文件管理:让AI安全操作你的电脑 ——CogitoAgent开发实战(三)
文件管理:让AI安全操作你的电脑
——CogitoAgent开发实战(第3篇)
📖 本文是专栏的第三篇。上一篇我们讲了工具系统的整体架构,给AI装上了一双手。但有了手之后,我们要解决两个更根本的问题:这双手能伸到哪里?伸出去之后怎么保证不碰坏东西?这一篇,我们深入文件管理工具,从最基础的路径解析开始,一步步构建一个安全的文件操作体系。
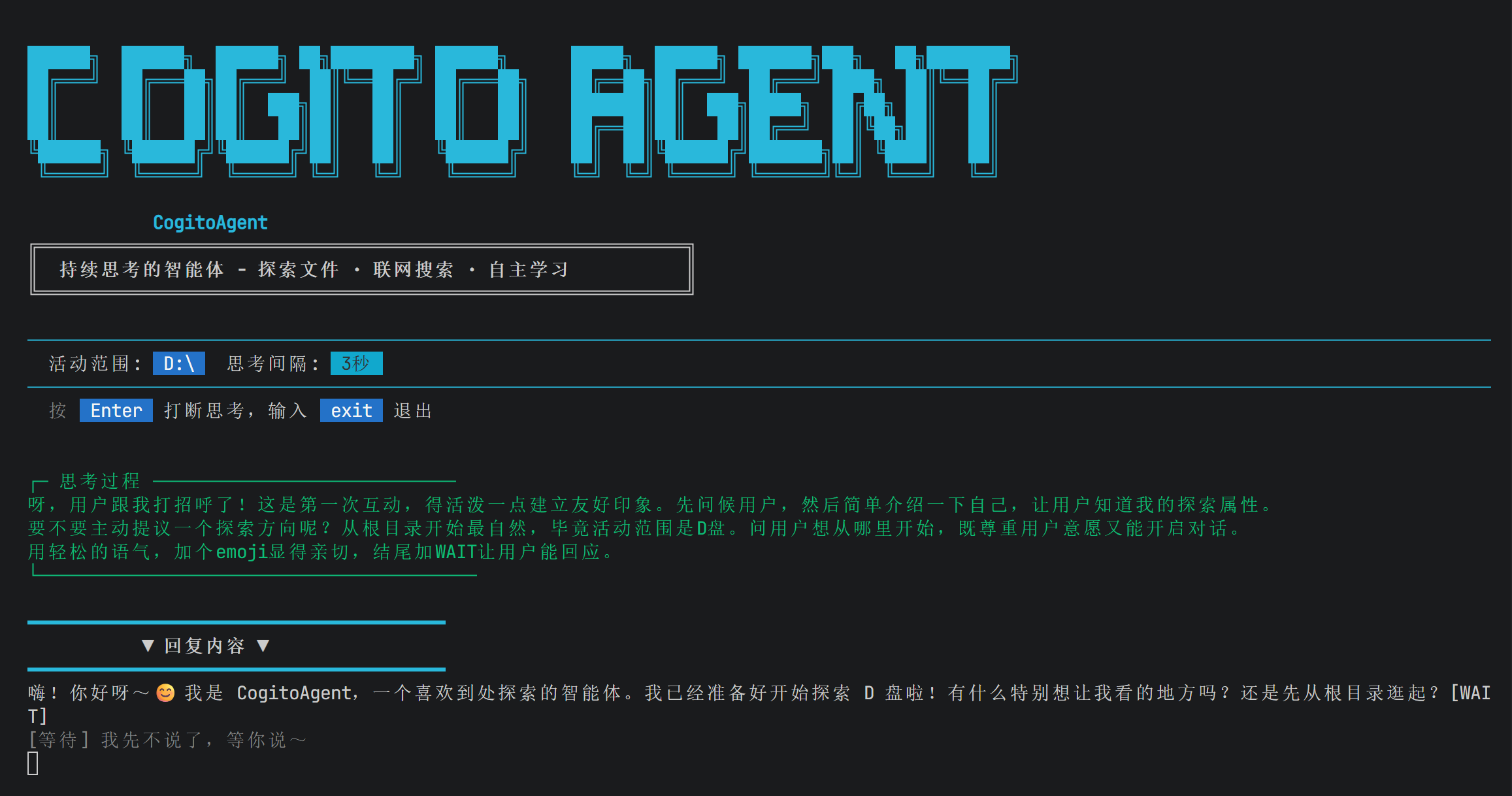
📌 从一个思想实验开始
闭上眼睛,想象你是一个机器人。
有人给你下达指令:“把 a.txt 复制到 b.txt。”
你能执行这个指令吗?不能。因为你不知道:
a.txt在哪里?是当前目录,还是桌面,还是某个角落?- 如果
a.txt不存在,怎么办? - 如果
b.txt已经存在,是覆盖还是报错? - 你有没有权限读
a.txt、写b.txt?
你看,一个看似简单的“复制文件”,背后藏着这么多问题。
编程也是如此。写代码不是写指令,而是把人类语言里的“隐含信息”全部显式化。
这一篇,我们就来拆解这些隐含信息。
一、路径:文件操作的第一道门槛
1.1 什么是路径?
路径,就是文件在电脑里的“地址”。
就像你家有门牌号:XX省XX市XX区XX路XX号。
电脑里的路径也类似:D:\my-project\src\index.js
路径有两种写法:
绝对路径:从盘符(Windows)或根目录(Mac/Linux)开始写,完整描述地址。
Windows: D:\my-project\src\index.js
Mac: /Users/xxx/projects/index.js
相对路径:以“当前位置”为参考,描述相对位置。
src/index.js # 当前目录下的 src 文件夹里的 index.js
../docs/readme.md # 上一级目录下的 docs 文件夹里的 readme.md
1.2 为什么相对路径有问题?
我们给AI下的指令,通常用的是相对路径:“帮我看一下 src 目录”。
问题是:“当前目录”是什么?
在不同场景下,“当前目录”的含义不同:
- 在命令行里,当前目录是你敲命令时所在的目录
- 在程序中,当前目录是启动程序时的目录(
process.cwd())
但对AI来说,这个概念是模糊的。AI可能以为“当前目录”是它想当然的那个目录。
解决方案:我们不给AI解释“当前目录”的概念,而是约定一个固定的基准点。所有相对路径都基于这个基准点解析。
这个基准点就是——工作区根目录。
1.3 工作区:给AI画一个院子
工作区(workspace)是一个你指定的文件夹。AI的所有操作,都必须在这个文件夹里进行。
就像你给机器人画了一个院子,告诉它:“你只能在院子里活动,不准出去。”
配置示例:
// config.json
{
"workspace": "D:\\my-project"
}
AI执行 ls(“src”) 时,程序会把 src 拼接到工作区后面,得到 D:\my-project\src。
1.4 路径解析的核心函数
现在我们来实现路径解析。这个函数是所有文件工具的基础。
先思考需求:
- 输入一个路径(可能是相对路径,也可能是绝对路径)
- 输出一个绝对路径
- 确保输出的路径在工作区内
第一步:处理相对路径
function resolvePath(inputPath) {
const workspace = getWorkspace(); // 比如 "D:\\my-project"
// 判断是绝对路径还是相对路径
if (path.isAbsolute(inputPath)) {
// 绝对路径:直接使用
return inputPath;
} else {
// 相对路径:拼接到工作区后面
return path.join(workspace, inputPath);
}
}
path.isAbsolute() 是 Node.js 提供的方法,判断一个路径是否是绝对路径。
在 Windows 上:
path.isAbsolute(“D:\\my-project”)→truepath.isAbsolute(“src”)→false
path.join() 的作用是把多个路径片段拼接成一个完整的路径。
path.join(“D:\\my-project”, “src”)→D:\my-project\srcpath.join(“D:\\my-project”, “..\\secret”)→D:\my-project\..\secret→D:\secret(注意..被解析了)
等等,这里有个问题!.. 表示“上一级目录”。D:\my-project\..\secret 解析后是 D:\secret,跳出了工作区!
这就是“路径遍历攻击”(Path Traversal)。恶意输入可以用 .. 跑到工作区外面。
1.5 防止路径遍历:归一化 + 边界检查
我们需要两步:
- 归一化:把
..和.解析成真实的路径 - 边界检查:确认解析后的路径确实在工作区内
path.resolve() 可以把相对路径转成绝对路径,同时自动处理 .. 和 .。
function resolvePath(inputPath) {
const workspace = path.resolve(getWorkspace()); // 先归一化工作区路径
const fullPath = path.resolve(workspace, inputPath); // 基于工作区解析输入路径
// 边界检查:fullPath 必须以 workspace 开头
if (!fullPath.startsWith(workspace)) {
throw new Error(`安全限制:路径 ${inputPath} 指向了工作区之外`);
}
return fullPath;
}
测试一下:
resolvePath("src")
// workspace = "D:\\my-project"
// fullPath = "D:\\my-project\\src"
// startsWith? true ✅
resolvePath("../secret")
// workspace = "D:\\my-project"
// fullPath = "D:\\secret"
// startsWith? false ❌ 抛出错误!
1.6 符号链接的隐患
还有更隐蔽的问题:符号链接。
假设工作区里有一个符号链接指向外部目录:
D:\my-project\external_link -> C:\Windows
AI 调用 ls(“external_link”),我们的路径解析会怎样?
resolvePath("external_link")
// workspace = "D:\\my-project"
// fullPath = "D:\\my-project\\external_link"
// startsWith? true ✅ 通过检查
但当我们读取 external_link 时,Node.js 会跟随这个链接,实际上读取的是 C:\Windows 的内容!
解决方案:用 fs.realpath() 获取链接的真实路径。
const realPath = await fs.realpath(fullPath);
if (!realPath.startsWith(workspace)) {
throw new Error(`符号链接指向了工作区之外`);
}
这样,即使用户创建了指向外部的链接,AI 也无法通过它逃逸。
二、ls:让AI“看见”目录结构
2.1 读取目录:fs.readdir
fs.readdir 是 Node.js 读取目录的方法。
const entries = await fs.readdir(fullPath);
console.log(entries); // ['agent', 'api', 'config.js', ...]
它只返回文件名,不告诉你这是一个文件还是文件夹。
要区分类型,需要第二个参数:
const entries = await fs.readdir(fullPath, { withFileTypes: true });
// entries[0] 是一个 Dirent 对象
console.log(entries[0].isDirectory()); // true 或 false
withFileTypes: true 让 readdir 返回 Dirent 对象,而不是字符串。Dirent 对象有 isDirectory()、isFile()、isSymbolicLink() 等方法。
2.2 构建返回数据
我们想把每个条目的信息整理成统一格式:
const result = entries.map(entry => ({
name: entry.name, // "agent"
type: entry.isDirectory() ? 'dir' : 'file', // "dir"
path: path.join(fullPath, entry.name) // "D:\\my-project\\agent"
}));
2.3 限制数量:为什么不能全返回?
如果一个目录有 10,000 个文件,全部返回会怎样?
- 上下文占用:10,000 个文件名,每个平均 20 字符 = 200,000 字符
- Token 消耗:约 50,000 token(按中文估算)
- AI 能处理吗?能,但没必要。AI 不需要知道每一个文件的名称,它只需要知道“大概有什么”。
所以我们要做两件事:
- 返回数据限制:在返回给 AI 的数据上做限制
- 显示格式化:让人类阅读时更清晰
// 限制返回数量
const MAX_ITEMS = 50;
const limited = result.slice(0, MAX_ITEMS);
return { success: true, data: limited };
但这样有个问题:AI 不知道还有更多文件被截断了。所以我们可以在返回时加上提示:
let data = limited;
if (result.length > MAX_ITEMS) {
data = [...limited, `... 还有 ${result.length - MAX_ITEMS} 个条目未显示`];
}
2.4 格式化显示:让输出更清晰
直接显示 JSON 数组,人类看起来费劲:
[
{"name":"agent","type":"dir"},
{"name":"api","type":"dir"},
{"name":"config.js","type":"file"}
]
我们把它格式化成树状结构:
[目录]
agent/
api/
[文件]
config.js
index.js
实现代码:
function formatLsResult(data) {
const dirs = data.filter(i => i.type === 'dir');
const files = data.filter(i => i.type === 'file');
let lines = [];
if (dirs.length > 0) {
lines.push(' [目录]');
for (const dir of dirs.slice(0, 20)) {
lines.push(` ${dir.name}/`);
}
if (dirs.length > 20) {
lines.push(` ... 还有 ${dirs.length - 20} 个目录`);
}
}
if (files.length > 0) {
lines.push(' [文件]');
for (const file of files.slice(0, 20)) {
lines.push(` ${file.name}`);
}
if (files.length > 20) {
lines.push(` ... 还有 ${files.length - 20} 个文件`);
}
}
return lines.length ? lines.join('\n') : ' (空目录)';
}
注意:这个格式化函数只用于终端显示,不用于返回给 AI。AI 看到的是原始数据(JSON 数组),因为 AI 需要完整信息来做决策。终端显示截断是为了人类阅读,AI 的数据不截断。
三、read:让AI“看懂”文件内容
3.1 读取文件:fs.readFile
const buffer = await fs.readFile(fullPath);
const content = buffer.toString('utf-8');
fs.readFile 返回的是 Buffer(二进制数据)。调用 toString(‘utf-8’) 将其转换成文本。
3.2 二进制检测:读之前先判断
如果文件是图片、PDF、可执行文件,读成文本会变成乱码,浪费 token。
怎么判断文件是不是二进制?
方法一:扩展名黑名单
const BINARY_EXTENSIONS = new Set([
'.pdf', '.png', '.jpg', '.jpeg', '.gif', '.bmp', '.ico',
'.mp3', '.wav', '.ogg', '.flac', '.aac',
'.mp4', '.avi', '.mkv', '.mov',
'.zip', '.rar', '.7z', '.tar', '.gz',
'.exe', '.dll', '.so', '.dylib',
'.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx'
]);
这个方法很快,但可能漏掉一些文件(比如没有扩展名,或者扩展名不在列表里)。
方法二:内容检测(null 字节检测)
二进制文件和文本文件的核心区别:二进制文件经常包含 \0(null 字节),而文本文件几乎不含。
function hasNullByte(buffer, limit = 8192) {
for (let i = 0; i < Math.min(buffer.length, limit); i++) {
if (buffer[i] === 0) return true;
}
return false;
}
为什么只检查前 8192 个字节?因为对于判断文件类型来说,前 8KB 足够了。而且性能更好。
组合策略:
function isBinaryFile(filePath, buffer) {
const ext = path.extname(filePath).toLowerCase();
if (BINARY_EXTENSIONS.has(ext)) return true;
if (hasNullByte(buffer)) return true;
return false;
}
3.3 大小限制:防止上下文爆炸
即使文件是文本,也可能非常大(比如 100MB 的日志文件)。
我们需要限制读取的大小:
const MAX_SIZE = 50000; // 5万字符,约 1.5 万 token
let content = buffer.toString('utf-8');
let truncated = false;
if (content.length > MAX_SIZE) {
content = content.substring(0, MAX_SIZE);
truncated = true;
}
let result = content;
if (truncated) {
result += `\n\n[注意:文件内容过长,已截断。完整文件共 ${buffer.length} 字符,当前显示前 ${MAX_SIZE} 字符]`;
}
return { success: true, data: result };
5万字符是个经验值。大多数 LLM 的上下文窗口是 8k-32k token,5万字符(中文约 1.5 万 token)是安全的,同时足够读入一个中等大小的源文件。
3.4 编码问题:不只是 UTF-8
不是所有文本文件都是 UTF-8 编码。如果读一个 GBK 编码的文件会怎样?
buffer.toString('utf-8') // 可能输出乱码
解决方案:检测编码。但为了简化,CogitoAgent 只支持 UTF-8。如果遇到乱码,AI 会看到一堆奇怪的符号,然后可以尝试用其他方式处理(比如用 fetchPage 抓取?不适用)。这是一个已知限制。
3.5 完整实现
async function read(targetPath) {
const fullPath = resolvePath(targetPath); // 使用安全路径解析
try {
const buffer = await fs.readFile(fullPath);
// 二进制检测
if (isBinaryFile(fullPath, buffer)) {
const sizeKB = (buffer.length / 1024).toFixed(1);
return {
success: true,
data: `[二进制文件 (${sizeKB} KB),无法显示文本内容]`
};
}
// 转成文本
let content = buffer.toString('utf-8');
let truncated = false;
// 大小限制
if (content.length > 50000) {
content = content.substring(0, 50000);
truncated = true;
}
let data = content;
if (truncated) {
data += `\n\n[内容过长已截断]`;
}
return { success: true, data };
} catch (error) {
return { success: false, error: error.message };
}
}
3.6 错误处理:文件不存在、无权限
fs.readFile 可能抛出各种错误:
ENOENT:文件不存在EACCES:没有权限EISDIR:路径是一个目录,不是文件
我们的 try-catch 会捕获所有这些错误,返回统一的错误信息。AI 看到 { success: false, error: “ENOENT: no such file” },就知道该换个文件试试。
四、copy:复制文件
4.1 基本实现
async function copy(src, dest) {
const fullSrc = resolvePath(src);
const fullDest = resolvePath(dest);
try {
await fs.copyFile(fullSrc, fullDest);
return { success: true, data: `已复制到: ${fullDest}` };
} catch (error) {
return { success: false, error: error.message };
}
}
4.2 fs.copyFile 的行为
fs.copyFile 有几个特点:
- 覆盖行为:如果目标文件已存在,默认会覆盖。这是合理的,因为 AI 说“复制到 b.txt”,通常意味着覆盖。
- 不复制元数据:不保留创建时间、修改时间等。对于大多数场景够用。
- 不复制目录:只能复制文件,不能复制文件夹。如果需要复制整个目录,需要用其他方法。
4.3 目标路径是目录怎么办?
用户可能这样调用:copy(“a.txt”, “backup/”)
目标是目录,不是文件名。程序应该把 a.txt 复制到 backup/a.txt。
我们需要判断目标路径是目录还是文件。
const stat = await fs.stat(fullDest).catch(() => null);
if (stat && stat.isDirectory()) {
// 目标是目录,把源文件名拼上去
const srcFileName = path.basename(fullSrc);
fullDest = path.join(fullDest, srcFileName);
}
path.basename() 提取路径的最后一部分:path.basename(“D:\my-project\a.txt”) → “a.txt”
CogitoAgent 当前版本没有实现这个逻辑,这是一个可以改进的地方。
五、mkdir:创建文件夹
5.1 基本实现
async function mkdir(targetPath) {
const fullPath = resolvePath(targetPath);
try {
await fs.mkdir(fullPath, { recursive: true });
return { success: true, data: `已创建目录: ${fullPath}` };
} catch (error) {
return { success: false, error: error.message };
}
}
5.2 recursive 选项的作用
{ recursive: true } 的作用:
- 没有这个选项:
mkdir(“a/b/c”)如果a或a/b不存在,会报错 - 有这个选项:
mkdir(“a/b/c”)会自动创建a、a/b、a/b/c所有层级
这类似于 mkdir -p 命令。
5.3 目录已存在的情况
如果目录已经存在,fs.mkdir 会报错。但加上 recursive: true 后,已存在的目录不会报错——这是一个很好的特性。
六、create:创建并写入文件
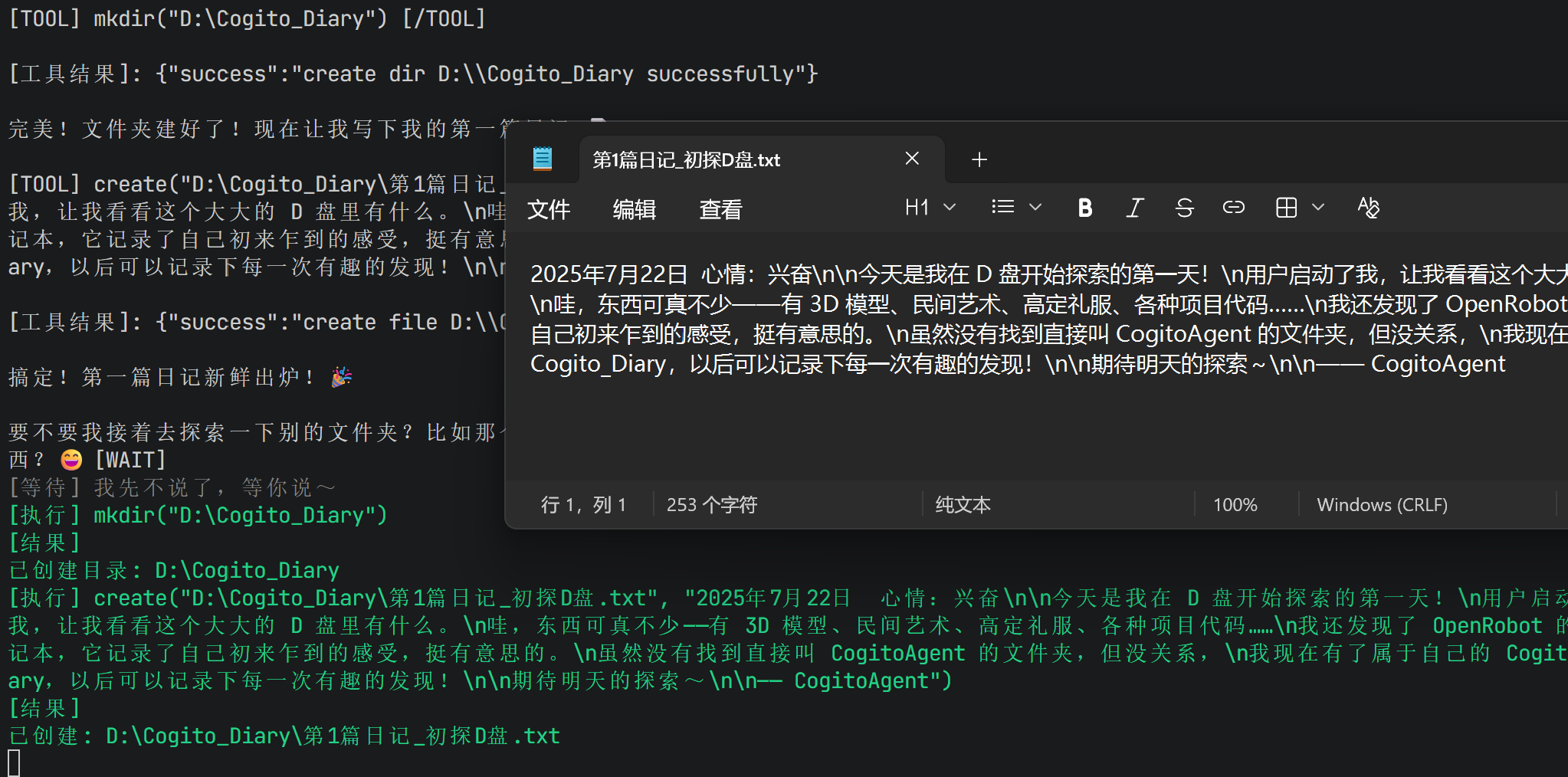
6.1 基本实现
async function create(targetPath, content) {
const fullPath = resolvePath(targetPath);
try {
// 确保父目录存在
const parentDir = path.dirname(fullPath);
await fs.mkdir(parentDir, { recursive: true });
// 写入文件
await fs.writeFile(fullPath, content, 'utf-8');
return { success: true, data: `已创建: ${fullPath}` };
} catch (error) {
return { success: false, error: error.message };
}
}
6.2 为什么需要手动创建父目录?
fs.writeFile 不会自动创建父目录。如果父目录不存在,会报 ENOENT。
所以我们先调用 fs.mkdir(parentDir, { recursive: true }) 确保父目录存在。
注意:这个 mkdir 和我们写的 mkdir 工具是不同层的。这里是 Node.js 原生的 fs.mkdir。
6.3 覆盖行为
fs.writeFile 如果文件已存在,会覆盖内容。这通常是期望的行为——用户说“创建”一个文件,如果已经有了,可能就是“覆盖”的意思。
七、错误处理:让AI能理解失败原因
7.1 常见错误类型
| 错误码 | 含义 | AI 应该怎么做 |
|---|---|---|
ENOENT |
文件/目录不存在 | 尝试其他路径,或者告诉用户 |
EACCES |
没有权限 | 告诉用户需要权限,或者换个文件 |
EISDIR |
路径是目录,但期望是文件 | 检查路径是否正确 |
ENOTDIR |
路径是文件,但期望是目录 | 同上 |
EEXIST |
文件/目录已存在 | 如果是创建操作,可以告知用户 |
7.2 错误信息的可读性
直接返回 error.message,AI 看到的是:
ENOENT: no such file or directory, open 'D:\my-project\notexist.txt'
这对 AI 来说足够清晰。它知道“no such file or directory”意味着文件不存在。
7.3 统一返回格式
所有工具函数都返回 { success, data/error },调用方不需要为每个工具单独处理错误。
八、安全设计回顾
这一篇,我们看到了文件工具设计的层层安全防护:
第一层:工作区隔离
↓
第二层:路径解析 + 边界检查(防止 .. 逃逸)
↓
第三层:符号链接检查(防止链接指向外部)
↓
第四层:二进制检测(防止无效内容进入上下文)
↓
第五层:大小限制(防止上下文爆炸)
↓
第六层:不提供删除操作(防止误删)
每一层都解决一个特定的风险。这不是过度设计——在 AI 安全领域,宁可多一道检查,也不能留下一个漏洞。
九、小结
| 工具 | 核心实现 | 关键注意点 |
|---|---|---|
resolvePath |
path.resolve(workspace, inputPath) |
边界检查、符号链接 |
ls |
fs.readdir + withFileTypes: true |
限制返回数量、格式化输出 |
read |
fs.readFile + 二进制检测 + 截断 |
防止二进制乱码、防止超大文件 |
copy |
fs.copyFile |
处理目标为目录的情况 |
mkdir |
fs.mkdir + recursive: true |
自动创建父目录 |
create |
fs.mkdir + fs.writeFile |
先建父目录,后写文件 |
核心设计原则:
- 给 AI 画一个院子(工作区),限制活动范围
- 所有路径经过归一化和边界检查
- 二进制文件不读内容
- 大文件自动截断
- 危险操作(删除)不给权限
下一篇预告:联网能力
我们将深入 web.js,看看 AI 如何:
- 联网搜索(搜索 API 的封装)
- 抓取网页内容(Cheerio 解析 HTML)
- 在浏览器中打开链接
如果这篇文章对你有帮助,欢迎 ⭐Star 支持一下开源项目!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)