配方案修改一下,如果是超过一半同意,结果有所不同)
5、沙漠里,我有两杯水,一杯毒药,一杯尿,这里你来了,如果再不喝水就会渴死,你会如何选择?
正确答案:1、360页;2、四个数分别为 11、 9、 6、 10;3、11+9-10-6=24。4、1号分配方案,用倒推法,5号没机会等来分配,如果4号分配,方案是自己100,5号0,如果3号分配,自己99,5号1,如果2号分配,自己98,5号2,如果1号分配,需要得到另外两张投票,而无论如何,都不可能让另外两人利益最大化,因此1号会被决死,最终执行2号的分配方案。5、选择喝水。
此外,还可以找一道你所在领域的专业问题,看模型能否给出准确解答。
响应速度测试:
用上述比较复杂的问题测试云端模型和本地模型,记录从回车到看到第一个字的时间。
思考深度测试:
问一个开放式问题:「恒大为什么会失败,许家印做错了什么,哪些锅不该由他背?」看回答是泛泛而谈还是有具体案例和数据支撑。
常见误区
❌ 盲目追求模型参数量(130B一定比7B强?不一定)
❌ 只看benchmark跑分(实际使用和跑分是两回事)
❌ 忽略思考深度(能快速回答的不一定是深度回答)
二、智能切换机制
一个好的agent系统知道什么时候该派什么模型上场。
这考验的是Agent工具本身的编排能力,不只是模型能力。
评分标准
| 等级 | 描述 |
|---|---|
| 优秀 | 自动识别任务复杂度,大模型处理复杂任务,小模型处理简单任务,无需人工干预 |
| 良好 | 提供手动切换选项,有预设规则,但不够智能 |
| 及格 | 支持切换但操作繁琐,或切换逻辑不合理 |
| 不及格 | 只能固定使用一个模型 |
实测方法
- 连续提交5个不同复杂度的任务(从"今天天气怎么样"到"帮我分析这份财报")
- 观察系统是否自动调度了不同模型
- 检查是否在保证质量的同时节省了成本
三、成本与Token消耗
不是越便宜越好,也不是越贵越强。要花对钱。
评分标准
| 维度 | 说明 |
|---|---|
| 性价比 | 每万 token的实际产出价值 |
| 定价透明度 | 是否清晰易懂,有无隐藏费用 |
| 免费额度 | 新用户免费token数量 |
| 本地模型成本 | 硬件投入vs实际使用频率 |
主流模型价格参考(2026年数据,详见第五点:网络搜索能力)
成本优化策略
任务分级:
- 简单任务(翻译、格式化)→ 便宜模型
- 中等任务(写文案、分析)→ 中等模型
- 复杂任务(代码调试、策略分析)→ 顶级模型
本地模型适合: - 日常轻度使用(每天<2小时)
- 有隐私要求的场景
- 特定领域任务(垂直领域微调模型)
四、本地文件读写能力
这是生产力的分水岭。
能读文件才能处理工作流,能写文件才能真正自动化。
评分标准
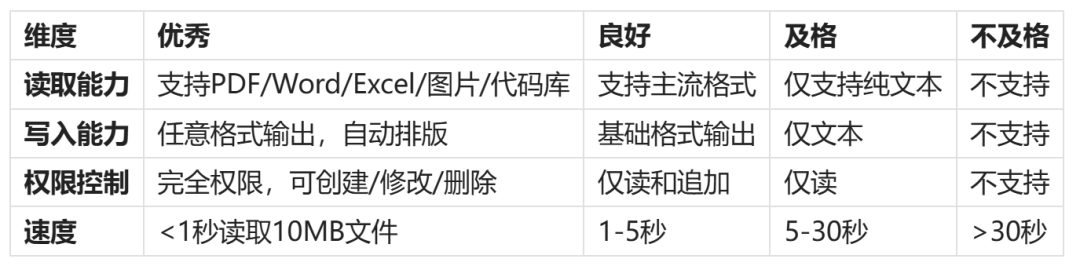
实测方法
- 上传一份100页PDF,问:「第三章的核心观点是什么?」
- 上传一份Excel表格,问:「计算A列的总和」
- 要求生成一份Markdown格式的报告,检查排版
工具推荐
OpenClaw:文件读写能力强,支持多种格式
Cherry Studio:本地知识库功能不错,适合文档处理
AnythingLLM:专注文档理解,优化PDF解析
五、网络搜索能力
不能联网的AI,就像没有地图的导航。
评分标准
| 维度 | 说明 |
|---|---|
| 搜索质量 | 能否找到最新、最相关的信息 |
| 信息整合 | 能否将多个来源的信息整合成完整答案 |
| 引用透明 | 是否标注信息来源,方便核实 |
| 时效性 | 能否获取最新新闻和数据 |
实测方法
问一些时效性问题:
-
「最新国际新闻」
-
「最近一个月AI领域有什么重大突破」
-
「openclaw最新版本是多少,有哪些新特性」
-
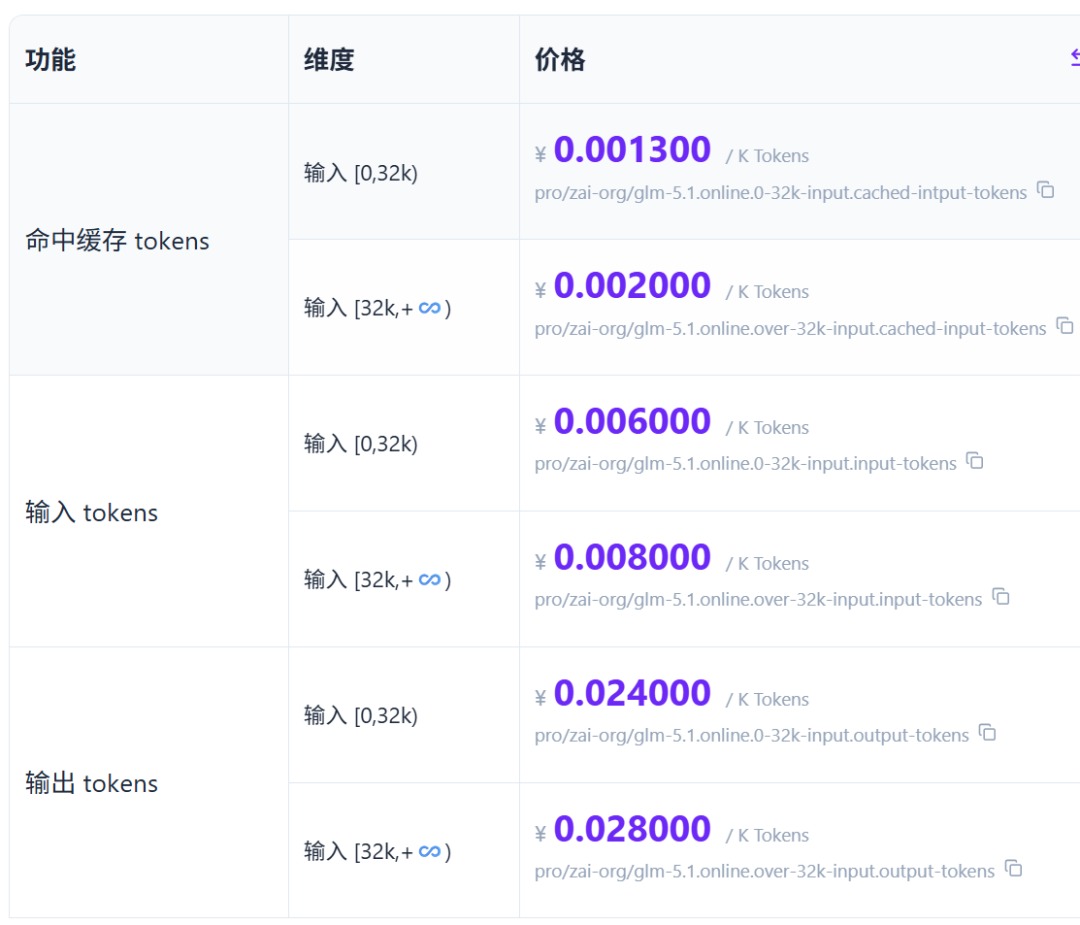
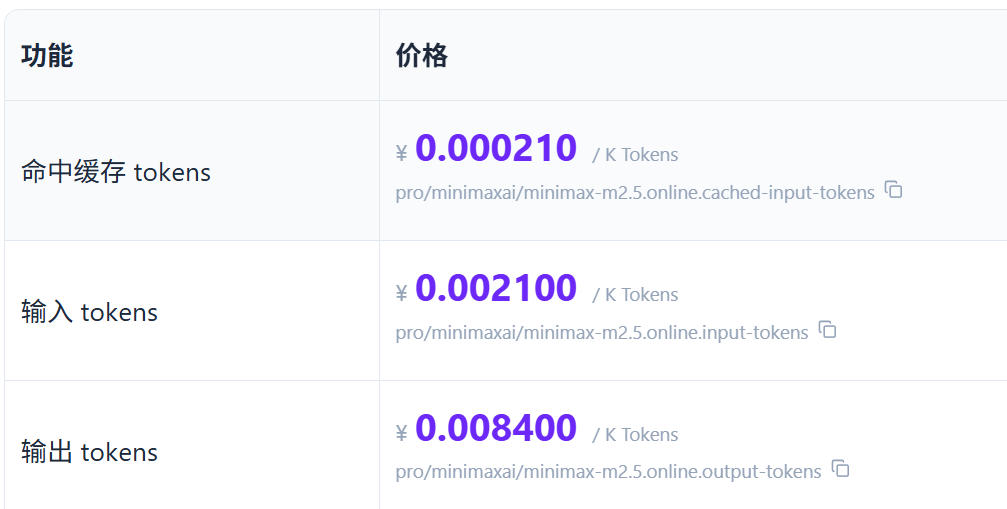
「你去硅基流动网站看一看,帮我查一下这几个大模型的价格,包括命中缓存 tokens、输入 tokens、输出 tokens,以及其他相关的重要信息。模型有:Kimi K2.6 、GLM-5.1 、MiniMax-M2.5、DeepSeek-V3.2、Qwen3.6-35B-A3B。最后输出一个表格给我。」
案例:以下为workbuddy在4月22日给我返回的结果: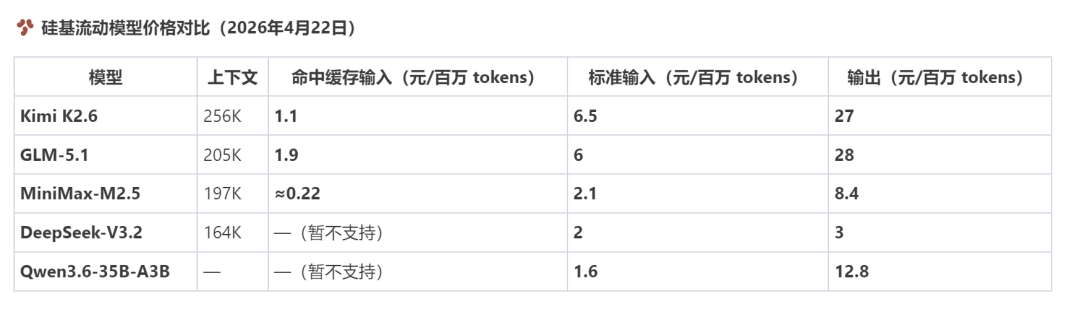
人工检查结果如下:
1、kimi k2.6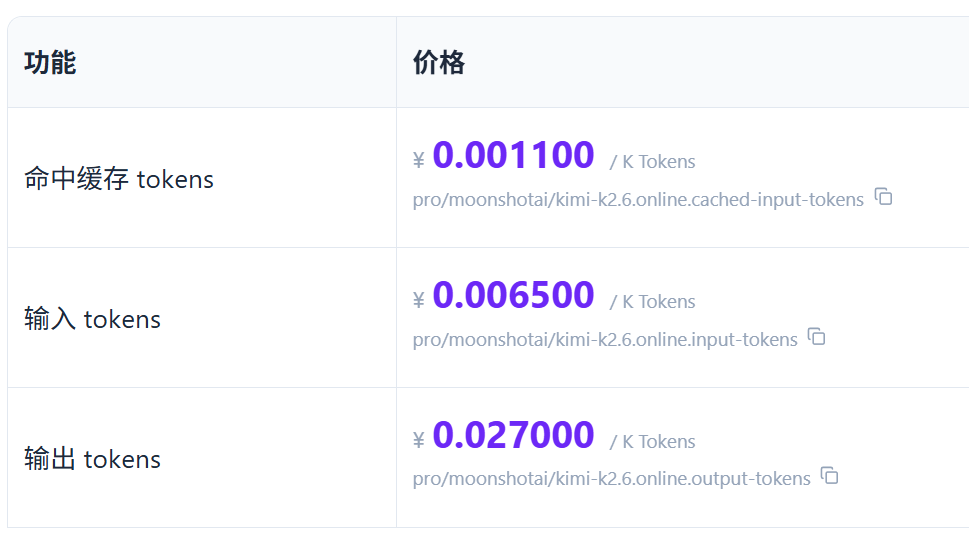
2、GLM-5.1
3、MiniMax-M2.5
4、DeepSeek-V3.2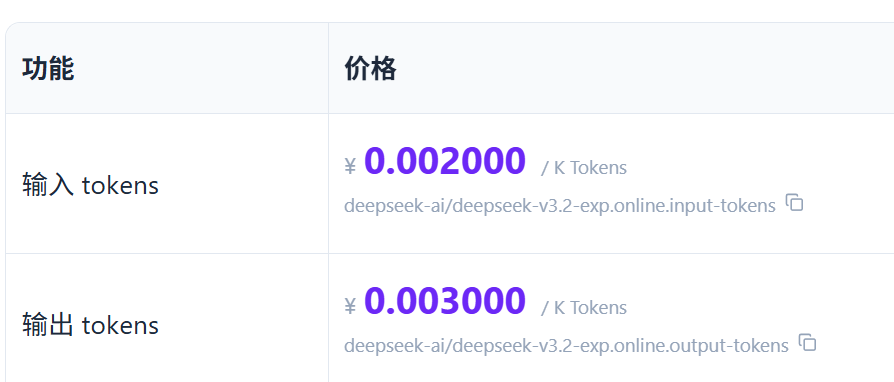
5、Qwen3.6-35B-A3B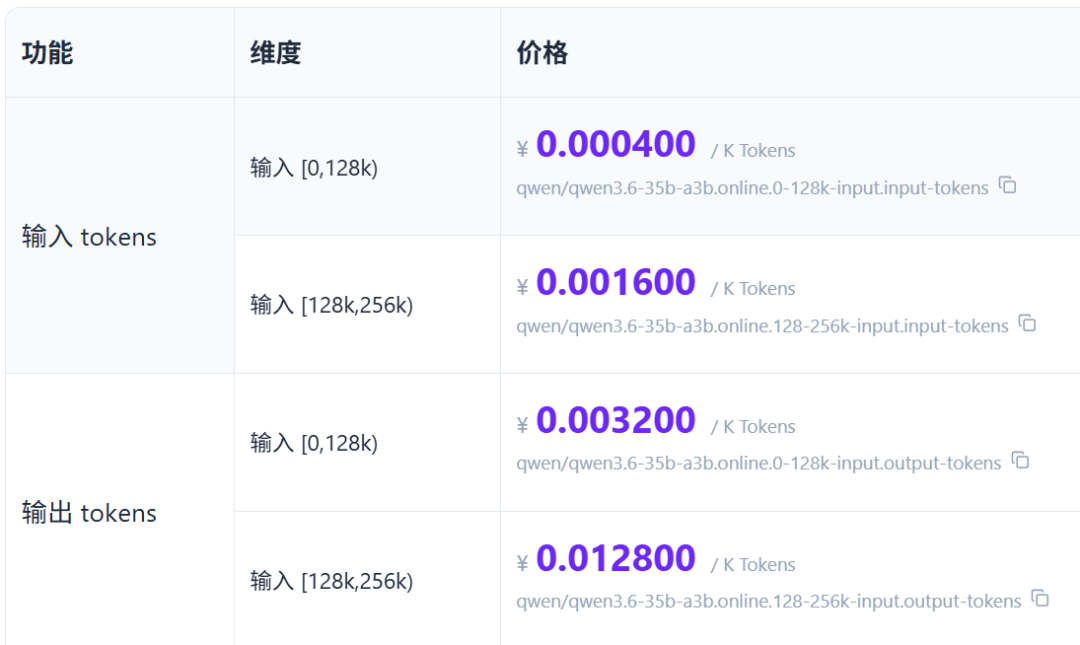
看回答是否包含具体数据、来源链接,以及是否正确。最后一个问题,就是测试agent及大模型网络查询能力的照妖镜。
经测评,workbuddy网络查询能力出色,准确论90%,只有GLM5.1多一个维度,分32k内以及超过32k两种情况,这一点没有反应出来。
六、自动化执行能力
能自动干活才是真AI Agent。
评分标准
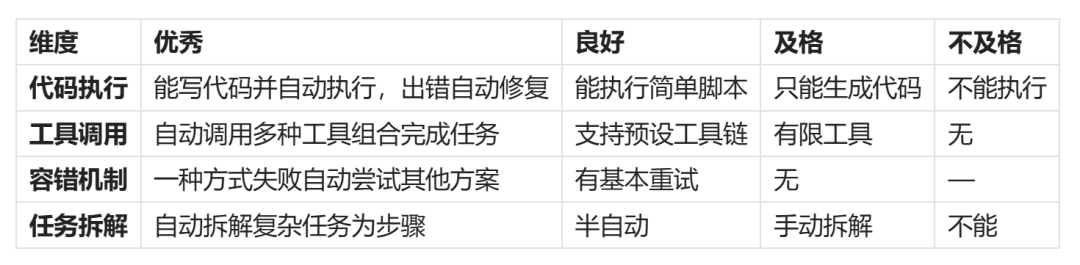
实测方法
- 布置一个多步骤任务:「帮我把这份CSV转成Excel,加个汇总图表,然后发到邮箱」
- 布置一个可能失败的任务,测试容错能力:
- 观察是否主动规划执行路径
案例:分别给workbuddy提供2025年、2026年两份同一项目的招标文件,请它对比这两份文件的不同点,尤其注意有哪些涉及废材内容,它于是调用了14个工具,最后输出建议。

两份招标文件基本性质差异: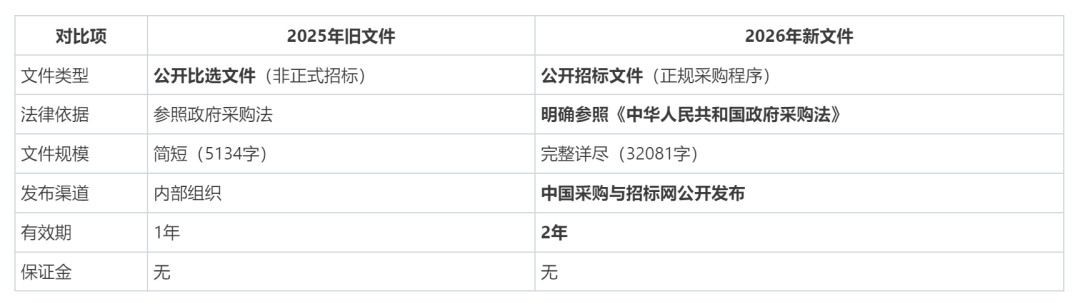
除了列举重大废标风险点,还特别提醒评分规则的变化: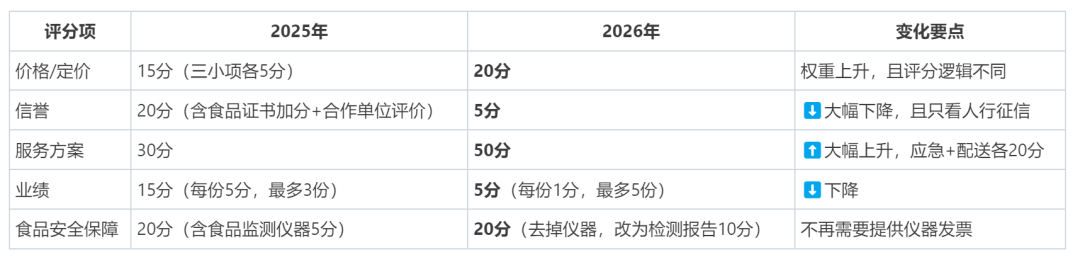
经测评,workbuddy的自动化能力出色,以往一个熟练的标书专员要工作两小时以上的工作,现在由workbuddy在10分钟以内可以完成。
七、记忆与进化机制
记不住你的AI,永远只是工具,不能成为助手。
评分标准
| 维度 | 说明 |
|---|---|
| 短期记忆 | 当前会话中的上下文保持能力 |
| 长期记忆 | 跨会话记住用户偏好和习惯 |
| 学习能力 | 能否从错误中学习,主动优化 |
| 积极遗忘 | 无关信息能否自然淘汰 |
实测方法
- 短期记忆测试:在一次长对话中,第20轮提到第1轮的信息,看是否还记得
- 长期记忆测试:隔天再对话,看是否还记得昨天的偏好设置
- 学习能力测试:故意纠正一个错误,看下次是否会修正
实现方式
本地方案:
- 通过文件存储记忆(OpenClaw支持)
- 向量数据库(如ChromaDB)存储偏好
云端方案: - 各平台的记忆功能(ChatGPT的Memory、Claude的Projects)
八、隐私保护
你的数据,比你想象的更值钱。此外,莫名其妙被推送的广告,也令人心烦。
评分标准
| 维度 | 说明 |
|---|---|
| 数据政策 | 是否默认不上传本地数据 |
| 匿名处理 | 对话是否用于模型训练可控制 |
| 本地优先 | 能本地处理就本地处理 |
| 透明度 | 隐私政策是否清晰易懂 |
实测方法
- 查看设置中「是否用于模型训练」的默认选项
- 询问客服数据存储和删除政策
- 测试敏感信息(身份证号、公司机密)是否安全
隐私优先方案
| 方案 | 特点 |
|---|---|
| 完全本地 | Ollama + 本地模型,零上传 |
| 隐私模式 | Claude/ChatGPT关闭训练选项 |
| 隐私浏览器 | DuckDuckGo + AI,保持匿名 |
综合评分表
将以下10个参数做成一个Excel表格,自己打分:
| 序号 | 维度 | 权重 | 得分(1-10) | 加权分 |
|---|---|---|---|---|
| 1 | 推理能力 | 25% | ||
| 2 | 响应速度 | 15% | ||
| 3 | 思考深度 | 15% | ||
| 4 | 智能切换 | 10% | ||
| 5 | 成本控制 | 10% | ||
| 6 | 文件能力 | 10% | ||
| 7 | 联网能力 | 5% | ||
| 8 | 执行能力 | 5% | ||
| 9 | 记忆进化 | 3% | ||
| 10 | 隐私保护 | 2% |
总分 = Σ(权重 × 得分)
最终,您的结论是:
友情提示:没有完美的模型,只有适合你的模型。
最后送大家一句话:模型是工具,判断力是核心。 搞清楚自己真正需要什么,比追新追热重要一百倍。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献164条内容
已为社区贡献164条内容

所有评论(0)