视觉模型中的坐标漂移
之前提过,我们搞了个企业级知识库系统,结果文档解析时总出幺蛾子——时不时就报错"解析失败"。我这人对 Bug 的容忍度基本为零,决定死磕到底。
明明文档内容清晰得像刚打印出来的,系统却一口咬定"提取失败"。
排查了半小时,日志翻得眼睛都快瞎了,最后发现一个让我当场愣住的事实:
那些边界框坐标,全偏移了!
不是随机乱偏,而是系统性地向右下方整体漂移。就像有个看不见的手,把所有文本框往右下角推。有的偏移几像素,有的几十像素,结果裁剪出来的图片要么切掉半个字,要么框住一堆空白。
我当时就懵了:这玩意儿不是 OCR 吗?OCR 不是最擅长像素级定位文本的吗?怎么连个框都框不准?
花了一整天把整个技术栈扒了个底朝天,才发现这事儿远比我想象的离谱。
你以为的 OCR vs 实际上的混合流水线
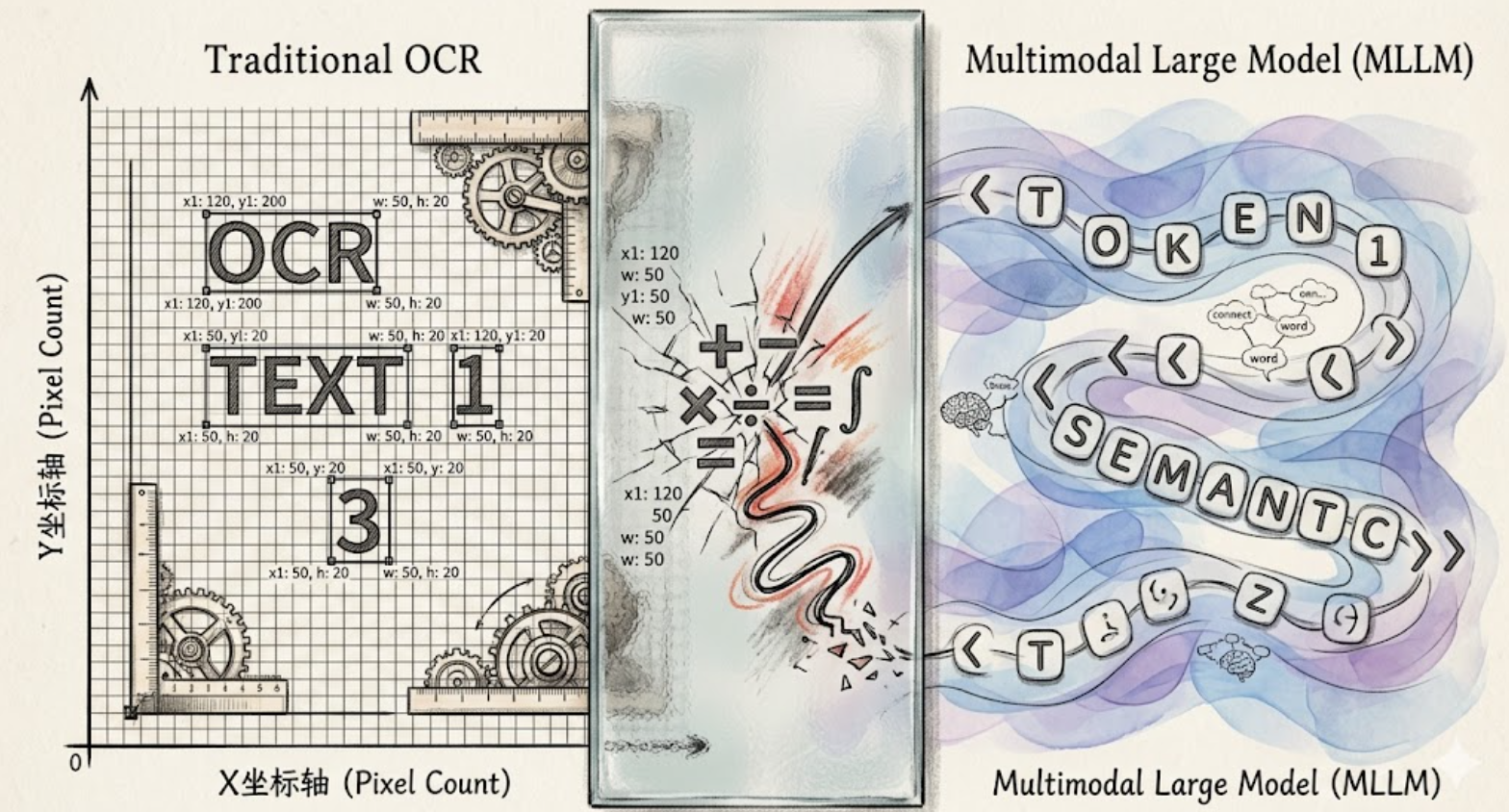
先说个你可能没意识到的事实:现在市面上大部分高大上的"智能文档解析系统",根本不是单一模型在干活,而是 传统 OCR 引擎 + 多模态大模型(MLLMs/VLMs) 的混合体。
-
传统 OCR(比如 PaddleOCR、Tesseract):跑在连续的二维几何空间里,优先考虑的是极其精确的像素级定位,直接告诉你"这里有个词,坐标是
[xmin, ymin, xmax, ymax]"。 -
大语言模型/多模态模型(LLM/MLLM):跑在离散的一维自回归 Token 空间里,优先考虑的是语义流畅性和上下文推理。
当这两种系统被迫进行数据交换时——不管是 OCR 生成边界框喂给 LLM,还是让多模态大模型原生生成空间坐标——冲突立马就来了。
那个让你崩溃的"坐标轴整体漂移",其实是中间集成层在做数学题时,踩中了三个极其隐蔽的架构大坑。
坐标漂移的幕后黑手:三大架构坑逐一解密
坑一:云端大模型 API 的"不透明缩放错觉"
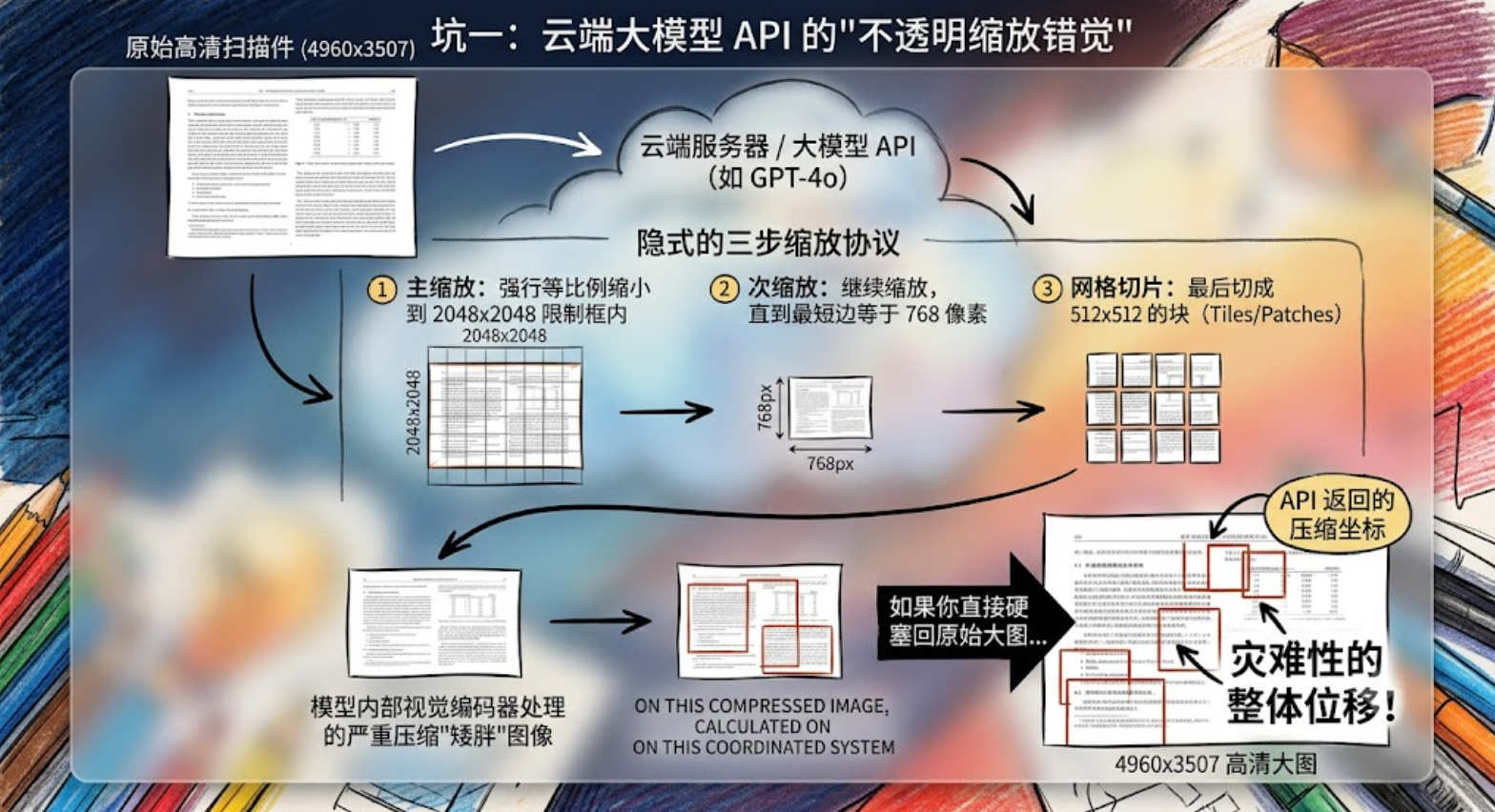
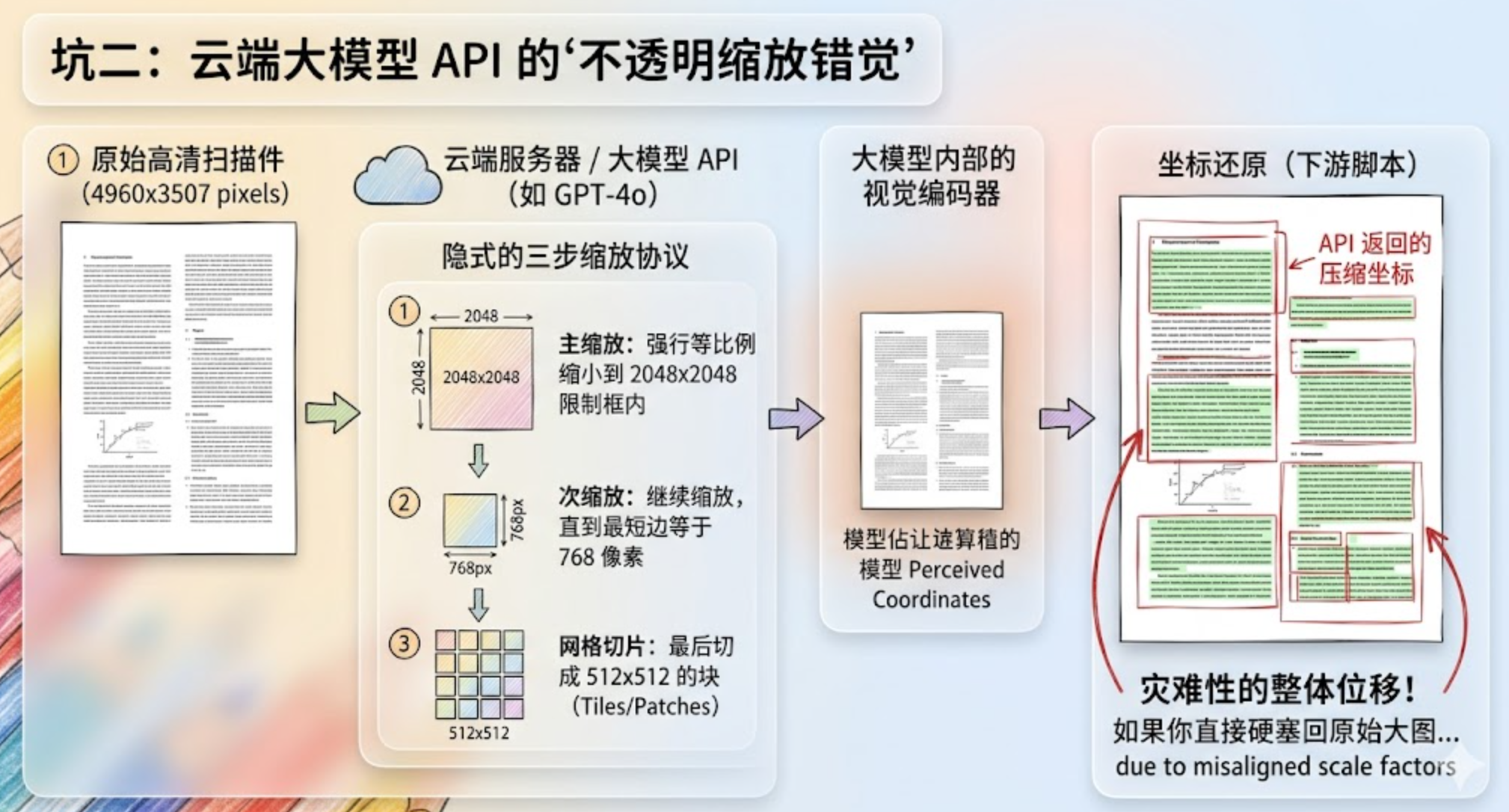
如果你调用的是云端生成式 AI 的视觉 API(比如 Azure OpenAI 的 GPT-4o 或类似模型)来原生提取坐标,那这个系统性偏移几乎是必然的。
你以为大模型看的是你上传的那张 4960x3507 像素的高清扫描件吗?根本不是!
云端服务器在把图片喂给模型前,有一套隐式的三步缩放协议:
-
主缩放:强行等比例缩小到 2048x2048 的限制框内。
-
次缩放:继续缩放,直到最短边等于 768 像素。
-
网格切片:最后切成 512x512 的块(
Tiles/Patches)。
大模型内部的视觉编码器,实际处理的是那张被严重压缩的"矮胖"图像,并在压缩后的坐标系上计算出边界框。当 API 把这些坐标以字符串形式返回给你时,如果你直接硬塞回原始高清大图上,由于缩放系数没对齐,边界框就会完全脱离实际文本区域,形成灾难性的整体位移!
坑二:本地视觉 Transformer 的"信箱模式与 Y 轴漂移"
就算不用云端 API,自己本地部署开源多模态大模型(比如 Qwen-VL 或 LayoutLM 这种布局感知模型),也逃不过几何维度的毒打。
大多数视觉 Transformer(ViT)被设计为处理固定的方形输入(比如 或 )。但我们上传的 A4 纸、发票全是典型的长方形文档。为了防止图像被拉伸变形,预处理流水线必须保持原始长宽比,于是在较短的一侧(通常是上下两侧)添加灰黑色的像素填充,强行补成正方形——这就叫**"信箱模式"(Letterboxing)**。
多模态大模型是基于这个带了黑边的正方形大空间去计算边界框的。如果下游的集成层脚本在把坐标还原回去时,没有极其精确地减去垂直或水平方向的填充偏移量,这个纯计算产生的黑边高度就会被永久性地引入到输出坐标中。
-
结果就是:X 轴可能挺准,但 Y 轴发生了整体上移或下移的系统性漂移!
坑三:分词器的"空间重叠与碎片化伪影"
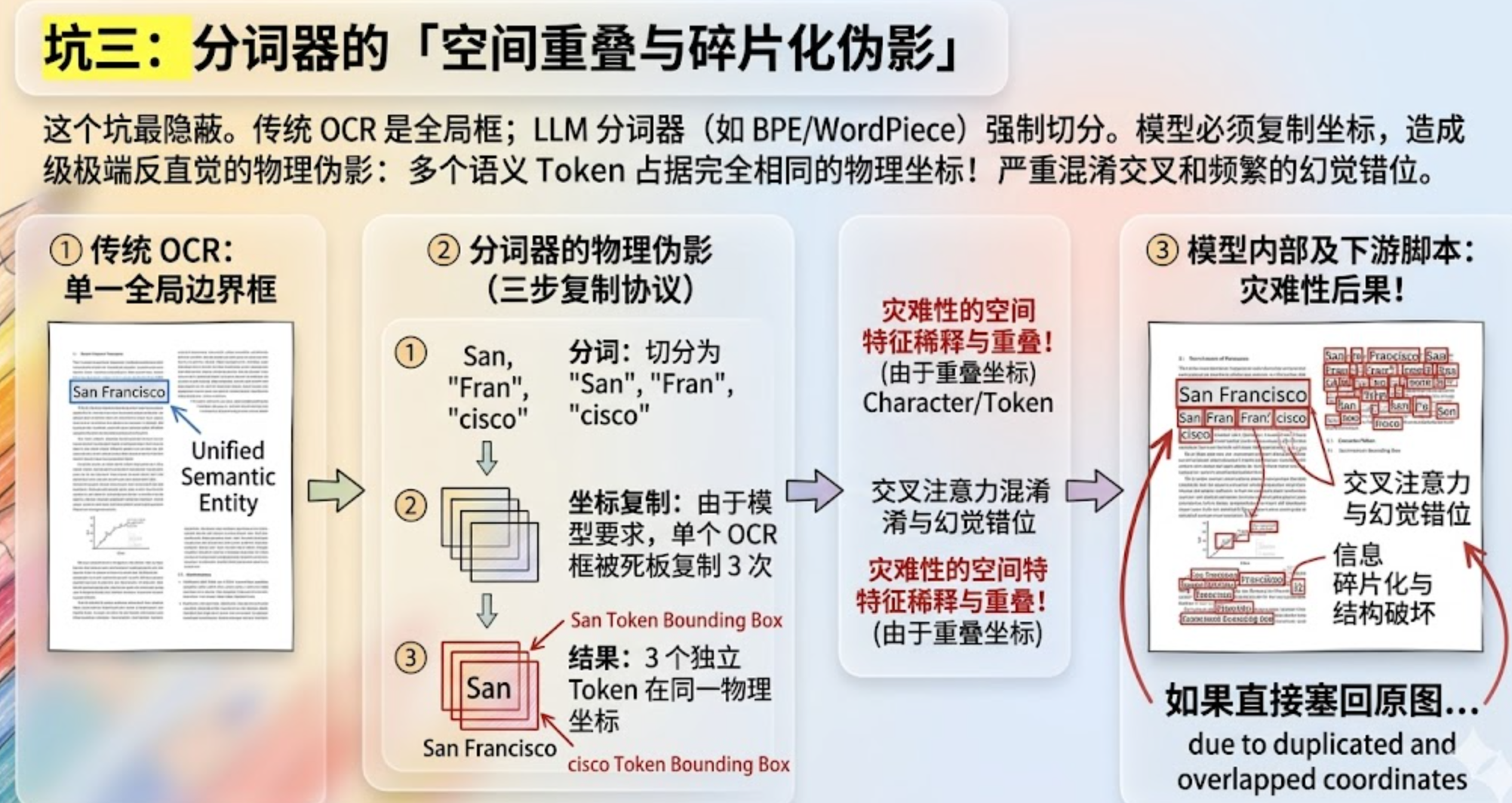
这个坑最隐蔽。
传统 OCR 引擎通常在字符或单词级别操作,一个完整的专有名词(比如 "San Francisco")只会生成一个统一的全局边界框。
但大语言模型用的是基于子词(Sub-word)的分词器(比如 BPE 或 WordPiece),它会把这个词强制切分成 "San", "Fran", "cisco" 3 个独立的 Token。由于模型要求每个输入的语言 Token 都必须拥有对应的空间嵌入,唯一的妥协方式就是把这单个 OCR 边界框强制复制 3 次,死板地强加在 3 个子词上。
这就产生了一个极端反直觉的物理伪影:在模型的高维空间里,多个不同的语义实体竟然占据了完全相同的物理坐标!
这种"空间重叠"会严重混淆大模型的交叉注意力层。当模型尝试输出结构化数据时,空间特征被稀释、破坏,直接导致信息碎片化和频繁的幻觉错位。
业界对齐坐标的"四大标准协议"
既然坑这么深,业界是怎么强制实现坐标对齐、彻底消除边界框异常的?我把目前最前沿的工程标准给你理出来了:
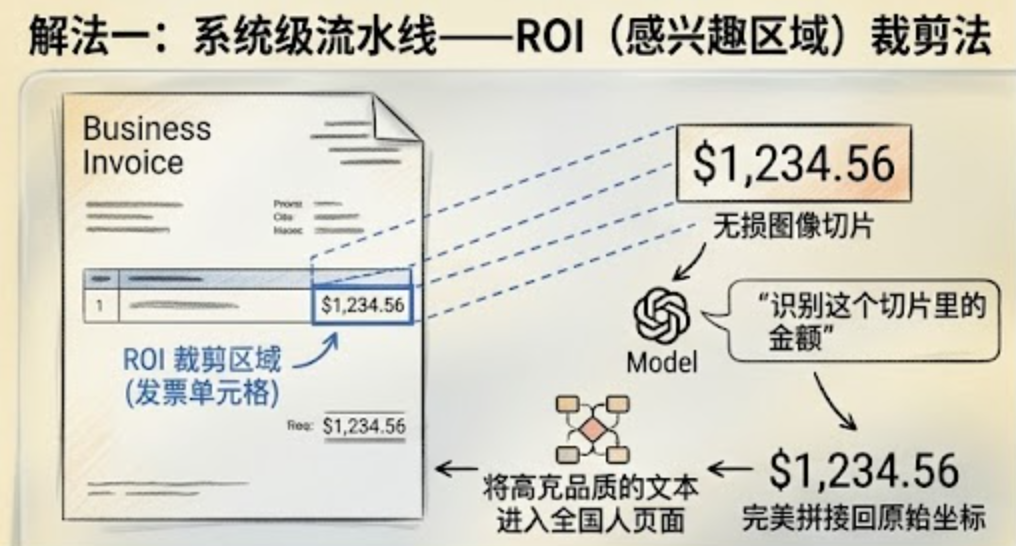
解法一:架构解耦——"先检测,后提示"的混合路由策略(最稳妥)
别盲目指望大模型同时干两件事:密集的"像素级定位" + 深度的"语义推理"。
目前企业级生产流水线的绝对标准是三阶段解耦:
-
底层空间锚定:先部署轻量、高精度的专用 OCR(比如 PaddleOCR),扫描全图,生成绝对不可更改的底层像素地图。
-
感兴趣区域提取(ROI 裁剪):基于 OCR 的精准坐标,直接从高分辨率原图中几何裁剪出特定区块(比如发票单元格、签名区),完好保留像素特征。
-
定向语义推理:只把这些无损的图像切片独立发给大模型,配上专注的提示词(比如:"识别这个切片里的金额")。
-
核心思路:让大模型彻底卸下追踪全局物理坐标的沉重负担。最后,由编排系统把大模型返回的高质量文本,完美拼接回第一阶段生成的固定坐标里。
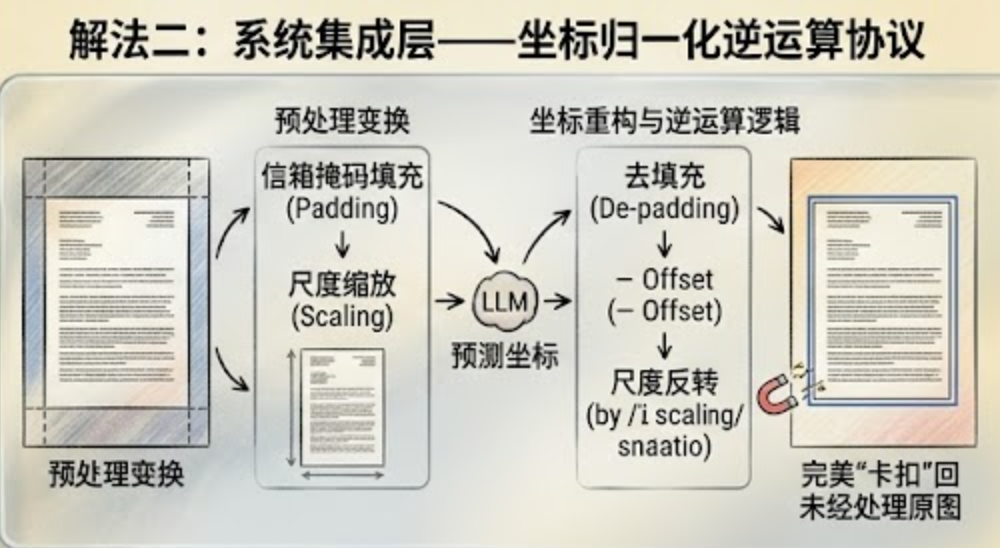
解法二:系统集成层——坐标归一化逆运算协议
如果你必须用端到端的视觉大模型,那就必须在系统集成层(Integration Layer)确立极其严格的坐标重构与逆运算逻辑。
你必须精确记录图像输入模型之前的每一次预处理变换参数:
-
**先执行"去填充(De-padding)"**:从预测坐标中扣除信箱掩码强加的水平/垂直偏移量()。
-
**再执行"尺度反转"**:除以缩放系数(Scale Ratio),还原到原始分辨率。
通过强制性的几何逆运算,让最终的边界框如同磁吸一般,完美"卡扣"回用户上传的未经任何处理的原图上。
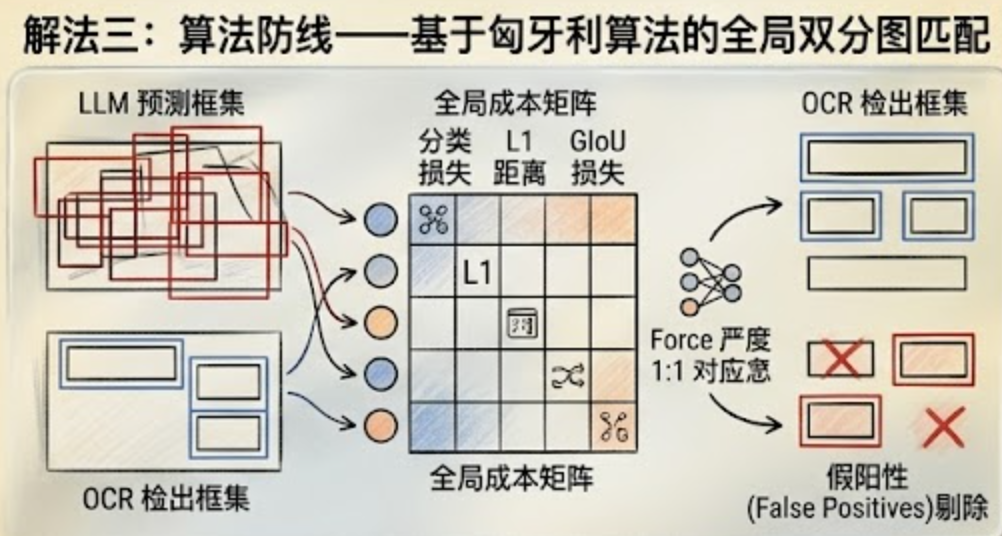
解法三:算法防线——基于匈牙利算法的全局双分图匹配
如果你的流水线里同时有两套边界框(比如底层 OCR 检出了一套,顶层布局大模型基于上下文也预测了一套),两者冲突、重叠了怎么办?千万别用传统的 NMS(非极大值抑制),那会错误丢弃高密度的相邻文本框。
业界标准协议是采用匈牙利算法(Hungarian Algorithm):
-
将 OCR 真实框集合与大模型预测框集合视作图论中的两个不相交节点集,构建一个全局成本矩阵。
-
成本矩阵结合了分类损失、L1 绝对距离损失以及 GIoU(广义交并比)损失(专门用来严厉惩罚那些宽高比扭曲的畸变框)。
-
匈牙利算法通过精妙的矩阵规约操作,强制建立严格的 1:1 对应关系,数学上保证排列不变性。对于大模型因为"幻觉"凭空捏造出的、无法与底层 OCR 高质量匹配的预测框,在算法结束时直接当成假阳性(False Positives)无情剔除!
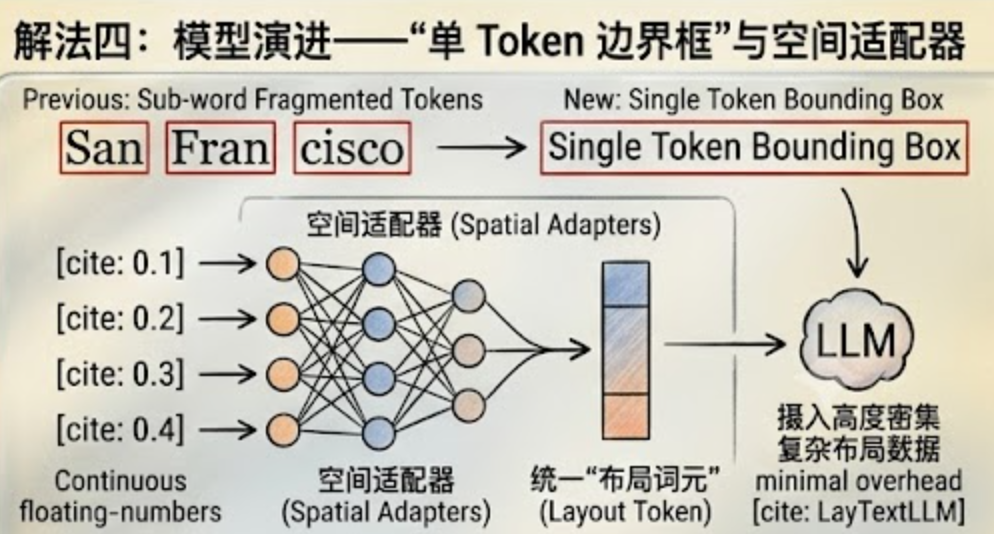
解法四:模型演进——"单 Token 边界框"与空间适配器(前沿方案)
针对分词器把空间切割得稀碎的问题,最前沿的架构(比如 LayTextLLM)开始引入独立的空间适配器(Spatial Adapters)。
它彻底摒弃了用一串离散的数字字符(比如 [xmin, ymin...])来让大模型读写坐标的做法。而是设计一个空间布局感知器(SLP),把四个连续的空间坐标浮点数直接送入非线性全连接网络,高维度投影到一个统一的**"布局词元"(Layout Token)**中。
-
一个边界框 = 一个 Token。大模型能够以处理单个单词的极低计算开销,瞬间摄入和生成高度密集的复杂二维空间布局数据,彻底规避了分词器带来的空间切割伪影。
最终的技术反思
这次把坑踩透之后,让我意识到一个很残酷的工程现实:现在全行业都太迷信端到端(End-to-End)的大模型了。
好像只要把一张图塞进一个巨大的模型里,就能自动、完美地吐出结构化数据。但现实是,空间定位和语义理解,本质上是两种完全不同的计算范式:
-
连续几何空间 vs 离散 Token 序列
-
像素级确定性 vs 概率生成幻觉
这两种范式强行融合,必然会在中间的编排层产生巨大的工程摩擦。
所以我的建议是:
-
看重绝对几何精度的场景(比如发票、账单、合同脱敏):坚定拥抱 "先检测,后提示" 的解耦架构,或者做好全套的 坐标逆运算 + 匈牙利匹配防线。别指望大模型自己能把几何题做对。
-
看重宏观布局与大局观语义的场景:可以尝试动态高分辨率编码器(Any-Resolution ViTs)原生输出,但必须在后处理进行强校验。
# 源头纠正:模型有时输出颠倒坐标(如 top > bottom)x1:左 top:上 x1:右 bottom:下
if x0 > x1:
x0, x1 = x1, x0
if top > bottom:
top, bottom = bottom, top
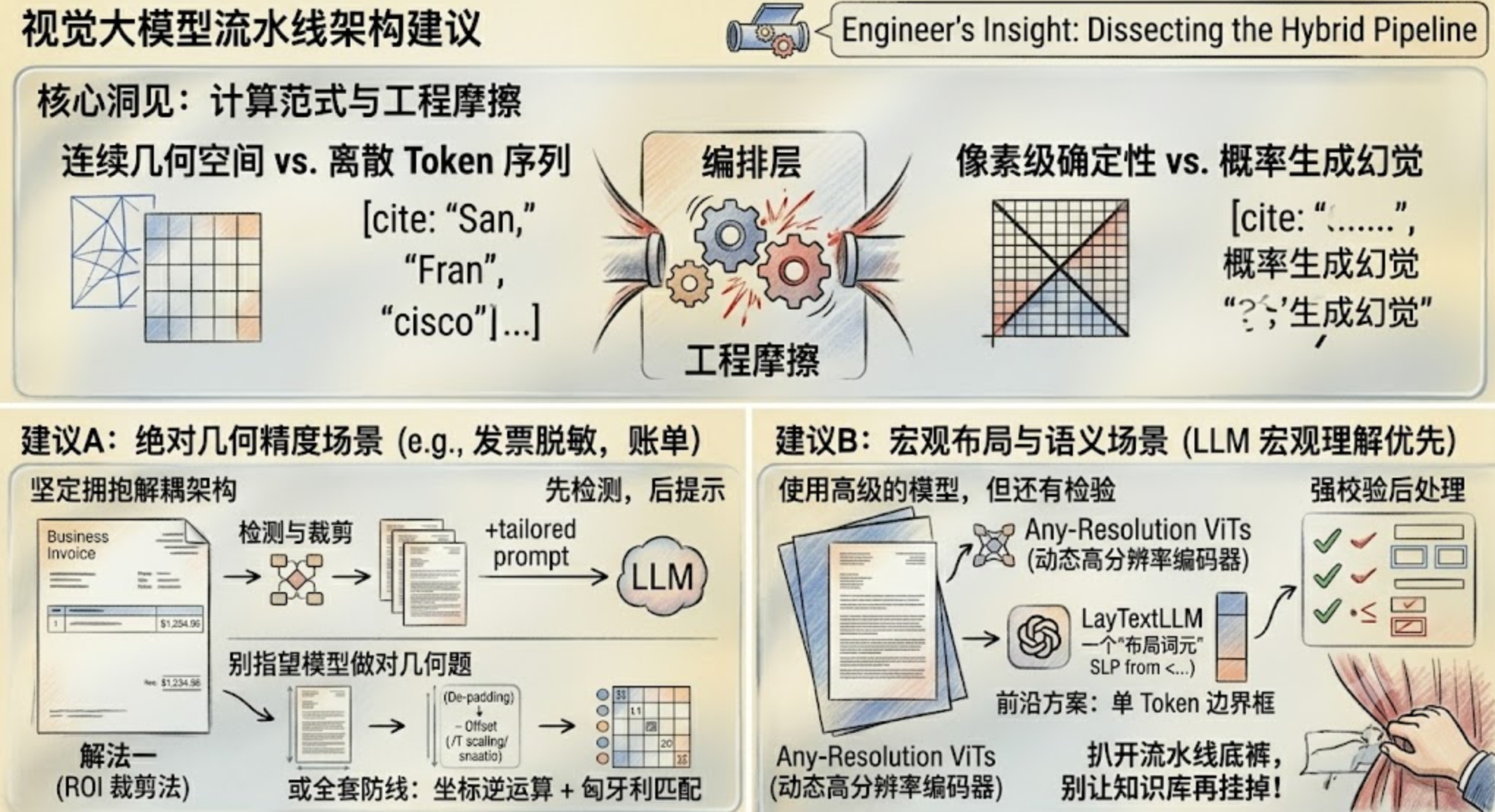
我替大家把整个混合流水线的底裤都扒开了,希望你们的知识库系统,别再因为这种看不见的"坐标漂移"而挂掉。
码字不易,欢迎“**在看**”!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)